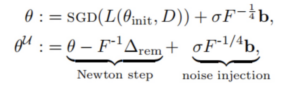
阅读: 22
随着机器学习模型在各类产品中的落地与应用,Machine learning逐渐成为人们生活中耳熟能详的概念。Machine learning学习数据中的规律,模型会“记住”训练集中的数据,但对已经训练完成的模型,如果需要删除训练集中的某些数据,要求模型“遗忘”特定数据,可不像从数据库中删除数据那样容易。“让模型有效遗忘指定训练数据”就是Machine unlearning(机器遗忘)在解决的问题。也就是说,Machine unlearning是一种保护用户数据隐私的方式。
一、概述
2018年生效的GDPR(欧盟通用数据保护条例)中,第17条立法规定用户享有“被遗忘权”(Right to be forgotten),当用户要求企业清楚和停止传播个人的隐私信息时,企业应当采取合理的措施,及时销毁用户的个人数据,否则将面临巨额处罚。GDPR的实行引起了企业对机器学习领域数据隐私保护合规性的重视。
机器学习模型对数据有很强的依赖性,机器学习模型需要基于大量的用户数据进行训练和分析,以满足企业业务上的需求。如果某个用户在分享了自己的数据后,出于隐私或其他考虑,想要删除数据并让模型遗忘自己的数据,是非常困难的。以ChatGPT这类大型商业模型为例,官方为用户提供了删除个人数据的渠道,但对用户来说ChatGPT是个黑盒模型,很难去验证模型是否真的彻底遗忘了自己的数据;对OpenAI来说,大多情况下要删除的信息量很小,而ChatGPT这样的大型AI系统拥有海量训练数据和千亿级参数,面对用户频繁的删除请求,采取重新训练整个模型的方案会消耗高额资源。
Machine unlearning概念的提出就是为了解决这种困境。不同于简单的“在训练集中删除指定数据并重新训练模型”的方案,Machine unlearning为模型拥有者提供新的训练思路,既能降低训练的计算和时间开销,也保障遗忘指定数据前后模型的表现相同。
本文对Machine unlearning的两个经典方案与适用场景进行简单的介绍。
二、方案
2.1 SISA
SISA指“Sharded、Isolated、Sliced and Aggregated training”,利用数据集划分和分布式训练的思想完成遗忘学习,加速模型的重训练。

图 1 SISA方案
- Sharding:将训练集D分成不相交的shards,确保每个训练数据仅处在一个shard内。
- Isolation:用每个shard的数据分别训练出一个子模型。
- Slicing:对每个shard内部的数据,进一步分成不相交的slices。从第一个slice开始,逐步向后增加一个slice构成新的数据集并训练子模型,保存每一步得到的模型参数。
- Aggregation:最终聚合slices所有子模型的预测结果并输出。
这种分布式训练方式仅需要重训练包含指定遗忘数据的子模型。当某个数据需要被遗忘时,找到该数据所在的shard,并在不包含该数据所属slice的最后保存的模型参数上,继续重训练该shard的子模型即可。
SISA是一种精确遗忘方案,在遗忘效果上与重新训练模型的方案持平,提供较强的隐私保障。但SISA需要重训练模型,不仅带来了额外的存储成本,还会为了训练效率损失一定的模型精度。
2.2 Fisher forgetting
基于Fisher的遗忘方案通过Newton correction和噪声注入进行遗忘。
如果原始模型与执行遗忘后的模型,其输出的概率分布之间的KL散度为0,可以认为模型对指定信息完成了完全遗忘。基于Fisher的方案在指定数据之外的训练数据上执行单次Newton step,并在其方向上添加高斯扰动,更新模型参数,达到最小化KL散度的目标。

基于Fisher的方案是一种近似遗忘方案,这类方案在遗忘目标上引入松弛,无需完整的再训练过程,最终模型与重新训练的模型在表现上保有较高近似度。一般来说近似遗忘方案的效率较精确遗忘更高。
三、适用场景
Machine unlearning可以用于这些场景:
1、助力企业满足合规政策。从GDPR、CCPA、PIPEDA到我国的《个人信息保护法》、《个人信息安全规范》,国内外在不断规范企业对用户隐私数据的使用权,企业可以借助Machine Unlearning满足合规性要求。
2、抵御对抗攻击。如果一个模型已经完成训练,但检测到其训练集中存在对抗样本,Machine unlearning可以帮助模型从对抗样本的影响中恢复。
3、优化模型表现。训练模型时往往会收集很多公开的数据,可能会出现训练数据不均衡、数据质量参差不齐等问题导致模型出现歧视行为,Machine Unlearning可以协助模型进行优化。
4、缓解模型的“过度学习”(Overlearning)。当模型学习到了训练数据在任务目标之外的属性、特征或一些敏感信息时,模型被认为进行了过度学习。过度学习的模型会暴露训练数据的潜在特征,提供数据的用户可能会因此提出遗忘数据的需求,这种情况下模型提供者需要依靠Machine unlearning。
四、局限
作为保护用户隐私方案的Machine unlearning,也可能给攻击者提供隐私窃取的机会。Gao等人发现应用了Machine unlearning的模型更易受到隐私攻击,攻击者能访问到遗忘数据前后的模型,借此推理出被遗忘数据的信息。
另外,Machine unlearning算法自身也可能受到攻击。Marchant等人指出Machine unlearning为模型引入了新的攻击面,并通过投毒攻击降低遗忘算法的运行效率,消除了Machine unlearning相较于重新训练的优势。
因此,决定采用Machine unlearning的同时,也需要综合考虑正则化、对抗训练等方案保障模型的鲁棒性。
参考文献
[1] Mercuri S, Khraishi R, Okhrati R, et al. An Introduction to Machine Unlearning[J]. arXiv preprint arXiv:2209.00939, 2022.
[2] Golatkar A, Achille A, Soatto S. Eternal sunshine of the spotless net: Selective forgetting in deep networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9304-9312.
[3] Bourtoule L, Chandrasekaran V, Choquette-Choo C A, et al. Machine unlearning[C]//2021 IEEE Symposium on Security and Privacy (SP). IEEE, 2021: 141-159.
[4] Gao J, Garg S, Mahmoody M, et al. Deletion inference, reconstruction, and compliance in machine (un) learning[J]. arXiv preprint arXiv:2202.03460, 2022.
[5] Marchant N G, Rubinstein B I P, Alfeld S. Hard to forget: Poisoning attacks on certified machine unlearning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2022, 36(7): 7691-7700.
[6] Song C, Shmatikov V. Overlearning reveals sensitive attributes[J]. arXiv preprint arXiv:1905.11742, 2019.
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。