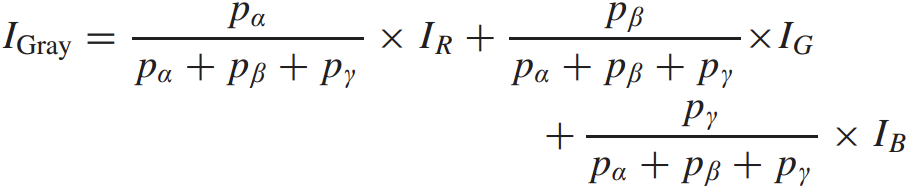
每周文章分享2023.04.10-2023.04.16简介标题: Lightweight Deep Neural Network for Joint Learning of Underwater Ob 2023-4-15 07:4:18 Author: 网络与安全实验室(查看原文) 阅读量:23 收藏
每周文章分享
2023.04.10-2023.04.16
简
介
标题: Lightweight Deep Neural Network for Joint Learning of Underwater Object Detection and Color Conversion
期刊: IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no, 11, pp. 6129-6143 November 2022.
作者: Chia-Hung Yeh, Chu-Han Lin, Li-Wei Kang, Chih-Hsiang Huang, Min-Hui Lin, Chuan-Yu Chang, and Chua-Chin Wang.
分享人: 河海大学——朱远洋
研究背景
水下目标检测是海洋探测、水下目标监测以及水下机器人等领域的关键问题。相较于在空气中,基于光学成像设备获取水下图像更加困难。由于水下光照条件的限制以及水的吸收和散射等因素的影响,水下图像常常出现模糊、失真和色彩失真等问题。这些问题使得传统的目标检测算法难以准确地识别水下目标。此外,不同的水下环境和光源条件也会导致水下图像颜色的变化,从而使得目标的颜色特征难以用来进行准确的识别。对于电池供电的自主式水下航行器(AUV)而言,将低复杂度或低功耗的算法实现嵌入其中以执行相关任务是至关重要的。也就是说,在最大化整体系统效率的同时,为水下执行的期望任务设计低复杂度模型将是有益的。因此,如何提高水下目标检测的准确性、鲁棒性和高效性一直是水下视觉领域的一个研究热点。
关键技术
本文提出了一种轻量级的深度水下目标检测网络,该网络能够同时学习水下图像的颜色转换和目标检测。该网络的关键技术包括图像颜色转换模块、目标检测模块和联合学习策略。图像颜色转换模块旨在将彩色图像转换为对应的灰度图像,以解决水下颜色吸收的问题,从而提高目标检测性能,并降低计算复杂度。目标检测模块采用了一种基于锚点框和特征金字塔网络(FPN)的单阶段目标检测器,能够有效地处理不同尺度和形状的水下目标。联合学习策略通过共享卷积层和使用多任务损失函数,实现了图像颜色转换和目标检测两个任务之间的互相促进和优化。作者在树莓派平台上实现了该网络,并在公开的水下数据集上与其他先进方法进行了对比实验,结果表明,该网络具有较高的目标检测精度和较低的运行时间。
本文的主要创新和贡献有三个方面:
1)针对电池供电的AUV的应用,本文提出了一个用于水下目标检测的轻型深度模型。依靠多尺度特征学习网络,所提出的深度网络被证明是轻量级的,而不会明显牺牲在Raspberry pi平台上实现的目标检测精度。
2)与最先进的水下目标检测框架不同,本文提出了联合学习图像颜色转换和目标检测的过程,以解决水下颜色失真和散射效应的问题,提高检测性能。
3)基于水下图像的训练样本难以收集的事实,本文提出了生成训练水下图像,以很好地训练所提出的深度目标检测模型。
算法介绍
1. 水下图像训练样本的生成
由于很难找到合适的水下图像数据集,特别是对于鱼类、残骸和潜水员等对象,本文提出生成相关的样本图像,用于提出的深度模型学习。如图1(a)所示,从互联网上收集了几张水下图像,形成要生成的图像的背景。图像选择器模块从注释过的图像集中随机地、手动地挑选出鱼类、碎片或潜水员等目标,作为目标成分(或前景)嵌入到背景水下图像中。为了考虑目标的各种尺度,尺度修改器模块旨在修改尺度和长宽比,为每个目标形成不同的版本(不同的尺寸)。
图1 (a)拟议的生成过程,用于生成包含目标的水下训练图像。(b)基于提议的生成过程的一些水下图像
为了将目标自然地融合到水下背景图像中,色彩转换模块首先将所有的目标和背景图像从RGB(红、绿、蓝)色彩空间转换到HSI(色调、饱和度和强度)色彩空间。然后,目标图像的色调值被调整为与其目标水下背景图像的色调值相近:对于要融合到水下背景图像B中的目标图像O,将B的所有像素的平均色调值(H_B)分配给O的每个第i个像素的色调值(Hi_O),即,设置所有i的Hi_O = H_B,O的饱和度和强度值保持不变。因此,目标图像可以与背景图像融合。此外,图像调整器模块被用来随机调整背景图像中要粘贴的目标(可能是旋转了一些角度)的位置。最后,“Annotation Creator”用于为每张融合的图像注释附加信息,包括每个目标i的中心点坐标(Xi和Yi)、宽度(Wi)和高度(Hi)。图1(b)显示了一些由提议的生成过程(图1(a))获得的水下图像用于的深度模型学习。
2. 轻量级深度目标检测网络
如图2所示,所提出的用于水下目标检测的轻量级深度神经网络主要由图像颜色转换网络和水下目标检测网络组成。通过整合多尺度预测的FPN的想法,采用了轻量级实现目标检测网络。此外,为了在方法中嵌入水下图像特征,使用联合学习所提出的颜色转换网络和所提出的目标检测网络,用于调整水下图像的颜色信息,同时实现更好的目标检测性能。
图2 提出的用于水下目标检测的轻量级深度神经网络
A. 深度模型中的色彩转换网络模块
如图2左侧所示,图像颜色转换网络以RGB水下图像为输入,输出三个参数进行颜色转换。这三个参数(pα、pβ、pγ)用于将输入的RGB转换为其相应的灰度Igray,其表示方法为:
其中IR、IG和IB分别表示输入的红色、绿色和蓝色通道,三个参数pα、pβ、pγ是由颜色转换网络学习的。
颜色转换网络由十个轻量级卷积层组成。前五个卷积层旨在从输入图像中提取特征。下面的卷积层是根据MobileNets的思想而设计的。在论文中使用的深度可分卷积首先使用大小为1×1的核进行逐点卷积,以降低上一层输出的维数。然后,通过对大小为3×3的核进行深度卷积,进行特征提取以生成每个颜色通道的变换参数。
深度可分离卷积层之后是max-pooling层和通道组合层,以产生转换后的灰度图像。在颜色转换模块的最后应用max-pooling层的主要目的是为了避免特征学习过程中可能出现的噪音。在这一层中,核大小和步长分别被设定为10×10和1。通道组合层被设计用来执行颜色转换。然后,如图2所示,“Channel duplication and concatenation”块将转换后的灰度图像的通道复制三次,并将其连接起来,形成三个通道的输出灰度图像。然后,由输入图像转化而来的灰度图像被送入物体检测网络模块。
为了训练提出的颜色转换网络,采用了三种不同的损失函数。由于彩色图像没有真实灰度图像,这里使用的损失函数依赖于生成的灰度图像的自相关,以及与彩色版本相比,生成的灰度图像保留了图像特征和风格。更具体地说,为了鼓励生成图像的空间平滑性,采用了总变化(TV)损失函数,其定义为:
还使用了两个感知损失函数。第一个是特征重构损失,其定义如下:
其中y和y ̂分别表示输入的彩色图像和生成的灰度图像。对于生成的灰度图像,为了与输入的彩色图像保持一致,通过将灰度通道堆叠三次,将通道数设置为3。φ(y)表示一个特征提取器,用于从图像y中提取特征表示。基于ImageNet的多样性,使用预训练VGG-16作为φ的骨干。使用的第二个感知损失函数是基于Gram矩阵的样式重构损失,其由下式表示:
G(y)是y的Gram矩阵,||·||2F表示平方的Frobenius规范。
B. 深度模型中的目标检测网络模块
在所提出的深度模型中,目标检测网络模块由特征提取网络模块和特征聚合网络模块两个子模块组成。所提出的特征提取网络模块是为了从色彩转换网络模块的输出图像中进行特征提取,以实现物体检测。如图2右侧所示,特征提取网络模块由特征提取CNN模块(图2中用“Feature extraction Conv”表示)、感受模块和卷积层级联组成。
如图3所示,特征提取CNN模块包括一个输入层,然后是一个max-pooling层、三个卷积层和一个输出层。特征提取CNN模块主要用于提取初始特征,将输入特征图的空间大小减半。第一阶段的特征提取CNN模块采用了1×1的卷积运算,核大小为1×1×32,使通道大小增加一倍。其主要目的是为了增加初始阶段的特征图,以便后续的特征提取过程。另一方面,对于后续阶段使用的每个特征提取CNN模块,1×1卷积运算被用来将通道大小减半,以减少特征大小并降低计算复杂性。
图3 拟议的特征提取网络中的特征提取CNN模块
为了弥补可能出现的特征提取不充分的问题,提出了感受模块来进一步完善前一特征提取CNN模块的特征。感受模块用于有效地提取输入特征图的多尺度特征。主要目标是在低计算复杂度下保持特征表示能力。如图4所示,拟议的感受模块由一个扩展层、一个挤压层和一个快捷连接组成。扩展层是基于inception v3架构。在低维嵌入上可以实现空间聚合,而不会有明显的表示能力损失。扩展层的结构与inception v3不同,也比它简单(有更多的卷积层和更大的内核尺寸)。此外,用多尺度处理扩展网络有利于提取多尺度特征,这对检测图像中较大或较小的物体很有用。在扩展层之后是挤压层,它只进行一次1×1的卷积运算,以减少特征通道的数量。为了保留感受模块的输入特征图并避免梯度消失的问题,使用了一个快捷连接来直接传输输入,与挤压层的输出相连接,形成感受模块的输出。然后,感受模块的输出被送入卷积运算,内核大小为3×3,跨度大小为1。
图4 拟议的特征提取网络模块中的感受模块
在特征提取网络模块中,级联了五个阶段。前四个阶段中的每个阶段都由特征提取CNN、感受模块和卷积层组成。第五阶段只包括一次CNN特征提取。后三个阶段的输出将被馈送到特征聚合网络模块。特征聚合网络模块是根据FPN架构的思想设计的,用于连接特征提取网络模块。其关键属性是开发一个具有横向连接的自上而下的架构,用于提取所有尺度的高级语义特征图。如图2所示,在特征聚合网络模块中,有三个连接点与特征提取网络(自上而下的架构)相连。特征聚合网络模块被设计成自下而上的架构,由两个横向连接块(如图5所示)和几个卷积层组成。横向连接块是为了合并来自自下而上路径(特征聚合网络模块)和自上而下路径(特征提取网络模块)的相同空间分辨率的特征图。
图5 拟议的特征聚合网络模块中的横向连接块
如图5所示,横向连接块由一个上采样层、一个连接层(用于连接放大的特征图和来自特征提取网络模块的特征图)和一个卷积层组成。在特征提取网络模块的第三、第四和第五阶段将向特征聚合网络模块输出特征图。特征聚合网络将最终产生三个不同级别的输出,用于不同尺度的物体检测,也就是说,基于学到的特征金字塔,可以在各个级别独立地进行物体预测。
为了训练所提出的目标检测网络,直接使用YOLOv3中使用的损失函数,表示为Ldetection:
最后,为了联合训练所提出的颜色转换网络和所提出的目标检测网络,总损失函数被表示为:
其中四个加权系数(λTV、λfeature、λstyle和λdetection)根据经验被分别设置为10、1、1和1。
实验结果分析
1. 网络训练和参数设置
选择8000张图片进行训练,2000张图片进行验证。数据集在鱼类、垃圾和潜水员类别中分别约为图像总数的20%、50%和30%。每个图像的大小为320×320,批次大小设置为32。在实验中,学习率最初被设定为0.001,如果每期10个epochs的损失没有进一步减少,则以0.1递减。如果在20个epochs中损失没有进一步减少,就会触发提前停止。此外,所提出的深度模型中使用的激活函数是漏整流线性单元(Leaky ReLU)函数,模型参数是根据权重初始化技术进行初始化。损失函数使用Adam优化算法进行最小化。基于Keras和PyTorch平台的设置,通过80个epochs可以得到一个收敛的深度网络。实验中没有使用预训练的模型。训练在配备英特尔酷睿i7-8700k处理器、32 GB内存和NVIDIA GeForce GTX 1080 GPU的个人计算机上实现的。
2. 量化结果
为了模拟用于水下环境的电池供电的AUV,在Raspberry Pi 3 B+上实现了基于深度学习的目标检测器,该模型带有ARM CortexA53、1.4 GHz CPU、双核多媒体协处理器GPU、1GB RAM和5.661-W的最大工作功率。使用了四个最先进的目标检测框架进行比较,分别是Faster R-CNN、SSD、YOLO和Tiny-YOLO。在实验中,用于Faster R-CNN、SSD、YOLOv2和YOLOv3框架的骨干分别是VGG-16、ResNet-101、Darknet-19和Darknet-53。同样的数据增强技术(提出的训练样本生成方法)被用于训练所有被评估的用于目标检测的深度模型。这四种被比较的方法也在同一平台上实现,并与所提出的方法一起进行评估,评估内容包括目标检测的平均精度(mAP)、所需的千兆浮点运算(GFLOPs)、每幅图像的平均处理时间(秒)和每秒处理的平均帧数(FPS,即帧率),用于系统性能评估。如表1所示,从计算复杂性的角度来看,所提出的方法在GFLOPs、每幅图像的处理时间和FPS指标方面明显优于这四种最先进的方法。需要注意的是,四种对比模型过于复杂,无法嵌入到所使用的树莓派平台来处理多个连续的帧。它们通常可以处理一帧,而在处理下一帧时,系统就没有资源了。
表1 在Raspberry Pi 3 B+上的定量性能评估
3. 颜色转换网络的消融研究
在这项研究中,对以下三种方法进行了评估。第一种是只使用提议的物体检测网络而不加入提议的颜色转换网络(用Proposed w/o color conversion表示)。第二种是采用基于标准色彩空间的色彩转换作为预处理阶段,将输入的彩色图像转换为相应的灰度版本(用Proposed with standard color conversion表示)。此外,第三种方法是本文提出的完整的深度框架,包括颜色转换和目标检测的联合学习(用Proposed表示)。从表2中可以看出,完整的拟议深度模型(具有较少的训练迭代次数和略高的GFLOPs)在目标检测的mAP方面优于没有颜色转换的方法和具有标准颜色转换的方法。
表2 颜色转换网络的评估结果
4. 训练样本生成的消融研究
通过只使用真实的训练样本,排除生成的训练图像,来训练另一个物体检测器(用proposed w/o generated samples表示)。为了训练没有生成的训练样本的深度模型,遵循与之前描述的带有生成的训练样本的拟议深度模型相同的参数设置。表3显示了由无生成样本的方法和完整的拟议框架(有生成的训练样本)获得的物体检测的mAP性能。从表3中可以看出,人为地增加训练样本确实会带来更好的物体检测性能。
表3 有无训练样本生成方法的实验结果
5. 总变化(TV)损失的加权系数选择
为了凭经验决定由(7)定义的损失函数中使用的TV项的最佳加权系数λTV,使用了不同的值,同时将λfeature、λstyle和λdetection的所有值固定为1,并在表4中报告了相应的检测精度。基于表4,在本研究的所有实验中,λTV被经验性地设定为10。
表4 不同权重值的TV损失函数的结果
总结
本文针对水下图像处理中的一个重要问题,即水下图像的退化,提出了一种轻量级的深度水下目标检测网络。本文的创新点是提出了一种深度模型,用于联合学习水下图像的颜色转换和目标检测。该模型由两个子模块组成:图像颜色转换模块和目标检测模块。图像颜色转换模块旨在将彩色图像转换为相应的灰度图像,以解决水下颜色吸收的问题,从而提高目标检测性能并降低计算复杂度。该模块利用无监督学习来实现颜色转换。目标检测模块旨在在灰度图像上进行目标检测,以识别和定位水下物体。该模块利用有监督学习来实现目标检测。本文在树莓派平台上实现了所提出的轻量级联合学习模型,具有更低的运行时间和内存占用。
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh