2019-11-04 20:54:37 Author: bbs.pediy.com(查看原文) 阅读量:221 收藏

JVM是怎么创建对象的呢?当你new Object()的时候到底发生了什么?
对象的分配通过是使用线程本地分配缓存(TLABs):每个线程独有的内存分配区域。因为在这块区域中不需要考虑同步,所以创建对象的速度会很快。
但是怎样正确地选择TLAB的大小呢?当你要分配10%的TLAB空间,但只剩9%的时候该怎么办呢?对象可以被分配在TLAB外吗?当分配的内存设置为0的时候会怎样?
在问了这些问题但没有找到答案之后,我决定写一篇文章来讲述这些内容。
在阅读后面的内容之前,如果对垃圾回收的工作机制有一些理解的话,会更容易理解
介绍
创建一个对象需要哪些步骤?
首先,需要找到一片未被占用且足够大的内存区域,然后初始化对象:用0填充内存区域,初始化一些内部结构(用于调用getClass()的信息及同步需要的信息等),最后调用构造函数。
本文的组织结构如下:首先在理论上分析创建对象时会发生些什么,然后我们进入JVM内部看看真实的情况是什么样的,最后写一些测试程序来验证它们。
声明:某些部分在不丢失一般性的情况下简化了。当说到垃圾回收的时候,我是指任意的压缩回收器,当说到地址空间的时候,我是指新生代的eden区。对于其他的(标准的或是知名的)垃圾回收器,部分地方可能会有变化,但不会变化太多。
TLAB 101
第一部分是给我们的对象分配内存。
一般而言,内存的分配是一项非常重要的任务,充满了痛苦。例如,链表的创建需要两倍的内存空间,在必要的情况下,需要搜索并将一部分内存区域从一个链表剪切到另一个链表(也就是buddy allocator)。幸运的是,Java中有一个垃圾收集器,它承担了其中大部分工作。在对新生代进行垃圾回收的过程中,所有存活的对象会被转移到幸存区,这样eden区就会空出来一大段连续的内存。
因为JVM会进行垃圾回收,分配器只需要知道去哪里找到空闲的内存,实际情况是,通过控制一个指向这片最大空闲内存区间的指针来寻找空闲内存。也就是说,分配过程非常简单:你需要将eden区的指针增加这个对象的大小(这一技术称之为指针碰撞,bump-the-pointer)。内存可以被同时分配给好几个线程,所以需要一些同步操作。如果你用最简单的方法来实现(阻塞堆内存或是使用原子操作实现指针的增长),内存分配就会成为一个瓶颈,所以JVM的开发者发明了指针碰撞:每个线程分配一大片独占的内存区域。如果可能的话,在其中的内存分配操作会导致指针的增长(但是因为是发生在线程本地,所以不需要同步),当这一片内存区域用完的时候会再申请一片内存空间。这一区域称之为线程本地分配缓存,它最终表现为基于层级的指针碰撞,第一层是堆区域,第二层是是当前线程的TLAB。这篇文章里有更进一步的探讨,分层是通过将缓存区内部再分割出一片缓存区实现的。

采取这种方式,在大部分情况下,内存分配会非常快,让我们执行一些指令试试:
end = start + sizeof(Object.class);
if (end > currentThread.tlabEnd) {
goto slow_path;
}
currentThread.setTlabTop(end);
callConstructor(start, end);
上面这段代码看起来非常正确,我们使用PrintAssembly看看结果,这个方法会创建 java.lang.Object ,编译之后是这样的:
; Hotspot machinery skipped mov 0x60(%r15),%rax ; start = tlabTop lea 0x10(%rax),%rdi ; end = start + sizeof(Object) cmp 0x70(%r15),%rdi ; if (end > tlabEnd) ja 0x00000001032b22b5 ; goto slow_path mov %rdi,0x60(%r15) ; tlabTop = end ; Object initialization skipped
在这段源码中可以发现,寄存器%r15包含一个指向VM线程的指针(题外话:因为这一不变的线程本地存储,Thread.currenThread()执行起来非常快),这刚好是我们期望看到的代码。同时,我们注意到JIT编译器zanilaynil会把内存直接分配给调用方法。这样的话,JVM可以随意地(在垃圾回收中并不推荐)创建对象,负责清理内存,垃圾回收。一个好的想法是定位到分配的连续数据,但是不能保证进行传统的分配。有一项完整的研究介绍了这种定位对经典应用的性能的影响。这项研究中,用增加GC负荷的方法来使程序运行更快。
TLAB大小对事件的影响
TLAB的大小应该是多少?从直觉上来看,缓存大小越小,内存分配会越频繁,也就导致程序运行更慢,因此,TLAB要做的事情也更多:最终为了使创建对象更快,我们得到一个相对缓慢的公共堆内存。
但这会产生另一个问题:内部碎片。
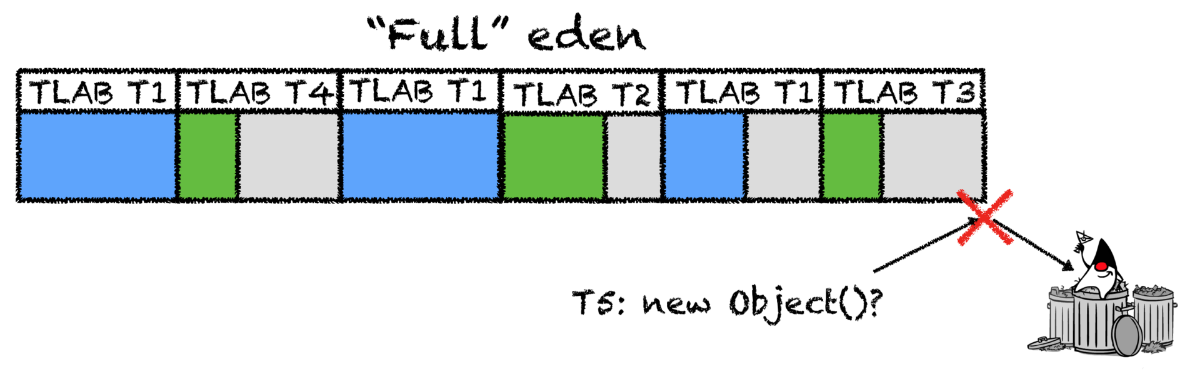
假设这样场景,TLAB大小为2MB,eden区(用于分配TLAB)是500MB,应用有个50线程。当堆中没有空间再进行TLAB的分配,第一个线程就会废弃它的TLAB,触发垃圾回收。假设所有TLAB都统一用±进行填充(实际应用中不会发生这种情况),所以TLAB的平均剩余空间大概是一半,也就是说,还剩下0.5 50 2 == 50MB的未占用空间(大概是10%),这时候垃圾回收就开始了。最后的结果不太理想:内存仍有大片的空间就调用GC了。

如果你继续增加TLAB的大小或是线程的数量,内存丢失的次数会线性增长,虽然最后TLAB分配空间的速度加快了,但是降低了整个应用的速度,垃圾回收会变得频繁。
如果TLAB中的中仍然有空间,而新对象太大了呢?如果你放弃原来的缓存重新开辟一个新的,碎片就会增多,如果直接在eden区创建对象的情况时常发生,应用运行速度就会比原来更慢。
通常而言,应该做什么并没有一个明确的标准,你可以设定一个神秘的常数(用在启发式算法中),你也可以把设置TLAB大小的权力交到开发者手中,为每个应用设定一个不同的大小(非常方便),你也可以让JVM来猜测正确的答案是多少。
我们该做什么?
选择一个常数并没有什么意义,但是Sun的工程师们并没有放弃,他们选择了另一种方式:不再指定大小,而是指定碎片的百分比,也就是堆中用于快速分配的空间,JVM会负责它的计算。它由TLABWasteTargetPercent这一参数负责,默认值为1%.
对于线程内存的分配也使用同一假设,这样就得到了一个简单的等式:
tlab_size * threads_count * 1/2 = eden_size * waste_percent
如果我们准备使用eden区10%的空间,现在我们有50个线程,eden区共有500MB,在刚开始进行垃圾回收的时候,在TLAB中会有50MB的可用空间,也就是说我们TLAB的大小是2MB。
在这一方法中,遗漏了一个重要的事实:它假设所有的数据流都以同一种方式进行分配,这几乎是不可能的。我们并不建议调整最密集数据流的分配速度,也不建议调整运行不那么快的数据流(例如,scheduled-vorkers(译者注:这里应该是作者打错了,应该是workers))。此外,在一个典型的应用中,通常有几百个线程(例如你最喜欢的服务器上的treadpulls),只有很少一部分在创建对象时的负荷较小,这种情况也要考虑进去。如果你想起了这个问题“如果你想要分配10%的TLAB空间,但剩余空间只有9%时应该怎样”,这种情况的解决方案就不是那么重要了。
其中涉及到的细节太多,很难在一篇博客中讲述完全,所以是时候看一看hotspot的源码,了解一下实际情况中是怎么实现的。
如果你想要重现这一过程,我是使用Clion进行开发,使用jdk9的master分支,这是CMakeLists。
兔子洞探险
(译者注:爱丽丝掉进了兔子洞,从而来到了仙境)
第一个引起我们注意的是 threadLocalAllocBuffer.cpp文件,在这个文件中定义了缓存的结构。这个类用于描述一个缓存及TLAB的使用数据,它会在每个线程创建和TLAB分配的时候进行创建。
要理解JIT编译器,你需要像JIT编译器一样思考。因此,跳过初始化阶段,为新线程创建一个缓存,计算一下这个缓存的大小,再看一看resize的实现,这个方法会在编译结束后,为所有的线程调用一次。
void ThreadLocalAllocBuffer::resize() {
// ...
size_t alloc =_allocation_fraction.average() *
(Universe::heap()->tlab_capacity(myThread()) / HeapWordSize);
size_t new_size = alloc / _target_refills;
// ...
}
JVM会追踪每个线程内存分配的紧张程度,根据紧张程度和constant_targetrefills(两次垃圾回收期间线程想要请求的TLAB的数量)来计算新的大小。 target_refills只会被初始化一次:
// Assuming each thread's active tlab is, on average, 1/2 full at a GC _target_refills = 100 / (2 * TLABWasteTargetPercent);
它刚好是我们上面假设的TLAB请求的数量,而不是TLAB的大小。要确保垃圾回收的时候所有线程剩余空间的大小不超过x%(译者注:原文内容为不超过%,疑为笔误),需要在两次垃圾回收期间,让每个流的TLAB的大小占总内存的2x%。用1除以2x%,就获取到了请求的数量。
线程共享空间需要在某个时刻进行更新。在每次垃圾回收的初始阶段,所有线程的数据都会被更新,具体实现的方法是accumulate_statistics
我们会检查线程的TLAB是否至少被更新了一次。对于什么也没做的线程(或是没有进行过内存分配),不再需要重新计算其大小。
在计算时,我们会检查eden区的一半是否有在使用,以避免完全GC或是pathological cases(例如,对System.gc()的显式调用)。
最后,想想eden区使用的空间的百分比,并更新它的共享分配空间。
我们更新了线程使用TLAB的数据,有多少空间被分配,被怎样分配,又有多少空间被浪费。
要避免由于频繁垃圾回收,和与垃圾收集器不稳定性相关的不同的分配模式,而导致的各种不稳定影响,共享内存的分配就不能仅仅用一个常数来控制,它应该是一个指数加权移动平衡,它反映了过去N次垃圾回收的平均值。在JVM在,每样东西都有一个key,这个地方也不例外,TLABAllocationWeight 标志控制着旧值的平均“遗忘”速度(没有人会想改变它的值)。
结果
到此为止,我们已经获取到了足够的信息,以回答文章最开头提到的那几个关于TLAB大小的问题。
JVM知道它能在碎片上花费多少内存。这一值计算了两次垃圾回收之间,线程应该请求的TLAB的数量。
JVM会追踪每个线程使用的空间,并对这些值进行平滑。每个线程以它使用空间的一定的百分比作为它的TLAB的大小。它解决了线程间不平均分配的问题,并使得分配速度更快,浪费的空间更少。

如果应用有100个线程,其中的3个处理用户请求,其中2个定时做一些辅助活动,其他的线程处于闲置状态,那么第一组线程会获取到更大的TLAB空间,第二组空间非常小,其他的都是默认值。最重要的是,“慢”分配(TLAB请求)的数量对于所有线程来说都是一样的。
原文链接:https://umumble.com/blogs/java/how-does-jvm-allocate-objects%3F/
翻译:看雪翻译小组 梦野间
校对:看雪翻译小组 lumou
如有侵权请联系:admin#unsafe.sh