2023-4-18 21:28:0 Author: www.cnblogs.com(查看原文) 阅读量:277 收藏
0x1:为什么要微调
- 对于数据集本身很小(几千张图片/几千段文本)的情况,从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。这时候如果还想用上大型神经网络的超强特征提取能力,只能靠微调已经训练好的模型。
- 可以降低训练成本(时间成本、计算架构成本、大语料成本):如果使用导出特征向量的方法进行迁移学习,后期的训练成本非常低,用低配GPU就可以训练。
- 前人花很大精力训练出来的模型在大概率上会比你自己从零开始搭的模型要强悍,没有必要重复造轮子。
人工智能的快速发展推动了大模型的广泛应用,它们在语言、视觉、语音等领域的应用效果已经越来越好。但是,训练一个大模型需要巨大的计算资源和时间(计算架构壁垒、大语料壁垒),为了减少这种资源的浪费,微调已经成为一种流行的技术。微调是指在预训练模型的基础上,通过在小数据集上的训练来适应新的任务。
传统的线性过程思维是”因果一一对应“,我们设定了什么规则和指令,结果就是完全一一按照我们的规则/指令生成的,不会产生模糊和意外之外的结果。但是到了神经网络,尤其是超大型神经网络中,由于参数空间和语料库都十分巨大,因此在超高维的参数空间中,知识的储存是以一种很抽象/高维的形式存在。通俗上理解就是:大模型通过学习了大语料之后,储存了大语料中包含的深层次知识,这些知识在不同的子领域都具备一定程度的迁移能力。所谓微调,本质上就是通过新领域语料库对模型的权重参数进行指向性微调(或者是增加一些新的结构,在新的结构上进行微调),从而使新的大模型具备在新的垂直领域上的预测路径。
0x2:如何进行微调
AIGC(AI芯片)的出现进一步加快了大模型的推广,它可以提供更快的计算速度和更大的存储容量。本文将介绍AIGC下大模型微调的方法。
- 微调所有层:将预训练模型的所有层都参与微调,以适应新的任务。
- 微调顶层:只微调预训练模型的顶层,以适应新的任务。
- 冻结底层:将预训练模型的底层固定不变,只对顶层进行微调。
- 逐层微调:从底层开始,逐层微调预训练模型,直到所有层都被微调。
- 迁移学习:将预训练模型的知识迁移到新的任务中,以提高模型性能。这种方法通常使用微调顶层或冻结底层的方法。
使用Paddle实现ChatGPT模型的五种微调方法:
微调所有层
import paddle from paddlenlp.transformers import GPT2Model, GPT2ForPretraining, GPT2PretrainingCriterion # 加载预训练模型 model = GPT2ForPretraining.from_pretrained('gpt2-medium-en') tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium-en') # 定义新的分类头 class_num = 2 cls = paddle.nn.Linear(model.config["hidden_size"], class_num) # 将新的分类头添加到模型中 model.cls = cls # 通过微调所有层来适应新任务 optimizer = paddle.optimizer.Adam(learning_rate=1e-5, parameters=model.parameters()) criterion = GPT2PretrainingCriterion()
微调顶层
import paddle from paddlenlp.transformers import GPT2Model, GPT2ForPretraining, GPT2PretrainingCriterion # 加载预训练模型 model = GPT2ForPretraining.from_pretrained('gpt2-medium-en') tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium-en') # 固定模型底层,只微调顶层 for param in model.parameters(): param.trainable = False # 定义新的分类头 class_num = 2 cls = paddle.nn.Linear(model.config["hidden_size"], class_num) # 将新的分类头添加到模型中 model.cls = cls # 通过微调顶层来适应新任务 for param in model.cls.parameters(): param.trainable = True optimizer = paddle.optimizer.Adam(learning_rate=1e-5, parameters=model.cls.parameters()) criterion = paddle.nn.CrossEntropyLoss()
冻结底层
import paddle import paddle.nn.functional as F from paddlenlp.transformers import GPTForPretraining, GPTChineseTokenizer # 加载预训练模型和分词器 model = GPTForPretraining.from_pretrained('gpt-cpm-large-cn') tokenizer = GPTChineseTokenizer.from_pretrained('gpt-cpm-large-cn') # 构造数据集和数据加载器 train_ds = [['今天天气不错'], ['明天要下雨'], ['这个季节很适合旅游']] train_ds = [{'text': text} for text in train_ds] def batch_iter(data, batch_size): num_batches = len(data) // batch_size if len(data) % batch_size != 0: num_batches += 1 for i in range(num_batches): batch = data[i * batch_size: (i + 1) * batch_size] yield batch batch_size = 2 train_loader = paddle.io.DataLoader(train_ds, batch_size=batch_size, shuffle=True, drop_last=True) # 构造优化器和损失函数 optimizer = paddle.optimizer.AdamW(parameters=model.parameters(), learning_rate=1e-4) criterion = F.cross_entropy # 冻结底层 for layer in model.layers[:6]: layer.eval() for param in layer.parameters(): param.trainable = False # 微调模型 for epoch in range(3): for batch in train_loader: texts = [example['text'] for example in batch] encoded_inputs = tokenizer(texts, return_attention_mask=True, return_length=True, padding=True) input_ids = paddle.to_tensor(encoded_inputs['input_ids']) attention_mask = paddle.to_tensor(encoded_inputs['attention_mask']) logits = model(input_ids, attention_mask=attention_mask)[0] loss = criterion(logits.reshape(-1, logits.shape[-1]), input_ids.reshape(-1)) loss.backward() optimizer.step() optimizer.clear_grad() print(f'Epoch {epoch + 1}: loss={loss.numpy():.4f}') # 保存微调后的模型 paddle.save(model.state_dict(), 'gpt-cpm-large-cn-finetuned
逐层微调
import paddle import paddle.nn.functional as F from paddlenlp.transformers import GPTForPretraining, GPTChineseTokenizer # 加载预训练模型和分词器 model = GPTForPretraining.from_pretrained('gpt-cpm-large-cn') tokenizer = GPTChineseTokenizer.from_pretrained('gpt-cpm-large-cn') # 构造数据集和数据加载器 train_ds = [['今天天气不错'], ['明天要下雨'], ['这个季节很适合旅游']] train_ds = [{'text': text} for text in train_ds] def batch_iter(data, batch_size): num_batches = len(data) // batch_size if len(data) % batch_size != 0: num_batches += 1 for i in range(num_batches): batch = data[i * batch_size: (i + 1) * batch_size] yield batch batch_size = 2 train_loader = paddle.io.DataLoader(train_ds, batch_size=batch_size, shuffle=True, drop_last=True) # 构造优化器和损失函数 optimizer = paddle.optimizer.AdamW(parameters=model.parameters(), learning_rate=1e-4) criterion = F.cross_entropy # 迁移学习微调模型 for epoch in range(3): for batch in train_loader: texts = [example['text'] for example in batch] encoded_inputs = tokenizer(texts, return_attention_mask=True, return_length=True, padding=True) input_ids = paddle.to_tensor(encoded_inputs['input_ids']) attention_mask = paddle.to_tensor(encoded_inputs['attention_mask']) logits = model(input_ids, attention_mask=attention_mask)[0] loss = criterion(logits.reshape(-1, logits.shape[-1]), input_ids.reshape(-1)) loss.backward() optimizer.step() optimizer.clear_grad() print(f'Epoch {epoch + 1}: loss={loss.numpy():.4f}') # 保存微调后的模型 paddle.save(model.state_dict(), 'gpt-cpm-large-cn-finetuned-transfer-learning.pdparams')
参考链接:
https://blog.csdn.net/weixin_42010722/article/details/129378983 https://handbook.pytorch.wiki/chapter4/4.1-fine-tuning.html
随着计算算力的不断增加,以transformer为主要架构的预训练模型进入了百花齐放的时代。BERT、RoBERTa、GPT-2/3等模型的提出为NLP相关问题的解决提供了极大的便利,但也引发了一些新的问题。
首先这些经过海量数据训练的模型相比于一般的深度模型而言,包含更多的参数,动辄数十亿、数百亿。在针对不同下游任务做微调时,存储和训练这种大模型是十分昂贵且耗时的。更麻烦的是,如果每一个垂直领域都要重新训练微调一个新的”庞然大物“出来,显然在时间和空间上都是不可接受的。
为了解决这个问题,各种lightweight-fine-tune的方法被提了出来,相比于“劳民伤财”的全参数微调,只需要以一个较小的训练和存储代价就可以取得和全模型微调相当的结果。
下面介绍一些主流的lightweight-fine-tune技术。
0x1:Adapters-tune

首先adapter方法的原理并不复杂,它是通过在原始的预训练模型中的每个transformer block中加入一些参数可训练的模块实现的。
假设原始的预训练模型的参数为ω,加入的adapter参数为υ,在针对不同下游任务进行调整时,只需要将预训练参数固定住,只针对adapter参数υ进行训练。通常情况下,参数量υ<<ω, 因此在对多个下游任务调整时,只需要调整极小数量的参数,大大的提高了预训练模型的扩展性和实用性。
对于adapter模块的网络组成,不同文章中针对不同任务略有不同。但是比较一致的结论是,bottleneck形式的两层全连接神经网络就已经可以满足要求。
在Houlsby的文章中,每个transformer层中有两个adapter模块,在每个adapter模块中,先将经过多头注意力和前馈层输出的output做一个降维的映射。经过一个非线性激活层后,再将特征矢量映射回原始的维度。在下游训练任务中,只更新adapter模块和layer Norm层(下图中的绿色部分)。
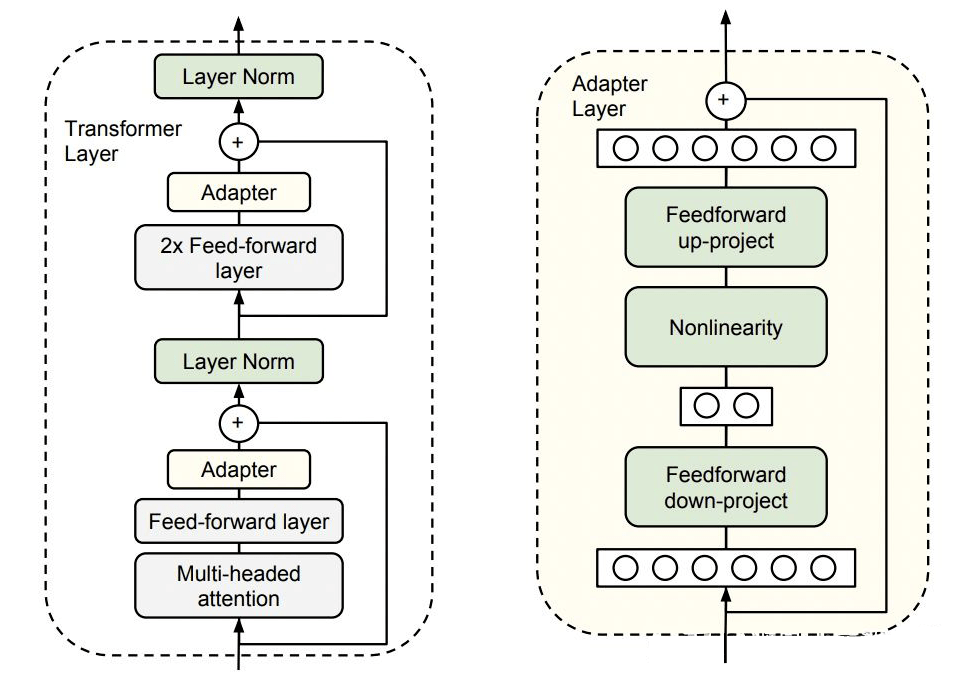
相比于预训练模型的全参数微调,Adapter方法的优势十分明显:
- 针对不同下游任务可保持预训练模型不变,仅需训练adapter模块的少量参数,训练代价小,可移植性强。
- 对于不同任务的连续学习(continual learning)而言,由于在训练不同任务时只需要训练不同的adapter,其他模型参数保持不变,避免了在学习新任务时对过往任务的遗忘。
huggingface开源了transformer库,在原来框架的基础上增添了adapter模块的训练和扩展,
用户只需要在原来的训练脚本中更改不超过两行的代码,就可以针对不同的下游任务无缝训练新的adapter模块,并且整个adapter模块的参数和原始的预训练模型参数是完全独立存储的。详情可以参阅这个链接。
0x1:Prompt-Tuning是什么?解决了传统Fine-tune的哪些问题?
自从GPT、EMLO、BERT的相继提出,以Pre-training + Fine-tuning 的模式在诸多自然语言处理(NLP)任务中被广泛使用,其先在Pre-training阶段通过一个模型在大规模无监督语料上预先训练一个预训练语言模型(Pre-trained Language Model,PLM),然后在Fine-tuning阶段基于训练好的语言模型在具体的下游任务上再次进行微调(Fine-tuning),以获得适应下游任务的模型。这种模式在诸多任务的表现上超越了传统的监督学习方法,不论在工业生产、科研创新还是竞赛中均作为新的主流方式。然而,这套模式也存在着一些问题。例如,
- 在大多数的下游任务微调时,下游任务的目标与预训练的目标差距过大导致提升效果不明显
- 微调过程中依赖大量的监督语料等
至此,以GPT-3、PET为首提出一种基于预训练语言模型的新的微调范式,Prompt-Tuning,其旨在通过添加模板的方法来避免引入额外的参数,从而让语言模型可以在小样本(Few-shot)或零样本(Zero-shot)场景下达到理想的效果。
Prompt-Tuning又可以称为Prompt、Prompting、Prompt-based Fine-tuning等。
因此简单的来说,Prompt-Tuning的动机旨在解决目前传统Fine-tuning的两个痛点问题:
- 降低语义差异(Bridge the gap between Pre-training and Fine-tuning):预训练任务主要以Masked Language Modeling(MLM)为主,而下游任务则重新引入新的训练参数,因此两个阶段的目标通常有较大差异。因此需要解决如何缩小Pre-training和Fine-tuning两个阶段目标差距过大的问题
- 避免过拟合(Overfitting of the head):由于在Fine-tuning阶段需要新引入额外的参数以适配相应的任务需要,因此在样本数量有限的情况容易发生过拟合,降低了模型的泛化能力。因此需要面对预训练语言模型的过拟合问题。
现如今常用的语言模型大多数是BERT及其变体,它的主体结构Transformer模型是由谷歌机器翻译团队在17年末提出的,是一种完全利用attention机制构建的端到端模型。之所以选择Transformer,是因为其完全以Attention作为计算推理技术,任意的两个token均可以两两交互,使得推理完全可以由矩阵乘积来替代,实现了可并行化计算,因此Transformer也可以认为是一个全连接图,缓解了序列数据普遍存在的长距离依赖和梯度消失等缺陷。
Prompt的目的是将Fine-tuning的下游任务目标转换为Pre-training的任务。那么具体如何工作呢?
我们依然以二分类的情感分析作为例子,描述Prompt-tuning的工作原理。给定一个句子:
[CLS] I like the Disney films very much. [SEP]
传统的Fine-tuning方法是将其通过BERT的Transformer获得[CLS]表征之后再喂入新增加的MLP分类器进行二分类,预测该句子是积极的(positive)还是消极的(negative),因此需要一定量的训练数据来训练。
而Prompt-Tuning则执行如下步骤:
- 构建模板(Template Construction):通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有[MASK]标记的模板。例如It was [MASK].,并拼接到原始的文本中,获得Prompt-Tuning的输入:[CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP]。将其喂入BERT模型中,并复用预训练好的MLM分类器,即可直接得到[MASK]预测的各个token的概率分布。
- 标签词映射(Label Word Verbalizer):因为[MASK]部分我们只对部分词感兴趣,因此需要建立一个映射关系。例如如果[MASK]预测的词是“great”,则认为是positive类,如果是“terrible”,则认为是negative类。不同的句子应该有不同的template和label word,因为每个句子可能期望预测出来的label word都不同,因此如何最大化的寻找当前任务更加合适的template和label word是Prompt-tuning非常重要的挑战。
- 训练:根据Verbalizer,则可以获得指定label word的预测概率分布,并采用交叉信息熵进行训练。此时因为只对预训练好的MLM head进行微调,所以避免了过拟合问题。
引入的模板和标签词本质上也属于一种数据增强,通过添加提示的方式引入先验知识。笔者认为,prompt-tuning相比于传统的fine-tune范式,最大的创新点就在于引入了”context template“的概念,通过预定义的模板,大幅度限定了模型微调的优化方向,减少了搜索空间,使得fine-tune出来的模型在具体的任务领域有更好的泛化性能,甚至具备zero-shot的能力。
0x2:Prompt-Tuning的鼻祖——GPT-3与PET
Prompt-Tuning起源于GPT-3的提出《Language Models are Few-Shot Learners》(NIPS2020),其认为超大规模的模型只要配合好合适的模板就可以极大化地发挥其推理和理解能力。其开创性提出in-context learning概念,即无须修改模型即可实现few-shot/zero-shot learning。同时引入了demonstrate learning,即让模型知道与标签相似的语义描述,提升推理能力。
- In-context Learning:是Prompt的前身。其通过从训练集中挑选一些样本作为任务的提示提示(Natural Language Prompt),来实现免参数更新的模型预测
- Demonstration Learning:添加一些新的文本作为提示。例如在对“I like the Disney film. It was [MASK]”进行情感分析时,可以拼接一些相似场景的ground-truth文本“I like the book, it was great.”、“The music is boring. It is terrible for me.”等。此时模型在根据新添加的两个样例句子就可以“照葫芦画瓢”式地预测结果了。
0x3:Prompt-Tuning的本质
最初的Prompt Tuning是旨在设计Template和Verbalizer(即Pattern-Verbalizer Pair)来解决基于预训练模型的小样本文本分类,然而事实上,NLP领域涉及到很多除了分类以外其他大量复杂的任务,例如抽取、问答、生成、翻译等。这些任务都有独特的任务特性,并不是简单的PVP就可以解决的,因而,我们需要提炼出Prompt Tuning的本质,将Prompt Tuning升华到一种更加通用的范式上。总结了三个关于Prompt的本质,如下:
- Prompt的本质是一种对任务的指令,可以作为一种信息增强。
- Prompt的本质是一种对预训练任务的复用,实现基于Prompt的统一范式
- Prompt的本质是一种参数有效性学习
1、Prompt的本质是一种对任务的指令,可以作为一种信息增强
简单的来说,就是告诉模型需要做什么任务,输出什么内容。
当数据集不同(乃至样本不同)的时候,我们期望模型能够自适应的选择不同的模板,这也相当于说不同的任务会有其对应的提示信息。例如在对电影评论进行二分类的时候,最简单的提示模板是“[x]. It was [mask].”,但是其并没有突出该任务的具体特性,我们可以为其设计一个能够突出该任务特性的模板,例如“The movie review is [x]. It was [mask].”,然后根据mask位置的输出结果通过Verbalizer映射到具体的标签上。这一类具备任务特性的模板可以称之为指令(Instruction)。
下面展示几个任务设计的指令模板:

看似设计指令是一件容易的事情,但是在真实使用过程中,预训练模型很难“理解”这些指令,根据研究工作发现,主要总结如下几个原因:
- 预训练模型不够大:我们常使用的BERT-base、BERT-large、RoBERTa-base和RoBERTa-large只有不到10亿参数,相比于现如今GPT-3、OPT等只能算作小模型,有工作发现,小模型在进行Prompt Tuning的时候会比Fine-tuning效果差,是因为小模型很容易受到模板的影响。对比一下传统的Fine-tuning,每个样本的输入几乎都是不同的,然而基于Prompt的方法中,所有的样本输入都会包含相同的指令,这就导致小模型很容易受到这些指令带来的干扰。
- 缺乏指令相关的训练:这些小模型在预训练阶段没有专门学习过如何理解一些特殊的指令。
2、Prompt的本质是一种对预训练任务的复用,实现基于Prompt的统一范式
我们需要思考,上述所讲的内容为什么要设计Template(和Verbalizer)?为什么都要包含mask token?
回顾之前我们介绍的几个预训练语言模型,我们发现目前绝大多数的双向预训练语言模型都包含Masked Language Modeling(MLM),单向预训练语言模型都包含Autoregressive Language Modeling(ALM),这些任务是预训练目标,本质上是预测被mask的位置的词,在训练时让模型理解语言的上下文信息。之所以设计Template和指令,就是希望在下游任务时能够复用这些预训练的目标,避免引入新的参数而导致过拟合。
因此,我们可以将Prompt升华到一个新的高度,即Prompt Tuning的本质是复用预训练语言模型在预训练阶段所使用的目标和参数。
由于绝大多数的语言模型都采用MLM或ALM进行训练,所以我们现如今所看到的大多数基于Prompt的分类都要设计Template和Verbalizer。那么我们是否可以极大化地利用MLM和ALM的先验知识在不同的下游任务上获得更好的表现?是否可以设计一个全新的预训练任务来满足一些下游任务的需求呢?
我们介绍几个充分利用这个思想的方法:
- 万物皆可生成:将所有任务统一为文本生成,极大化利用单向语言模型目标
- 万物皆可抽取:将所有任务统一为抽取式阅读理解,并设计抽取式预训练目标
- 万物皆可推理:将所有任务建模为自然语言推断(Natural Language Inference)或相似度匹配任务
万物皆可生成——基于生成的Prompt范式统一
在含有单向Transformer的语言模型中(例如GPT、BART),都包含自回归训练目标,即基于上一个token来预测当前的token,而双向语言模型中的MLM可以视为只生成一个token的自回归模型,为此,我们则可以将分类任务视为一种特殊的文本生成,并配上Verbalizer,这样,所有的NLP任务都可以统一为生成任务。针对不同的任务,只需要提供对应的指令和模板即可(由于是使用单向语言模型,因此没有mask token,需要生成的部分置于文本末尾)。
下面给出几个事例:

万物皆可抽取——基于抽取式阅读理解的Prompt范式统一
基于生成的方法存在两个缺点:
- 必须让待生成的部分置于文本末尾,此时会约束指令和模板的设计,不利于灵活运用
- 由于是开放式生成,生成的内容无法控制,且依赖于文本的长度等
- 对于一些具有条件限制的任务,例如多项选择、信息抽取等,生成的内容或许不符合这些条件。例如在做实体抽取的时候,需要确保生成的实体是在文本中出现的
为此,“万物皆可抽取”的思想可以解决此类问题,其思想指将所有自然语言理解任务转换为抽取式阅读理解的形式,下面给出形式化的定义:

除了抽取式阅读理解任务外,其他NLP任务如何转换为这个形式呢?本质上还是在如何设计模板和指令。
下面给出几个事例:

可以发现,如果是分类型的任务,只需要通过指令和模板的形式将所有类别罗列起来即可。在训练时,可以采用两种方法:
- 设计抽取式预训练目标,在无标注语料上进行自监督训练
- 按照阅读理解的形式统一所有任务范式,并混合所有任务进行Cross-task Learning,再在新的任务上进行测试
万物皆可推理——基于NLI的Prompt范式统一
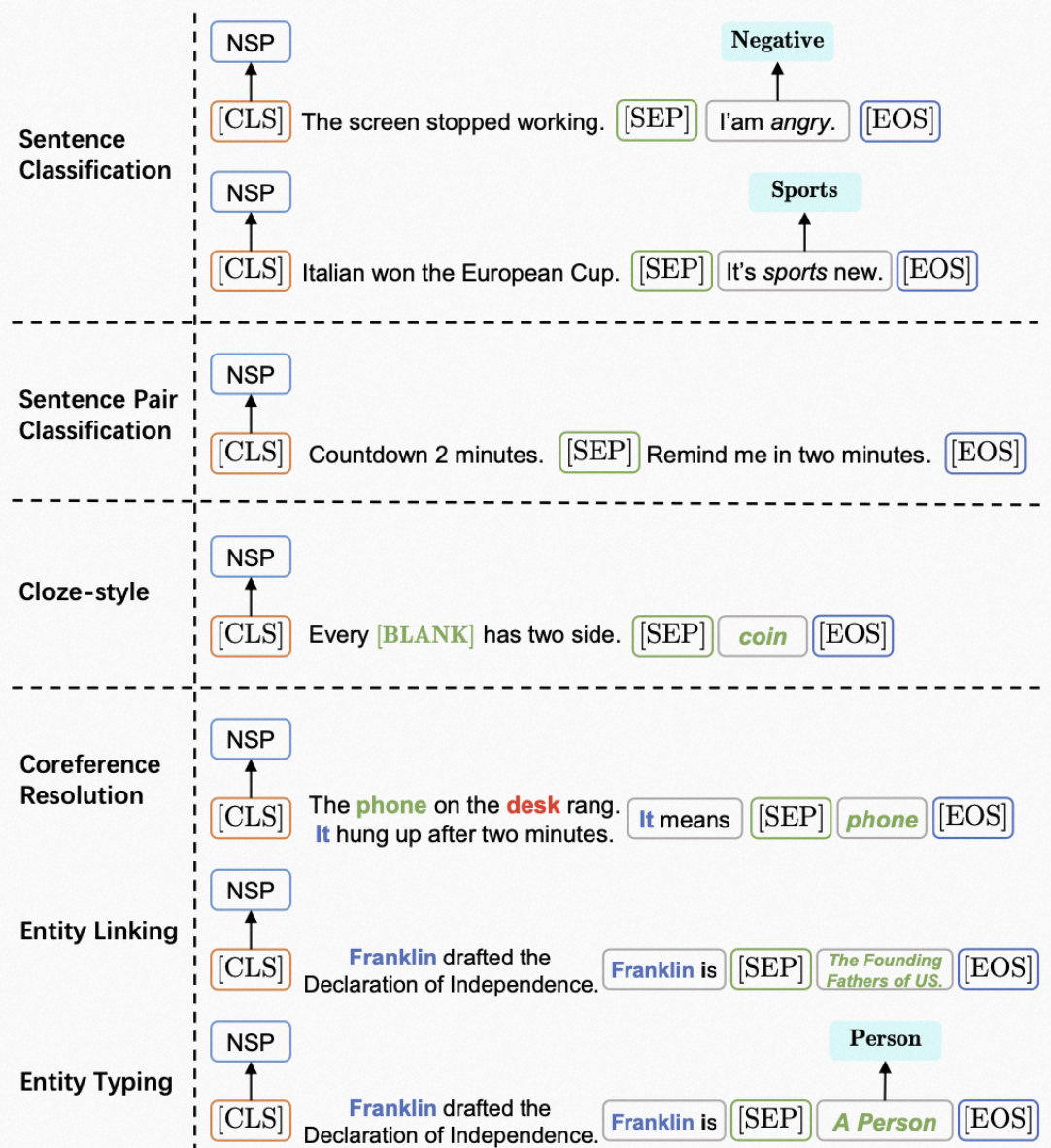
另外一个方法则是将所有任务建模为NLI形式,其与上文介绍的MPT比较类似,除了MPT以外,《Entailment as Few-Shot Learner》(EFL)和NSP-BERT也是类似的方法,其思想是复用BERT中的Next Sentence Prediction(NSP)的预训练目标。下面给出几个事例:
3、Prompt的本质是参数有效性学习
实现Prompt-Tuning只需要考虑如何设计模板或指令,而模型和训练目标则都是复用预训练阶段的,即在整个训练过程中,无须添加任何参数(或只需要添加非常少量的与模板有关的参数),而其他参数都是训练好的。基于这个思想,我们再一次将Prompt升华到更高的层面——Prompt的本质是参数有效性学习(Parameter-Efficient Learning,PEL)。
- 参数有效性学习的背景:在一般的计算资源条件下,大规模的模型(例如GPT-3)很难再进行微调,因为所有的参数都需要计算梯度并进行更新,消耗时间和空间资源。为了解决这个问题,参数有效性学习被提出,其旨在确保模型效果不受太大影响的条件下尽可能地提高训练的时间和空间效率。
- 参数有效性训练:在参数有效性学习过程中,大模型中只需要指定或额外添加少量的可训练参数,而其余的参数全部冻结,这样可以大大提高模型的训练效率的同时,确保指标不会受到太大影响。
0x4:面向超大规模模型的Prompt-Tuning
Prompt-Tuning发展的过程中,有诸多工作发现,对于超过10亿参数量的模型来说,Prompt-Tuning所带来的增益远远高于标准的Fine-tuning,小样本甚至是零样本的性能也能够极大地被激发出来。
- 得益于这些模型的参数量足够大
- 训练过程中使用了足够多的语料
- 同时设计的预训练任务足够有效
最为经典的大规模语言模型则是2020年提出的GPT-3,其拥有大约1750亿的参数,且发现只需要设计合适的模板或指令即可以实现免参数训练的零样本学习。
下面介绍几个面向超大规模的Prompt-Tuning方法,分别为:
- 上下文学习 In-Context Learning(ICL):直接挑选少量的训练样本作为该任务的提示
- 指令学习 Instruction-tuning:构建任务指令集,促使模型根据任务指令做出反馈
- 思维链 Chain-of-Thought(CoT):给予或激发模型具有推理和解释的信息,通过线性链式的模式指导模型生成合理的结果。
1、In-Context Learning(上下文学习)

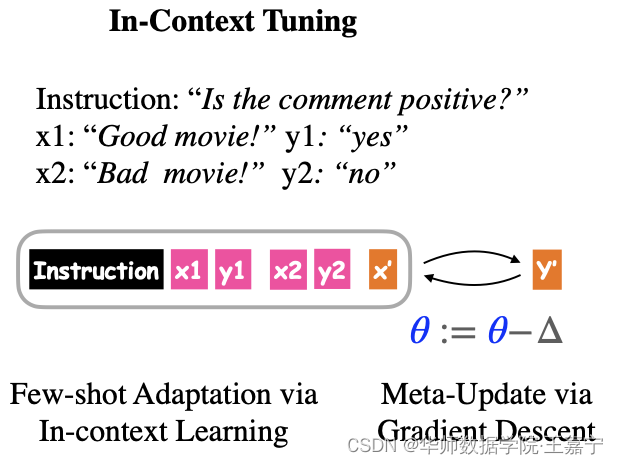
目前,向语言模型通过prompting可以在小样本场景下得到很大的成功,例如GPT-3。然而原始的语言模型在预训练时并没有针对in-context进行优化。先前工作发现prompting会过度受到(oversensitive)样本选取以及instruction本身影响。因此该工作提出In-Context Tuning,旨在通过多任务训练的方式直接对预训练模型微调ICL任务目标。
在训练(fine-tuning)阶段,给定一系列的训练task,每一个task都有相应的instruction,以及该task对应的少量样本(输入/输出对)。在测试阶段,给定一个新的unseen task,以及该task对应的instruction和少量样本(输入/输出对),旨在让模型能够对测试样本预测其类别。
如下图,给定一个情感分析task:
除了将ICL的模板与自监督训练结合外,是否可以直接使用ICL来训练一个具体的任务呢?答案是可以的,下面两篇工作将ICL的模板与下游任务相结合,并提出基于元学习的ICL训练方法:
- 《Meta-learning via Language Model In-context Tuning》:提出In-Context Tuning方法;
- 《MetaICL: Learning to Learn In Context》:提出MetaICL方法。
2、Instruction-tuning(指令学习)
面向超大规模模型第二个Prompt技术是指令学习。Prompt的本质之一是任务的一种指令,因此,在对大规模模型进行微调时,可以为各种类型的任务定义指令,并进行训练,来提高模型对不同任务的泛化能力。
什么是指令呢?如下图所示:

假设是一个Question Generation任务,那么可以为这个任务定义一些指令,例如:
- Title:任务的名称;
- Definition:任务的定义,说明这个任务的本质和目的;
- Things to avoid:说明这个任务的注意事项,例如需要避免什么等等;
- Positive / Negative Examples:给出正确和错误的例子,作为提示;
- Prompt:当前任务的提示信息;
当许多任务都按照这种模式定义好模板,让模型在指令化后的数据上进行微调,模型将可以学会如何看到指令做预测。
下面介绍一些典型的基于Instruction的方法,包括FLAN、LaMDA和InstructionGPT,它们都是遵循Instruction-tuning实现统一范式。
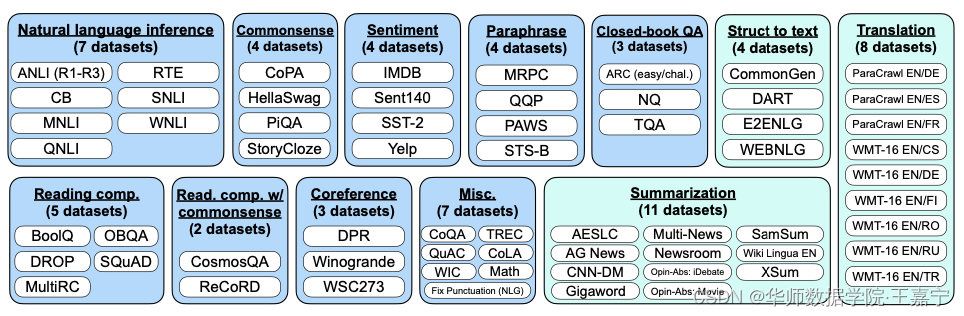
FLAN
例如基于Instruction-Tuning训练的FLAN模型,其在62个任务上进行多任务训练,每个任务都设计了Instruction,最后得到137B的大模型,如下图所示:

LaMDA
谷歌提出的LaMDA模型,其完全采用自回归生成式模型,并在大量的对话语料上进行预训练,得到137B的大模型。为了提高模型的安全性和事实性,LaMDA涉及到两个微调策略,
- 一个是通过人工标注形式标注一些存在安全隐患的数据。期望模型生成过程中考虑四种因素:
- sensibleness:文本是否合理,跟历史对话是否有冲突
- specificity:对于前文是否有针对性,避免笼统回复
- interestingness:文本是否能引起某人注意或者好奇
- safety:符合谷歌AI的基本原则,避免生成具有伤害、偏见和歧视的结果
- 另一种微调策略则是引入互联网搜索机制,提高模型生成结果的事实性
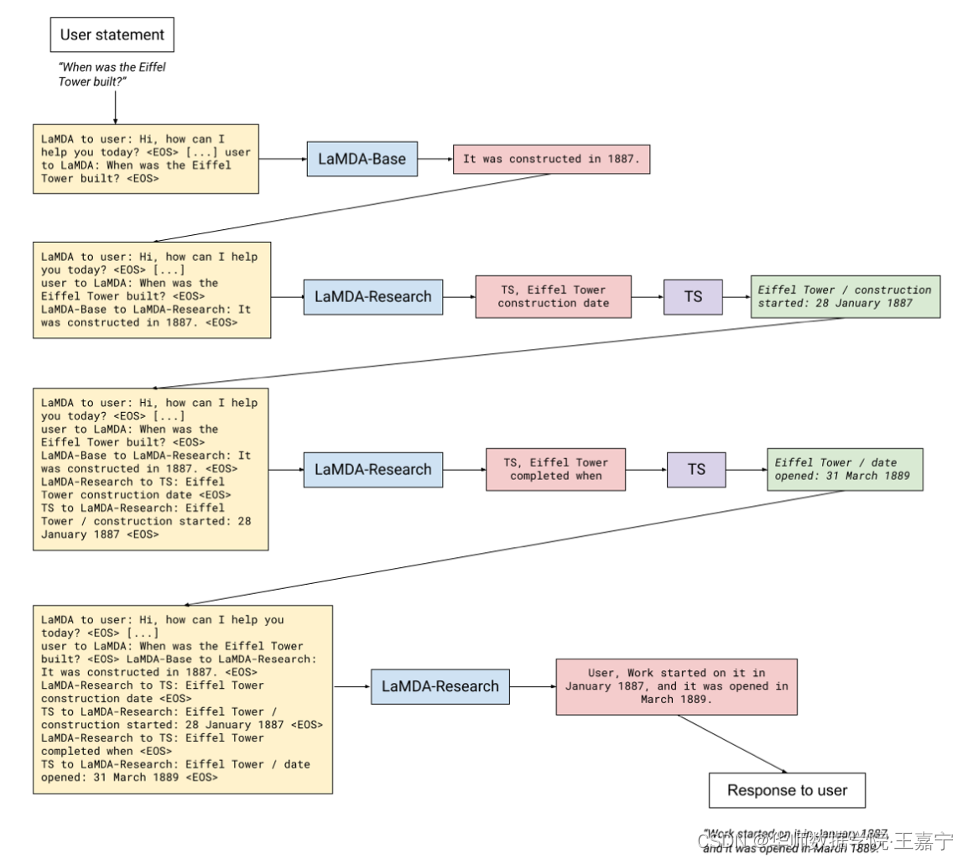
与ChatGPT类似的Bard大模型则是基于LaMDA微调的模型。
InstructionGPT
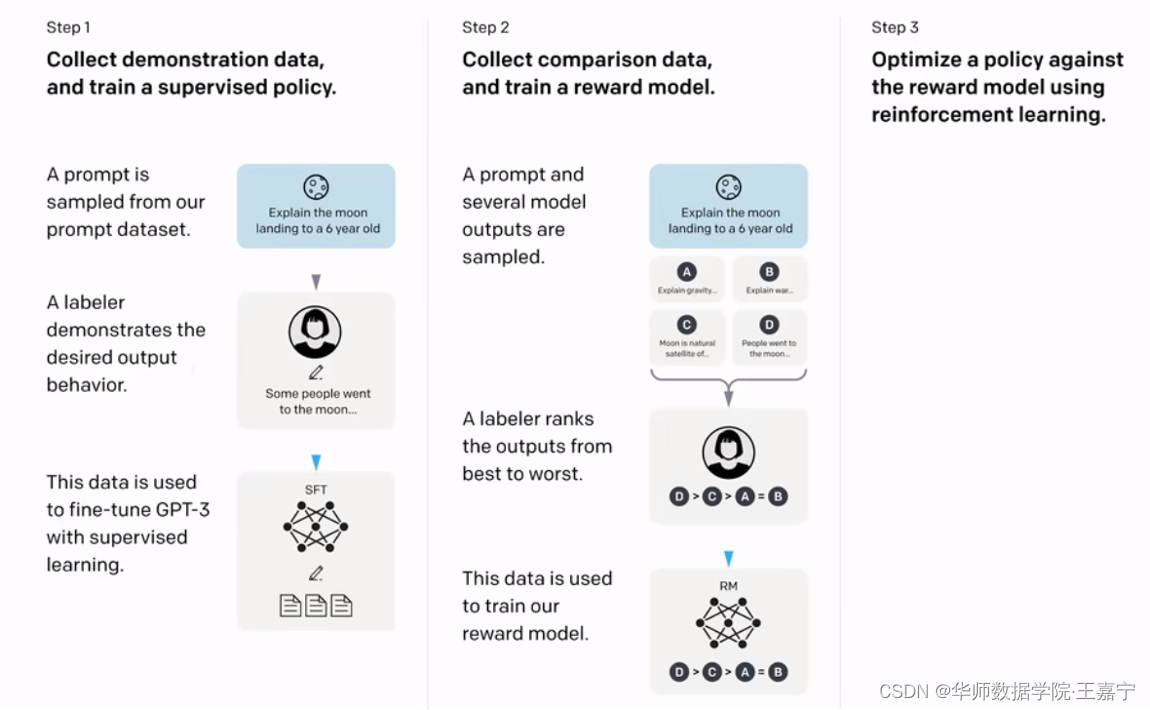
- Step1:先采样一些demonstration数据,其包括prompt和labeled answer。基于这些标注的数据,对GPT-3进行fine-tuning,得到SFT(Supervised Fine-tuning)。
- Step2:Fine-tuning完之后,再给一个prompt让SFT模型生成出若干结果(可以通过beam search等方法),例如生成ABCD四种结果,通过人工为其排序,例如D>C>A=B,可以得到标注的排序pair;基于标注的排序结果,训练一个Reward Model,对多个排序结果,两两组合,形成多个训练数据对。RM模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
- Step3:继续用生成出来的结果训练SFT,并通过强化学习的PPO方法,最大化SFT生成出排序靠前的answer。
3、Chain-of-Thought(思维链)
思维链在2022年初由谷歌团队提出,其旨在进一步提高超大规模模型在一些复杂任务上的推理能力。其认为现有的超大规模语言模型可能存在下面潜在的问题:
- 增大模型参数规模对于一些具有挑战的任务(例如算术、常识推理和符号推理)的效果并未证明有效
- 期望探索如何对大模型进行推理的简单方法:
- 对于算术类推理任务,期望生成自然语言逻辑依据来指导并生成最终答案;但是获得逻辑依据是比较复杂昂贵的
- 对某个task,为大模型提供一些上下文in-context example作为prompt;简单的示例可能并非能够提升推理能力
因此,提出思维链(Chain-of-Thought)。思维链的定义如下:
A chain of thought is a series of intermediate natural language reasoning steps that lead to the final output, and we refer to this approach as chain-of-thought prompting.
直观理解很简单,思维链是一种特殊的In-Context Learning,对于每个挑选的In-Context Example,除了给出Input-Output Mapping外,还需要给出一个推理过程,称为Relationale或Reasoning Path,其是一个具有逻辑推理过程的短文本,如下图蓝色部分。
通过引入推理路径作为提示,可以激发大模型按照这种推理的模式生成出合理的结果,引导大模型如何思考、如何推理。
0x5:使用Prompt Tuning解决问题的流程
在NLP领域,“Prompt”是将人为的规则给到预训练模型,使模型可以更好地理解人的指令的一项技术,可以简单理解为给任务的输入加入补充文本,以便更好地利用预训练模型。
例如,在文本情感分类任务中,输入为"I love this movie.",希望输出的是"positive/negative"中的一个标签。可以设置一个Prompt,形如:"The movie is ___",然后让模型用来表示情感状态的答案(label),如“fantastic”、“boring”等,将空补全,最后再将答案转化成情感分类的标签(positive/negative)作为输出。
这样,通过设置合适的Prompt,我们可以控制模型预测输出,一个完全无监督训练的预训练模型可以被用来解决各种各样的下游任务。
1、构建Prompt
代入前文所述的例子,x = "I love this movie."。首先,设计一个Prompt模板(Prompt Template):
Overall it was a [z] movie
在实际研究中,[z]是需要模型进行填充的空位,[z]的位置和数量决定了Prompt的类型。
例如,根据[z]位置的不同,可以将prompt分为
- cloze prompt([z]在句中)
- prefix prompt([z]在句末)
具体选择哪一种则取决于任务形式和模型类别。
至于Prompt模板的选择,大致可以分为
- 手工设计模板
- 自动学习模板:自动学习类别下又包含
- 离散Prompt:离散Prompt主要包括:Prompt Mining、Prompt Paraphrasing、Gradient-based Search、Prompt Generation、LM Scoring
- 连续Prompt:连续Prompt包括Prefix Tuning和Hybrid Tuning
2、构建Answer
所谓的Answer,指的是表示情感的答案。在上述案例中,可以是“fantastic”、“boring”等。
构建答案空间(Answer Space)能够重新定义任务的目标,使任务从输出“positive”或“negative”标签转变成选择恰当的词汇填空,使情感分类任务转变为语言模型构建任务。此时的关键在于如何定义标签空间(Label Space)与答案空间(Answer Space)之间的映射。
构建答案空间同样需要选择合适的形式和方法。在Prompt Learning中,答案有Token、Span、Sent三种形式;从答案空间是否有边界的角度,又可分为bounded和unbounded两种;在选择方法上,同样可以分为人工选择和自动学习两种方式。
3、预测Answer
要进行预测,首先需要预先选择预训练语言模型。在实际应用中,可以根据现有的预训练模型的不同特点进行适配,不同类型的预训练模型适配不同的prompt,比如Left-to-right LM适合搭配prefix-prompt等。
当模型选择好之后,为了使当前的Prompt框架(framework)能够支撑更多的下游任务,可以考虑进行范式的拓展,例如,将之前的Single-Prompt设计拓展成Multi-Prompt,使模型能够更加灵活地解决更多的下游任务。
4、匹配答案与标签
最后,为了得到最终的输出(output),还需要根据之前定义好的映射,将预测到的Answer与实际任务中的Label匹配。
根据应用场景的不同,还需要从数据和参数的角度对整体策略进行调整。
- 从数据角度,需要考虑到应用场景是zero-shot、few-shot还是Full-data
- 从参数角度,则需要考虑不同的Tuning策略,包括对模型参数的处理,对Prompt参数的处理等等,来匹配相应的场景
0x6:Prompt Tuning的优势
1、Prompt Tuning本身的优势
- 首先,Prompt Tuning使得几乎所有NLP任务都可以被看作语言模型任务而不是生成任务。这可以更好地利用预训练模型,使不同的任务之间都有所联系,实现更深层次的参数共享
- 其次,几乎所有NLP任务都能够放在zero-shot情境下处理,不再需要训练样本
- 同时,目前不少研究表明Prompt在few-shot情景下的性能也更好
2、Prompting vs. Fine-Tuning
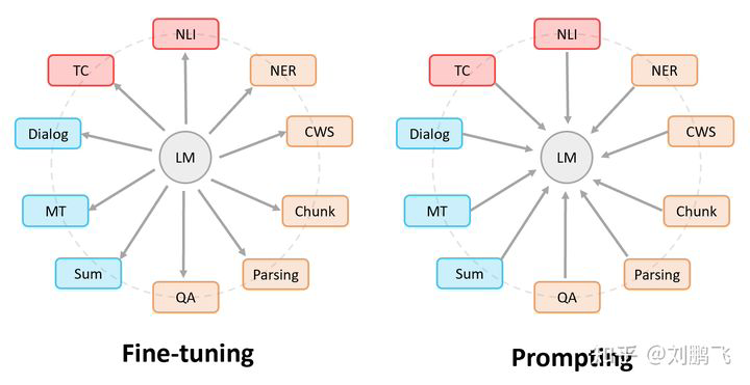
实际上,Prompting可以细分出许多不同的Tuning策略,比如根据应用场景的不同,决定是否需要Prompting、Prompting是否存在参数、参数是否可调等等。
与一般的Fine-Tuning相比,Prompt Tuning将Prompt加入到微调过程中,并且可以做到只对Prompt部分的参数进行训练,同时保证整个预训练模型的参数固定不变,这种灵活性是一般的Fine-tuning无法做到的。所以后来不少学者开始进行“Adaptor Tuning”的研究,这也是对传统Fine-tuning的一个补充。
正如前文所说,Fine-tuning是预训练模型“迁就”下游任务,而Prompt Learning可以让任务改变,反而“迁就”预训练模型。模型因此能够完成更多不同类型的下游任务,极大地提升了预训练的效率。
3、Prompting技术的里程碑意义
引用刘鹏飞博士的观点,Prompt Tuning“剧透”了NLP发展的规律。
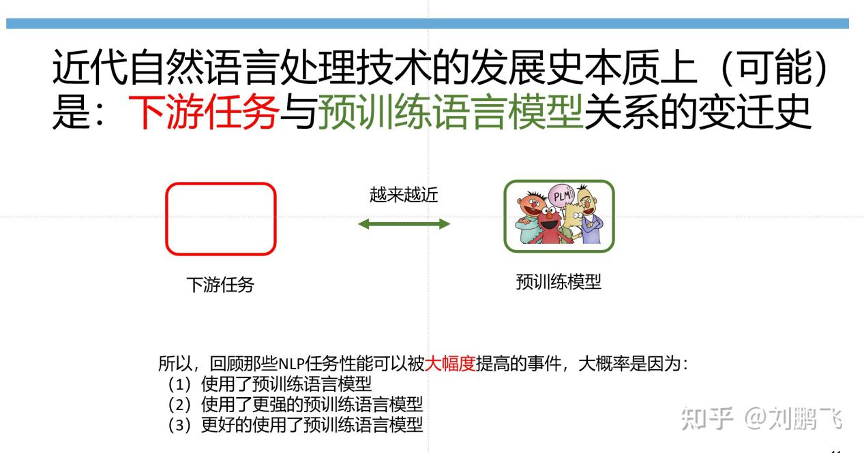
纵观近代NLP技术发展历史,不难总结出四个范式:
特征挖掘 -> 架构挖掘 -> 目标挖掘 -> Prompt挖掘
在这个过程中,下游任务与预训练模型之间是越来越接近的。
- 在传统的监督学习中,没有预训练语言模型的概念
- 随着神经网络技术的发展,出现了预训练模型,能够承担的任务也越来越多,越来越深入
- 直到Prompt技术的出现,预训练模型可以承担起更多深层次的任务,甚至包括输出层任务。
0x7:Prompt Tuning发展面临的挑战与未来展望
1、Prompt的设计问题
目前,由于Prompt设计上的复杂性,现有的大多数基于Prompt的工作都还围绕着文本分类或生成任务,而在信息提取和文本结构化分析任务中的应用相对较少。
而设计Answer时,对于Label较多的任务,很难合理地定义二者之间的映射。
并且,如何同时构建一对最佳的Prompt和Answer也是一个具有挑战性的问题。
2、Prompt的理论和实证分析
尽管Prompt方法在很多场景中取得了成功,但是目前关于Prompt-based Learning的理论分析和保证的研究成果很少,Prompt取得成果的可解释性较差。
而在选择Tuning的策略上,对于选择Prompt以及调整Prompt与预训练模型参数的方法缺少可解释的权衡方式。
3、NLP研究之外贡献
Prompt Learning以自然语言为桥接,理论上可以将不同模态的信号进行连接。同时,Prompt Learning启发了人们对数据的标注、存储、检索的新思路。
参考链接:
https://zhuanlan.zhihu.com/p/451440421 https://github.com/Adapter-Hub/adapter-transformers https://blog.csdn.net/qq_36426650/article/details/120607050 https://www.aminer.cn/research_report/617a27745c28d1a4d4362fd4 https://arxiv.org/pdf/2212.10560.pdf https://zhuanlan.zhihu.com/p/590311003 https://www.qin.news/instructgpt/
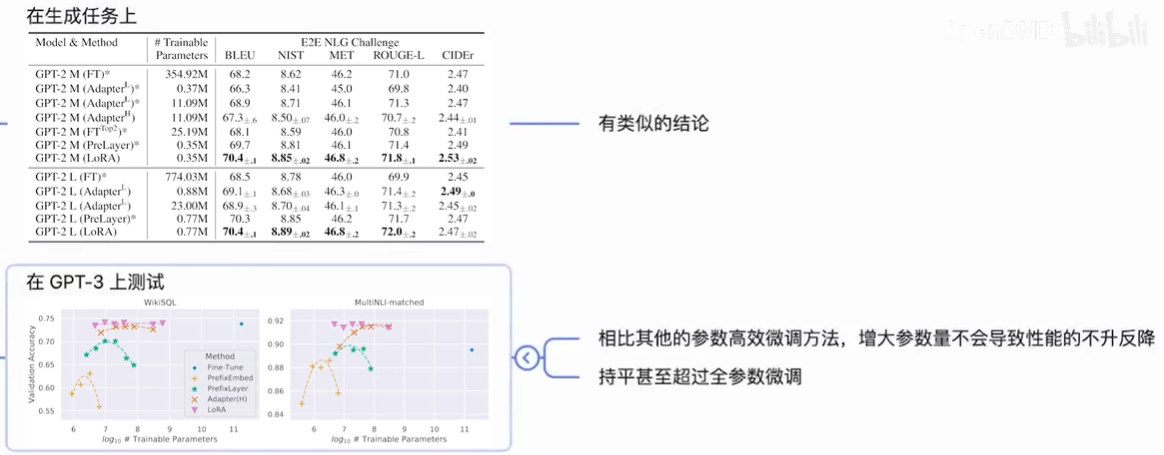
微调大规模语言模型到特殊领域和任务是自然语言处理的重要课题之一。但随着模型规模的不断扩大,微调模型的所有参数(所谓full fine-tuning)的可行性变得越来越低。以GPT-3的175B参数为例,每增加一个新领域就需要完整微调一个新模型,代价和成本很高。
0x1:已有方案的问题
为解决微调大规模语言模型到不同领域和任务的挑战,已有多种方案,比如部分微调、使用adapters和prompting。但这些方法存在如下问题:
- Adapters引入额外的推理延迟 (由于增加了模型层数)
- Prefix-Tuning难于训练,且预留给prompt的序列挤占了下游任务的输入序列空间,影响模型性能
1、Adapter引入推理延迟
显然,使用Adapter增加模型层数会增加推理的时长:

从上图可以看出,对于线上batch size为1,输入比较短的情况,推理延迟的变化比例会更明显。
简单来说,adapter就是固定原有的参数,并添加一些额外参数用于微调。Adapter会在原始的transformer block中添加2个adapter,一个在多头注意力后面,另一个这是FFN后面。显然,adapter会在模型中添加额外的层,这些层会导致大模型在推理时需要更多的GPU通信,而且也会约束模型并行。这些问题都将导致模型推理变慢。
2、很难直接优化Prompt
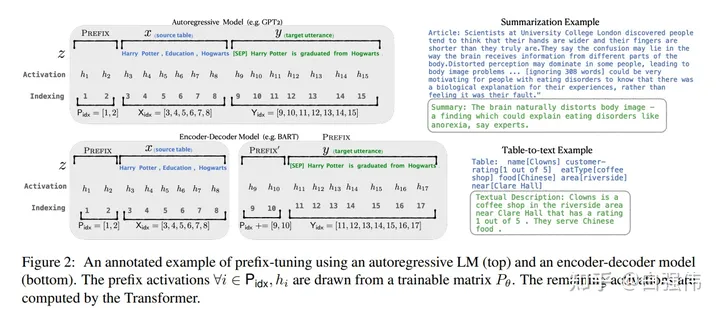
prefix-tuning方法是受语言模型in-context learning能力的启发,只要有合适的上下文则语言模型可以很好的解决自然语言任务。但是,针对特定的任务找到离散token的前缀需要花费很长时间,prefix-tuning提出使用连续的virtual token embedding来替换离散token。
具体来说,对于transformer中的每一层,都在句子表征前面插入可训练的virtual token embedding。对于自回归模型(GPT系列),在句子前添加连续前缀,即![]() 。对于Encoder-Decoder模型(T5),则在Ecoder和Decoder前都添加连续前缀
。对于Encoder-Decoder模型(T5),则在Ecoder和Decoder前都添加连续前缀![]() 。添加前缀的过程如上图所示。
。添加前缀的过程如上图所示。
虽然,prefix-tuning并没有添加太多的额外参数。但是,prefix-tuning难以优化,且会减少下游任务的序列长度,一定程度上会影响模型性能。
0x2:LoRA的原理简介
lora本质是对大模型微调的方法,

NLP领域的一个重要课题是,一般领域数据的通用大模型对特定任务或领域的适应。当预训练大模型很大时,重新训练所有模型参数的微调变得不可太行,例如GPT3的175B。提出的lora采用低秩分解矩阵,冻结了预训练模型的权重,并将低秩分解矩阵注入到transformer的每一层,减少了训练参数量。
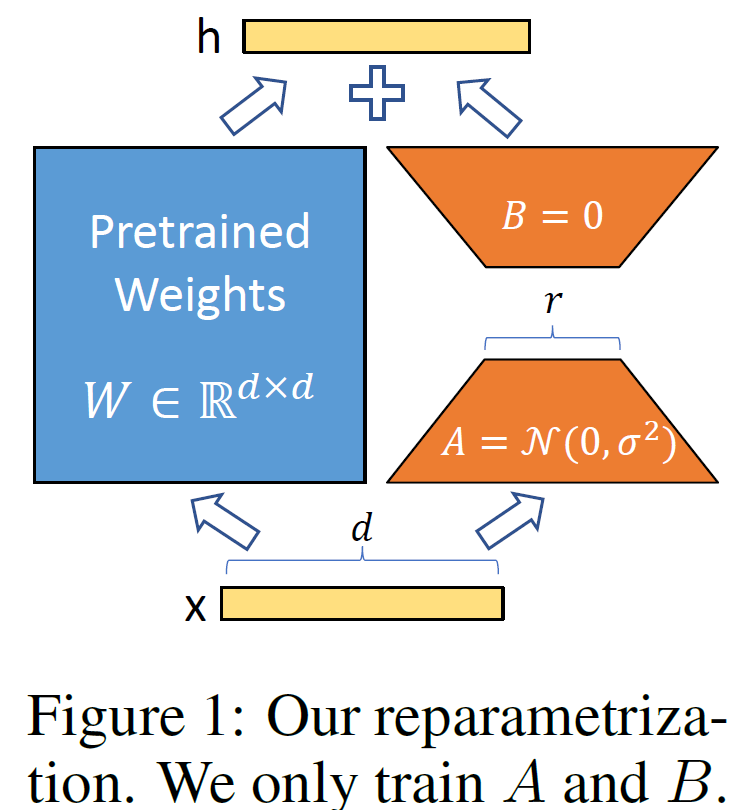
如上图所示们对于某个线性层而言,左边是模型原有的参数,在训练过程中是冻结不变的,右边是lora方法增加的低秩分解矩阵。
在原始PLM旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。
训练过程中,优化器只优化右边这一部分的参数,两边的矩阵会共用一个模型的输入,分别进行计算,最后将两边的计算结果相加作为模块的输出。不同于之前的参数高效微调的adapter,
- adapter是在模块的后面接上一个mlp,对模块的计算结果进行一个后处理
- lora是和模块的计算并行的去做一个mlp,和原来的模块共用一个输入

具体来看,假设预训练的矩阵为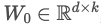 ,它的更新可表示为:
,它的更新可表示为:
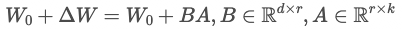
其中秩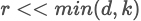 。
。
这种思想有点类似于残差连接,同时使用这个旁路的更新来模拟full finetuning的过程。并且,full finetuning可以被看做是LoRA的特例(当r等于k时)。
根据之前的一些工作,发现大模型其实是过参数化的, 有更小的一个内在维度,于是文章做了一个假设,大模型在任务适配(instruction-tune)过程中,参数的改变量是低秩的,
- 在训练过程中,lora单独去学习这个改变量,而不是去学习模型的参数,通过把最终训练得到的参数分解为原参数W0和该变量deltaW进行相加,论文假设deltaW是低秩的,把deltaW进一步拆分为低秩矩阵A和低秩矩阵B。
- 在推理的过程中,由于模型参数已经固定不再变动,这时候把模型的改变量直接放到模型里,这样在推理的计算过程中,就避免了一次额外的矩阵乘法开销。推理是改变量是直接加到原路径中的。在切换不同推理任务时,只需要从模型参数里减去当前任务的该变量,再换上新任务的改变量即可。这里隐含了一个推理:大模型中已经内含了一些小模型的参数空间,特定的垂直领域instruction-tune本质上就等价于”切割“出这些小的子空间。



理论上lora可以支持任何线性层,包括transformer中的4个attention矩阵和2个feed forward中的矩阵,论文旨在attention上做了实验,它限制总参数量不变的情况下观察是在attention其中一个矩阵上,放一个更高秩的lora,还是在多个attention的矩阵上,分别放置低秩一点的lora效果好?
结论是把秩分散到多个矩阵上,效果会优于集中在单个上的效果。在一般任务上很小的秩就可以和很大秩具备类似的效果,这也证明了作者一开始做出的改变量低秩的假设。
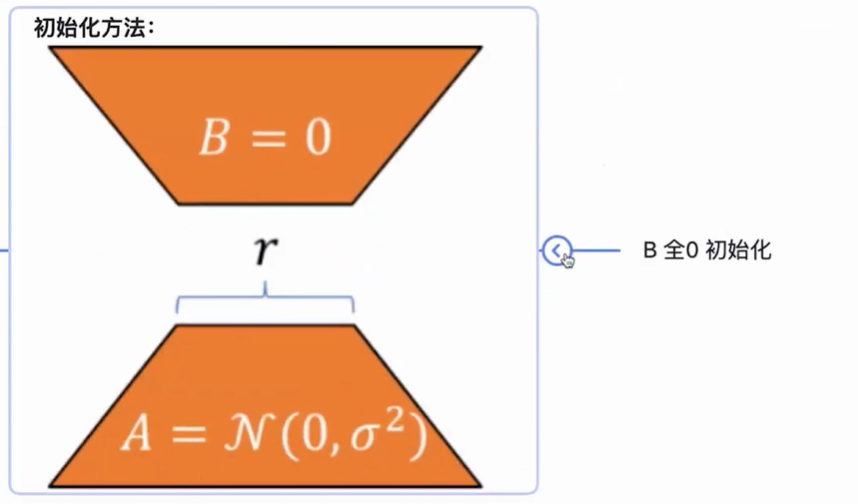
初始化一开始右边为0,也就意味着模型优化的初始点就和原本的大模型能够保持一致,这一点和controlnet中的zero convolution是一致的。
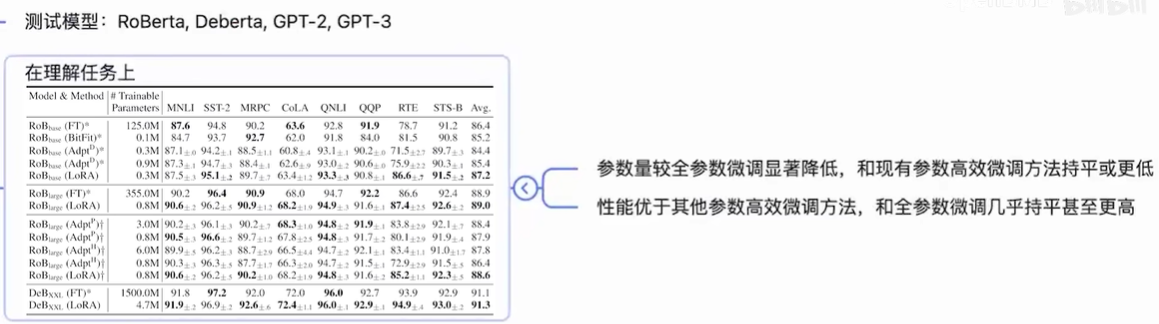

总之,基于大模型的内在低秩特性,增加旁路矩阵来模拟全模型参数微调,LoRA通过简单有效的方案来达成轻量微调的目的。
引申一下,GPT的本质是对训练数据的有效压缩,从而发现数据内部的逻辑与联系,LoRA的思想与之有相通之处,原模型虽大,但起核心作用的参数是低秩的,通过增加旁路,达到事半功倍的效果。
0x3:LoRA原理的数学化表达
1、术语与约定
由于LoRA原理的介绍,会使用Transformer架构。因此,这里先给出一些术语约定。
一个Transformer层的输入和输出维度尺寸为dmodel ,使用Wq、Wk、Wv和W表示自注意力模块中的query/key/value/output投影矩阵。 W或W0表示预训练模型的权重矩阵, ΔW 表示模型在适配过程中的梯度更新。r来表示LoRA模块的秩。使用Adam作为模型优化器,Transformer MLP前馈层的维度为dffn=4×dmodel
2、问题表述
LoRA虽然与训练目标无关,这里还是以语言建模为例。假设给定一个预训练的自回归语言模型 PΦ(y|x) , Φ是模型参数。目标是使该语言模型适应下游的摘要、机器阅读理解等任务。
每个下游任务都有context-target样本对组成的训练集:![]() ,其中xi和yi都是token序列。例如,对于摘要任务,xi是文章内容,yi是摘要。
,其中xi和yi都是token序列。例如,对于摘要任务,xi是文章内容,yi是摘要。
在完整微调(fine-tune)的过程中,模型使用预训练好的权重Φ0来初始化模型,然后通过最大化条件语言模型来更新参数 Φ0+ΔΦ :
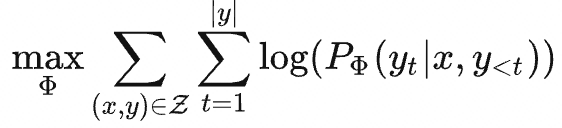
完整微调的主要缺点:对于每个下游任务,都需要学习不同的参数更新ΔΦ,其中维度 |ΔΦ|=|Φ0| 。因此,如果预训练模型很大,存储和部署许多独立的微调模型实例非常有挑战。
LoRA为了更加的参数高效,使用相对非常小的参数Θ来表示任务相关的参数增量ΔΦ=ΔΦ(Θ) ,其中 |Θ|≪|Φ0| 。寻找ΔΦ的任务就变成对Θ的优化

LoRA将会使用低秩表示来编码ΔΦ,同时实现计算高效和存储高效。当预训练模型是175B GPT-3,可训练参数 |Θ| 可以小至 |Φ0| 的 0.01% 。
参考链接:
https://blog.csdn.net/u012193416/article/details/129427242 https://finisky.github.io/lora/ https://zhuanlan.zhihu.com/p/618073170
本小节我们来学习一下,如何使用LoRA微调大语言模型bloom。
0x1:训练前准备
1、基模型
使用bloomz-7b1-mt,BigScience Large Open-science Open-access Multilingual Language Model(BLOOM)是在46种自然语言和13种编程语言上训练的1760亿参数语言模型,其是由数百名研究人员合作开发和发布的。训练BLOOM的计算力是由来自于法国公共拨款的GENCI和IDRIS,利用了IDRIS的Jean Zay超级计算机。为了构建BLOOM,对于每个组件进行了详细的设计,包括训练数据、模型架构和训练目标、以及分布式学习的工程策略。
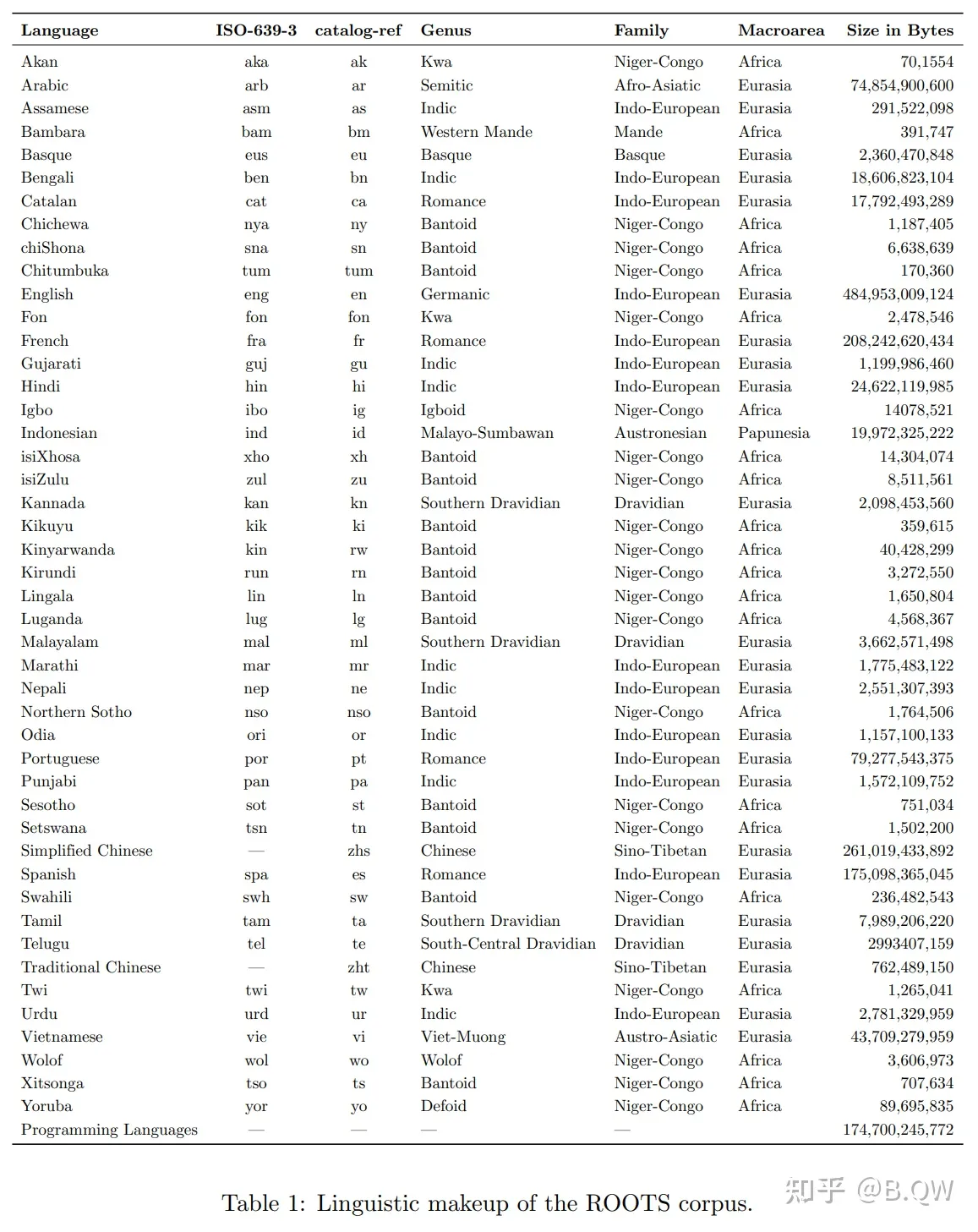
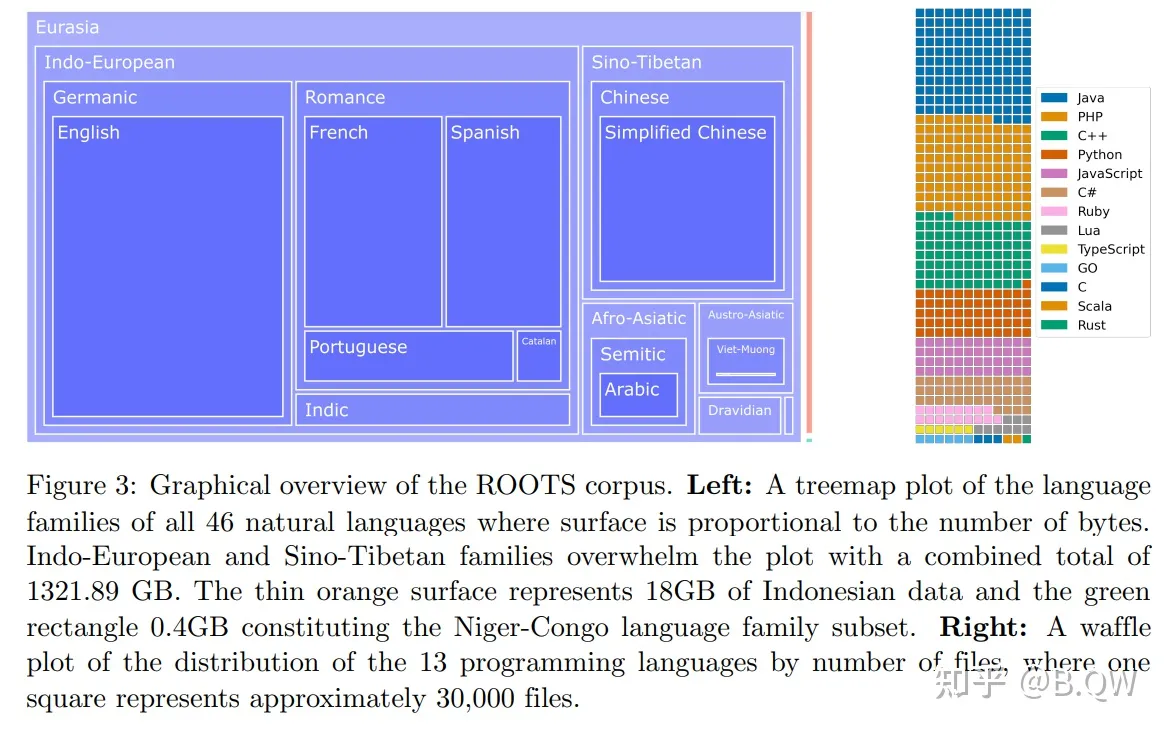
BLOOM是在一个称为ROOTS的语料上训练的,其是一个由498个Hugging Face数据集组成的语料。共计1.61TB的文本,包含46种自然语言和13种编程语言。上图展示了该数据集的高层概览,上表则详细列出了每种语言及其语属、语系和宏观区域。除了产生了语料库之外,该过程也带来了许多组织和技术工具的开发和发布。
2、prompt数据
使用BELLE提供的100万指令微调数据。
# 创建data_dir文件夹,并且下载我们参考Stanford Alpaca 生成的中文数据集1M + [0.5M](https://huggingface.co/datasets/BelleGroup/train_0.5M_CN),同时随机地划分训练和测试数据 python3 download_data.py
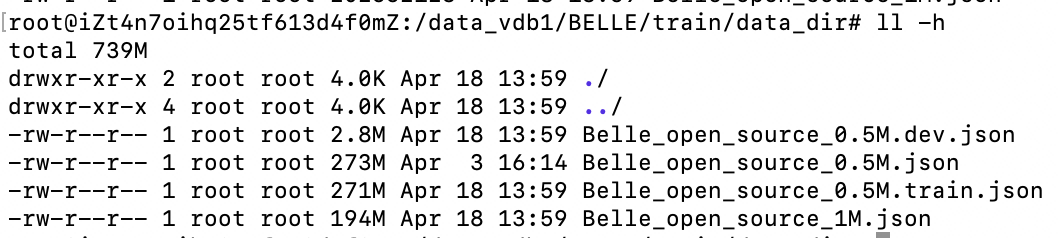
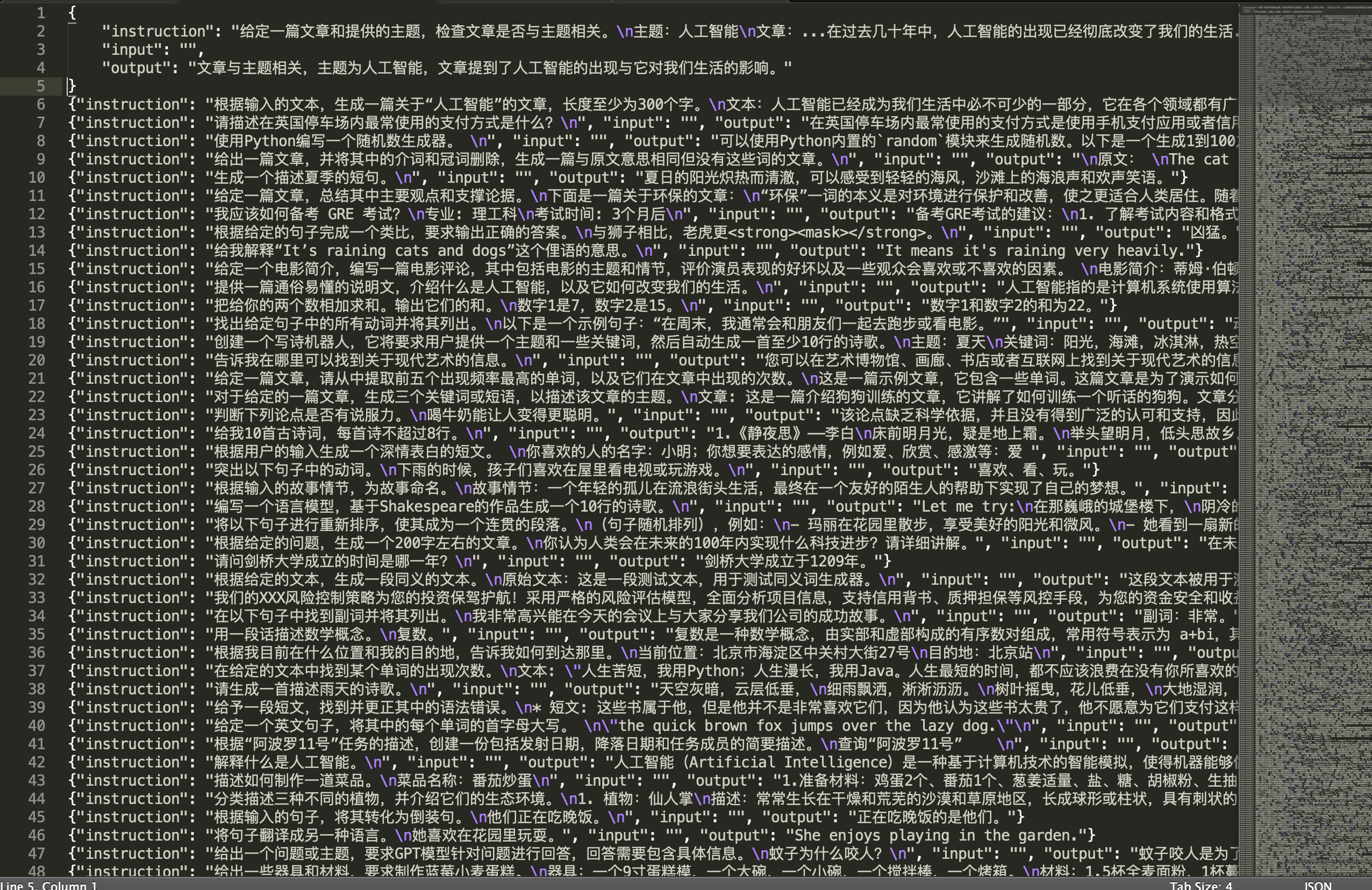
3、依赖包
使用transformers提供模型加载和训练;使用peft提供LoRA实现;使用DeepSpeed提供训练加速。
pip install transformers
pip install torch
pip install deepspeed
pip install peft
0x2:训练参数配置
1、配置Bloom模型的超参数
{ "model_type": "bloom", "model_name_or_path": "bigscience/bloomz-7b1-mt", "data_path": "data_dir/Belle_open_source_0.5M.dev.json", "output_dir": "trained_models/bloom", "batch_size": 8, "per_device_train_batch_size": 1, "num_epochs": 2, "learning_rate": 1e-5, "cutoff_len": 1024, "val_set_size": 1000, "val_set_rate": 0.1, "save_steps": 1000, "eval_steps":1000, "warmup_steps":10, "logging_steps":10, "gradient_accumulation_steps":8 }
2、配置Deepspeed策略的参数
{ "train_batch_size": "auto", "optimizer": { "type": "Adam", "params": { "lr": "auto", "betas": [ 0.9, 0.999 ], "eps": "auto", "weight_decay": "auto" } }, "overwrite":true, "steps_per_print": 5, "fp16": { "enabled": true, "min_loss_scale": 1, "opt_level": "O2" }, "zero_optimization": { "stage": 2, "allgather_partitions": true, "allgather_bucket_size": 5e8, "contiguous_gradients": true }, "scheduler": { "type": "WarmupLR", "params": { "warmup_min_lr": "auto", "warmup_max_lr": "auto", "warmup_num_steps": "auto" } } }
3、LoRA训练Bloom模型的参数
{ "lora_r": 8, "lora_alpha": 16, "lora_dropout": 0.05, "lora_target_modules": [ "query_key_value" ] }
0x3:模型训练
1、训练Bloom模型的启动命令
# 如果是单张显卡,建议使用如下命令启动 CUDA_VISIBLE_DEVICES=0 python3 finetune.py --model_config_file run_config/Bloom_config.json # 多显卡 screen deepspeed --num_gpus=1 finetune.py --model_config_file run_config/Bloom_config.json --deepspeed run_config/deepspeed_config.json
2、训练Llama模型的启动命令
# 如果是单张显卡,建议使用如下命令启动 CUDA_VISIBLE_DEVICES=0 python3 finetune.py --model_config_file run_config/Llama_config.json # 多显卡 screen deepspeed --num_gpus=1 finetune.py --model_config_file run_config/Llama_config.json --deepspeed run_config/deepspeed_config.json
3、采用LoRA训练的启动命令(Bloom模型)
# 多显卡 torchrun --nproc_per_node=1 finetune.py --model_config_file run_config/Bloom_config.json --lora_hyperparams_file run_config/lora_hyperparams_bloom.json --use_lora # 单显卡 CUDA_VISIBLE_DEVICES=0 python3 finetune.py --model_config_file run_config/Bloom_config.json --lora_hyperparams_file run_config/lora_hyperparams_bloom.json --use_lora

4、采用LoRA训练的启动命令(Llama模型)
torchrun --nproc_per_node=1 finetune.py --model_config_file run_config/Llama_config.json --lora_hyperparams_file run_config/lora_hyperparams_llama.json --use_lora
0x4:文本生成
# 训练的模型将会保存在trained_models/model_name目录下,其中model_name是模型名,比如Bloom,Llama。假设训练的模型是Bloom,训练数据采用的是Belle_open_source_0.5M,下面的命令将读取模型并生成测试集中每一个样本的生成结果 python3 generate.py --dev_file data_dir/Belle_open_source_0.5M.dev.json --model_name_or_path trained_models/bloom/ # 如果是LoRA模型,需要给出LoRA权重保存的位置,如:--lora_weights trained_models/lora-llama
参考资料:
https://zhuanlan.zhihu.com/p/603518061 https://github.com/LianjiaTech/BELLE https://zhuanlan.zhihu.com/p/618073170
首先列举一下影响大模型在具体垂直领域应用效果的影响因子:
- 基础大模型本身的参数规模,目前认为超过100B以后才能产生推理链、上下文学习、知识推理等涌现能力
- 基模型训练语料库和目标任务的关联性、迁移性
- fine-tune参数空间
- prompt template对目标任务描述的精确度,业务人员需要根据具体垂直领域的任务,有针对性地设计一个prompt template,这个模板设计的质量/数据丰富度直接影响到最终prompt-tuning的效果
- 计算架构,A100(4卡以上)基本成为大模型训练、fine-tune的入门条件,本质上一个ROI问题
其中,我们重点来关注一下prompt template的设计问题。
首先要关注的是”Instruct verbs“,它是instruction中的动词,因为attention机制的存在,大模型会对instruction中的特定关键词给予更多的关注(权重)。
指示动词是提示中的第一个词,它们用于指示模型做某事,它们是提示中最重要的部分,有助于让机器理解并遵循您的指令。这些动词中的每一个都有特定的含义,可以帮助模型理解期望的答案类型,例如,
- 如果你要求模型解释某事,它会提供详细的解释
- 如果你要求模型总结一些东西,它会提供一个简短的概述
- 如果你要求模型注意你输入文本的特定位置/部分,可以使用如下动词
- Given text
- following passage
- Following
- The following
- 如果你要求模型遵照你的指令执行特定的动作,可以使用如下动词
- Explain
- Create
- Generate
- Provide
- Write
- Summarize
- Paraphrase
- Translate
- Rewrite
- Reword
- Rephrase
- List
- Extract
- Pick out
- Analyze
- Define
- Identify
- Describe
- Predict
- Explain
- Analyze
- compare
- Categorize
- Evaluate
- Critique
- Differentiate
- Examine
- Illustrate
- Outline
- Calculate
- Infer
- Revise
- Summarize
- Classify
- Develop
- Evaluate
- Formulate
- Discuss
- Clarify
- Highlight
- Simplify
- Apply
- Suggest / Propose
- Make
接下来要关注的是”prompt style/format“,有以下几个选择方式可供参考:
- 一致性:一致的风格使您的提示更易于预测,更易于 AI 模型理解。 它确保模型接收到清晰的指令并在多个提示中产生所需的输出。
- 清晰:定义明确的样式可确保您的说明清晰明确。 这减少了 AI 模型误解您的提示或生成不相关或不需要的响应的可能性。
- 效率:良好的风格可以让您有效地传达您的需求,减少多次迭代或调整提示的需要。 这样可以节省时间和资源。
- 自定义:通过采用特定样式,您可以定制输出以匹配您所需的色调、格式和细节级别。 这在尝试生成符合特定品牌声音、行业标准或目标受众的内容时特别有用。
当选定了一种prompt style之后,有以下几种原则可供遵守:
- 细节和特异性:对所需的背景、结果、长度、格式和风格尽可能具体和详细。
- 指令放置:将指令放在提示符的开头,并使用###或“””等分隔符将指令和上下文分开。
- 示例:提供所需输出格式的示例,这有助于模型更好地理解您的期望。
- 避免乱七八糟:使用简明扼要的语言来尽量减少歧义和混淆。
- 积极的指示:与其说不该做什么,不如说该做什么。
参考资料:
https://github.com/kevinamiri/Instructgpt-prompts
完全从零开始生成一个新的webshell样本,不管是直接基于基模型还是fine-tune,搜索空间都太大了,基本不现实。一个现实可落地的方向是:通过prompt-tuning,预定义一些指令(比如期望生成webshell具备的代码功能等)以及答案模板(webshell样本示例),让大模型学习到如何将一组代码功能的指令”翻译“为一段可运行的webshell代码。
笔者认为一个可能的pipeline如下:
- 通过下载php开发文档,枚举所有内置函数,记为php_func_list(),每次生成instruction时从该数组中随机选择【3,10】随机个数的函数,指示大模型生成的代码需要用到被选中的函数,用于指示大模型需要生成代码的功能边界
- 通过安全专家的经验,枚举所有容易被杀软检测到的代码特征(例如”不能出现'eval'的明文编码“),记为anti_av_trick_list(),每次生成instruction时从该数组中随机选择【1,3】随机个数的trick,用于指示大模型生成代码的风格(倾向非常规方式)
- 将php_func和trick拼接到一个context template中,生成一段instruction
- 通过chatGPT的API获取instruction的output
- 累计到5000对样本量,作为prompt-tune的语料库,通过lora fine-tune一个llma模型,得到一个可以根据一些指令和描述生成webshell的大模型
中文instruction模板:
请帮我生成一段可以运行的php代码,代码中至少使用如下函数: "variant_int"、"http_get_request_body"等函数,同时它具备接受通过HTTP协议传入的外部可控参数,代码没有对外部传入的参数做输入校验,通过某种方式解析执行了外部传入的参数,并返回执行结果。同时需要注意,生成的代码不能包含如下特征: "Clear text encoding of 'eval' cannot appear in the code"。请按照上述要求生成一段可以运行的php代码,并尝试给出一段包含访问参数的http访问链接。
英文instruction模板:
Please help me generate a executable PHP code that uses at least the following functions: "variant_int", "http_get-request_body", and other functions. It also accepts external controllable parameters passed in through the HTTP protocol, and the code does not perform input validation on external parameters. It parses and executes the external parameters in some way and returns the execution result. It should also be noted that the generated code cannot contain the following features: "Clear text encoding of 'eval' cannot appear in the code". Please generate a running PHP code according to the above requirements and try providing an HTTP access link containing access parameters.
如有侵权请联系:admin#unsafe.sh