团队科研成果分享2023.02.27-2023.03.05标题: A Novel Clustering Based on Consensus Knowledge for Cross-Domain Fa 2023-3-5 06:3:57 Author: 网络与安全实验室(查看原文) 阅读量:35 收藏
团队科研成果分享
2023.02.27-2023.03.05
标题: A Novel Clustering Based on Consensus Knowledge for Cross-Domain Fault Diagnoses
期刊: IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 9, pp. 16842-16853, Sept. 2022, doi: 10.1109/TITS.2021.3131473.
作者: Guangjie Han, Zhengwei Xu, Chuanliang Chen, Li Liu, and Hongbo Zhu.
分享人: 河海大学——张煜
01
研究背景
BACKGROUND
研究背景
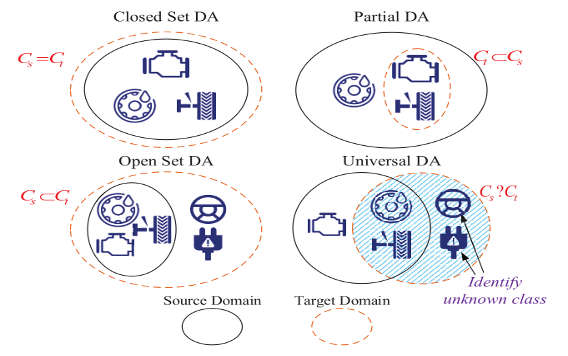
近年来,随着世界各地工业基础设施安全事件数量不断增加, 工业设备的故障诊断成为了智能物联网安全系统中不可或缺的一部分。传统的算法通常假设目标域和源域的样本共享相同的故障模式集,并且源域和目标域是相互关联的。然而,在实际的工业故障诊断中很难获得这种先验知识。并且现有方法没有充分利用私有类样本的固有结构,即每个故障模式内的变化以及各种类别之间的关系。这导致模型紧凑性较低以及识别精度的下降。图1显示了几种常见的故障诊断传输模式。
基于上述问题,本文提出了一种新颖的域共识通用域自适应网络(DCUAN),以构建端到端的通用域故障诊断模型。
图1 现有的四种域自适应模式
02
关键技术
TECHNOLOGY
关键技术
为了解决现有方法不能充分利用私有类样本固有结构的问题,本文通过挖掘目标域中的公共类和私有类,可以更有效地使用内部结构。在通用域自适应诊断问题中,源域和目标域都包含它们自己的私有类和公共故障模式的公共类。本文提出的DCUAN采用类级对齐方法,通过减少源域和目标域的集群中心之间的距离来识别它们的公共类。此外,DCUAN采用样本级共识知识来解决目标域故障模式难以获取的问题。DCUAN从类和样本级别挖掘领域共识知识,并将其集成到特征提取模块中,该模块使用原型正则化器来促进样本与其连接的聚类中心接近。这使得模型能够通过允许私有样本相互区分来学习更好的表示。
该方法的创新和贡献如下:
1)为了解决通用域自适应诊断问题,本文提出了一种基于聚类的域共识通用域自适应网络(DCUAN)的故障诊断模型。训练的模型不仅自动识别和匹配来自公共标签集的样本,还通过将其他目标样本指定为“未知”来过滤它们。
2)本文为故障诊断模型提出了一种称为域共识聚类的混合无监督聚类策略。它通过在没有先验知识的情况下引导目标聚类,从类和样本级别挖掘领域共识知识。
3)本文引入了一种新的聚类评估标准,称为域共识分数,以帮助DCUAN进行跨域分类。与针对单个领域问题设计的现有度量不同,它支持跨领域的有效知识迁移。
03
算法介绍
ALGORITHMS
算法介绍
1. 网络模型
图2 提出的DCUAN框架
与现有方法不同,本文提出的DCUAN将私有样本作为通用类,并忽略私有类的独特特征,将无监督聚类嵌入到深度模型中,以提取目标样本的固有特征。如图2所示,DCUAN包含三个模块:特征提取器F、聚类模块和分类器G。
由于输入数据是一维振动信号,本文使用一维卷积神经网络(1-D CNN)来构造F以提高特征的表示性。F将输入样本映射到新的特征空间中,以获得域不变和类判别表示。G接收提取的特征并将其分配给一个源类。此外,聚类模块在两个连续的步骤中利用领域共识知识,然后在私有和公共故障模式上形成有区别的聚类。因为源域有标签,所以模型根据源样本的真实标签对其进行聚类,每个类的聚类中心表示相应样本的均值嵌入。第c个源类的集群中心定义为:
对于目标域,无监督K-means方法用于将未标记的目标样本分配给K个不同的聚类,因为没有目标标签空间的先验知识。DCUAN学习领域共识知识以在两个领域之间执行类匹配,而不是使用鉴别器来弥合对抗性域适应中的领域差异。此外,还挖掘了类和样本级共识,以确保目标聚类的合理性。
2. 类级共识
尽管存在领域差异,但通用域诊断模型应区分公共样本和私人样本。同时,不同的工作条件会影响数据分布,但来自两个域之间的共享故障模式的样本应包含相似的故障机制,并且它们之间的距离应小于来自不同故障模式的采样。基于这一前提,DCUAN采用类级对齐来通过区分集群识别公共类。因此,对每个特定故障模式执行聚类,以减少目标域和源域的聚类中心之间的距离。
对于目标域样本,由于缺乏特定的标签信息,本文采用K-means聚类算法将其分组为K个聚类,并获得相应的聚类中心。具体而言,对于目标域数据集,该算法根据不同样本之间的距离将所有样本划分为K个聚类。彼此更接近的样本将被分配给同一个簇,而来自不同簇的样本之间的距离将相对较大。为了找到合适的目标簇数K,本文选择不同的K进行多重聚类,然后根据域共识得分确定最佳簇数。这样,模型可以在没有标记样本的情况下实现类对齐。
由于同一故障模式的集群中心应该足够接近,DCUAN假设当两个集群的中心彼此最近时,它们属于同一个共同故障模式。这类配对被认为是达成阶级共识的集群。共识知识有助于模型将来自相同故障模式的集群关联起来,而不是单独识别每个样本。因此,挖掘样本级共识以确保该假设的有效性。
3. 样本级共识
由于目标标签空间的知识不可用,DCUAN在无监督聚类过程中嵌入了一种新的聚类评估标准,称为域共识分数。与针对单个领域问题设计的现有度量不同,领域共识得分通过挖掘样本级共识实现了跨领域的有效知识迁移。对于每个私有样本,DCUAN在另一个域中寻找最近的集群中心,类似于类级对齐。如果最近中心的类标签与配对集群的类标签一致,则达到样本级共识。通过计算达到共识的样本比例,DCUAN获得域共识分数,以确定最合适的聚类和目标类的准确数量。
对于源集群中的样本,DCUAN通过如下公式测量其与不同目标集群的相似性:
由此源共识得分计算过程如下:
以相同的方式获得目标共识分数。总体共识得分是所有关联集群对的平均得分。具体来说,DCUAN计算每个实例化的共识分数,并选择具有最高分数的实例化进行后续聚类。
4. 优化目标
为了确保聚类的合理性和提取特征的有效性,模型参数和聚类被交替优化。如果DCUAN在多轮优化中保持恒定值,则会修正参数U。H表示训练期间迭代更新的所有L2标准化目标集群中心。除了上述对比域差异外,本文还引入了正则化器来区分目标聚类:
在训练阶段,这些模型会不断迭代更新。τ是一个控制分布密度的超参数,在整个研究过程中根据经验设定为0.1。因为CDD是由再生核希尔伯特空间中分布的均值嵌入确定的,所以当样本数量足够时,它受标签噪声的影响较小。对于本工作中构建的一维CNN,该模型需要最小化多个完全5连接层上的CDD,以减少域差异和标签噪声的影响,如下所示:
DCUAN的损失函数由三项组成:
通常,目标聚类在多次迭代后收敛到最佳值。因此,简单地对Lreg应用恒定权重可能会导致簇间分离,从而阻碍收敛。为了解决这个问题,本文引入了γ的斜升函数γ。这种增量权重允许簇早期生长,同时防止饱和后吸收额外的私有样本。
在测试阶段,DCUAN在优化的特征空间中映射要诊断的目标样本,并计算样本与每个目标集群中心之间的距离M=[µt1,µt2,…,µtK]。如果最近的集群中心属于目标域的私有类,则模型输出“未知”。如果它属于公共类,则该模型输出与源集群对应的故障标签。
04
实验结果
EXPERIMENTS
实验结果
1. 仿真参数设置
图3 PT700数据集的采集设备和相应的故障模式
如图3所示,本文在两个数据集上进行了实验(CWRU数据集和PT700数据集),其中每个数据集都包含九个故障状态和一个健康状态,总共有十种模式。在仿真实验中,本文从这十种模式中设计了不同的域自适应场景,以验证所提出方法的有效性。具体而言,建立了几个不同的域自适应任务,包括CSDA、PDA、OSDA和UDA,以全面评估所提出的诊断模型。此外,还设置了几个不同规格的UDA任务来研究迁移效应。同时,随机选择每个任务的源和目标标签空间中包含的健康状态,以提高实验结果的准确性。具体参数设置如表1所示,每个故障模式包含200个样本,样本维数为1024,其中原始信号被划分为多个窗口。本文提出的DCUAN和比较模型采用了相同的参数设置。
表1 DCUAN中的参数设置
2. 结果与分析
DCUAN和比较方法在CWRU数据集上对任务C1-C7的诊断结果如图4所示,DCUAN获得的结果远远优于比较的方法。两个数据集的准确率均超过80%。对于任务C1(CSDA),所有方法的性能都十分优异,这表明了知识迁移的必要性。在任务C2(PDA)和C3(OSDA)中,IWAN和STA分别实现了最高的诊断精度,并抑制了由整体对齐分布引起的负面迁移的影响。
然而,DCUAN的表现几乎相同。此外,当处理与先验假设不一致的任务时,IWAN和STA的性能急剧下降。相比之下,DCUAN保持其高识别性能。与针对特定环境设计的PDA和OSDA方法不同,DCUAN促进正向迁移,而不需要对标签空间进行初步假设。
图4 DCUAN在CWRU数据集上的结果
此外。为了进一步验证DCUAN在实际工业诊断任务中的性能,还在PT700数据集上分析了每个算法的性能。PDA和OSDA任务的诊断结果列于表2中。OSDA任务计算诊断模型的ACC和HS。在PDA任务中,只计算模型的ACC,因为目标域没有私有类。在该实验中,DCUAN性能表现出不同程度的改进。与UAN和IWAN算法相比,后者是专门为PDA任务设计的,DCUAN获得了更高的诊断精度。这表明DCUAN有效地区分了已知故障模式和未知故障模式。
表2 CWRU数据集上任务M1-M6的诊断结果
如表3所示,在更适合用于实际应用的通用域自适应设置中,DCUAN在ACC和HS上的性能优于比较方法。对于任务M7-M9,具有完整的样本类和较小的任务跨度,尽管DCUAN在ACC方面难以弥补与UAN之间的差距,但在HS和识别私有样本的能力方面,它显著优于UAN。这说明DCUAN在公共样本和私有样本的识别之间实现了比UAN更高的平衡。任务M10-M12代表了更具挑战性的诊断场景。较低的标签通用性导致较大的域跨度,这意味着两个域之间的可用知识较少。因此,筛选无效信息的任务更加艰巨。此外,任务M10-M12中的私有类的数量远高于公共类,这测试了DCUAN对不同类样本的权衡。在这三个极端的情况下,DCUAN表现出更强的区分公共样本和私有样本的能力,与UAN相比,平均HS值增加了7.53%,这表明在特征映射后私有类中具有更高的紧凑性。
表3 CWRU数据集上任务M7-M12的诊断结果
除了上述实验外,本文还验证了DCUAN网络在不同SNR条件下的鲁棒性。采用MATLAB的agwn函数在原始样本中添加高斯白噪声。图5显示了在SNR为{10,-5,0,5,10,15,20}的范围内,上述方法的识别精度。可以看出,所有方法的性能都与SNR的值成正比,这意味着SNR越大,模型受影响越小。因此,可以观察到,当SNR大于10dB时,DCUAN很少受到高斯白噪声的影响。此外,在所有SNR情况下,DCUAN方法的性能都优于比较方法。这表明DCUAN的鲁棒性是目前最优的。
图5 不同信噪比下的精度对比
05
总结
CONCLUSION
总结
本文提出了一种新的通用域故障诊断方法(DCUAN),用于解决域偏移问题。鉴于现有算法仅关注公共样本的局限性,本文采用无监督聚类来指导模型从目标域自发提取内部诊断知识。此外,聚类匹配和域共识得分有助于模型同时从两个不同层次学习共识知识。因此,DCUAN可以识别共享故障模式中的样本,并对“未知”样本进行预分类。通过这种方式,DCUAN拥有较高的诊断精度,同时还降低了手动标记的成本。
然而,所提出的方法也有一定的局限性。在实际应用中,由于模型错误,目标健康状况可能被错误地识别为源域的私有类,这使得工业设备的故障排除更加困难。此外,DCUAN的另一个限制是类平衡样本的假设,因为不平衡数据将在分类器的标签预测结果中产生偏差。在现实的工业场景中,机器运行期间收集的数据集通常是不平衡的,这在基于DA的故障诊断中构成了不可忽视的挑战。在未来的工作中,将致力于解决这些问题,以便模型在实际应用中更好地工作。
END
扫描二维码关注我们
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh