本文不是落地经验分享,而是看到三方实践分享后的发散性文章。写的并非笔者熟悉的领域,如果有写的不对的地方,欢迎指正~
ChatGPT 刚出来的时候,我测了一个场景,输入一些典型的漏洞代码片段如 SQL 注入,看 ChatGPT 能否识别以及能否把漏洞代码自动改写为安全的代码。
后来看了几篇讨论 ChatGPT 怎么和网络安全场景结合的文章,感觉都不是那么好落地的,对于甲方来说绕不开一个数据安全的问题。
期间 Meta 开源 LLaMA 之后,各种基于或者不基于 LLaMA 的 LLM 模型如雨后春笋般冒了出来。受限于机器资源,中间也陆续用 llama、alpaca、vicuna 低参数量的小模型测试了文章开头的 case,只能说目前和 ChatGPT 还有些差距。
尽管大部分模型还是偏对话向的,几个新出来的模型(比如基于 LLaMA 然后针对特定样本进行微调训练)甚至是基于和 ChatGPT 的对话样本进一步训练的。但是占用资源相对可控(可 cpu 推理,或者使用相对不那么贵的显卡可以进行训练)的离线模型,解决了私以为大语言模型和网络安全场景结合最大的障碍——数据安全。
后来陆续看到一些应用 ChatGPT 进行代码审计方向的尝试,可以参阅两篇文章:
使用 gpt 进行代码审计和创建小型知识库的详细教程(手把手)
感觉代码审计方向还是不是太对,一来受限于对话式 AI 天生的输入上限,只输入代码片段可能会影响判定,使用 embedding 来绕过长度问题对于大型项目最终效果有点存疑。二来对于甲方场景,代码非特殊场景是不可能外发给三方的。平常研发传个公司代码到 github,严重的可能都得开除,安全自己外发代码?
周末碰巧看到 semgrep (一个开源的轻量级 SAST 项目)在这块的实践,感觉不错
We put GPT-4 in Semgrep to point out false positives & fix code
https://semgrep.dev/blog/2023/gpt4-and-semgrep-detailed
从上面这篇文章拎出来几个点:
白盒的误报非常普遍,业界产品误报率在 10%~50%
GPT-4 能识别 Semgrep 扫描出来的告警的误报,但是目前仅作为提示(文章没有提判定误报的正确率)
GPT-4 给出修复的代码有 40% 可以直接拿来用,有 40% 需要再改改
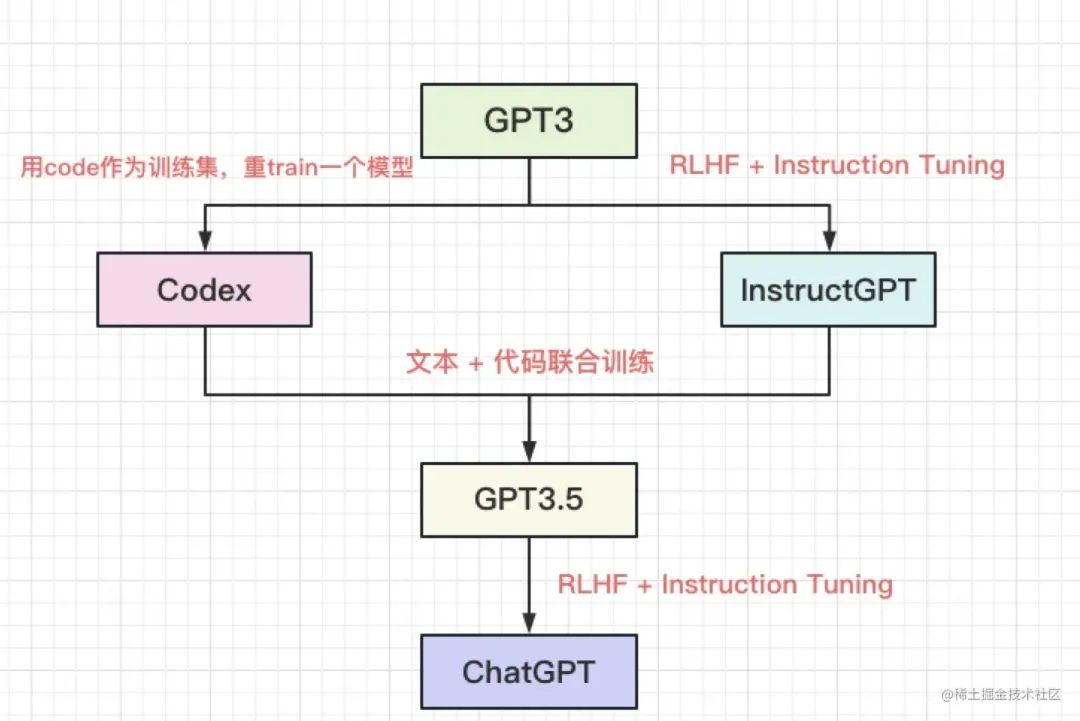
另外 semgrep 尝试过先调用 GPT-4 进行评估然后输出 prompt 再调用代码向的 code-davinci-edit-001 模型。思路上很好理解,通用大模型理解自然语言输出 prompt 调用专业领域模型,以期获得更好的输出。但是实际效果并不理想,会输出一些不相关的内容。原因可能也好理解,如下图,chatgpt 本身就是一个超集。
上图来自 ChatGPT 技术解析之:GPT 写代码的能力从何而来
https://juejin.cn/post/7215806457961955384
实际 Semgrep 的文章还有些细节,感兴趣的可以看下原文。
我在文章摘要中说『或许是短期内在网络安全领域能看到的最实际的可落地场景之一』,有几个原因:
SAST 告警输出本身就是代码片段,如多少行到多少行存在 xx 漏洞,所以不存在长度问题
离线大语言模型解决了数据安全问题
存在漏洞的代码及漏洞类型和修复后的代码作为 LLM 模型微调的语料,获取成本相对不高。对于一线大甲方甚至可能不需要去想办法抓取开源项目对应的存在漏洞和修复后的代码,整理下内部历年来白盒非误报的告警代码及输出后被修复的代码就有了
场景对时延要求不高,基于可商用的离线模型仅使用 CPU 进行推理可以不强依赖显卡,成本可控
切实点中白盒运营实际痛点,对于小型甲方安全团队白盒扫描的 ROI 是不太高的,因为误报,这块并不能像大型甲方那样有资源进行规则优化和嵌入发布流程变成发布门禁,很多时候只是作为应用安全同事的个人代码审计辅助。对于写出漏洞的研发来说,修复成本也降低了,就着尝试自动修复的 pr 进行 review、确认合并或者改写就行。甚至提自动修复 pr 或者 comment 之前可以跑下单测,通过再提交,乃至自动生成单测,哈
这是一个可标准化的路线(Model-As-A-Service),具备商业层面走通的潜质。商业层面能走通,业界可能会有更多的投入
蜚语安全做了一个科普,以及他们产品和 ChatGPT 结合生成修复建议的 demo
GPT 之于代码分析,“掀桌”还是“救赎”?| 附 Demo
虽然不是安全的实践,但是 code review 也是研发场景很实用的一个场景
基于 ChatGPT 的 code review!来 Curve 开源社区体验
当 CI 遇到错误时尝试找到错误自动改写提交 pr,这个也只能说是个 demo https://github.com/xpluscal/selfhealing-action-express
这是 Semgrep 文章中的一句话,解释为什么他们要做自动修复。大概明白意思,但是想了一会儿,没有想出来一个中文的『信达雅』的翻译。
发给 ChatGPT,告诉它不要直译,返回『身教胜于言教』 ,但是按照中文习惯,是有这样的说法『言传不如身教,身教不如境教』
我们可以想一下,公司内的安全编码指南,有多少人会事先用心去看?
我们思路可以再发散下,不止局限于解决 SAST 的误报和自动修复漏洞代码。
整体流程再左移,可以在 IDE 插件这层联动 LLM 模型。训练一个私有化的 "Github Copilot",在开发的时候改写有漏洞的代码或者引入内部的代码安全 SDK。『润物细无声』,这何尝不是某种程度的 "secure by default"。有想法的可以看下清华开源的 CodeGeeX 以及相关 IDE 插件。国外也有 codeium 这种公司提供完全本地化部署,可以基于客户代码仓库进行微调的 AI 代码补全产品。
当然,如果再发散下,不仅仅是 SAST 场景,langchain 可以调用另外的模型或者 api,在应用安全这块在不同的系统间做一些交叉验证。
或许安全从业者距离被 ChatGPT 这类生成式 AI 替代的可能性现阶段看还相对遥远,微软的 Security Copilot 定位也还是 Copilot,说到底现阶段『主驾驶』还是人。不用焦虑,可以了解相关内容,进行一些尝试,研究如何找到合适的使用场景提高自己或者组织的工作效率。
本来这个公众号是上周为了测试注册的,没想到周末得空就随手写了点,还不是自己熟悉的领域。防止有些点写的不对,邀请了几位同学对文章预览 review 了下。他们的公众号也可以关注观摩下:
如有侵权请联系:admin#unsafe.sh