2023-4-17 18:1:7 Author: bbs.pediy.com(查看原文) 阅读量:11 收藏
-
-
[原创]DynamoRIO源码分析(二)--基本块(Basic Blocks)和跟踪 (trace)
-
17小时前 264
-
[原创]DynamoRIO源码分析(二)--基本块(Basic Blocks)和跟踪 (trace)
上篇我们分析到劫持了目标程序,进行了一系列初始化并且注册了收集覆盖率信息的回调函数,最后以一个干净的堆栈调用d_r_dispatch。现在我们还没有运行目标程序的代码,本章将讲述DynamoRIO如何运行目标程序代码。
下图演示了DynamoRIO的高级设计。DynamoRIO通过将应用程序代码复制到代码缓存中来执行目标应用程序,每次复制一个基本块。代码缓存是通过从DynamoRIO的调度状态到应用程序的调度状态的上下文切换进入的。

现在我们开始,由于我在上篇分析到d_r_dispatch的时候打了快照,现在恢复快照:
请注意dcontext->next_tag为目标进程主线程的EIP(RtlUserThreadStart)

现在我们来分析d_r_dispatch,同样的,我们只保留关键的操作,简化后的函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
现在得到简化后的d_r_dispatch函数,我们以动态跟踪详细分析各个函数的作用。
在执行的过程中发现前面的函数都没有为targetf赋值,直到build_basic_block_fragment函数:

因此我们首先分析build_basic_block_fragment,之后再分析前面的函数做了哪些操作。
build_basic_block_fragment
从名字上就能看出此函数创建了基本块。基本块是从入口点开始,直到到达控制转移(控制转移说白了 就是如跳转,call,ret等,这种不按程序的语句流程执行的指令)。下图便是一个基本块:

首先笔者先带大家了解常见的控制转移指令的缩写:cti(Control Transfer Instructions 控制转移指令),ubr(Unconditional Branch Instruction 无条件跳转指令如jmp),cbr(Conditional Branch Instruction 条件分支指令),mbr(通过寄存器等的间接分支)
现在我们开始分析build_basic_block_fragment此函数,简化后如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
让我们来逐个分析各个函数的作用
init_interp_build_bb
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
可以看到init_interp_build_bb此函数为bb分配了空间,并对bb进行了初始化操作。执行此函数后bb的结构如下:

build_bb_ilist
此函数十分庞大,因为它维持着一个基本块的解码操作,我们将之简化后如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
|
终于我们完成了对此函数的大致解读,为了让我们更加清晰,笔者将通过动态调试分析此过程
首先让我们执行到while (true) ,此时cur_pc为772641e0:

运行decode函数,此时应解码成cmp指令,将此指令填充到bb->instr结构:

此时opcode为0xe,

随后发现其不是cti指令将此cmp指令加入到bb->ilist:


接着解码下一条指令,发现其为条件跳转指令,将其加入ilist跳出while循环,将下一条指令地址给bb->exit_target:

创建ilist的过程还没有结束,因为此条件跳转指令带来了两个分支,为了确定采用了哪个分支,DynamoRIO在条件跳转指令后再添加一个jmp指令,jmp的跳转地址为bb->exit_target(也就是条件跳转指令的下一条指令)。将此jmp语句加入到ilist中。
还没有结束因为还有一个函数我们没有分析,client_process_bb这个函数是在while循环结束后调用的。还记得上篇中我们注册的收集覆盖率信息的回调吗。client_process_bb将调用我们注册的回调。
client_process_bb
回调的调用过程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
|
从上面可知最终是由call_all_ret宏调用,call_all_ret调用了bb_callbacks.callbacks。我们来看看bb_callbacks是什么结构:

可以看到调用的是drmgr!drmgr_bb_event,我们跟进drmgr_bb_event后发现它又调用了drmgr_bb_event_do_instrum_phases。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
|
我们注册的是analysis回调类型,关于回调类型描述可以在官网查询。
之后通过 e->cb.pair.analysis_cb调用我们注册的回调:

关于回调是如何收集覆盖率信息的,将在下篇分析。
总结
我们现在总结一下build_bb_ilist执行过程。首先会解码出一个原始基本块,之后会调用注册的回调,最后记录一些参数并将基本块变成想要的模样。
emit_fragment_ex
函数代码如下 :
1 2 3 4 5 6 7 |
|
此函数是一个封装,核心代码在emit_fragment_common中。
emit_fragment_common
简化后如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
我们知道了emit_fragment_common的大致流程,但仍感觉一头雾水。没关系,接下来通过实践来将此函数的功能呈现。
调用fragment_create创建f,f的结构如下:


请注意这两个数值
tag:为基本块在原始代码中的基址。
start_pc:此基本块在代码缓存中的基址,此时还没有将基本块写入到代码缓存中。
同时,我们注意到f的地址为0x20cc520c。你肯定有疑问为什么start_pc的值为0x20d01004,而不是从0x20d01000开始的。我们查看0x20d01000里的值发现里面存放了f的地址:

此外还为在f后面为每个cti指令创建linkstubs结构,但此时还没有赋值:

接下来执行set_linkstub_fields,此函数将ilist中的每个instr编码到f的代码缓存中,但会将inst中分支目标pc改为自己指令的pc:

并且会为linkstubs赋值:

现在我们终于复制了一份基本块并将它加载到了代码缓存中,但是有一个问题,当切换上下文并执行这个基本块后该怎么切换上下文回到DynamoRIO以复制下一个基本块。这就需要用到exit stub。
接着执行遍历linkstub_t,为l->stub_pc赋值此值为exit stub,将代码缓存中cti指令的目标地址设置为exit stub:


接下来再执行就是关于链接的操作了,由于现在我们内存中只有一个基本块,还无法做到链接。链接操作将在之后分析,现在主要关注这个基本块是怎么被执行的。
总结:
此函数的核心就是将ilist加入到代码缓存中。代码缓存结构如下表示:

exit_interp_build_bb
1 2 3 4 5 6 7 8 9 10 |
|
此函数最后做了清理操作。
到此build_basic_block_fragment大致分析完毕,就差一个链接部分之后分析。
回看d_r_dispatch函数,此时我们拿到了targetf,下一个执行的函数理应是monitor_cache_enter(dcontext, targetf);但此函数控制着trace的创建,此过程在之后分析。
targetf != NULL 跳出循环,之后执行dispatch_enter_fcache。
dispatch_enter_fcache
简化后如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
从上面可以看到此函数核心就是(*entry)(dcontext);我们跟踪看看entry是什么:

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
|

经过上下文切换,终于执行到了代码缓存中的基本块,真是一个复杂的过程!
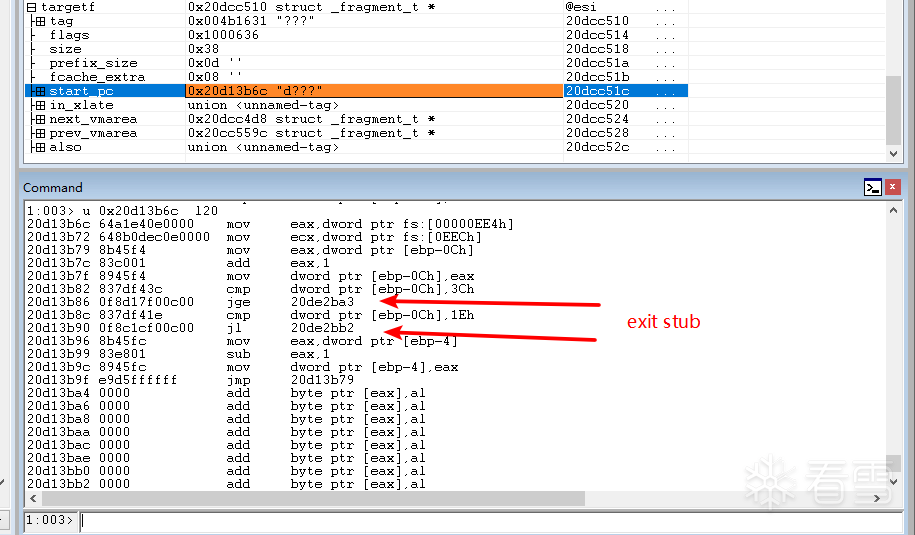
执行完cmp指令之后执行je指令跳转到exit stub:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
|
可以看到将目标进程上下文保存之后再切换回DynamoRIO的上下文,之后再调用d_r_dispatch。但此时有一个问题,DynamoRIO将怎么知道我们到底执行了哪个分支,我们将要复制的下一个基本块的地址又是什么?
d_r_dispatch的dispatch_enter_dynamorio将处理以上问题
dispatch_enter_dynamorio
1 2 3 4 5 6 7 8 9 10 11 12 |
|
首先会将dcontext->last_fragment赋值为上个fragment_t

根据eflags选择到底选择哪个linkstub_t 之后赋值给dcontext->last_exit,我们是运行的是je指令因此last_exit 应该为0x20cc522c:


同时dcontext->next_tag也执行了目标进程中下一个基本块。到此我们跟踪了一个基本块从创建到执行的过程。总算对DynamoRIO有了更深入的了解。但是又有一个问题,我们不可能每次复制一个基本块后上下文切换执行基本块再次上下文切换回DynamoRIO再复制。这样会造成大量的资源浪费在切换上下文。如果是一个直接分支指令将两个基本块相连,我们可不可以在代码缓存中将这两个基本块链接起来。
链接
为了更好理解这个过程我们将程序运行到test.exe的main函数中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
|
也就是让dcontext->next_tag为004b1600:

执行一次build_basic_block_fragment之后将地址0x004b1600到0x004b1617的基本块复制到代码缓存中,再次执行build_basic_block_fragment,其中emit_fragment_common的link_new_fragment将执行链接操作,他会将两个存在于代码缓存中,且由直接分支定位的基本块,将这两个基本块链接起来(跟踪头除外):




昂贵的上下文切换被简单的跳转代替。
此外link_new_fragment还会进行标记跟踪头的操作。
跟踪
什么是跟踪,这里我们使用官方原话:
为了提高间接分支的效率,并实现更好的代码布局,经常按顺序执行的基本块被缝合到一个称为跟踪的单元中。卓越的代码布局和跟踪中的块间分支消除提供了显著的性能提升,跟踪的最大好处之一是通过将间接分支的流行目标内联到跟踪中来避免间接分支查找。
简单来说就是将循环执行的代码(比如for,while)看成一个整体复制到代码缓存中,同时内联间接分支。
跟踪的实现过程如下:
DynamoRIO的跟踪基于 Next Executing Tail (NET)方案,NET通过将计数器与每个跟踪头关联来进行操作。跟踪头要么是向后分支(目标循环)的目标,要么是现有跟踪的出口(称为辅助跟踪头)。计数器在每次执行跟踪头时递增。一旦计数器超过一个阈值(通常是一个很小的数字,比如50),就会进入跟踪创建模式。这意味着在之后执行的下一个基本块序列将连接在一起成为一个新的跟踪。当跟踪到达向后分支或另一个跟踪或跟踪头时,跟踪将终止。DynamoRIO修改了NET,使其不将向后间接分支目标视为跟踪头。这样做的好处是将更多的间接分支内联到跟踪中。
简单来说就是如果一个循环执行了50次,第51次执行的时候将他创建成跟踪,同时内联间接分支。
现在我们大致知道了什么是跟踪。回看我们的程序,我们猜测由i引导的for循环应该被创建成trace。让我们验证此过程:
地址0x004b165a处的jmp语句会跳转到0x004b1631,发现其为后向分支的目标,于是由link_new_fragment将0x004b1631处的基本块标记为跟踪头。之后一直进行循环,有一点要注意有没有发现循环执行的代码已经存在于代码缓存中了,在这种情况下fragment_lookup_fine_and_coarse会查找代码缓存,一旦发现其已经存在于代码缓存中,就将targetf赋值,这样就不需要再次调用build_basic_block_fragmen创建基本块了。
最后让我们查看monitor_cache_enter的实现过程
monitor_cache_enter
此函数比较复杂,同样我们将之简化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
|
创建跟踪后如下:



可以看到进行了优化,将循环创建成为一个trace。
终于我们完成了对d_r_dispatch这个核心控制函数的解读,但其实还有很多细节我们没有讲解,比如间接分支,他是如何通过哈希查找的,trace是如何内联间接分支的,感兴趣的可以自行去研究。
现在回顾整个过程,真的能感受到DynamoRIO作者为了能监控控制整个程序所进行的疯狂操作。这种大胆且细致的行为,真是让人着迷!
下一章我们将研究到底什么是覆盖率信息,如果我们创建了一个新线程,DynamoRIO应该怎么拿到此线程的控制权。
个人能力有限,最后如果有什么分析错误的地方,请一定指点斧正。
最后于 16小时前 被DriverUnload编辑 ,原因:
返回
如有侵权请联系:admin#unsafe.sh