写在前面
这篇和上篇不同的是上篇更多关注于RFC文档规范的部分,而这篇更关注于如何从代码层面上的利用来绕过,具体内容请接着往下看
正文
tomcat
灵活的parseQuotedToken
继续看看这个解析value的函数,它有两个终止条件,一个是走到最后一个字符,另一个是遇到;
如果我们能灵活控制终止条件,那么waf引擎在此基础上还能不能继续准确识别呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| private String parseQuotedToken(final char[] terminators) {
char ch;
i1 = pos;
i2 = pos;
boolean quoted = false;
boolean charEscaped = false;
while (hasChar()) {
ch = chars[pos];
if (!quoted && isOneOf(ch, terminators)) {
break;
}
if (!charEscaped && ch == '"') {
quoted = !quoted;
}
charEscaped = (!charEscaped && ch == '\\');
i2++;
pos++;
}
return getToken(true);
}
|
如果你理解了上面的代码你就能构造出下面的例子

同时我们知道jsp如果带"符号也是可以访问到的,因此我们还可以构造出这样的例子

还能更复杂点么,当然可以的结合这里的\,以及上篇文章当中提到的org.apache.tomcat.util.http.parser.HttpParser#unquote中对出现\后参数的转化操作,这时候如果waf检测引擎当中是以最近""作为一对闭合的匹配,那么waf检测引擎可能会认为这里上传的文件名是y4tacker.txt\,从而放行

变形之双写filename*与filename
这个场景相对简单
首先tomcat的org.apache.catalina.core.ApplicationPart#getSubmittedFileName的场景下,文件上传解析header的过程当中,存在while循环会不断往后读取,最终会将key/value以Haspmap的形式保存,那么如果我们写多个那么就会对其覆盖,在这个场景下绕过waf引擎没有设计完善在同时出现两个filename的时候到底取第一个还是第二个还是都处理,这些差异性也可能导致出现一些新的场景
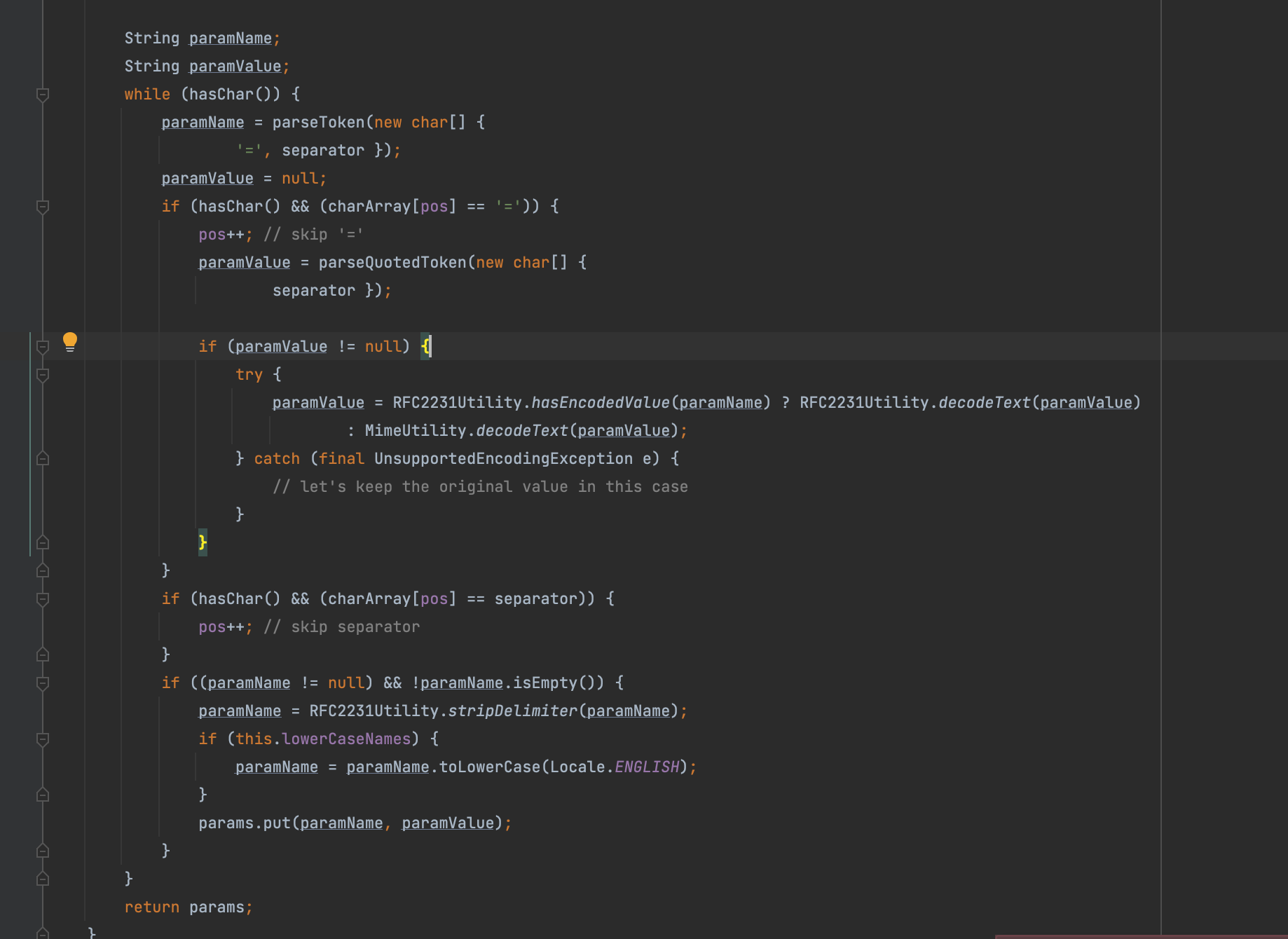
同时这里下面一方面会删除最后一个*
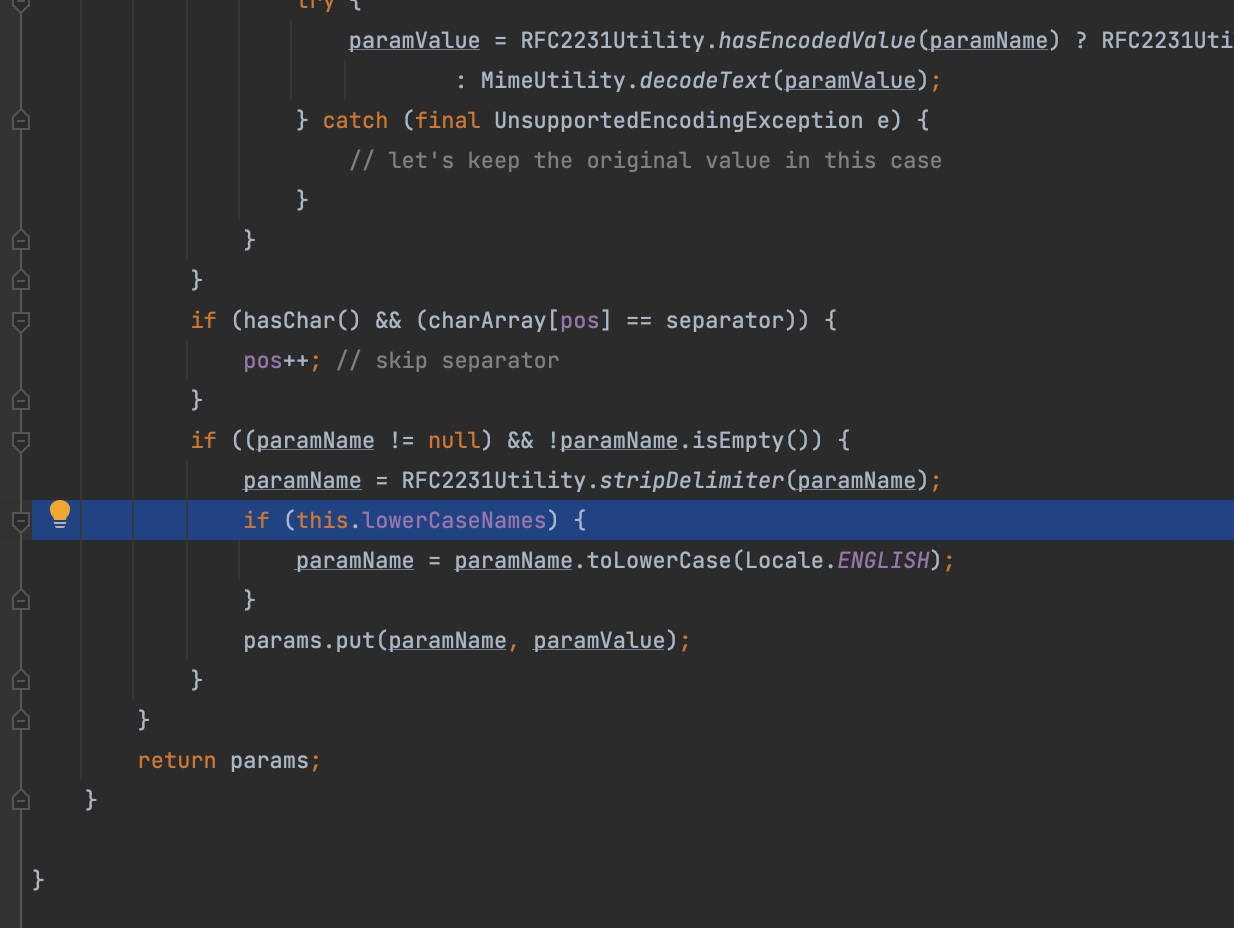
另一方面如果lowerCaseNames为true,那么参数名还会转为小写,恰好这里确实设置了这一点
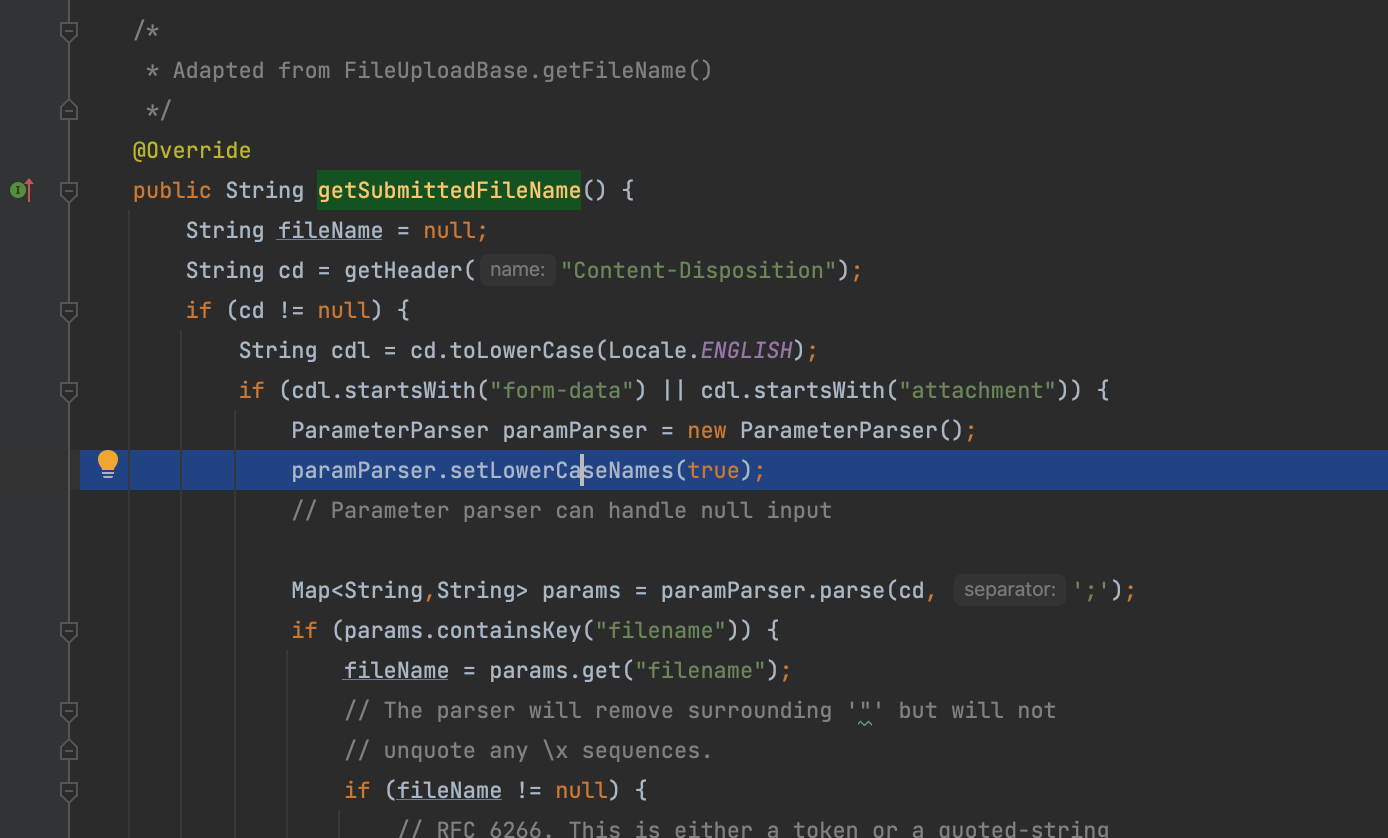
因此综合起来可以写出这样的payload,当然结合上篇还可以变得更多变这里不再讨论

变形之编码误用
假设这样一个场景,waf同时支持多个语言,也升级到了新版本会解析filename*,假设go当中有个编码叫y4,而java当中没有,waf为了效率将两个混合处理,这样会导致什么问题呢?

如果没有,这里报错后会保持原来的值,因此我认为这也可以作为一种绕过思路?
1
2
3
4
5
6
| try {
paramValue = RFC2231Utility.hasEncodedValue(paramName) ? RFC2231Utility.decodeText(paramValue)
: MimeUtility.decodeText(paramValue);
} catch (final UnsupportedEncodingException e) {
}
|
Spring4
这里我用了springboot1.5.20RELEASE+springframework4.3.23,这里不去研究小版本间是否有差异只看看大版本了
猜猜我在第几层
说个前提这里只针对单文件上传的情况,虽然这里的代码逻辑一眼看出不能有上面那种存在双写的问题,但是这里又有个更有趣的现象
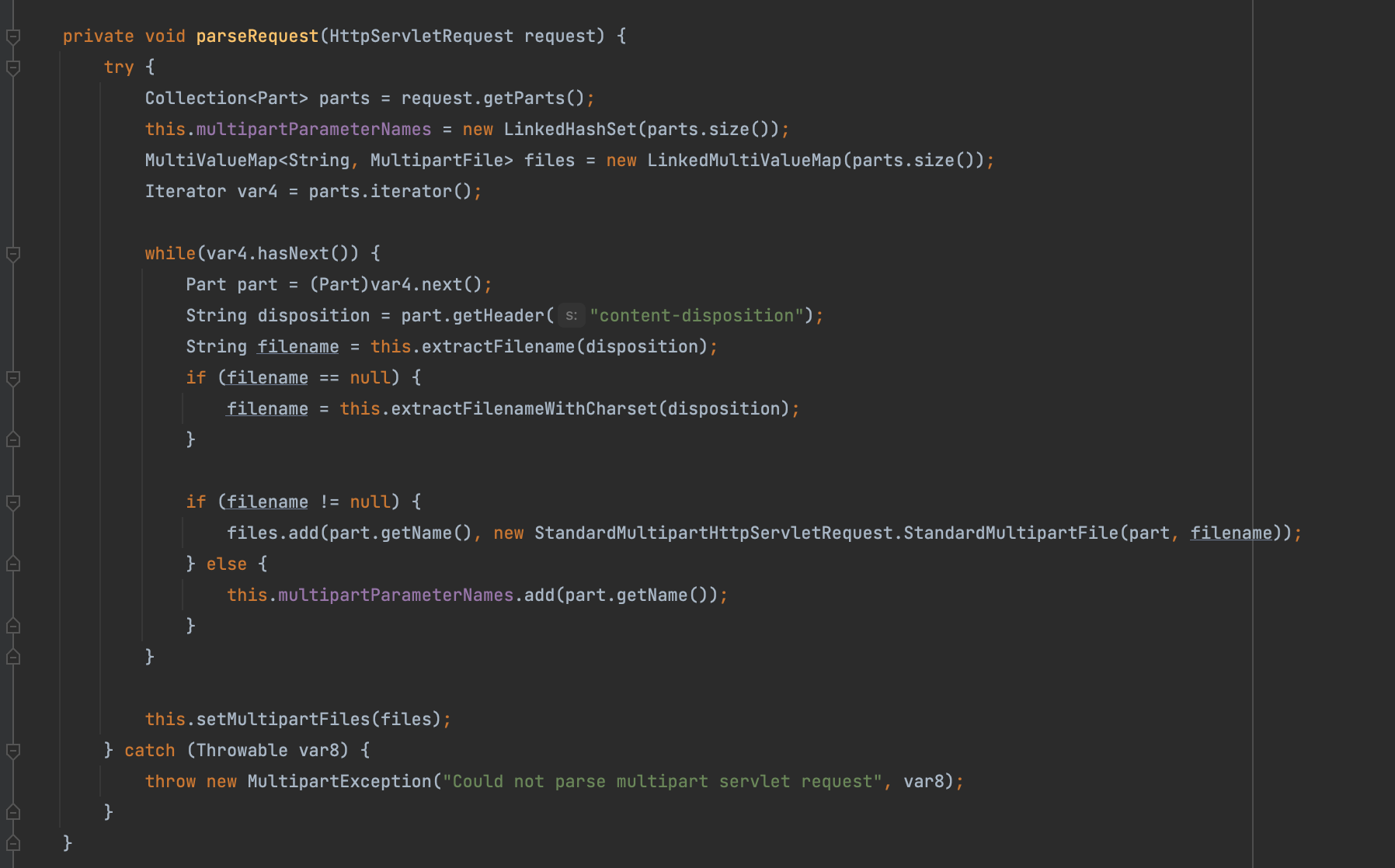
我们来看看这个extractFilename函数里面到底有啥骚操作吧,这里靠函数indexOf去定位key(filename=/filename*=)再做截取操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| private String extractFilename(String contentDisposition, String key) {
if (contentDisposition == null) {
return null;
} else {
int startIndex = contentDisposition.indexOf(key);
if (startIndex == -1) {
return null;
} else {
String filename = contentDisposition.substring(startIndex + key.length());
int endIndex;
if (filename.startsWith("\"")) {
endIndex = filename.indexOf("\"", 1);
if (endIndex != -1) {
return filename.substring(1, endIndex);
}
} else {
endIndex = filename.indexOf(";");
if (endIndex != -1) {
return filename.substring(0, endIndex);
}
}
return filename;
}
}
}
|
这时候你的反应应该会和我一样,套中套之waf你猜猜我是谁

当然我们也可以不要双引号,让waf哭去吧

Spring5
同样是springboot2.6.4+springframework5.3,这里不去研究小版本间是否有差异只看看大版本了
“双写”绕过
来看看核心部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| public static ContentDisposition parse(String contentDisposition) {
List<String> parts = tokenize(contentDisposition);
String type = (String)parts.get(0);
String name = null;
String filename = null;
Charset charset = null;
Long size = null;
ZonedDateTime creationDate = null;
ZonedDateTime modificationDate = null;
ZonedDateTime readDate = null;
for(int i = 1; i < parts.size(); ++i) {
String part = (String)parts.get(i);
int eqIndex = part.indexOf(61);
if (eqIndex == -1) {
throw new IllegalArgumentException("Invalid content disposition format");
}
String attribute = part.substring(0, eqIndex);
String value = part.startsWith("\"", eqIndex + 1) && part.endsWith("\"") ? part.substring(eqIndex + 2, part.length() - 1) : part.substring(eqIndex + 1);
if (attribute.equals("name")) {
name = value;
} else if (!attribute.equals("filename*")) {
if (attribute.equals("filename") && filename == null) {
if (value.startsWith("=?")) {
Matcher matcher = BASE64_ENCODED_PATTERN.matcher(value);
if (matcher.find()) {
String match1 = matcher.group(1);
String match2 = matcher.group(2);
filename = new String(Base64.getDecoder().decode(match2), Charset.forName(match1));
} else {
filename = value;
}
} else {
filename = value;
}
} else if (attribute.equals("size")) {
size = Long.parseLong(value);
} else if (attribute.equals("creation-date")) {
try {
creationDate = ZonedDateTime.parse(value, DateTimeFormatter.RFC_1123_DATE_TIME);
} catch (DateTimeParseException var20) {
}
} else if (attribute.equals("modification-date")) {
try {
modificationDate = ZonedDateTime.parse(value, DateTimeFormatter.RFC_1123_DATE_TIME);
} catch (DateTimeParseException var19) {
}
} else if (attribute.equals("read-date")) {
try {
readDate = ZonedDateTime.parse(value, DateTimeFormatter.RFC_1123_DATE_TIME);
} catch (DateTimeParseException var18) {
}
}
} else {
int idx1 = value.indexOf(39);
int idx2 = value.indexOf(39, idx1 + 1);
if (idx1 != -1 && idx2 != -1) {
charset = Charset.forName(value.substring(0, idx1).trim());
Assert.isTrue(StandardCharsets.UTF_8.equals(charset) || StandardCharsets.ISO_8859_1.equals(charset), "Charset should be UTF-8 or ISO-8859-1");
filename = decodeFilename(value.substring(idx2 + 1), charset);
} else {
filename = decodeFilename(value, StandardCharsets.US_ASCII);
}
}
}
return new ContentDisposition(type, name, filename, charset, size, creationDate, modificationDate, readDate);
}
|
spring5当中又和spring4逻辑有区别,导致我们又可以”双写”绕过(至于为什么我要打引号可以看看我代码中的注释),因此如果我们先传filename=xxx再传filename*=xxx,由于没有前面提到的filename == null的判断,造成可以覆盖filename的值

同样我们全用filename*也可以实现双写绕过,和上面一个道理

但由于这里indexof的条件变成了”=”号,而不像spring4那样的filename=/filename=*,毕竟indexof默认取第一个,造成不能像spring4那样做嵌套操作
