An incident response playbook is a predefined set of actions to address a specific security incident such as malware infection, violation of security policies, DDoS attack, etc. Its main goal is to enable a large enterprise security team to respond to cyberattacks in a timely and effective manner. Such playbooks help optimize the SOC processes, and are a major step forward to SOC maturity, but can be challenging for a company to develop. In this article, I want to share some insights on how to create the (almost) perfect playbook.
Imagine your company is under a phishing attack — the most common attack type. How many and what exact actions should the incident response team take to curb the attack? The first steps would be to find if an adversary is present and how the infrastructure had been penetrated (whether though an infected attachment or a compromised account using a fake website). Next, we want to investigate what is going on within the incident (whether the adversary persists using scheduled tasks or startup scripts) and execute containment measures to mitigate risks and reduce the damage caused by the attack. All these have to be done in a prompt, calculated and precise manner—with the precision of a chess grandmaster — because the stakes are high when it comes to technological interruptions, data leaks, reputational or financial losses.
Why defining your workflow is a vital prestage of playbook development
Depending on organization, the incident response process will comprise different phases. I will consider one of the most widespread NIST incident response life cycles relevant for most of the large industries — from oil and gas to the automotive sector.
The scheme includes four phases:
- preparation,
- detection and analysis,
- containment, eradication, and recovery,
- post-incident activity.
All the NIST cycles (or any other incident response workflows) can be broken down into “action blocks”. In turn, the latter can be combined depending on specific attack for a timely and efficient response. Every “action” is a simple instruction that an analyst or an automated script must follow in case of an attack. At Kaspersky, we describe an action as a building block of the form: <a subject> does <an action> on <an object> using <a tool>. This building block describes how a response team or an analyst (<a subject>) will perform a special action (<an action>) on a file, account, IP address, hash, registry key, etc. (<an object>) using systems with the functionality to perform that action (<a tool>).
Defining these actions at each phase of the company’s workflow helps to achieve consistency and create scalable and flexible scenarios, which can be promptly modified to accommodate changes in the infrastructure or any of the conditions.

An example of a common response action
1. Be prepared to process incidents
The first phase of any incident response playbook is devoted to the Preparation phase of the NIST incident response life cycle. Usually the preparation phase includes many different steps such as incident prevention, vulnerability management, user awareness, malware prevention, etc. I will focus on the step involving playbooks and incident response. Within this phase it is vital to define the alert field set and its visual representation. For the response team’s convenience, it is a good idea to prepare different field sets for each incident type.
A good practice before starting is to define the roles specific to the type of incident, as well as the escalation scenarios, and to dedicate the communication tools that will be used to contact the stakeholders (email, phone, instant messenger, SMS, etc.). Additionally, the response team has to be provided with adequate access to security and IT systems, analysis software and resources. For a timely response and to avoid human factor errors, automations and integrations need to be developed and implemented, that can be launched by the security orchestration, automation and response (SOAR) system.
2. Create a comfortable track for investigation
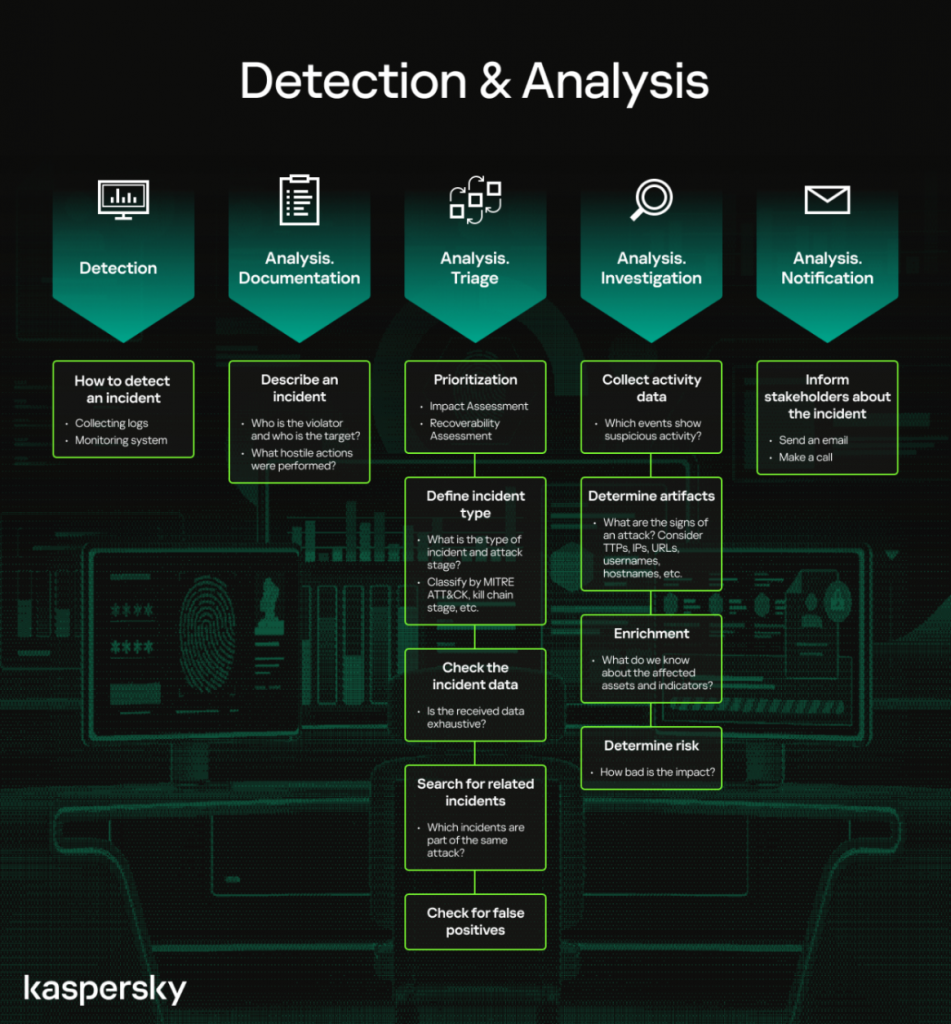
The next important phase is Detection that involves collecting data from IT systems, security tools, public information, and people inside and outside the organization, and identifying the precursors and indicators. The main thing to be done during this phase is configuring a monitoring system to detect specific incident types.
In the Analysis phase, I would like to highlight several blocks: documentation, triage, investigation, and notification. Documentation helps the team to define the fields for analysis and how to fill them once an incident is detected and registered in the incident management system. That done, the response team moves on to triage to perform incident prioritization, categorization, false positive checks, and searches for related incidents. The analyst must be sure that the collected incident data comply with the rules configured for detection of specific suspicious behavior. If the incident data and rule/policy logic mismatch, the incident may be tagged as a false positive.
The main part of the analysis phase is investigation, which comprises logging, assets and artifact enrichment, and incident scope forming. When in research mode, the analyst should be able to collect all the data about the incident to identify patient zero and the entry point — knowing how unauthorized access was obtained and which host/account had been compromised first. It is important because it helps to properly contain the cyberattack and prevent similar ones in the future. By collecting incident data one gets information about specific objects (assets and artifacts such as hostname, IP address, file hash, URL, and so on) relating to the incident, so one can extend the incident scope by them.
Once the incident scope is extended, the analyst can enrich assets and artifacts using the data from Threat Intelligence resources or a local system featuring inventory information, such as Active Directory, IDM, or CMDB. Based on the information on the affected assets, the response team can measure the risk to make the right choice of further actions. Everything depends of how many hosts, users, systems, business processes, or customers have been affected, and there are several ways to escalate the incident. For a medium risk, only the SOC manager and certain administrators must be notified to contain the incident and resolve the issue. In a critical risk case, however, the crisis team, HR department, or the regulatory authority must be notified by the response team.
The last component of the analysis phase is notification, meaning that every stakeholder must be notified of the incident in timely manner, so the system owner can step in with effective containment and recovery measures.

Detection and Analysis phase actions to analyze the incident
3. Containment is one of the most important phases to minimize incident consequences
The following big part consists of Containment, Eradication and Recovery phases. The main goal of containment is to keep the situation under control after an incident has occurred. Based on incident severity and possible damage caused, the response team should know the proper set of containment measures.
Following the prestage where workflows had been defined, we now have a list of different object types and possible actions that can be completed using our tool stack. So, with a list of actions in hand, we just want to choose proper measures based on impact. This stage mostly defines the final damage: the smoother and more precise the actions the playbook suggests for this phase, the prompter will be our response to block the destructive activity and minimize the consequences. During the containment process, the analyst performs a number of different actions: deletes malicious files, prevents their execution, performs network host isolation, disables accounts, scans disks with the help of security software, and more.
The eradication and recovery phases are similar and consist of procedures meant to put the system back into operation. The eradication procedures include cleaning up all traces of the attack—such as malicious files, created scheduled tasks and services—and depend on what traces were left following the intrusion. During the recovery process, the response team should simply adopt a ‘business as usual’ stance. Just as the eradication, the recovery phase is optional, because not every incident impacts the infrastructure. Within this phase we perform certain health check procedures and revoke changes that had been made during the attack.

Incident containment steps and recovery measures
4. Lessons learned, or required post-incident actions
The last playbook phase is Post-incident activity, or Lesson learning. The phase is focused on how to improve the process. To simplify this task, we can define a set of questions to be answered by the incident response team. For example:
- How well did the incident response team manage the incident?
- What information was the first to be required?
- Could the team have done a better job sharing the information with other organizations/departments?
- What could the team do differently next time if the same incident occurred?
- What additional tools or resources are needed to help prevent or mitigate similar incidents?
- Were there any wrong actions that had caused damage or inhibited recovery?
Answering these questions will enable the response team to update the knowledge base, improve the detection and prevention mechanism, and adjust the next response plan.
Summary: components of a good playbook
To develop a cybersecurity incident response playbook, we need to figure out the incident management process with focus on phases. As we go deeper into the details, we look for tools/systems to help us with the detection, investigation, containment, eradication, and recovery phases. Once we know our set of tools, we can define the actions that can be performed:
- logging;
- enriching the inventory information or telemetry of affected assets or reputation of external resources;
- incident containment through host isolation, preventing malicious file execution, URL blocking, termination of active sessions, or disabling of accounts;
- cleaning up the traces of intrusion by deleting remote files, deleting suspicious services, or scheduled tasks;
- recovering the system’s operational state by revoking changes;
- formalizing lessons learned by creating a new article in the local knowledge base for later reference.
Additionally, we want to define responsibilities within the response team, for each team member must know what his or her mission-critical role is. Once the preparation is done, we can begin developing the procedures that will form the playbook. As a common rule, every procedure or playbook building block looks like “<a subject> does <an action> on <an object> using <a tool>”—and now that all subjects, actions, objects, and tools have been defined, it is pretty easy to combine them to create procedures and design the playbook. And of course, keep in mind and stick to your response plan and its phases.
如有侵权请联系:admin#unsafe.sh