团队科研成果分享2023.03.27-2023.04.02标题: 基于多元区域集划分的工业数据流概念漂移检测期刊: 电子学报, 2023.作者: 韩光洁,赵腾飞,刘立,张帆,徐政伟.分享人: 河海大学 2023-4-2 17:24:7 Author: 网络与安全实验室(查看原文) 阅读量:48 收藏
团队科研成果分享
2023.03.27-2023.04.02
标题: 基于多元区域集划分的工业数据流概念漂移检测
期刊: 电子学报, 2023.
作者: 韩光洁,赵腾飞,刘立,张帆,徐政伟.
分享人: 河海大学——赵腾飞
01
研究背景
BACKGROUND
研究背景
近年来,工业产业系统正加速推动由自动化向智能化的转型升级。在智能化转型进程中,数据驱动的机器学习算法展现出了巨大的潜力。然而,在现代工业环境下,设备生成数据的环境会随时间发生变化,导致底层分布在实际应用中不稳定,这种由潜在因素影响而导致的目标概念发生改变的现象称为概念漂移,如图1所示。当工业设备运行中工况的变化使得数据流中的潜在数据分布随时间发生不可预测的改变时,嵌入式系统软件中原先运行的故障诊断算法就会失效,需要嵌入式系统快速检测到这种工况变化,迅速更新原先的AI模型。
图1 工业数据流中的概念漂移
目前,对于工业控制这类时间敏感系统而言,在相关的嵌入式软件中部署时间敏感的工业数据概念漂移检测模块是保证嵌入式系统安全的重要一环。如何对时间敏感的工业系统做出快速响应并进行嵌入式系统的实时更新,仍然是一个具有挑战性的问题。
02
关键技术
TECHNOLOGY
关键技术
本文提出了一种基于多元区域集划分的工业数据流概念漂移检测算法CDMP,区别于传统的以数据实例为抓手进行概念漂移检测的算法,CDMP聚焦于数据实例对标的多元区域集,通过对多元区域集的自适应与更新,来实现对概念漂移区域的更新与维护。同时,不再孤立看待概念漂移引起的模型更新,而是保留不同概念分布下生成的历史模型,当概念漂移发生时,重用一组特定的历史模型,通过历史模型集成实现对新概念的适应。实验结果表明,CDMP实现了对历史模型多样性的保留和重用,能够在不同噪声水平的工业物联网环境中实现对重现型、突发型等多类型概念漂移的准确检测。
该方法的创新和贡献如下:
1)基于密度峰值聚类算法提出对工业数据实例实行在线模糊区域划分的分区机制,保留了历史数据的多样性,提高了概念漂移检测的准确性和泛化性。
2)从数据实例到达多元区域集的统计学角度出发,设定缓冲区对当前区域集的概念漂移做出自适应更新,使概念漂移场景下数据实例分区得到快速响应,并对持续发生的概念漂移进行实时检测与在线更新。
3)设计一种新的多元历史模型池构建与更新机制,通过历史模型池多样性保留策略和模型价值度量机制,降低了模型再训练造成的性能及时间消耗,保证了模型的分类性能,实现了工业场景下不同类型概念漂移的集成检测。
03
算法介绍
ALGORITHMS
算法介绍
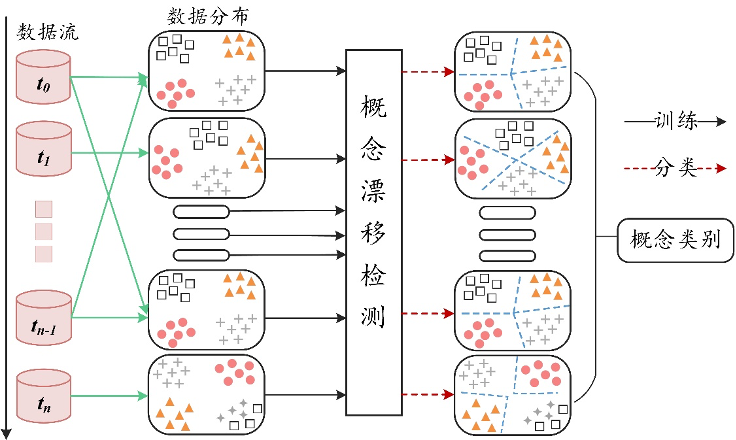
该算法主要分为三个阶段,分别为多元区域集划分阶段、历史模型池构建阶段和概念漂移检测阶段,算法的整体框架图如图2所示。
图2 算法框架图
CDMP首先将数据流中的数据实例基于实例模糊密度划分成若干模糊分区集合。随后,针对划分的多元区域进行概念漂移区域识别,实现概念漂移检测的数据检索,使得基于多元区域集中数据实例构建的机器学习模型能够解析实例各部分的空间特征。多元区域划分的整体结构如图3所示。
图3 多元区域集分区框架图
(1)基于集成学习策略的概念漂移检测与自适应
CDMP将模糊算子引入到密度峰值聚类算法DPC中,利用模糊计算中的模糊性和不确定性,解决实例的模糊分区问题。CDMP将密度峰值看作特殊的模糊峰值,即将模糊算子作用于数据实例对应的隶属度函数而获得的模糊耦合的结果,以解决区域划分过程中的歧义和不确定性。
本文还通过引入丰富的模糊算子来解决数据的不确定性以完成数据集的模糊分区。由于非参数型模糊算子Zadeh和Product在模糊集合合并时隶属度不会发生变化,而参数型的模糊算子引入了参数ω,通过控制隶属度来达到控制模糊集合权重的作用,这种方式可以在模糊计算中提供更多的灵活性。因此,CDMP算法引入其中一种参数型模糊算子Hamacher-S模算子,具体计算公式如下:
其中a,b代表不同的模糊集合,ω为权重参数。
多元区域集的划分方法是基于密度峰值来计算的,其区域中心均局部密度较大,并且距离其他较大密度点的距离较远。实际情况下,若一个数据集中有多个密度峰值点且其分布相似时,选择合适的区域中心变得较为困难,为避免选择噪声作为区域中心,CDMP计算出距离所有数据最近的较大密度实例的距离的标准偏差,该标准偏差用作统计分布的度量,并且在一定程度上反映了数据的分散程度。然后,考虑选择离最近大密度实例的距离大于或者等于加权标准偏差的实例作为区域中心。区域中心EC和去除噪声中心的区域中心RC的确定方式如下:
其中δi是距最近的较大密度实例的距离,σ(δi)是距离所有较大密度实例的距离的标准偏差,λ为权重,ρi为局部密度,μ(ρi)是所有局部密度的平均值。
考虑工业数据流中因噪声干扰易出现离群值的情况,CDMP在计算每个数据实例的密度值后,将与最近高密度实例距离较远,但其局部密度小的实例看作离群值噪声,设置阈值参数将其去除,以实现降噪的目的。
在完成上述的模糊分区后,可以构建出一个基于实例模糊密度峰值的多元区域集合。然而,随着数据流的持续到达,现有的概念漂移区域识别更新机制对如何适应可能发生的概念漂移,以及如何解决区域集的持续更新仍是一项具有挑战的问题。概念漂移场景下,算法需要持续、在线的对漂移区域保持更新和维护,这种方式并不能保证多元区域集在不同类型概念漂移场景下的自适应性。
为了实现多元区域集的在线更新,CDMP从数据实例到达多元区域集的统计学角度出发,通过设定缓冲区完成当前区域集对概念漂移的自适应更新,使概念漂移场景下数据实例分区得到快速响应的同时对漂移区域做出精确识别进而完成区域的更新。
(2)基于多元历史模型池的概念漂移检测
CDMP通过模糊分区机制构建出多元区域集,从数据实例的角度支持模型的多样性,应用区域识别算法对概念漂移区域做出自适应的识别与更新。然而,当数据流中出现新的概念或发生概念漂移时,每次都进行多元区域集模型的重建与更新,无疑会增加网络能耗与计算复杂度,且先前已经构建的多元区域集模型中的相同概念将被重复学习,历史模型没有得到有效利用。因此,本文提出了一种新的多元历史模型池构建与更新机制,通过历史模型池多样性保留策略和模型价值度量机制,降低模型再训练造成的性能及时间消耗,并保证模型的分类性能,实现工业场景下不同类型概念漂移的集成检测。多元区域的建模整体框架如图4所示。
图4 多元区域集建模示意图
CDMP采用集成学习的方法对历史模型池进行构建。集成学习通过构建并结合多个学习器来完成学习任务,随机森林(Random Forest)算法不仅可以判断特征的重要程度,还可以判断不同特征之间的相互影响,增加了学习的特征的数量。CDMP采用基于Hoeffding树构建随机森林基础模型,采取在线重采样的方式,选择较大的特征数量去分割构建决策树,构建过程中倾向于生成更深的树。然后在构建的随机森林中对保留了多样性的模型进行训练,将得到的模型不断加入到历史模型池中。因此,CDMP算法采用随机森林作为集成策略去进行概念漂移的预测,通过随机森林保留有价值的历史模型,存储旧概念,以进行概念漂移检测。
图5为历史模型池多样性保留策略示意图,图中模型分别用f1,f2,…,fM表示,最大模型数量为M,在模型未到达预设的模型池最大模型数量M时,模型将会直接加入历史模型池;当模型池数量达最大值M后,将会对模型池中多样性进行计算,淘汰多样性最差的模型,并通过不断反馈所获得的模型价值度量标椎对历史模型池进行更新,以保证历史模型池中各模型均具有显著代表性。
图5 历史模型池多样性保留模块
在完成随机森林模型构建和历史模型池构建之后,使用警告检测参数δω和实际漂移检测参数δd来进行概念漂移检测。CDMP使用经典方法ADWIN[11]作为漂移检测器,对于ADWIN,δω和δd分别对应于警告和实际漂移的置信度。在检测到概念漂移警告级别时将会进行区域集更新并训练新的背景树以准备概念漂移的集成预测。当达到发生实际概念漂移级别的阈值时,将会对模型的价值进行重新度量,并选择最具代表性的历史模型在集成决策中使用。
图6 模型价值度量机制
如图6为算法中模型的价值度量机制框架示意图。随着数据实例的持续到达,概念漂移随时可能发生。若发生了概念漂移,则由发生变化的多元区域集构建的决策树模型在集成方法中所占权重会增加,以便更精确地实现对当前概念漂移的检测。当区域集中数据实例发生漂移时,发生变化的区域时效性将会增加,这会保证集成方法能检测到最新的变化,以提高检测概念漂移的准确率。
04
实验结果
EXPERIMENTS
实验结果
A. 区域集更新性能评估
仿真将使用与缓冲区限制相同的滑动窗口,使用Kolmogorov-Smirnov检验(KS检验)作为比较CDMP中区域子集与传统概念漂移恢复过程的基准测试。为了验证多样性区域集的自适应性能,首先将CDMP算法根据表1中描述的三种数据分布来生成数据集。
表1 数据集1描述
为了维持KS检验的数据缓存区域,本实验使用了常用的概念漂移适应策略,即在检测到概念漂移告警级别时构建一个新的缓冲区,然后将会在达到实际概念漂移级别时替换旧的缓冲区。其中警告级别的参数设置为α=0.05,而漂移等级的参数设置为α=0.01。
图7 缓冲区大小变化示意图
图7中展示了算法在突然和增量概念漂移后不同时刻存储在缓冲区中的数据实例数量,绿色虚线为时刻标注线。由结果可知,CDMP和KS检验都能在每种概念漂移发生后采取自适应措施。但从缓冲区大小可以发现,KS检验使用的传统方法在确认概念漂移发生会丢弃几乎所有的历史数据,即使这些历史数据可能是有用的。而CDMP能去除与缓冲区数据无关的数据信息,同时保留了符合当前数据分布的历史数据。且可以看到KS检验在增量漂移发生时段触发了两次的实际概念漂移级别,使缓冲区的数据实例数量在原有基础上进一步降低,导致缓冲区可用数据实例数量过少。相比有着漂移区域自适应能力的CDMP对漂移的发生更加敏感,并可以更多的保留缓冲区中与当前概念相关的数据实例。
因此,CDMP算法可以提供高效的模糊区域划分性能以处理漂移场景下具有歧义性和不确定性的数据实例,且能在漂移持续发生的情况下进行区域集的在线更新,以实现多元区域集对概念漂移自适应,并能准确识别发生概念漂移的区域。
B. 概念漂移检测准确性分析
本文将基于大数据在线分析开源平台MOA(Massive Online Analysis)系统进行实验,此系统是用于实现概念漂移数据流相关算法以及对在线学习相关算法进行仿真验证的实验环境。实验采用人工数据集和真实数据集相结合的形式,更全面的对算法的性能水平以及概念漂移预测准确率等进行验证。文章中使用了3个真实数据集Covertype、Poker和Electricity,以及3个人工数据集SEA、Hyper和RanTree,数据集各参数如表2所示。
表2 数据集2描述
C. 算法对比研究
在对比实验中,将CDMP与相关的算法进行对比,包括NB,LNSE,AUE2,ARF算法,其中NB是单分类器算法,算法本身不包含漂移应对的机制。AUE2和ARF为集成分类方法,LNSE算法可以应对多种不同的概念漂移场景。在实验过程中,首先对每个数据集随机选取部分数据分别进行预检测,从而保证数据的真实性和概念漂移类型。此外,所有数据集均重复100次实验,平均分类准确度为去除实验结果中的最大最小值并最终取平均值所得的结果。
表3 平均分类准确度对比
由表3的结果可以看出,CDMP在其中6个数据集上的平均分类准确度都显著优于其他的对比算法,但在HyperPlane和Electricity数据集上的检测准确率相比其他对比算法并未展现出明显优势。原因在于在上述数据集包含渐进型概念漂移,而算法中区域更新策略对渐进型概念漂移的数据实例反应相对迟滞,因此造成CDMP集成模型对渐进型概念漂移的适应能力相对较低。而ARF算法是除了CDMP算法之外表现最好的算法,原因是ARF算法设定了两段阈值机制以应对频繁发生的概念漂移。CDMP算法采用构建历史模型池的策略,所以随着数据实例的不断到达,CDMP算法的检测准确率最终都高于其他对比算法,并且基于价值度量的权重计算能保证模型对新数据实例的高敏感性,其次基于历史多样性的检测机制也能很好的适应数据集中重现概念漂移的出现,因此在检测中也能达到较高的检测准确率。
D. HHU轴承数据集性能验证
HHU轴承数据集采集于河海大学网络与安全实验室的PT700轴承故障测试平台。PT700轴承故障测试平台包括一个产生扭矩的三相电动机,一个转子组件,一个传动系,齿轮箱振动传感器等组成,整体结构如图8所示。
图8 PT700轴承实验台
实验的采样频率为102.4kHz,故障类型包括内圈故障、外圈故障和滚珠故障。实验仿真在内圈故障条件下,使用了轻度、中度、重度三种故障程度,对应的故障尺寸分别为0.2 mm、0.4 mm、0.6 mm的损伤。该数据集中包含有环境噪声,设置信噪比阈值大小为0.01db,低于0.01db视为无噪声影响。本文CDMP算法分别对两种不同场景下的概念漂移进行性能验证,场景一为轴承在内圈故障、不同负载条件下,转速由100到150、150到200、200到250、250到300、350到400的工况变化引起的概念漂移,场景二为轴承在内圈故障、相同转速条件下,由轻度故障转为中度故障、中度故障转为重度故障所引起的概念漂移,对应两种场景的概念漂移分别进行仿真实验。实验参数和检测结果如表4、表5所示。
表4 不同工况下的实验参数与检测准确度
表5 不同故障程度下的实验参数与检测准确度
表4、表5的实验结果表明,在真实的工业场景下对数据流发生的概念漂移进行检测时,CDMP仍然表现出较高的准确度。这进一步表明,本文提出的CDMP算法不仅在广泛使用的实验数据集中对数据流概念漂移的检测具有较好的性能,而且在真实的工业应用场景下也具有巨大的应用潜力。
图9 HHU数据集下不同算法的检测准确度
为了更好的验证CDMP算法的性能,在HHU数据集下对CDMP与其它概念漂移检测算法进行了对比实验,实验结果如图9所示。对比算法除NB,LNSE,AUE2,ARF算法外,进一步补充了AC-OE和EOFWOSELM两个集成学习算法作为对比算法。实验结果可知,本文提出的CDMP算法由于事先对多元区域集进行划分和历史模型池重用的策略,仍然对工业场景下HHU数据集存在的概念漂移具有较高的检测准确度和实用性。
E. 抗噪性分析
本节将会对不同噪声水平下各算法的检测准确率进行实验。表6列出了各算法在不同的噪声水平下的平均分类准确率,可以看出在不同的噪声水平影响下,CDMP的分类准确率均比其他对比算法高。图10中展示了所有对比算法在存在不同噪声水平的SEA数据集上检测准确率的仿真结果。
表6 不同噪声水平下的分类准确率(%)
由图10表明,各个对比算法均可在无噪声的情况下保持较高的检测准确率,但当噪声水平由0%增大到20%时,对比算法的检测性能都有不同程度的降低,但本文算法能在高噪声水平的场景下保持相对更好的准确性和稳定性,原因在于在构建多样性区域集的过程中模糊密度峰值可以筛选数据实例,筛选低密度的离群值,从而实现集成方法中基础模型的高泛化性和高鲁棒性。这是CDMP在工业高噪声水平下能保持高稳定性和高鲁棒性的根本原因。
图10 不同噪声水平下的检测结果对比
05
总结
CONCLUSION
总结
工业场景下复杂的工况环境和存在的工业噪声极大的影响了传统概念漂移检测的快速响应能力。本文提出了基于多元区域集划分的工业数据概念漂移检测算法CDMP,该算法基于模糊密度峰值的聚类方法实现在线的数据实例的模糊分区,通过在线监测数据流分布变化,对多元区域集实施概念漂移区域识别。最后,构建并维护历史模型池,通过对历史模型的重用实现对概念漂移识别的快速响应。实验结果表明,CDMP不仅具有良好的多元模糊区域划分性能,且能在概念漂移场景下实现对多元区域集的实时更新并准确识别概念漂移区域,具有较高的泛化性与鲁棒性。在未来的工作中,将考虑对概念漂移区域中缓冲区的大小进行自适应调整,同时降低增量漂移对算法的适应性产生的负面影响。
END
扫描二维码关注我们
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh