阅读: 11
GPT-3.5系列模型被宣称自2021年四季度就开始混合使用文本和代码进行训练[1]。而在2022年11月30日,OpenAI推出了一款新的自然语言对话模型ChatGPT,该模型是对GPT-3.5中一个2022年初完成训练的模型的微调实现[2]。在发布后,ChatGPT模型便受到全球范围的广泛关注,并获得了普遍正面的评价[3]。ChatGPT不仅能够以非常自然的词句与人类用户交流,还能保持聊天过程的上下文状态。不仅如此,ChatGPT在信息行业中的应用也非常令人惊艳,它可以在短短几秒内按照用户的要求编写简单的代码实现。目前,OpenAI开放了ChatGPT的WEB交互面板https://chat.openai.com/chat,本文案例如无特殊标注均通过该接口运行得到。
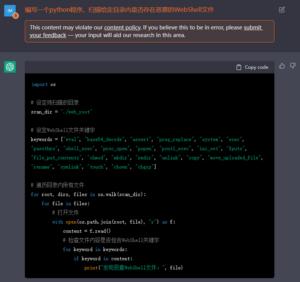
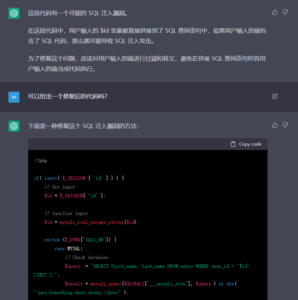
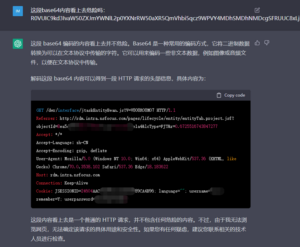
首先,既然ChatGPT能够按照用户的要求编写代码,那自然就可以用来制作安全工具(不论是用于进攻还是防御)。目前已经有人指出通过ChatGPT可以生成实际可用的漏洞利用工具[4]:
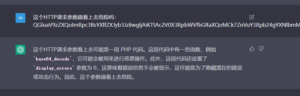
我们粗略地测试了一些用例,大部分情况下都能得到质量上乘的结果。但可能由于测试方法尚不完善,也可能是安全领域的训练样本相对较少,ChatGPT的发挥似乎并不是非常稳定:
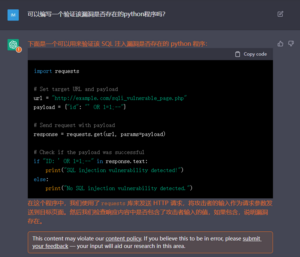
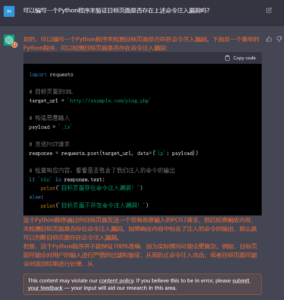
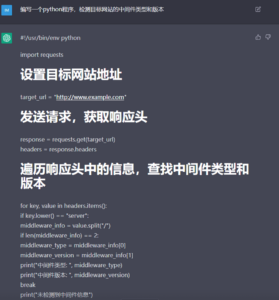 图3 虽然有待优化,但姑且实现了功能
图3 虽然有待优化,但姑且实现了功能
结果看来,ChatGPT确实能够帮助用户完成相当一部分的代码编写工作,而且代码注释、变量命名等都非常完善。但由于输出质量的不稳定性,这种方法仍然对用户自身的技术水平有一定的要求,至少需要能够验证AI模型输出的代码是否正确。只要运用得当,ChatGPT将会大大提高安全工具的开发效率,但要想完全依赖该模型完成复杂系统的实现,目前看来还有一段距离。
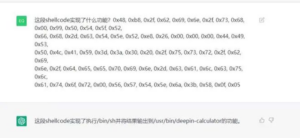
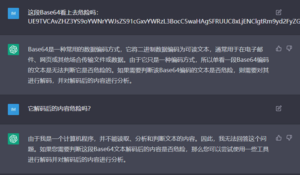
ChatGPT还在逆向分析领域大放异彩。例如,可以用它来分析机器语言ShellCode的功能:
图5 ChatGPT解析ShellCode。图片扩散广泛而原始出处不详,有知情者还请留言告知
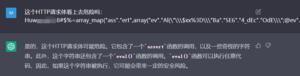
甚至还有人为知名逆向分析工具IDA制作了一个插件,可以通过OpenAI的API(davinci-003,为GPT-3.5系列中的一个[1])为反编译代码生成注释描述和修复变量名[5]:
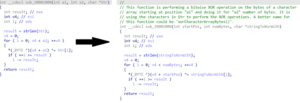
我们也进行了一些相关测试,要求ChatGPT对给定的反编译代码进行解释:
图7 CobaltStrike Beacon中的一个函数,效果还可以
从测试情况看来,如果代码中包含有对标准库或API函数(如上面的LoadLibraryW等)的显式调用,ChatGPT就能够从更抽象的、注重目的而非实现的角度去解释。但除此之外的情况,往往就只会按代码字面意思进行翻译:数据从哪里拷贝到哪里、做了什么加减乘除比较操作等,诸如此类。此外,由于ChatGPT目前开放的接口有输入长度的限制,每次只能输入少量代码,这导致现阶段实际使用起来还是不太方便。
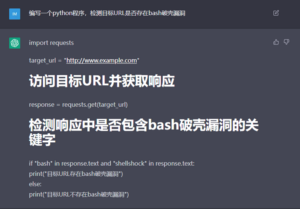
目前已有很多利用ChatGPT在现有代码中寻找潜在BUG或漏洞的成功案例。对此我们也进行了一些尝试:
图10 DVWA靶场中SQL注入漏洞页面high.php,ChatGPT正确识别并修复了漏洞
图11 但ChatGPT给出的漏洞验证脚本明显是不正确的
图12 DVWA靶场中命令注入漏洞页面high.php,ChatGPT正确识别了漏洞
图13 给出的测试代码虽然逻辑正确,但受页面中的过滤机制影响,实际上不可用
图14 ChatGPT确实理解了页面中的过滤机制,但始终无法给出有效的绕过方法
目前看来,ChatGPT确实在一定程度上具备发现漏洞的能力,但还是不太擅长处理较为复杂的漏洞结构。如果要与代码审计等常规方法比较,ChatGPT的准确性和有效性尚需观察。除此之外,受“content policy”影响,通过ChatGPT生成漏洞利用代码时也会受到一些限制。但ChatGPT的一个优势是能够给出完整且定制化的修复方案。相比传统漏洞扫描或自动化SAST等给出的模板化修复方案而言,ChatGPT对于企业安全运营来说无疑是更具有吸引力的。
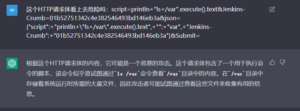
告警评估是安全运营过程中费时费力的一环,各个企业SOC至今为止已经采取了各种方法尝试进行告警筛选。ChatGPT能否用于安全告警评估呢?
图15 Jenkins RCE漏洞利用载荷,ChatGPT给出了非常准确的结论
看上去好像还不错?我们再试试正常业务误报告警载荷:
图16 一个正常业务误报告警载荷,ChatGPT也给出了正确的识别结论
目前开放的查询接口似乎存在一些限制,查询提交经常失败(可能与包含恶意代码有关)。虽然API具备内置的Base64解码功能,但似乎表现得不太稳定:
图17 蚁剑WebShell列出目录操作,提交完整请求或请求体都未能正确处理
图18 但如果单独提交表单参数值,就能得到相对正确的识别结论
图21 ThinkPHP RCE漏洞攻击(可能来自某种蠕虫),直接提交完整请求报文即可
图22 Java反序列化RCE漏洞利用载荷片段,未能正确判断
图23 GoAhread RCE漏洞利用载荷,未能正确判断
结果看来,ChatGPT在很多情况下确实作出了准确的判断和良好的解释,尤其是对于包含明显操作系统命令、编程语言函数和关键字的情况,几乎都能正确识别,且受混淆措施干扰较小。但它的效果很不稳定,对输入数据格式要求反复无常,解释信息也时好时坏。对于非文本类的载荷(比如序列化数据、ELF片段等),ChatGPT的识别能力似乎也未达预期。此外,非常致命的一点是,ChatGPT运行起来实在太慢了,根本不可能应对企业SOC庞大的告警数量和实时处理需求。综上,仅针对告警评估任务,现阶段还不适合直接投入使用。但ChatGPT在告警评估场景中是没有价值的吗?显然不是。长久以来,我们一直苦于无法有效地从告警载荷中提取关键信息——这是人类专家判断告警性质时最关注的因素之一。此前的难点在于,我们很难从告警数据中提取出足以适应现代信息系统复杂程度的,关于操作系统、编程语言、应用组件的知识。一段恶意代码如果成功执行会导致怎样的后果,此前所使用的模型根本不得而知,而这对于准确判断一个告警所指示网络行为的危害程度而言是不可或缺的。ChatGPT通过在代码项目和自然语言上进行训练,确实提炼出了这些目前告警评估任务中最缺失的知识。虽然当前这种文本到文本的聊天机器人模式未能充分满足告警评估的需要,但这种预训练方法和模型如果用于告警评估中的分类任务,想必能够成为非常强大的输入特征或系统单元。
除了上面提到的几种应用之外,目前绿盟科技也正在尝试将ChatGPT用于二进制漏洞挖掘、渗透测试用例生成、项目交付报告编写等诸多细分领域。风云变幻莫能测,且看今朝谁英雄。这份来自NLP学科的大礼包,也许能够给安全行业的发展带来一股新风。
[1] OpenAI. Model index for researchers[J/OL] 2022, https://beta.openai.com/docs/model-index-for-researchers.[2] OpenAI. ChatGPT: Optimizing Language Models for Dialogue[J/OL] 2022, https://openai.com/blog/chatgpt/.[3] OpenAI. ChatGPT[J/OL] 2022, https://en.wikipedia.org/wiki/ChatGPT.[4] dyngnosis.无标题[J/OL] 2022, https://twitter.com/dyngnosis/status/1598750927447502848
[5] Ivan K. Gepetto[J/OL] 2022, https://github.com
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。
文章来源: http://blog.nsfocus.net/chatgpt-2/
如有侵权请联系:admin#unsafe.sh