![]()
This is the repo for the Stanford Alpaca project, which aims to build and share an instruction-following LLaMA model. The repo contains:
- A web demo to interact with our Alpaca model
- The 52K data used for fine-tuning the model
- The code for generating the data
Overview
The current Alpaca model is fine-tuned from a 7B LLaMA model [1] on 52K instruction-following data generated by the techniques in the Self-Instruct [2] paper, with some modifications that we discuss in the next section.
In a preliminary human evaluation, we found that the Alpaca 7B model behaves similarly to the text-davinci-003 model on the Self-Instruct instruction-following evaluation suite [2].
Alpaca is still under development, and there are many limitations that have to be addressed. Importantly, we have not yet fine-tuned the Alpaca model to be safe and harmless. We thus encourage users to be cautious when interacting with Alpaca, and to report any concerning behavior to help improve the safety and ethical considerations of the model.
Our initial release contains the data generation procedure, dataset, and training recipe. We intend to release the model weights if we are given permission to do so by the creators of LLaMA. For now, we have chosen to host a live demo to help readers better understand the capabilities and limits of Alpaca, as well as a way to help us better evaluate Alpaca's performance on a broader audience.
Please read our release blog post for more details about the model, our discussion of the potential harm and limitations of Alpaca models, and our thought process of an open-source release.
[1]: LLaMA: Open and Efficient Foundation Language Models. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. https://arxiv.org/abs/2302.13971v1
[2]: Self-Instruct: Aligning Language Model with Self Generated Instructions. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi. https://arxiv.org/abs/2212.10560
Data Release
alpaca_data.json contains 52K instruction-following data we used for fine-tuning the Alpaca model.
This JSON file is a list of dictionaries, each dictionary contains the following fields:
instruction:str, describes the task the model should perform. Each of the 52K instructions is unique.input:str, optional context or input for the task. For example, when the instruction is "Summarize the following article", the input is the article. Around 40% of the examples have an input.output:str, the answer to the instruction as generated bytext-davinci-003.
We used the following prompts for fine-tuning the Alpaca model:
- for examples with a non-empty input field:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
- for examples with an empty input field:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
Data Generation Process
Running the code
- Set environment variables
OPENAI_API_KEYto your OpenAI API key. - Install the dependencies with
pip install -r requirements.txt. - Run
python -m generate_instruction generate_instruction_following_datato generate the data.
We built on the data generation pipeline from self-instruct and made the following modifications:
- We used
text-davinci-003to generate the instruction data instead ofdavinci. - We wrote a new prompt (
prompt.txt) that explicitly gave the requirement of instruction generation totext-davinci-003. - We adopted much more aggressive batch decoding, i.e., generating 20 instructions at once, which significantly reduced the cost of data generation.
- We simplified the data generation pipeline by discarding the difference between classification and non-classification instructions.
- We only generated a single instance for each instruction, instead of 2 to 3 instances as in [1].
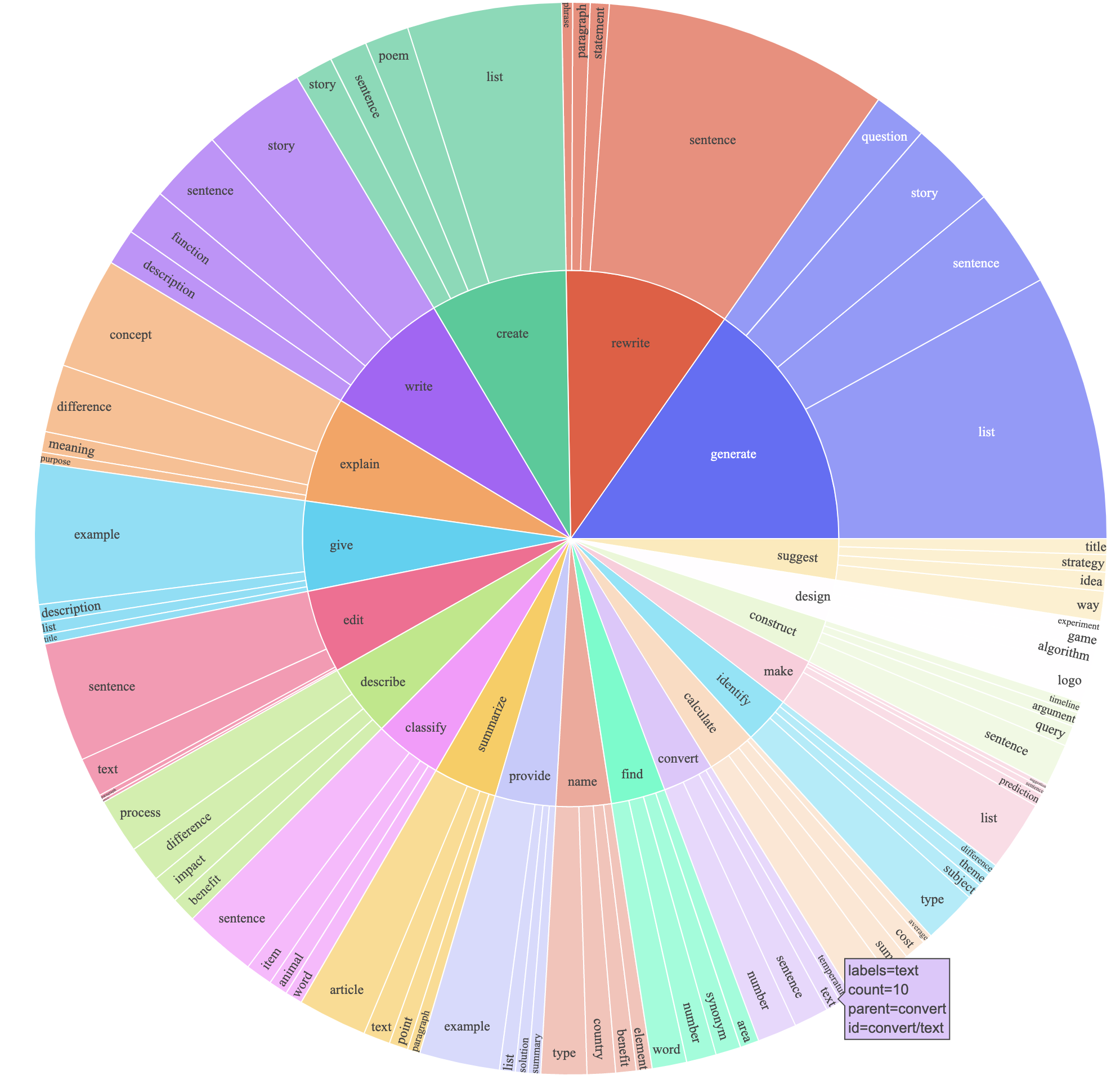
This produced an instruction-following dataset with 52K examples obtained at a much lower cost (less than $500). In a preliminary study, we also find our 52K generated data to be much more diverse than the data released by self-instruct. We plot the below figure (in the style of Figure 2 in the self-instruct paper to demonstrate the diversity of our data. The inner circle of the plot represents the root verb of the instructions, and the outer circle represents the direct objects.

Fine-tuning
We fine-tune our model using standard huggingface training code with the following hyperparameters:
| Hyperparameter | Value |
|---|---|
| Batch size | 128 |
| Learning rate | 2e-5 |
| Epochs | 3 |
| Max length | 512 |
| Weight decay | 1 |
We are waiting for huggingface to officially support the llama models (i.e. this PR to be merged) before we release a stable version of the finetuning code.
Authors
All grad students below contributed equally and the order is determined by random draw.
All advised by Tatsunori B. Hashimoto. Yann is also advised by Percy Liang and Xuechen is also advised by Carlos Guestrin.
Citation
Please cite the repo if you use the data or code in this repo.
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
}
Naturally, you should also cite the original LLaMA paper [1] and the Self-Instruct paper [2].
Acknowledgements
We thank Yizhong Wang for his help in explaining the data generation pipeline in Self-Instruct and providing the code for the parse analysis plot.