
Loading...

Cloudflare serves a huge amount of traffic: 45 million HTTP requests per second on average (as of 2023; 61 million at peak) from more than 285 cities in over 100 countries. What inevitably happens with that kind of scale is that software will be pushed to its limits. As we grew, one of the problems we faced was related to deploying our code. Sometimes, a release would be delayed because of inadequate hardware resources on our servers. Buying more and more hardware is expensive and there are limits to e.g. how much memory we can realistically have on a server. In this article, we explain how we optimised our software and its release process so that no additional resources are needed.
In order to handle traffic, each of our servers runs a set of specialised proxies. Historically, they were based on NGINX, but increasingly they include services created in Rust. Out of our proxy applications, FL (Front Line) is the oldest and still has a broad set of responsibilities.
At its core, it’s one of the last uses of NGINX at Cloudflare. It contains a large amount of business logic that runs many Cloudflare products, using a variety of Lua and Rust libraries. As a result, it consumes a large amount of system resources: up to 50-60 GiB of RAM. As FL grew, it became more and more difficult to release it. The upgrade mechanism requires double the memory (which sometimes is not available) than at runtime. This was causing delays in releases. We have now improved the release procedure of FL, and in effect, removed the need for additional memory during the release process, improving its speed and performance.
Architecture
To accomplish all of its work, each FL instance runs many workers (individual processes). By design, individual processes handle requests while the master process controls them and makes sure they stay up. This allows NGINX to handle more traffic by adding more workers. We take advantage of this architecture.
The number of workers depends on the numbers of total CPU cores present. It’s typically equal to half of the CPU cores available, e.g. on a 128-core CPU we use 64 FL workers.
So far so good, what's the problem then?
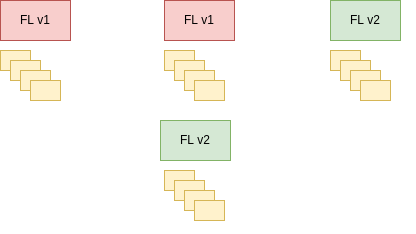
We aim to deploy code in a way that’s transparent to our customers. We want to continue serving requests without interruptions. In practice, this means briefly running both versions of FL at the same time during the upgrade, so that we can flawlessly transition from one version to another. As soon as the new instance is up and running, we begin to shut down the old one, giving it some time to finish its work. In the end, only the new version is left running. NGINX implements this procedure and FL makes use of it.
After a new version of FL is installed on a server, the upgrade procedure starts. NGINX’s implementation revolves around communicating with the master process using signals. The upgrade process starts by sending the USR2 signal which will start the new master process and its workers.
At that point, as can be seen below, both versions will be running and processing requests. The unfortunate side effect of this is the memory footprint has been doubled.
PID PPID COMMAND
33126 1 nginx: master process /usr/local/nginx/sbin/nginx
33134 33126 nginx: worker process (nginx)
33135 33126 nginx: worker process (nginx)
33136 33126 nginx: worker process (nginx)
36264 33126 nginx: master process /usr/local/nginx/sbin/nginx
36265 36264 nginx: worker process (nginx)
36266 36264 nginx: worker process (nginx)
36267 36264 nginx: worker process (nginx)
Then, the WINCH signal will be sent to the master process which will then ask its workers to gracefully shut down. Eventually, they will all quit, leaving just the original master process running (which can be shut down with the QUIT signal). The successful outcome of this will leave just the new instance running, which will look similar to this:
PID PPID COMMAND
36264 1 nginx: master process /usr/local/nginx/sbin/nginx
36265 36264 nginx: worker process (nginx)
36266 36264 nginx: worker process (nginx)
36267 36264 nginx: worker process (nginx)
The standard NGINX upgrade mechanism is visualised in this diagram:
It’s also clearly visible in the memory usage graph below (notice the large bump during the upgrade).
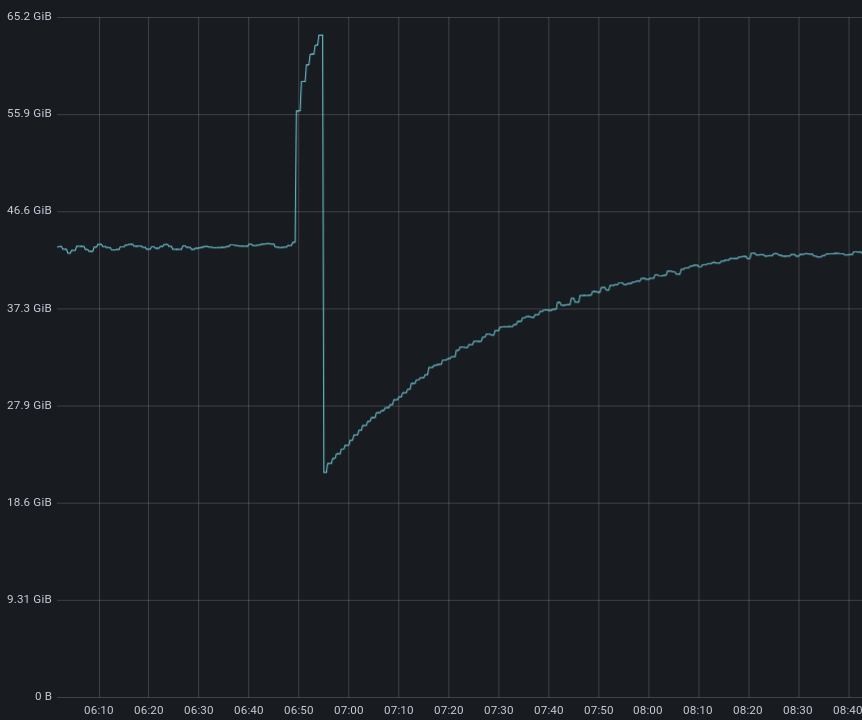
The mechanism outlined above has both versions running at the same time for a while. When both sets of workers are running, they are still sharing the same sockets, so all of them accept requests. As the release progresses, ‘old’ workers stop listening and accepting new requests (at that point only the new workers accept new requests). As we release new code multiple times per week, this process is effectively doubling up our memory requirements. At our scale, it’s easy to see how multiplying this event by the number of servers we operate results in an immense waste of memory resources.
In addition, sometimes servers would take hours to upgrade (a concern especially when we need to release something quickly), as we are waiting to have enough memory available to kick off the reload action.
New upgrade mechanism
We solved this problem by modifying NGINX's method for upgrading executable. Here's how it works.
The crux of the problem is that NGINX treats the entire instance (master + workers) as one. When upgrading, we need to start all the workers whilst all the previous ones are still running. Considering the number of workers we use and how heavy they are, this is not sustainable.
So, instead, we modified NGINX to be able to control individual workers. Rather than starting and stopping them all at once, we can do so by selecting them individually. To accomplish this, the master process and workers understand additional signals compared to the ones NGINX uses. The actual mechanism to accomplish this in NGINX is nearly the same as when handling workers in bulk. However, there’s a crucial difference.
Typically, NGINX's master process ensures that the right number of workers is actually running (per configuration). If any of them crashes, it will be restarted. This is good, but it doesn't work for our new upgrade mechanism because when we need to shut down a single worker, we don't want the NGINX master process to think that a worker has crashed and needs to be restarted. So we introduced a signal to disable that behaviour in NGINX while we're shutting down a single process.
Step by step
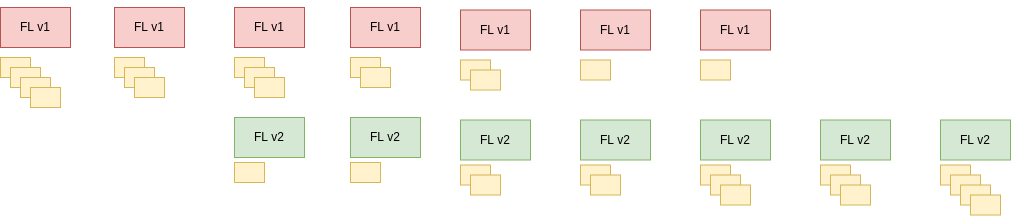
Our improved mechanism handles each worker individually. Here are the steps:
- At the beginning, we have an instance of FL running 64 workers.
- Disable the feature to automatically restart workers which exit.
- Shut down a worker from the first (old) instance of FL. We're down to 63 workers.
- Create a new instance of FL but only with a single worker. We're back to 64 workers but including one from the new version.
- Re-enable the feature to automatically restart worker processes which exit.
- We continue this pattern of shutting down a worker from an older instance and creating a new one to replace it. This can be visualised in the diagram below.
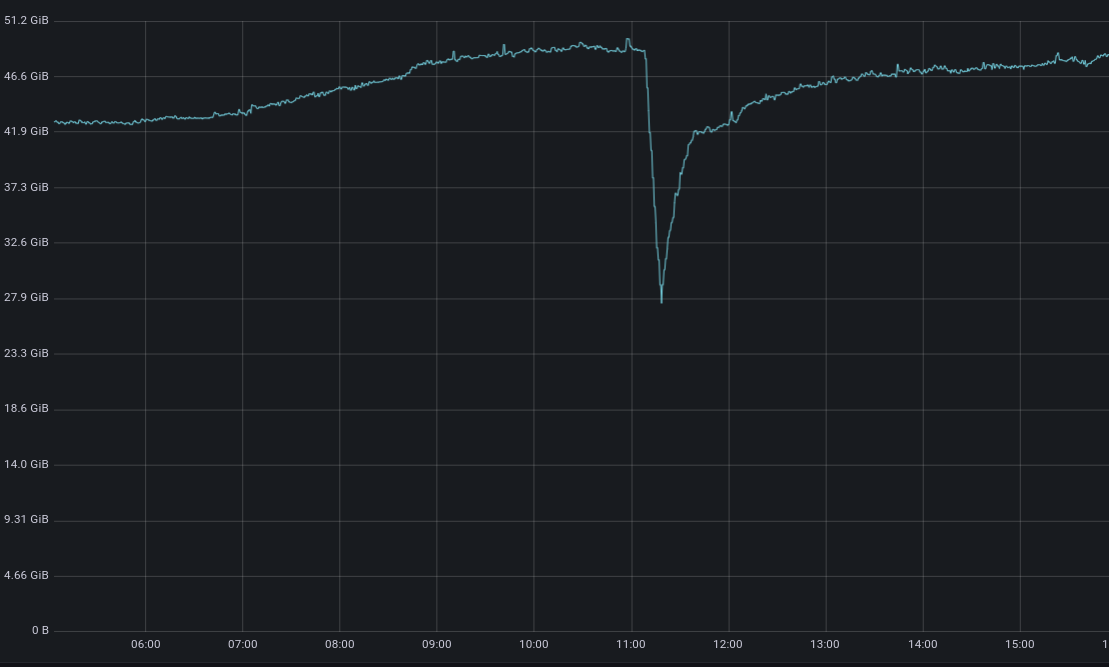
We can observe our new mechanism in action in the graph below. Thanks to our new procedure, our use of memory remains stable during the release.
But why do we begin by shutting down a worker belonging to an older instance (v1)? This turns out to be important.
Worker-CPU pinning
During this workflow, we also had to take care of CPU pinning. FL workers on our servers are pinned to CPU cores with one process occupying one CPU core to help us distribute resources more efficiently. If we start a new worker first, it will share the CPU core with another one for a brief amount of time. This will make one CPU overloaded compared to other ones running FL, impacting the latency for requests served. That's why we start by freeing up a CPU core which then can be taken over by a new worker rather than starting by creating a new worker.
For the same reason, pinning of worker processes to cores must be maintained throughout the whole operation. At no point, we can have two different workers sharing a CPU core. We make sure this is the case by executing the whole procedure in the same order every time.
We start from CPU core 1 (or whichever is the first one used by FL) and do the following:
- Shut down a worker that's running there.
- Create a new worker. NGINX will pin it to the CPU core we have freed up in the previous step.
After doing that for all workers, we end up with a new set of workers which are correctly pinned to their CPU cores.
Conclusion
At Cloudflare, we need to release new software multiple times per day across our fleet. Standard upgrade mechanism used by NGINX is not suitable at our scale. For this reason, we customised the process to avoid increasing the amount of memory needed to release FL. This enabled us to safely ship code whenever it's needed, everywhere. The custom upgrade mechanism enables us to release a large application such as FL reliably regardless of how much memory we have available on an edge server. We showed that it’s possible to extend NGINX and its built-in upgrade mechanism to accommodate the unique requirements of Cloudflare.
If you enjoy solving challenging application infrastructure problems and want to help maintain the busiest web server in the world, we’re hiring!
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.