2023-4-14 15:7:0 Author: www.cnblogs.com(查看原文) 阅读量:21 收藏
2017年,Google在论文 Attention is All you need 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,其最大的优点是可以并行计算。Transformer 的整体模型架构如下图所示

0x1:Transformer概览
首先,让我们先将Transformer模型视为一个黑盒,如下图所示。在机器翻译任务中,将一种语言的一个句子作为输入,然后将其翻译成另一种语言的一个句子作为输出。

Transformer本质上是一个Encoder-Decoder架构。因此中间部分的Transformer可以分为两个部分:
- 编码组件
- 解码组件
如下图所示:

其中,编码组件由多层编码器(Encoder)组成(在论文中作者使用了6层编码器,在实际使用过程中你可以尝试其他层数)。解码组件也是由相同层数的解码器(Decoder)组成(在论文也使用了6层)。如下图所示:

每个编码器由两个子层组成:
- Self-Attention层(自注意力层)
- Position-wise Feed Forward Network(前馈网络,FFN)
如下图所示,每个编码器的结构都是相同的,但是它们使用不同的权重参数。

编码器的输入会先流入Self-Attention层,它可以让编码器在对特定词进行编码时使用输入句子中的其他词的信息。然后,Self-Attention层的输出会流入前馈网络。
解码器也有编码器中这两层,但是它们之间还有一个注意力层(即 Encoder-Decoder Attention),其用来帮忙解码器关注输入句子的相关部分(类似于seq2seq模型中的注意力机制)。

0x2:Transformer结构
现在我们从输入层开始逐步分析论文中的模型,下图是Transformer用于中英文翻译的整体结构。

第一步:输入数据向量化表示
和大部分的NLP任务一样,首先,我们使用词嵌入算法(Embedding)将每个词转换为一个词向量。在Transformer论文中,词嵌入向量的维度是512。
输入句子的每一个单词的表示向量X,X由单词的Embedding和单词位置的Embedding相加得到。

第二步:计算编码矩阵
将得到的单词表示向量矩阵(如上图所示,每一行是一个单词的表示x)传入Encoder中,经过6个Encoder block后可以得到句子所有单词的编码信息矩阵C,如下图。

单词向量矩阵用X(n×d)表示, n是句子中单词个数,d是表示向量的维度(论文中d=512)。每一个Encoder block输出的矩阵维度与输入完全一致。
第三步:计算解码矩阵
将Encoder输出的编码信息矩阵C传递到Decoder中,Decoder依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。

在使用的过程中,翻译到单词 i+1 的时候需要通过Mask(掩盖)操作遮盖住 i+1 之后的单词。
上图Decoder接收了Encoder的编码矩阵C,然后首先输入一个翻译开始符 "<Begin>",预测第一个单词 "I";然后输入翻译开始符 "<Begin>" 和单词 "I",预测单词 "have",以此类推。
这是Transformer使用时候的大致流程,接下来是里面各个部分的细节。
0x3:Transformer结构的内部细节
1、Transformer的输入
Transformer中单词的输入表示x由单词Embedding和位置Embedding相加得到。

单词的Embedding有很多种方式可以获取,例如可以采用Word2Vec、Glove等算法预训练得到,也可以在Transformer中训练得到。词Embedding负责捕获词与词之间的相对语义近邻关系。
Transformer中除了单词的Embedding,还需要使用位置Embedding表示单词出现在句子中的位置。因为Transformer不采用RNN的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于NLP来说非常重要。所以Transformer中使用位置Embedding保存单词在序列中的相对或绝对位置。
位置和顺序对于一些任务十分重要,例如理解一个句子、一段视频。位置和顺序定义了句子的语法、视频的构成,它们是句子和视频语义的一部分。循环神经网络RNN本质上考虑到了句子中单词的顺序。因为RNN以顺序的方式逐字逐句地解析一个句子,这将把单词的顺序整合到RNN中。Transformer使用MHSA(Multi-Head Self-Attention),从而避免使用了RNN的递归方法,加快了训练时间,同时,它可以捕获句子中的长依赖关系,能够应对更长的输入。
当句子中的每个单词同时经过Transformer的Encoder/Decoder堆栈时,模型本身对于每个单词没有任何位置/顺序感 (permutation invariance)。 因此,仍然需要一种方法来将单词的顺序信息融入到模型中。
为了使模型能够感知到输入的顺序,可以给每个单词添加有关其在句子中位置的信息,这样的信息就是位置编码(positional embedding, PE)。
为了更好地理解Positional Encoding,我们来从本质思考一下如何设计positional embedding?有什么规则?
一般我们可能想到的方案是:
- 给每一个时间步设定[0,1]范围的一个值,0表示第一个,1表示最后一个。这样做的问题是,因为我们不确定句子里有多少个单词,如果用变长的位置向量来进行编码,不同单词数的句子中相邻单词之间的距离就不固定了。
- 给每一个时间步分配一个数值,例如第一个单词分配“1”,第二个单词分配“2”等等。这样做的问题是,这些值很大,并且实际中遇到的句子可能比训练时见过的句子还要长,这就会导致模型泛化性能变差。
上述的第一个方案,假设现在我们想用4dim的二进制向量来表示数字,如下图所示,[0,15]的16个位置被编码为了16个4维向量。

我们可以观察到不同位置之间的变化率,最后一位在0和1上依次交替,第二低位在每两个数字上交替,以此类推。
但是用二进制表示数字在浮点数空间非常浪费空间,也无法解决[,16]以后的不同长度的位置的编码问题。用一个远超过实际所需的向量空间对位置进行编码也不现实,我们需要找到一个能兼容上述问题的新模型。
理想情况下PE的设计应该遵循这几个条件:
- 为每个时间步(单词在句子中的位置)输出唯一的编码
- 即便句子长度不一,句子中两个时间步之间的相对距离应该是“恒定”的
- 算法可以轻易泛化到不同长度的句子上
- PE必须是确定的
按照上述限定条件,一个很直接的思考方向就是:需要用一个正弦/余弦曲线函数来对位置进行编码。
接下来我们来看看“Attention is all you need”中固定类型的PE为什么是这样设计(sin, cos )的?作者设计的这种位置编码的方式非常巧妙。
- 首先,它不是一个单一的数值,它是关于句子中一个特定位置信息的
d维的向量,本质上也是用一个定长的向量空间来对位置信息进行编码。 - 其次,这种编码没有集成到模型本身上。相反,这个向量用于给每个单词分配一个有关其在句子中位置的信息。换句话说,PE只和输入有关,而和模型无关。
假设 t 是输入序列的一个位置,![]() 是它对应的编码,d 是维度。定义
是它对应的编码,d 是维度。定义![]() 是产生
是产生![]() 的函数,它的形式如下:
的函数,它的形式如下:

这里 i 是位置向量的index(d维向量的索引), k 的引入是为了区分位置向量的奇偶位(2k<<d、2k+1<<d)。其中:

由函数定义可以推断出,PE可以表示为一个向量,其中每个wk都决定了一个维度,每一维都对应一个正弦/余弦曲线,wk决定了正弦/余弦曲线的频率。i从[0,d],wk逐渐减少,因此正弦/余弦函数的频率逐渐减少。

因此,PE中的位置向量,本质上就是一组频率逐渐减少的正弦/余弦函数。

从上式可以看到,
- 每一维都对应一个正弦/余弦曲线。
- 正弦/余弦的波长范围是 [2π,10000·2π] ,每个值的范围是 [-1,1],这意味着它可以编码最长为10000的位置,第1和第10001的位置编码重复。
- 每一个位置数值都被映射到一个d维的正弦/余弦值向量空间上。
- 不管处于什么位置,两个相对位置对应的向量距离差值总是相同的,这是由正弦/余弦函数的频率计算定理保证的,这保证了位置编码函数最基本的要求。
- PE能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有20个单词,突然来了一个长度为21的句子,则使用公式计算的方法可以计算出第21位的Embedding。
现在产生了几个个新问题:
- 这种sines和cosines的组合为什么能够表示位置/顺序?
- 为什么这种正弦曲线形的位置编码可以轻松允许模型获取相对位置relative positioning?
- 为什么sine和cosine都被用到了?
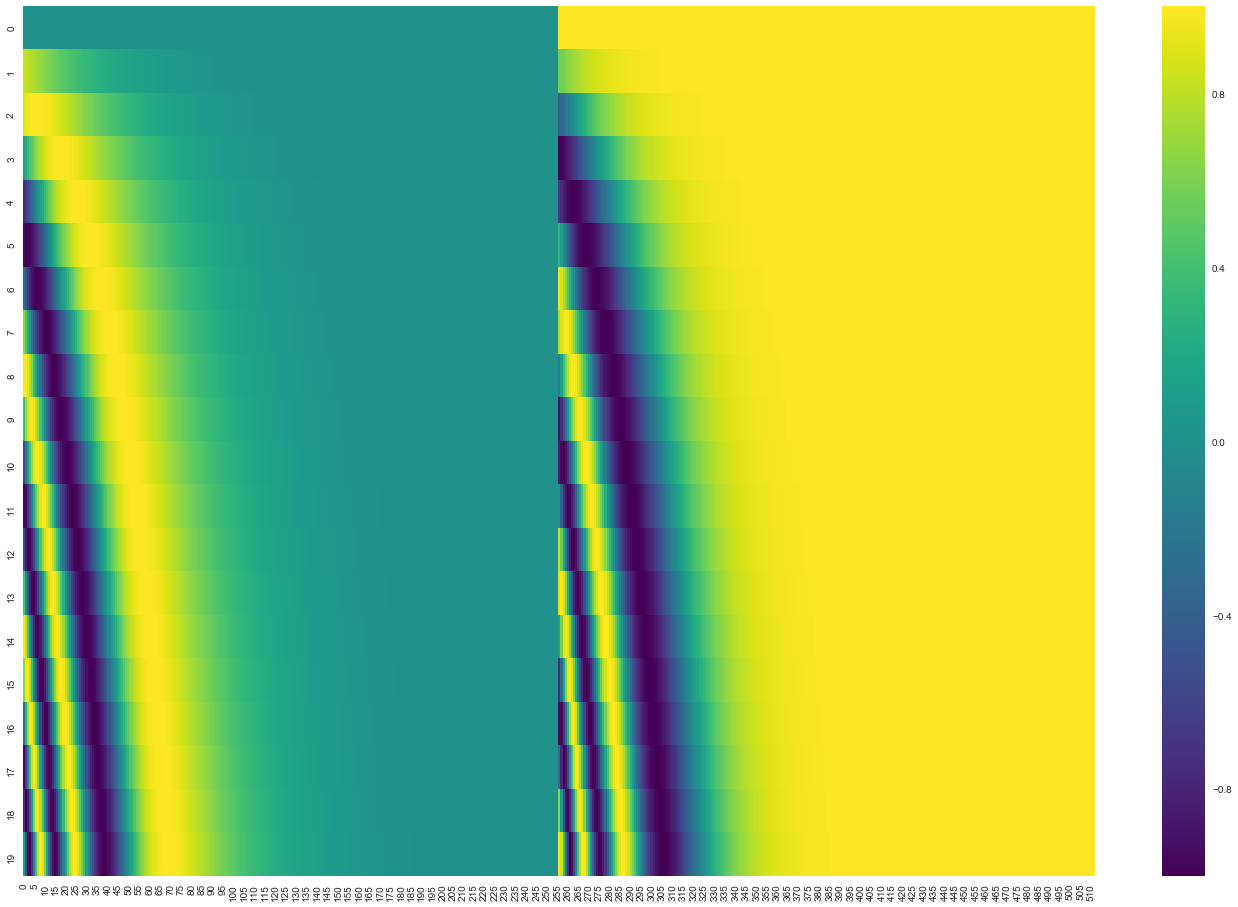
先看第一个问题,下图展示了一个最多50个单词的句子中的每个单词的位置编码,维度是128。每一行都表示一个位置编码向量,如下图所示,

从宏观来看
- 横向看,对同一个位置来说,不同维度对应的正弦/余弦函数频率逐步降低,从红色的的位变为橙色的位。
- 纵向来看,左侧上下变化较大,越向右上下变化差越小,其原因还是因为越往右频率越小,不同位置对应的值变化空间就越小。
- 相邻时间步的位置编码的距离(点积)是对称的,并且会随着时间很好地衰减。
再来看第二个问题,Attention原文是这么写的:

为什么这句话成立?这篇博客给了一个完整的证明。
这里简单可以理解为,对于固定长度的间距 k,PE(pos+k) 可以用PE(pos) 计算得到。因为:
Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)
上式也回答了第三个问题,为什么sine和cosine都被用到了?只用它们的组合才能用sin(x)和cos(x)的组合线性表示sin(x+k), cos(x+k)。
随后,将单词的词Embedding和位置Embedding相加,就可以得到单词的表示向量x,x就是Transformer的输入。
这里又引出一个新的问题:
- 为什么PE和WE(word embeddings)是相加(add),而不是拼接(concatenate)?
目前这个问题没有理论证明,但是加法相对于拼接减少了模型的参数量。
回到上面的位置编码的可视化图,我们会发现:相对于整个embedding来说,只有前面少数dimension是用来存储位置信息的。由于embedding只有128维,不够明显,借用另一个博客的图:

这幅图表示20个单词的512维的位置编码,
- 左图是sine拼接之前的样子
- 右图是cosine拼接之前的样子
大部分的维度(全绿/黄)几乎只共享常数1或者-1,换句话说这些维度都用表示word embedding的信息了。
另外,由于Transformer中PE和WE是从头开始训练的,因此参数的设置方式可能是单词的语义不会存储在前几个维度中,以免干扰位置编码。(这也是这个问题的解: PE是如何训练的?或者说如何让模型知道这些embeddings是position信息?)
从这个角度来看,Transformer或许可以分离语义信息和位置信息。这样的话,考虑分类PE和WE可能就不会是一个优点了,可能加法提供了额外的可以学习的特征。
上面那幅图sine和cosine合起来大概是这样:

完成输入数据的向量化之后,模型结构的下一步就是Self-Attention层。
2、Self-Attention(自注意力)
关于self-attension的简单原理解释可以参阅这篇文章,我们这里继续展开分析一下。
假如,我们要翻译下面这个句子:
The animal didn’t cross the street because it was too tired
这个句子中的 it 指的是什么?是指 animal 还是 street ?对人来说,这是一个简单的问题,但是算法来说却不那么简单。
当模型在处理 it 时,Self-Attention 机制使其能够将 it 和 animal 关联起来,即将这个词映射到相近的向量空间位置上,以此来表示两个词的相关性。在深度网络中,越相近的两个词,在后续的神经元连接中就越容易被同时激活。
当模型处理每个词(输入序列中的每个位置)时,Self-Attention机制使得模型不仅能够关注当前位置的词,而且能够关注句子中其他位置的词,从而可以更好地编码这个词。
如果你熟悉RNN,想想如何维护隐状态,使RNN将已处理的先前词/向量的表示与当前正在处理的词/向量进行合并。Transformer使用Self-Attention机制将其他词的理解融入到当前词中。
当我们在编码器 #5(堆栈中的顶部编码器)中对单词”it“进行编码时,有一部分注意力集中在”The animal“上,并将它们的部分信息融入到”it“的编码中。
下面我们来看一下Self-Attention的具体机制。其基本结构如下图所示:

Scaled Dot-Product Attention(缩放点积注意力)
对于Self Attention来讲,Q(Query),K(Key)和 V(Value)三个矩阵均来自同一输入,并按照以下步骤计算:
- 首先计算 Q 和 K 之间的点积,为了防止其结果过大,会除以
 ,其中 dk 为 Key 向量的维度。
,其中 dk 为 Key 向量的维度。 - 然后利用Softmax操作将其结果归一化为概率分布,再乘以矩阵 V 就得到权重求和的表示。
整个计算过程可以表示为:

下面通过一个例子,让我们看一下如何使用向量计算Self-Attention。计算Self-Attention的步骤如下:
第一步:基于输入的词向量,创建QKV向量
对编码器的每个输入向量(在本例中,即每个词的词向量)创建三个向量:
- Query向量
- Key向量
- Value向量
它们是通过词向量分别和3个矩阵相乘得到的,这3个矩阵通过训练获得。Query,Key和Value向量是一种抽象,对于注意力的计算和思考非常有用。
请注意,这些向量的维数小于词向量的维数,论文中新向量的维数为64,而embedding和编码器输入/输出向量的维数为512。新向量不一定非要更小,这是为了使多头注意力计算保持一致的结构性选择。 在上图中,x1乘以权重矩阵WQ得到q1,即与该单词关联的Query向量。最终会为输入句子中的每个词创建一个Query,一个Key和一个Value向量。
在上图中,x1乘以权重矩阵WQ得到q1,即与该单词关联的Query向量。最终会为输入句子中的每个词创建一个Query,一个Key和一个Value向量。
第二步:计算注意力分数
假设我们正在计算这个例子中第一个词“Thinking”的自注意力。我们需要根据“Thinking”这个词,对句子中的每个词都计算一个分数。这些分数决定了我们在编码“Thinking”这个词时,需要对句子中其他位置的每个词放置多少的注意力。
这些分数,是通过计算“Thinking”的Query向量和需要评分的词的Key向量的点积得到的。如果我们计算句子中第一个位置词的注意力分数,则第一个分数是q1和k1的点积,第二个分数是q1和k2的点积。

第三步:基于Key向量维度进行归一化
将每个分数除以![]() (
(![]() 是Key向量的维度)。目的是在反向传播时,求梯度更加稳定。实际上,你也可以除以其他数。
是Key向量的维度)。目的是在反向传播时,求梯度更加稳定。实际上,你也可以除以其他数。
第四步:对分数进行Softmax概率归一化
将这些分数进行Softmax操作。Softmax将分数进行归一化处理,使得它们都为正数并且和为1。

这些Softmax分数决定了在编码当前位置的词时,对所有位置的词分别有多少的注意力。很明显,当前位置的词汇有最高的分数,但有时注意一下与当前位置的词相关的词是很有用的。
第五步:将每个Softmax分数分别与每个Value向量相乘
这种做法背后的直觉理解是起一个放大作用:
- 对于分数高的位置,相乘后的值就越大,我们把更多的注意力放在它们身上。
- 对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大,我们就可以忽略这些位置的词。
第六步:将加权Value向量(即上一步求得的向量)求和
最终得到了自注意力层在这个位置的输出。

这样就完成了自注意力的计算。生成的向量会输入到前馈网络中。但是在实际实现中,此计算是以矩阵形式进行,以便实现更快的处理速度。
3、Multi-head Attention(多头注意力机制)
在Transformer论文中,通过添加一种多头注意力机制,进一步完善了自注意力层。具体做法:
- 首先,通过 h 个不同的线性变换对Query、Key Value进行映射
- 然后,将不同的Attention拼接起来
- 最后,再进行一次线性变换
基本结构如下图所示:

每一组注意力用于将输入映射到不同的子表示空间,这使得模型可以在不同子表示空间中关注不同的位置。整个计算过程可表示为:

其中,![]() 。在论文中,指定 h = 8(即使用8个注意力头)和
。在论文中,指定 h = 8(即使用8个注意力头)和![]() 。
。
在多头注意力下,我们为每组注意力单独维护不同的Query、Key和Value权重矩阵,从而得到不同的Query、Key和Value矩阵。如前所述,我们将 X乘以WQ、WK、和 WV矩阵,得到Query、Key和Value矩阵。
按照上面的方法,使用不同的权重矩阵进行8次自注意力计算,就可以得到8个不同的Z矩阵。
接下来,因为前馈神经网络层接收的是1个矩阵(每个词的词向量),而不是上面的8个矩阵。因此,我们需要一种方法将这8个矩阵整合为一个矩阵。具体方法如下:
- 把8个矩阵
 拼接起来。
拼接起来。 - 把拼接后的矩阵和一个权重矩阵WO相乘。
- 得到最终的矩阵Z,这个矩阵包含了所有注意力头的信息。这个矩阵会输入到FFN层。

综上所有过程,用一张图归纳一下整个多头注意力的过程,

现在让我们重新回顾一下前面的例子,看看在对示例句中的“it”进行编码时,不同的注意力头关注的位置分别在哪:

当我们对“it”进行编码时,一个注意力头关注“The animal”,另一个注意力头关注“tired”。从某种意义上来说,模型对“it”的表示,融入了“animal”和“tired”的部分表达。
Multi-head Attention的本质是,在参数总量保持不变的情况下,将同样的Query,Key,Value映射到原来的高维空间的不同子空间中进行Attention的计算,在最后一步再合并不同子空间中的Attention信息。这样降低了计算每个head的Attention的向量维度,在某种意义上防止了过拟合;由于Attention在不同子空间中有不同的分布,Multi-head Attention实际上是寻找了序列之间不同角度的关联关系,并在最后拼接这一步骤中,将不同子空间中捕获到的关联关系再综合起来。
4、Position-wise Feed-Forward Networks(位置前馈网络)
位置前馈网络就是一个全连接前馈网络,每个位置的词都单独经过这个完全相同的前馈神经网络。其由两个线性变换组成,即两个全连接层组成,第一个全连接层的激活函数为ReLU激活函数。可以表示为:
![]()
在每个编码器和解码器中,虽然这个全连接前馈网络结构相同,但是不共享参数。整个前馈网络的输入和输出维度都是dmodel = 512,第一个全连接层的输出和第二个全连接层的输入维度为 dff = 2048。
5、Add & Norm(残差连接和层归一化)
编码器结构中有一个需要注意的细节:每个编码器的每个子层(Self-Attention层和FFN层)都有一个残差连接,再执行一个层标准化操作,整个计算过程可以表示为:
![]()
其中X表示Multi-Head Attention或者Feed Forward的输入,MultiHeadAttention(X)和FeedForward(X)表示输出(输出与输入X维度是一样的,所以可以相加)。

Add指X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练中权重矩阵衰退的问题,可以让网络只关注当前差异的部分,在ResNet中经常用到。

Norm指Layer Normalization,通常用于RNN结构,Layer Normalization会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。

将向量和自注意力层的层标准化操作可视化,如下图所示:

上面的操作也适用于解码器的子层。假设一个Transformer是由2层编码器和2层解码器组成,其如下图所示:

为了方便进行残差连接,编码器和解码器中的所有子层和嵌入层的输出维度需要保持一致,在Transformer论文中dmodel = 512 。
6、解码器
前面我们已经介绍了编码器的大部分概念,我们也了解了解码器的组件的原理。现在让我们看下编码器和解码器是如何协同工作的。

上图红色部分为Transformer的Decoder block结构,与Encoder block相似,但是存在一些区别:
- 包含两个Multi-Head Attention层
- 第一个Multi-Head Attention层采用了Masked操作
- 第二个Multi-Head Attention层的 K, V矩阵使用Encoder的编码信息矩阵C进行计算,而Q使用上一个Decoder block的输出计算
- 最后有一个Softmax层计算下一个翻译单词的概率。
1)第一个Multi-Head Attention
Decoder block的第一个Multi-Head Attention采用了Masked操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过Masked操作可以防止第 i 个单词知道 i+1 个单词之后的信息。
下面以"我有一只猫"翻译成"I have a cat"为例,了解一下Masked操作。
下面的描述中使用了类似Teacher Forcing的概念,在Decoder的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。
首先根据输入"<Begin>"预测出第一个单词为"I",此时得到ouput:"<Begin> I",将output也输入decoder,decoder根据之前的翻译结果"<Begin> I"以及新的encoder输入(”有“这个词向量),然后预测下一个单词"have"。

Decoder可以在训练的过程中使用Teacher Forcing并且并行化训练,即将正确的单词序列 (<Begin> I have a cat) 和对应输出 (I have a cat <end>) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意Mask操作是在 Self-Attention的Softmax之前使用的,下面用 0 1 2 3 4 5 分别表示 "<Begin> I have a cat <end>"。
- 第一步
是Decoder的输入矩阵和Mask矩阵,输入矩阵包含"<Begin> I have a cat"(0, 1, 2, 3, 4)五个单词的表示向量,Mask是一个 5×5 的矩阵。在Mask可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。

- 第二步
接下来的操作和之前的Self-Attention一样,通过输入矩阵X计算得到Q, K, V矩阵。然后计算Q和KT的乘积QKT。

- 第三步
在得到QKT之后需要进行Softmax,计算attention score,我们在Softmax之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:

得到Mask QKT之后在Mask QKT上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的attention score都为 0。
- 第四步
使用Mask QKT与矩阵V相乘,得到输出Z,则单词 1 的输出向量 Z1 是只包含单词 1 信息的。

- 第五步
通过上述步骤就可以得到一个Mask Self-Attention的输出矩阵Zi,然后和Encoder类似,通过Multi-Head Attention拼接多个输出Zi,然后计算得到第一个Multi-Head Attention的输出Z,Z与输入X维度一样。
2)第二个Multi-Head Attention
Decoder block第二个Multi-Head Attention变化不大,主要的区别在于其中Self-Attention的 K, V矩阵不是使用上一个Decoder block的输出计算的,而是使用Encoder的编码信息矩阵C计算的,这有助于解码器把注意力集中在输入序列的合适位置。

根据Encoder的输出C计算得到K, V,根据上一个Decoder block的输出Z计算Q(如果是第一个Decoder block则使用输入矩阵X进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在Decoder的时候,每一位单词都可以利用到Encoder所有单词的信息(这些信息无需Mask)。
3)Softmax预测输出单词
Decoder block最后的部分是利用Softmax预测下一个单词,在之前的网络层我们可以得到一个最终的输出Z,因为Mask的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,如下。

Softmax根据输出矩阵的每一行预测下一个单词,

以上就是Decoder block的定义,与Encoder一样,Decoder是由多个Decoder block组合而成。
接下来会重复这个过程,直到输出一个结束符,表示Transformer解码器已完成其输出。每一步的输出都会在下一个时间步输入到下面的第一个解码器,解码器像编码器一样将解码结果显示出来。就像我们处理编码器输入一样,我们也为解码器的输入加上位置编码,来指示每个词的位置。

7、Mask(掩码)
Transformer模型属于自回归模型,也就是说后面的token的推断是基于前面的token的。Decoder端的Mask的功能是为了保证训练阶段和推理阶段的一致性。
论文原文中关于这一点的段落如下:

在推理阶段,token是按照从左往右的顺序推理的。也就是说,在推理timestep=T的token时,decoder只能“看到”timestep < T的T-1 个Token,不能和timestep大于它自身的token做attention(因为根本还不知道后面的token是什么)。为了保证训练时和推理时的一致性,所以,训练时要同样防止token与它之后的token去做attention。
Transformer模型里面涉及两种mask,分别是Padding Mask和Sequence Mask。其中,Padding Mask在所有的scaled dot-product attention里面都需要用到,而Sequence Mask只有在Decoder的Self-Attention里面用到。
1)Padding Mask
什么是Padding mask呢?因为每个批次输入序列的长度是不一样的,所以我们要对输入序列进行对齐。具体来说,就是在较短的序列后面填充0(但是如果输入的序列太长,则是截断,把多余的直接舍弃)。因为这些填充的位置,其实是没有什么意义的,所以我们的Attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法:把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过Softmax后,这些位置的概率就会接近0。
2)Sequence Mask
Sequence Mask是为了使得Decoder不能看见未来的信息。也就是对于一个序列,在 t 时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因为我们需要想一个办法,把 t 之后的信息给隐藏起来。
具体的做法:产生一个上三角矩阵,上三角的值全为 0。把这个矩阵作用在每个序列上,就可以达到我们的目的。
3)总结
对于Decoder的Self-Attention,里面使用到的scaled dot-product attention,同时需要Padding Mask和Sequence Mask,具体实现就是两个Mask相加。其他情况下,只需要Padding Mask。
8、最后的线性层和Softmax层
解码器栈的输出是一个float向量。我们怎么把这个向量转换为一个词呢?通过一个线性层再加上一个Softmax层实现。
线性层是一个简单的全连接神经网络,其将解码器栈的输出向量映射到一个更长的向量,这个向量被称为logits向量。
现在假设我们的模型有10000个英文单词(模型的输出词汇表)。因此logits向量有10000维,每个维度的数表示一个单词的分数。然后,Softmax层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于1)。最后选择最高概率所对应的单词,作为这个时间步的输出。

9、正则化操作
为了提高Transformer模型的性能,在训练过程中,使用了以下的正则化操作:
- Dropout。对编码器和解码器的每个子层的输出使用Dropout操作,是在进行残差连接和层归一化之前。词嵌入向量和位置编码向量执行相加操作后,执行Dropout操作。Transformer论文中提供的参数Pdrop = 0.1
- Label Smoothing(标签平滑)。Transformer 论文中提供的参数 ϵls = 0.1
0x3:Transformer和RNN的区别
- Transformer与RNN不同,可以比较好地并行训练。
- Transformer本身是不能利用单词的顺序信息的,因此需要在输入中添加位置Embedding,否则Transformer就是一个词袋模型了。
- Transformer的重点是Self-Attention结构,其中用到的Q, K, V矩阵通过输出进行线性变换得到。
- Transformer中Multi-Head Attention中有多个Self-Attention,可以捕获单词之间多种维度上的相关系数attention score。
参考资料:
https://zhuanlan.zhihu.com/p/359366717 https://kazemnejad.com/blog/transformer_architecture_positional_encoding/ https://www.jianshu.com/p/e6b5b463cf7b https://jalammar.github.io/illustrated-transformer/ https://cloud.tencent.com/developer/article/1800935 https://blog.csdn.net/sinat_34072381/article/details/106173365 https://zhuanlan.zhihu.com/p/42833949 https://blog.csdn.net/benzhujie1245com/article/details/117173090 https://baijiahao.baidu.com/s?id=1651219987457222196&wfr=spider&for=pc https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247506890&idx=4&sn=12445fc7d65284d0db385cc316c4e9cb&chksm=ebb7e31edcc06a089746a1c2a3ac192a1f859b2e0f757e94bcd01bd4b64a8025aa8ebf3a3070&scene=27
GPT模型的训练需要超大的训练语料,超多的模型参数以及超强的计算资源。GPT系列的模型结构秉承了不断堆叠transformer的思想,通过不断的提升训练语料的规模和质量,提升网络的参数数量来完成GPT系列的迭代更新的。GPT也证明了,通过不断的提升模型容量和语料规模(模型参数不断扩大产生的涌现现象),模型的能力是可以不断提升的。
| 模型 | 发布时间 | 能力 | 模型结构 | 参数量 | 预训练数据量 | 后训练策略 |
|---|---|---|---|---|---|---|
| GPT-1 | 2018 年 6 月 | Decoder | 1.17 亿 | 约 5GB | - | |
| GPT-2 | 2019 年 2 月 | Decoder | 15 亿 | 40GB | - | |
| GPT-3 | 2020 年 5 月 |
|
Decoder | 1,750 亿 | 45TB | - |
| ChatGPT(GPT-3.5) | 2022 年 11 月 |
|
Decoder | ? | ? | RLHF |
| GPT-4 | 2023 年 3 月 | Transformer-Style | ? | ? | RLHF(Reinforcement learning with human feedback)+RLHF(安全性)+RBRMS |
下图展示了GPT生成模型的研究脉络:

0x1:GPT-1:无监督学习
在GPT-1之前,传统的NLP模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点:
- 需要大量的标注数据,高质量的标注数据往往很难获得,特别是在一个垂直领域,获取高质量样本的成本,甚至超过了训练模型和模型预测所能带来的收益,简单说就是ROI不高。
- 根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP。
GPT-1的思想是先通过在无标签的数据上学习一个生成式的语言模型,然后再根据特定垂直任务进行微调,处理的有监督任务包括:
- 自然语言推理(Natural Language Inference 或者 Textual Entailment):判断两个句子是包含关系(entailment),矛盾关系(contradiction),或者中立关系(neutral)
- 问答和常识推理(Question answering and commonsense reasoning):类似于多选题,输入一个文章,一个问题以及若干个候选答案,输出为每个答案的预测概率
- 语义相似度(Semantic Similarity):判断两个句子是否语义上市是相关的
- 分类(Classification):判断输入文本是指定的哪个类别
将无监督学习应用于有监督模型的预训练目标,因此叫做生成式预训练(Generative Pre-training,GPT)。
1、GPT-1的训练
GPT-1的训练分为无监督的预训练和有监督的模型微调。
1)无监督训练
GPT-1的无监督预训练是基于语言模型进行训练的,给定一个无标签的序列![]() ,语言模型的优化目标是最大化下面的似然值:
,语言模型的优化目标是最大化下面的似然值:
![]()
其中 k 是滑动窗口的大小,P 是条件概率, Θ 是模型的参数。这些参数使用SGD进行优化。
在GPT-1中,使用了12个transformer块(6个编码器、6个解码器)的结构,每个transformer块是一个多头的自注意力机制,然后通过全连接得到输出的概率分布。


其中![]() 是当前时间片的上下文token(决定用多少的输入预测下一个字符的输出), n 是层数, We 是词嵌入矩阵, Wp 是位置嵌入矩阵。
是当前时间片的上下文token(决定用多少的输入预测下一个字符的输出), n 是层数, We 是词嵌入矩阵, Wp 是位置嵌入矩阵。
2)有监督微调
当得到无监督的预训练模型之后,我们将它的值直接应用到有监督任务中。对于一个有标签的数据集C,每个实例有m个输入token:{x1,…,xm} ,它对于的标签 y 组成。
首先将这些token输入到训练好的预训练模型中,得到最终的特征向量 hlm 。然后再通过一个全连接层得到预测结果 y:
![]()
其中 Wy 为全连接层的参数。有监督的目标则是最大化上式的值:
![]()
作者并没有直接使用 L2,而是向其中加入了 L1,并使用 λ 进行两个任务权值的调整, λ 的值一般为 0.5 :
![]()
当进行有监督微调的时候,我们只训练输出层(后接的小模型)的 Wy 和分隔符(delimiter)的嵌入值。
3)任务相关的输入变换
对于不同的输入,GPT-1有不同的处理方式,具体介绍如下:
- 分类任务:将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布;
- 自然语言推理:将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果;
- 语义相似度:输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果;
- 问答和常识推理:将 n 个选项的问题抽象化为 n 个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。

(左):transformer的基本结构,(右):GPT-1应用到不同任务上输入数据的变换方式
2、GPT-1的数据集
GPT-1使用了BooksCorpus数据集,这个数据集包含 7,000 本没有发布的书籍。作者选这个数据集的原因有二:
- 数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系
- 这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力
3、GPT-1的网络结构细节
GPT-1使用了12层的transformer,使用了掩码自注意力头,掩码的使用使模型看不见未来的信息,得到的模型泛化能力更强。
1)无监督训练
- 使用字节对编码(byte pair encoding,BPE),共有 40,000 个字节对;
- 词编码的长度为 768 ;
- 位置编码也需要学习;
- 12 层的transformer,每个transformer块有 12 个头;
- 位置编码的长度是 3,072 ;
- Attention,残差,Dropout等机制用来进行正则化,drop比例为 0.1 ;
- 激活函数为GLEU;
- 训练的batchsize为 64 ,学习率为 2.5e−4 ,序列长度为 512 ,序列epoch为 100 ;
- 模型参数数量为 1.17 亿。
2)有监督微调
- 无监督部分的模型也会用来微调;
- 训练的epoch为 3 ,学习率为 6.25e−5 ,这表明模型在无监督部分学到了大量有用的特征。
4、GPT-1的性能
- 在有监督学习的12个任务中,GPT-1在9个任务上的表现超过了state-of-the-art的模型。
- 在没有见过数据的zero-shot任务中,GPT-1的模型要比基于LSTM的模型稳定,且随着训练次数的增加,GPT-1的性能也逐渐提升,表明GPT-1有非常强的泛化能力,能够用到和有监督任务无关的其它NLP任务中。
GPT-1证明了transformer对学习词向量的强大能力,在GPT-1得到的词向量基础上进行下游任务的学习,能够让下游任务取得更好的泛化能力。对于下游任务的训练,GPT-1往往只需要简单的微调便能取得非常好的效果。
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家。
0x2:GPT-2:多任务学习
GPT-2的目标旨在训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集。
1、GPT-2的核心思想
GPT-2的学习目标是使用无监督的预训练模型做有监督的任务。因为文本数据的时序性,一个输出序列可以表示为一系列条件概率的乘积:

上式也可以表示为 ,它的实际意义是根据已知的上文
,它的实际意义是根据已知的上文 预测未知的下文
预测未知的下文 ,因此语言模型可以表示为
,因此语言模型可以表示为 。对于一个有监督的任务,它可以建模为
。对于一个有监督的任务,它可以建模为 的形式。在decaNLP中,他们提出的MQAN模型可以将机器翻译,自然语言推理,语义分析,关系提取等10类任务统一建模为一个分类任务,而无需再为每一个子任务单独设计一个模型。
的形式。在decaNLP中,他们提出的MQAN模型可以将机器翻译,自然语言推理,语义分析,关系提取等10类任务统一建模为一个分类任务,而无需再为每一个子任务单独设计一个模型。
基于上面的思想,作者认为,当一个语言模型的容量足够大时,它就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集。例如:
- 当模型训练完“Micheal Jordan is the best basketball player in the history”语料的语言模型之后,便也学会了(question:“who is the best basketball player in the history ?”,answer:“Micheal Jordan”)的Q&A任务。
综上,GPT-2的核心思想概括为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
2、GPT-2的数据集
GPT-2的文章取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。
3、GPT-2的模型参数
- 同样使用了使用字节对编码构建字典,字典的大小为 50,257 ;
- 滑动窗口的大小为 1,024 ;
- batchsize的大小为 512 ;
- Layer Normalization移动到了每一块的输入部分,在每个self-attention之后额外添加了一个Layer Normalization;
- 将残差层的初始化值用
 进行缩放,其中 N 是残差层的个数。
进行缩放,其中 N 是残差层的个数。
GPT-2训练了4组不同的层数和词向量的长度的模型,具体值见表2。通过这4个模型的实验结果我们可以看出随着模型的增大,模型的效果是不断提升的。
| 参数量 | 层数 | 词向量长度 |
|---|---|---|
| 117M(GPT-1) | 12 | 768 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
4、GPT-2的性能
- 在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法;
- 在“Children's Book Test”数据集上的命名实体识别任务中,GPT-2超过了state-of-the-art的方法约7%;
- “LAMBADA”是测试模型捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6;
- 在阅读理解数据中,GPT-2超过了4个baseline模型中的三个;
- 在法译英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差;
- GPT-2在文本总结的表现不理想,但是它的效果也和有监督的模型非常接近。
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。尽管在有些zero-shot的任务上的表现不错,但是我们仍不清楚GPT-2的这种策略究竟能做成什么样子。
最重要的事,GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了GPT-3。
0x3:GPT-3:初代GPT-3与大规模预训练
初代GPT-3展示了三个重要能力:
- 语言生成:遵循提示词(prompt),然后生成补全提示词的句子。这也是今天人类与语言模型最普遍的交互方式。
- 上下文学习 (in-context learning):遵循给定任务的几个示例,然后为新的测试用例生成解决方案。很重要的一点是,GPT-3虽然是个语言模型,但它的论文几乎没有谈到“语言建模” (language modeling),作者将他们全部的写作精力都投入到了对上下文学习的愿景上,这才是GPT-3的真正重点。
- 世界知识:包括事实性知识(factual knowledge)和常识(commonsense)。
- 长距离理解能力:是多轮对话的基础
那么这些能力从何而来呢?
基本上,以上三种能力都来自于大规模预训练:在有3000亿单词的语料上预训练拥有1750亿参数的模型(训练语料的60%来自于 2016 - 2019 的 C4 + 22% 来自于 WebText2 + 16% 来自于Books + 3%来自于Wikipedia)。其中:
- 语言生成的能力来自于语言建模的训练目标 (language modeling)。
- 世界知识来自 3000 亿单词的训练语料库。
- 模型的 1750 亿参数是为了存储知识,Liang et al. (2022) 的文章进一步证明了这一点。他们的结论是,知识密集型任务的性能与模型大小息息相关。
- 长距离理解能力来自对代码语料库的微调学习。
上下文学习的能力来源及为什么上下文学习可以泛化,仍然难以溯源。 直觉上,这种能力可能来自于同一个任务的数据点在训练时按顺序排列在同一个batch中。然而,目前还没有明确的研究确定语言模型为什么预训练会促使上下文学习,以及为什么上下文学习的行为与微调 (fine-tuning) 如此不同。
0x4:GPT-3.5:存在于大模型而非小模型的涌现能力
从最初的GPT-3开始,为了展示OpenAI是如何发展到ChatGPT的,我们看一下GPT-3.5的进化树:

- 在 2020 年 7 月,OpenAI 发布了模型索引为的 davinci 的初代 GPT-3 论文,从此它就开始不断进化。
- 在 2021 年 7 月,Codex 的论文发布,其中初始的 Codex 是根据(可能是内部的)120 亿参数的 GPT-3 变体进行微调的。后来这个 120 亿参数的模型演变成 OpenAI API 中的code-cushman-001。
- 在 2022 年 3 月,OpenAI 发布了指令微调 (instruction tuning) 的论文,其监督微调 (supervised instruction tuning) 的部分对应了davinci-instruct-beta和text-davinci-001。
- 在 2022 年 4 月至 7 月的,OpenAI 开始对code-davinci-002模型进行 Beta 测试,也称其为 Codex。然后code-davinci-002、text-davinci-003和ChatGPT 都是从code-davinci-002进行指令微调得到的。详细信息请参阅 OpenAI的模型索引文档。
尽管 Codex 听着像是一个只管代码的模型,但code-davinci-002可能是最强大的针对自然语言的GPT-3.5 变体(优于 text-davinci-002和 -003)。code-davinci-002很可能在文本和代码上都经过训练,然后根据指令进行调整。
- 在 2022 年 5-6 月发布的text-davinci-002是一个基于code-davinci-002的有监督指令微调 (supervised instruction tuned) 模型。在text-davinci-002上面进行指令微调很可能降低了模型的上下文学习能力,但是增强了模型的零样本能力。
- 然后是text-davinci-003和 ChatGPT,它们都在 2022 年 11 月发布,是使用的基于人类反馈的强化学习的版本指令微调 (instruction tuning with reinforcement learning from human feedback) 模型的两种不同变体。text-davinci-003 恢复了(但仍然比code-davinci-002差)一些在text-davinci-002 中丢失的部分上下文学习能力(大概是因为它在微调的时候混入了语言建模) 并进一步改进了零样本能力(得益于RLHF)。另一方面,ChatGPT 似乎牺牲了几乎所有的上下文学习的能力来换取建模对话历史的能力。
总的来说,在 2020 - 2021 年期间,在code-davinci-002之前,OpenAI 已经投入了大量的精力通过代码训练和指令微调来增强GPT-3。当他们完成code-davinci-002时,所有的能力都已经存在了。很可能后续的指令微调,无论是通过有监督的版本还是强化学习的版本,都会做以下事情:
- 指令微调不会为模型注入新的能力 —— 所有的能力都已经存在了。指令微调的作用是解锁 / 激发这些能力。这主要是因为指令微调的数据量比预训练数据量少几个数量级(基础的能力是通过预训练注入的)。
- 指令微调将 GPT-3.5 的分化到不同的技能树。有些更擅长上下文学习,如text-davinci-003,有些更擅长对话,如ChatGPT。
- 指令微调通过牺牲性能换取与人类的对齐(alignment)。OpenAI 的作者在他们的指令微调论文中称其为 “对齐税” (alignment tax)。许多论文都报道了code-davinci-002在基准测试中实现了最佳性能(但模型不一定符合人类期望)。在code-davinci-002上进行指令微调后,模型可以生成更加符合人类期待的反馈(或者说模型与人类对齐),例如:零样本问答、生成安全和公正的对话回复、拒绝超出模型它知识范围的问题。
总结来说:
- 语言生成能力 + 基础世界知识 + 上下文学习都是来自于预训练。
- 存储大量知识的能力来自 1750 亿的参数量。
- 遵循指令和泛化到新任务的能力来自于扩大指令学习中指令的数量。
- 执行复杂推理的能力很可能来自于代码训练。
- 生成中立、客观的能力、安全和翔实的答案来自与人类的对齐。具体来说:
- 如果是监督学习版,得到的模型是text-davinci-002
- 如果是强化学习版 (RLHF) ,得到的模型是text-davinci-003
- 无论是有监督还是 RLHF ,模型在很多任务的性能都无法超过 code-davinci-002 ,这种因为对齐而造成性能衰退的现象叫做对齐税。
- 对话能力也来自于 RLHF(ChatGPT),具体来说它牺牲了上下文学习的能力,来换取:
- 建模对话历史
- 增加对话信息量
- 拒绝模型知识范围之外的问题

Wei. et. al. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models。X轴为模型尺寸。GSM8K是是一个小学水平的数学问题集。
在以上的效果图中,我们可以观察到模型的表现:
- 当尺寸相对小的时候提升并不大
- 当模型变大时有很明显的提升
这从根本上说明,某些能力可能不存在于小模型中,而是在大模型中获得的。有很多种突现能力,但目前学术界主流主要对以下能力感兴趣:
- NLP社区近几年都关注但还没实现的能力
- 之前的NLP模型很难达到的能力
- 源自于人类语言最深层的本质的能力
- 可能达到人类智力的最高水平的能力
很多有意思的能力都可以归到上文提到的类别里,在它们之中,我们主要讨论以下三种典型能力:
- 复杂推理,大型模型在没有使用全部训练数据的情况下便显著优于以前的小型模型。
- 知识推理,大型模型可能没有小模型效果好,但大模型不需要额外的知识来源(知识可能很昂贵,或者很难从非结构化数据中抽取)。
- 分布外鲁棒性,这是之前进行模型精调时需要努力解决的问题。大型模型虽然在同分布情况下的效果不如以前的方法,但非同分布情况下的泛化性能却好得多。
复杂推理

虽然这道题对于10岁的孩子来说很容易,但对语言模型来说却很难,主要是由于数学和语言混合在一起。
GSM8K 最初由 OpenAI 于 2021 年 10 月提出。当时他们用第一版GPT3在全部训练集上进行了精调,准确率约为 35%。这个结果让作者相当悲观,因为他们的结果显示了语言模型的缩放规律:随着模型大小呈指数增长,性能呈线性增长(即投入收益不成比例)。因此,他们在第 4.1 节中思考:
“175B 模型似乎需要至少额外两个数量级的训练数据才能达到 80% 的求解率。”
- 三个月后,即 2022 年 1 月,Wei 等人基于 540B PaLM 模型,仅使用了8个思维链提示示例便将准确率提高到56.6% (无需将训练集增加两个数量级)
- 之后在 2022 年 3 月,Wang 等人基于相同的 540B PaLM 模型,通过多数投票的方法将准确率提高到 74.4%
从以上进展可以看到,技术进步确实呈指数级增长。
思维链提示是一个展示模型随着规模突现出能力的典型例子:
- 从突现能力来看:尽管不需要 17500B,但模型大小确实要大于 100B ,才能使思维链的效果大于的仅有回答提示。所以这种能力只存在于大型模型中。
- 从效果来看:思想链提示的性能明显优于其之前的精调方法(目前还没有能公平对比提示词和微调的工作。但当思维链被提出的时候,尽管他们对于提示和精调的比较可能是不公平的,但确实比精调效果要好)。
- 从标注效率上来看:思维链提示只需要 8 个示例的注释,而微调需要完整的训练集。
知识推理
下一个例子是需要知识的推理能力(例如问答和常识推理)

Yu et. al. 2022. 以前的 SOTA 模型需要从外部知识源中检索。GPT-3 的性能与以前的模型相当/优于以前的模型,且无需检索。
如表中所示,与数学题的例子不同,GPT-3 并没有明显优于之前的精调模型。但它不需要从外部文档中检索,本身就包含了知识(虽然这些知识可能过时或者不可信,但选择哪种可信知识源超出了本文的讨论范围)。
为了理解这些结果的重要性,我们可以回顾一下历史:NLP 社区从一开始就面临着如何有效编码知识的挑战。人们一直在不断探究把知识保存在模型外部或者内部的方法。上世纪九十年代以来,人们一直试图将语言和世界的规则记录到一个巨大的图书馆中,将知识存储在模型之外。但这是十分困难的,毕竟我们无法穷举所有规则。因此,研究人员开始构建特定领域的知识库,来存储非结构化文本、半结构化(如维基百科)或完全结构化(如知识图谱)等形式的知识。
通常,结构化知识很难构建(因为要设计知识的结构体系),但易于推理(因为有体系结构),非结构化知识易于构建(直接存起来就行),但很难用于推理(没有体系结构)。然而,语言模型提供了一种新的方法,可以轻松地从非结构化文本中提取知识,并在不需要预定义模式的情况下有效地根据知识进行推理。下表为优缺点对比:
| 构建 | 推理 | ||
|---|---|---|---|
| 结构化知识 |
难构建,需要设计体系结构并解析
|
容易推理,模型结构已经确定,输入和输出的格式都是确定的 | |
| 非结构化知识 | 容易构建,只存储文本即可 |
难推理,强依赖于
|
|
| 语言模型 | 容易构建,在非结构化文本上训练 | 容易推理,使用提示词即可 |
分布外鲁棒性
第三种能力是分布外的鲁棒性。在 2018 年至 2022 年期间,NLP、CV 和通用机器学习领域有大量关于分布偏移/对抗鲁棒性/组合生成的研究,人们发现当测试集分布与训练分布不同时,模型的行为性能可能会显著下降。然而,在大型语言模型的上下文学习中似乎并非如此。Si 等人在2022年的研究显示

Si et. al. 2022. 虽然 GPT-3 在同分布设置下比 RoBERTa 要差,但在非同分布设置下优于 RoBERTa,性能下降明显更小。
同样,在此实验中,同分布情况下基于提示词的 GPT-3 的效果并没有精调后的 RoBERTa要好。但它在三个其他分布(领域切换、噪声和对抗性扰动)中优于 RoBERTa,这意味着 GPT3 更加鲁棒。
此外,即使存在分布偏移,好的提示词所带来的泛化性能依旧会继续保持。比如:

Fu et. al. 2022. 即使测试分布与训练分布不同,复杂提示也始终比简单提示的表现更好。
Fu 等人2022年的研究显示,输入提示越复杂,模型的性能就越好。这种趋势在分布转移的情况下也会继续保持:无论测试分布与原分布不同、来自于噪声分布,或者是从另一个分布转移而来的,复杂提示始终优于简单提示。
在进一步讨论之前,让我们再回顾一下之前的工作,就会发现一个很奇怪的问题:GPT-3 在 2020 年就发布了,但为什么直到现在我们才发现并开始思考范式的转变?这个问题的答案就藏在两种曲线中:对数线性曲线和相变曲线。如下图:

左图: 比例定律. 当模型大小呈指数增长时,相应的模型性能呈线性增长。
右图: 当模型尺寸达到一定规模时,会出现突现能力,让性能急剧增加。
最初,(OpenAI)的研究者认为语言模型的性能与模型尺寸的关系可以通过对数线性曲线预测,即模型尺寸呈指数增长时,性能会随之线性增加。这种现象被称为语言模型的缩放定律,正如 Kaplan 等人在2020年最初的GPT3文章中讨论的那样。重要的是,在那个阶段,即便最大的 GPT-3 在有提示的情况下也不能胜过小模型精调。所以当时并没有必要去使用昂贵的大模型(即使提示词的标注效率很高)。
直到2021年,Cobbe 等人发现缩放定律同样适用于精调。这是一个有点悲观的发现,因为它意味着我们可能被锁定在模型规模上——虽然模型架构优化可能会在一定程度上提高模型性能,但效果仍会被锁定在一个区间内(对应模型规模),很难有更显著的突破。
在缩放定律的掌控下(2020年到2021),由于GPT-3无法胜过精调 T5-11B,同时T5-11B微调已经很麻烦了,所以NLP社区的关注点更多的是研究更小的模型或者高效参数适应。Prefix tuning就是提示和适应交叉的一个例子,后来由 He 等人在 2021统一。当时的逻辑很简单:如果精调效果更好,我们就应该在高效参数适应上多下功夫;如果提示词的方法更好,我们应该在训练大型语言模型上投入更多精力。
之后在 2022 年 1 月,思维链的工作被放出来了。正如作者所展示的那样,思维链提示在性能-比例曲线中表现出明显的相变。当模型尺寸足够大时,性能会显著提高并明显超越比例曲线。当使用思维链进行提示时,大模型在复杂推理上的表现明显优于微调,在知识推理上的表现也很有竞争力,并且分布鲁棒性也存在一定的潜力。要达到这样的效果只需要8个左右的示例,这就是为什么范式可能会转变的原因。
范式转变究竟意味着什么?下面我们给出精调和提示词方法的对比:
| 模型规模 | 学习方法 | 学习范式 | 数据 | 泛化 |
|---|---|---|---|---|
| 小模型 | 微调/精调 | 监督学习 | 完整训练数据集 | 分布内泛化,分布外泛化能力欠佳 |
| 大模型 | 上下文学习 | 自监督学习/无监督学习 | 少量提示词 | 同时泛化到分布内(分布内泛化能力有所损失) + 分布迁移 |
提示词的好处很明显:我们不再需要繁琐的数据标注和在全量数据上进行精调,只需要编写提示词并获得满足要求的结果,这比精调要快很多。
参考资料:
https://mp.weixin.qq.com/s?__biz=MzAxMTk4NDkwNw==&mid=2247492293&idx=1&sn=14f0e33658ee2f33100113c55ebf9e2c&scene=21#wechat_redirect https://mp.weixin.qq.com/s?__biz=MzAxMTk4NDkwNw==&mid=2247492896&idx=1&sn=69484f88ee4bc67221e2a5a08fff8f91&chksm=9bba6c44accde55299c96060366cafa427c63453100df6c4922bb50403d9f36eefd020123a9a&token=1296225236&lang=zh_CN#rd https://zhuanlan.zhihu.com/p/350017443
在应用领域,GPT-4是一个速度倍增器,可以用来强化/增强/辅助/加速现有技术、效率和生产力。
| 产品 | 战略 | AI核心能力 | 定位 | 技术落地形式 | 产品形态 | 产品优势能力 |
|---|---|---|---|---|---|---|
| Microsoft Security Copilot | 数据【威胁情报】+ 算法【AI】+ 算力【云】 | 加速整个pipline处理流程各个环节,提升生产力和效率 | AI并非取代安全人员的工作,而是辅助/赋能安全分析师更高效输出价值 | 延续了ChatGPT的问答模式,核心技术是GPT-4和安全专用模型 | OpenAI GPT预训练模型+微软安全垂直领域语料+安全专家训练的fine-tune小模型+大规模的威胁情报数据+e2e安全工具 |
|
| Bing搜索引擎【AI赋能】 | 待跟进 | |||||
| Office套件【AI赋能】 | 待跟进 | |||||
| 恶意代码检测 |
|
大模型在每一个领域的应用效果,取决于后训练的数据质量,其本质上是对大模型的引导程度和引导深度。
GPT大模型的出现,引发了对知识和人脑智能机制的重新理解。
- “预训练”是指科技巨头通过大量文本语料库的训练,教会它语言的基本模式和关系——简而言之,是教它理解世界。
- “生成式”意味着AI可以从这个基础知识库中创造新的想法。
但是,其实GPT在”创造“新想法的时候,其实并没有引入新的语料库,也没有修改原始模型,它本质上只是在自己的模型中进行”搜索“。也就是说,这些所谓的”被创造“出来的”新知识“,其实一早就已经存在于GPT内部的网络中,只是在等待对应的”引导(prompt)“去激发出这些新知识。
这让笔者想起了一句话:
人生的很多底层道理其实在很小的时候就知道了,之后的人生只是通过经历不同的人和事,从不同的角度去理解它们。
脑科学中有一种说法,大脑类似一个神经元网络,在儿童发育初期,整个神经网络就发育完全了,也即在硬件层面就已经具备了完整的”模型能力“了,后天的学习和历练,就是通过不断的”预训练“,调整和激活整个神经网络更多的预测路径,最终表现出来的宏观结果就是,似乎随着不断的成长和学习,大脑具备了越来越好的创造力。
对于GPT模型来说,模型参数永远是固定不变的,本质是在做预测任务,多轮对话的本质是不断扩充input,
比如下面的例子:



可以看到,通过不断的对话,不断扩充了input,激活了模型更多的神经元,回答地就更精确了。
笔者认为,其本质是因为GPT模型内部的搜索空间和路径预测空间十分巨大,因此,通过调整和明确的instruction tuning,可以获得不同精确程度的预测路径,这在宏观上就表现出了一种”创造性“行为。

而预训练大模型+小模型fine-tune的本质是重新做训练任务,决定最终效果的因素可能包括:
- 基模型本身的泛化能力,以及在新的任务上的迁移能力
- 小模型自身的复杂程度
- 训练语料库的质量
参考资料:
https://www.kunchengblog.com/essay/ilya https://toooold.com/2023/04/08/magnificient_underdogs.html?continueFlag=34ed6b02ba678ae8608c3a02e8607732
如果说近十几年来,全球的”算法工程师“相当于60年代”大跃进“时普遍搞”小烟囱式“的小模型(相比GPT),当GPT-4技术出来后,相当于出现了”首钢/宝钢“这类的大型垄断企业,小作坊式的小算法模型将彻底被放进历史博物馆。
少数头部机构/公司基于语料库+计算能力的绝对壁垒,将垄断大模型的研发和迭代,下游各个领域的业务工程师则基于这些预训练大模型开发自己的垂直领域小模型(仅仅需要喂入领域数据对大模型进行fine-tune)。
先展望一下在大模型应用端的几种可能应用形态:
- 现有产品接入OpenAI API
- 基于开源类GPT大模型+领域小模型fine-tune,训练出垂直领域xGPT模型
- 如果遇到国家间技术封锁,则依赖国内公司自研国产大模型,使用其服务和资源
具体到应用领域上,其实网络安全几乎所有领域都可以找到结合点。从最抽象的层面来看,”问答“的本质就是”输入-输出“模型,这里输入可以是一个样本、一条日志、一段shellcode、一个问题,这里输出可以是一个样本分析结果、一个入侵判断结果、一个入侵/回溯处置建议。
- 增强攻击欺骗技术:预设不同的角色给到GPT模型,例如终端角色,如果攻击者输入cat /etc/passwd,GPT就会返回相应信息,以假乱真,生成符合预期的与攻击者交互的“攻击和响应”对话内容,但也要注意拦截偏离预期的回答。
- 增强可信纵深检测和防御体系:预设场景提问,给出预期内行为的定义,让GPT直接去预测。或是给出正常行为数据,让GPT自己总结出预期内行为的特征和规律,辅助/加速做可信策略。
值得注意的是, 拥抱大模型对于网络安全从业者提质增效而言肯定是一个正确甚至必要的方向。事实上,如果不考虑信息泄露风险的话,在安全产品研发过程中直接使用ChatGPT这类大模型就可以直接获得显著的开发效率和质量提升。然而,要想实现系统和全面的智能安全化,还有很多基础性的工作需要去做,同时还有一些关键问题需要探索。以下是相关的几点思考和建议。
- 扎实做好安全垂直领域的数字化和知识化积累。大模型不仅可以为安全产品的数字化和知识化提供技术和业务背景知识,而且还为我们整合数字化和知识化平台中的信息和知识提供了一种有力的手段。
如有侵权请联系:admin#unsafe.sh