原文链接:https://arxiv.org/pdf/2302.13971.pdf0x1:引言 在大语料上训练得到的大语言模型(LLM)已经展示了它们的实力,在few-shot特性展现之后,有 2023-4-19 21:6:0 Author: www.cnblogs.com(查看原文) 阅读量:84 收藏
原文链接:https://arxiv.org/pdf/2302.13971.pdf
0x1:引言
在大语料上训练得到的大语言模型(LLM)已经展示了它们的实力,在few-shot特性展现之后,有一系列的工作都关注于提高这些模型的规模。它们的努力是基于更多的参数可以带来更好的性能的假设之上。
但是Hoffmann的工作表示,在给定预算的条件下,最好的模型并不一定是最大的模型,在更多的数据上训练的较小的模型反而会达到更好的性能。Hoffmann工作的目的是决定如何确定数据集和模型大小的规模,但是他忽略了推理的成本。所以在这篇文章中,给定一个目标的性能等级,更推荐的模型不是最快训练的,但是是最快推理的。产生的模型称为LLaMA,参数范围从7B到65B,与现在最好的LLM相当。
LLaMA-13B比GPT-3在大多数benchmarks上性能都要好,但是模型大小缩减到十分之一。Meta团队相信这个模型有助于LLM的使用和研究的大众化,因为可以在单个GPU上运行。在更高的规模量上,65B参数量模型与当前最好的LLM(比如Chinchila或PaLM-540B)相比更具有竞争力。LLaMA的另一个优势是它是使用公开数据集进行训练。
在论文的剩余部分,作者概述对Transformer架构的调整以及训练方法的调整。然后,作者介绍了LLaMA的性能,以及在benchmark上与其他LLM的比较。最后,作者揭露了在他们编码中的偏见和毒性。
主要贡献:
- 开源一系列语言模型,可以与SOTA模型竞争
- LLaMA-13B比GPT-3的性能更好,但是模型大小却是十分之一
- LLaMA-65B与Chinchilla-70B和PaLM-540B的实力相当
- 使用公开数据集即可部分复现最先进的性能(86%左右的效果)
0x2:方法
这项工作的训练方法相似于Brown的工作,并且受到Hoffmann的启发。模型使用标准优化器进行优化。
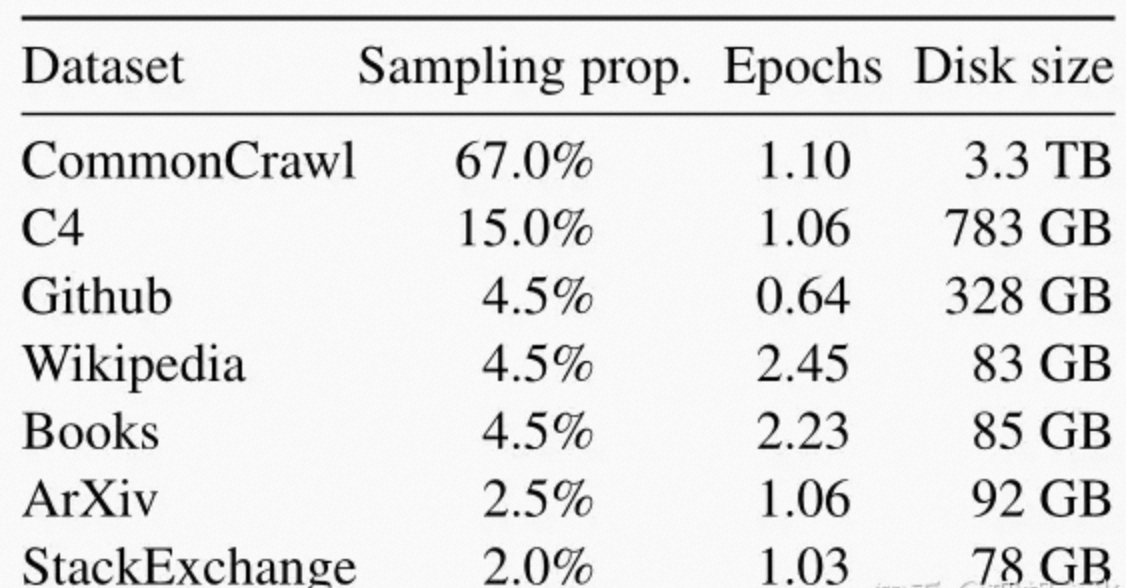
1、预训练数据
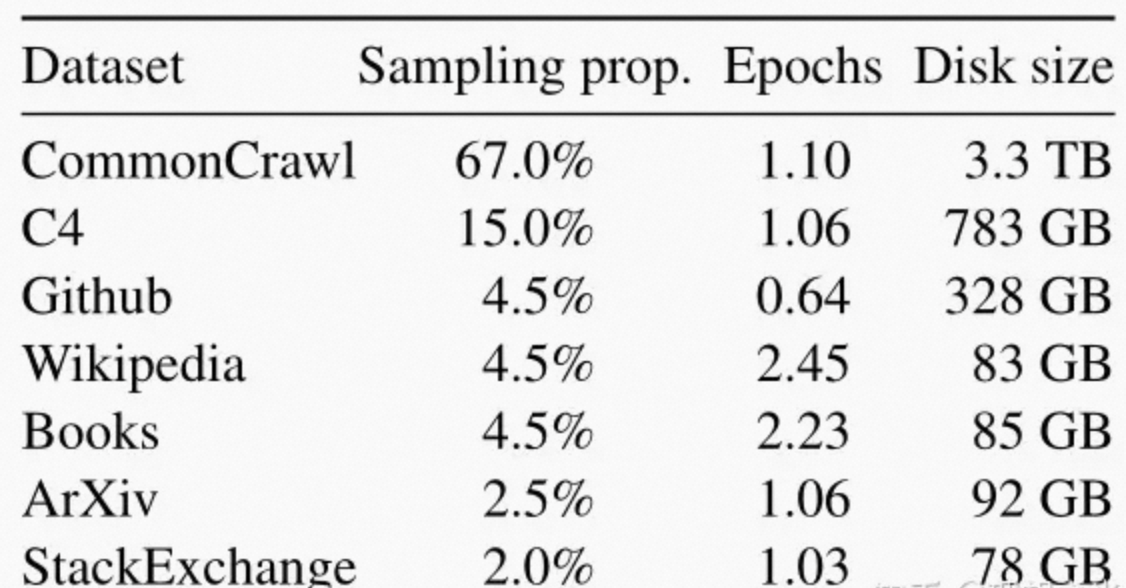
2、模型架构
与目前在LLM上的工作相似,本工作基于transformer架构,并且利用了Transformer后续提出的各种改进,下面是与原始架构不同之处,灵感来源在括号中显示。
- 预正则化[GPT3],为了提高训练的稳定性,在每个transformer子层的input处进行正则化,而不是在output处,使用的正则化方法是RMSNorm。
- SwiGLU activation function[PaLM],激活函数使用SwiGLU激活函数,而非ReLU,使用的维度是
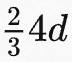 ,而不是PaLM中的4d。
,而不是PaLM中的4d。 - Rotary Embeddings[GPTNeo],去掉原来的绝对positional embeddings,而是使用rotary positional embeddings。
3、优化器
LLaMA使用AdamW优化器,超参数是![]() ,使用余弦学习率调度,这样最终的学习率是最大的学习率的十分之一,使用的权重衰减为0.1,梯度剪裁为1,使用2000个热身步,并且根据模型的大小而改变学习率和批处理大小。
,使用余弦学习率调度,这样最终的学习率是最大的学习率的十分之一,使用的权重衰减为0.1,梯度剪裁为1,使用2000个热身步,并且根据模型的大小而改变学习率和批处理大小。
4、训练速度优化
通过以下方法来提高训练速度:
- 使用因果多头注意力来减少内存的使用和运行时间。这个实现可以通过
xformers库完成。之所以可以达到这个效果,是因为它不存储注意力权重和不计算由于语言建模任务的因果性质而被掩盖的关键字/查询分数。 - 通过检查点减少向后传播期间重新计算的激活量。这是通过手动实现转换器的向后传播函数来实现的,而不是以来PyTorch的autograd。为了能充分利用这种优化,需要通过使用模型和序列并行性来减少模型的内存使用。此外,还尽可能重叠了激活的计算和GPU之间的网络的通信(使用
all_reduce)。
当训练65B参数模型时,代码在2048个A100 GPU和80GB RAM上处理大约380个token/秒/GPU,这意味着1.4T个token的数据集训练大概需要21天。
5、主要结果
1)zero-shot/few-shot任务表现
像大部分的工作一样,这项工作使用zero-shot和few-shot的任务,在20个benchmarks上进行实验。
主要实验的内容有:
- 常识推理
- 闭卷问答
- 阅读理解
- 数学推理
- 代码生成
- 大规模多任务语言理解
2)Instruction Finetuning
对instruction data进行简单的微调可以快速改进MMLU。
3)偏见、毒性和错误信息
根据之前的研究所得,LLM生成的信息有潜在的毒性,所以去判定一个LLM生成毒性信息的潜力是有必要的。为了了解LLaMA-65B的潜在危害,作者在不同的benchmarks上评估有毒成分的生成和进行定型检测。
4)RealToxicityPrompts
一个模型可以产生的有毒成分范围非常大,这使得彻底的评估具有挑战性。许多最近的工作选择采用RealToxicityPrompts benchmark来表征模型的毒性。RealToxicityPrompts由100K个prompts组成,然后模型必须完成这些prompt,再由PerspectiveAPI生成得分。但是作者无法控制使用第三方API的管道,所以使得和以前的模型比较变得困难。
对于每个prompt,作者都贪婪地用模型生成结果,并测量它们的得分,得分范围从0(无毒)到1(有毒)。
0x3:相关工作
1、语言模型
1951年Shannon提出语言模型是单词、token或者字符序列的概率分布。下一个token预测一直被认为是自然语言处理中的一个核心问题。因为图灵提出通过“模仿游戏”使用语言来衡量机器智能,因此语言建模被认为是衡量人工智能的benchmark。
2、架构
在过去,语言模型基于n-gram的数量统计,并且提出大量的平滑技术来改进罕见事件的估计。在过去二十年,神经网络成功地应用到语言模型任务中,从前馈神经网络、RNN到LSTM。最近Transformer架构,基于自注意力的特性使得自然语言处理领域有了巨大进步,尤其是在获取长距离依赖关系的时候。
3、缩放
对于语言模型,在模型和数据集上进行规模的改变都有着悠久的历史。Brants等人展示了使用在2trillion tokens、300billion n-grams上训练对机器翻译质量的提升,但是这项工作依赖于一种简单的平滑工具,称为Stupid Backoff。后来Heafield等人展示如何将Kneser-Ney平滑扩展到Web-scale的数据,他从CommonCrawl获取数据集,训练了一个在975billions token上的5-gram模型,从而得到一个有500billions n-grams的模型。Chelba引入One Billion Wordbenchmark,一个用来衡量语言模型进展的大规模训练集。
在神经语言模型的背景下,Jozefowicz达到Billion Word Benchmark的SOTA,方法是将LSTM扩大到1B参数;后面还有一系列对Transformer进行缩放的模型,比如BERT,GPT-2,Megatron-LM和T5,其中比较著名的是有175B参数的GPT-3,这催生了一系列LLM,比如Jurassic-1,Megatron-Turing NLG,Gopher,Chinchilla,PaLM,OPT和GLM。Kaplan专门为transformer模型推导了幂律,Hoffmann通过在scaling数据集时调整学习率,修改了它。
参考链接:
https://arxiv.org/pdf/2302.13971.pdf https://zhuanlan.zhihu.com/p/618297774
下载基模型参数
git clone https://huggingface.co/nyanko7/LLaMA-7B
调用基模型进行生成任务:
python3 example.py --llama-path modles/llama --model 7B
参考链接:
https://github.com/facebookresearch/llama https://github.com/galatolofederico/vanilla-llama https://huggingface.co/decapoda-research/llama-7b-hf/tree/main?doi=true https://huggingface.co/nyanko7/LLaMA-7B/tree/main
0x1:fine-tune训练
本节中,我们介绍如何基于TencentPretrain预训练框架训练LLaMA模型。
TencentPretrain 是UER-py预训练框架的多模态版本,支持BERT、GPT、T5、ViT、Dall-E、Speech2Text等模型,支持文本、图像和语音模态预训练及下游任务。TencentPretrain基于模块化设计,用户可以通过模块组合的方式构成各种模型,也可以通过复用已有的模块进行少量修改来实现新的模型。例如,LLaMA的模型架构基于Transformer有三项改动:
- 前置normalization[GPT3]:在每个transformer层输入之前进行标准化,以提高训练稳定性。标准化层使用RMSNorm。
- SwiGLU激活函数[PaLM]:在Feedforward层使用Gated Linear Units [T5]以及SwiGLU激活函数。
- 旋转位置编码[GPTNeo]:移除了Embedding层的绝对位置编码,并在每个transformer层增加旋转位置编码(RoPE)。
得益于模块化特性,我们在TencentPretrain中基于GPT2模型的已有模块,仅添加约100行代码就能实现以上三个改动从而训练LLaMA模型。具体的使用步骤为。
1、克隆 TencentPretrain 项目,并安装依赖:PyTorch、DeepSpeed、SentencePiece git clone https://github.com/Tencent/TencentPretrain.git 2、下载 LLaMA 模型权重(7B),可以向 FacebookResearch 申请模型,或者从 Huggingface 社区获取;将模型权重转换为 TencentPretrain 格式 git clone https://huggingface.co/nyanko7/LLaMA-7B cd TencentPretrain python3 scripts/convert_llama_to_tencentpretrain.py --input_model_path models/LLaMA-7B/consolidated.00.pth --output_model_path models/llama-7b.bin --layers_num 32 3、调整配置文件 将 tencentpretrain/utils/constants.py 文件中 L4: special_tokens_map.json 修改为 llama_special_tokens_map.json 4. 语料预处理:使用项目自带的语料作为演示,也可以使用相同格式的语料进行替换 预训练语料下载:https://github.com/dbiir/UER-py/wiki/%E9%A2%84%E8%AE%AD%E7%BB%83%E6%95%B0%E6%8D%AE python3 preprocess.py --corpus_path corpora/book_review.txt --spm_model_path models/LLaMA-7B/tokenizer.model --dataset_path dataset.pt --processes_num 8 --data_processor lm 5. 启动训练,以单卡为例 deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_config.json \ --pretrained_model_path models/llama-7b.bin \ --dataset_path dataset.pt --spm_model_path models/LLaMA-7B/tokenizer.model \ --config_path models/llama/7b_config.json \ --output_model_path models/LLaMA-7B/output_model.bin \ --world_size 1 --learning_rate 1e-4 \ --data_processor lm --total_steps 10000 --save_checkpoint_steps 2000 --batch_size 24
启动训练后,可以看到模型的 loss 和准确率。
0x2:lora-fine-tuning训练
0x3:模型推理
类似facebookresearch/llama ,TencentPretrain也提供语言模型推理代码。例如,使用单卡进行LLaMA-7B推理,prompt在文件beginning.txt中:
python3 scripts/generate_lm.py --load_model_path models/llama-7b.bin --spm_model_path models/LLaMA-7B/tokenizer.model \ --test_path beginning.txt --prediction_path generated_sentence.txt \ --config_path models/llama/7b_config.json
开源的LLaMA模型在预训练阶段主要基于英语训练,也具有一定的多语言能力,然而由于它没有将中文语料加入预训练,LLaMA在中文上的效果很弱。利用TencentPretrain框架,用户可以使用中文语料增强LLaMA的中文能力,也可以将它微调成垂直领域模型。
参考链接:
https://github.com/dbiir/UER-py https://zhuanlan.zhihu.com/p/612752963 https://github.com/Tencent/TencentPretrain
参考链接:
https://github.com/ymcui/Chinese-LLaMA-Alpaca
0x1:项目背景

a lightweight adaption method for fine-tuning instruction-following LLaMA models, using 52K data provided by Stanford Alpaca.
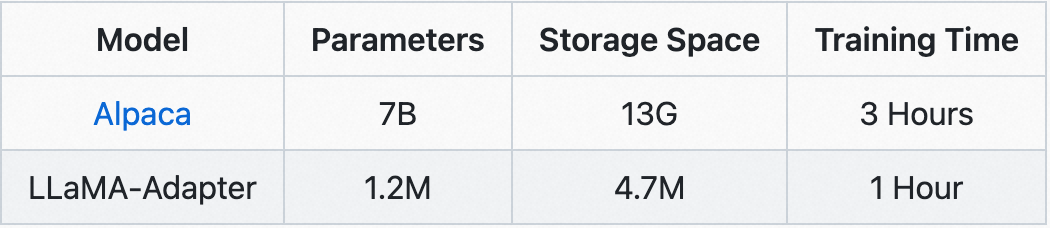
By inserting adapters into LLaMA's transformer, our method only introduces 1.2M learnable parameters, and turns a LLaMA into an instruction-following model within 1 hour. For stablizing training at early stages, we propose a novel Zero-init Attention with zero gating mechanism to adaptively incorporate the instructional signals. After fine-tuning, LLaMA-Adapter can generate high-quality instruction-following sentences, comparable to the fully fine-tuned Stanford Alpaca and Alpaca-Lora.
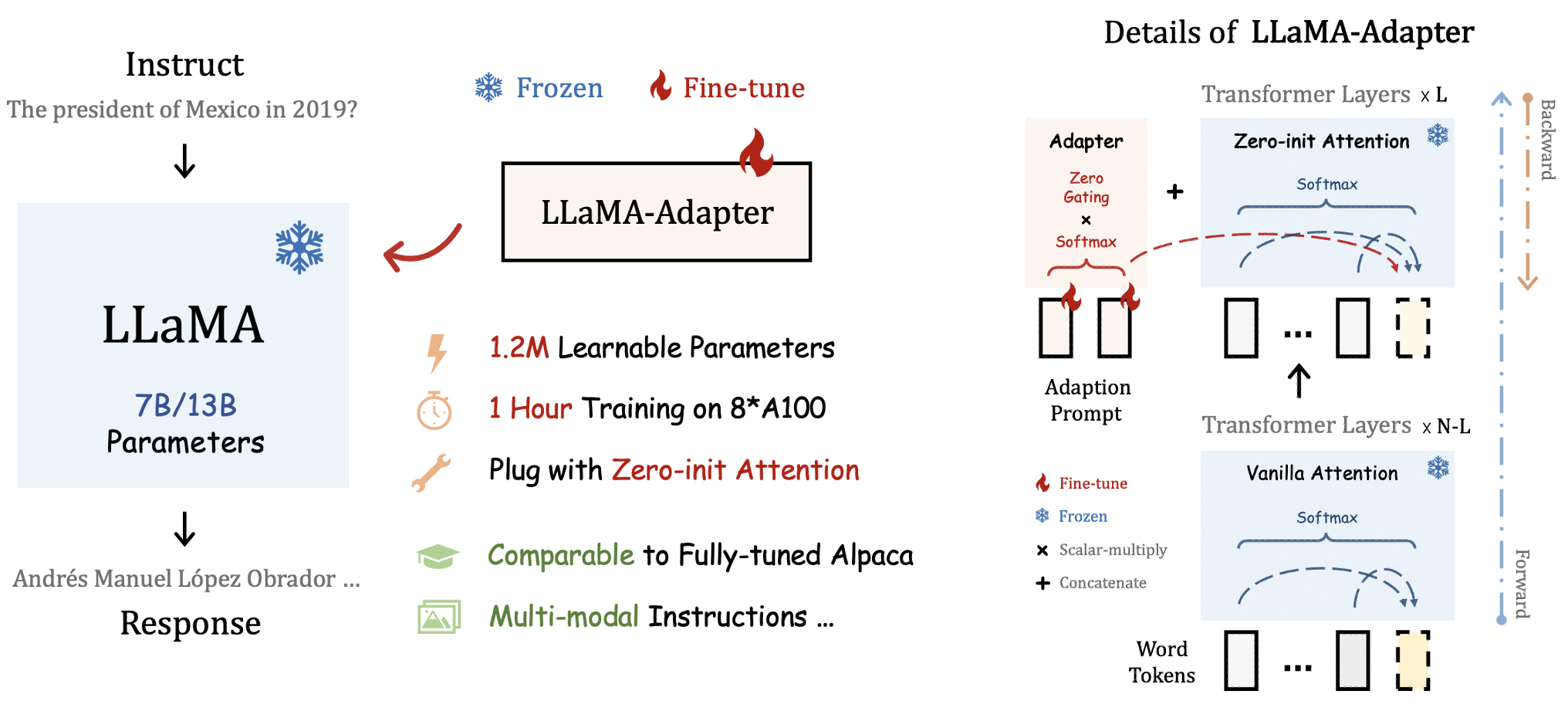
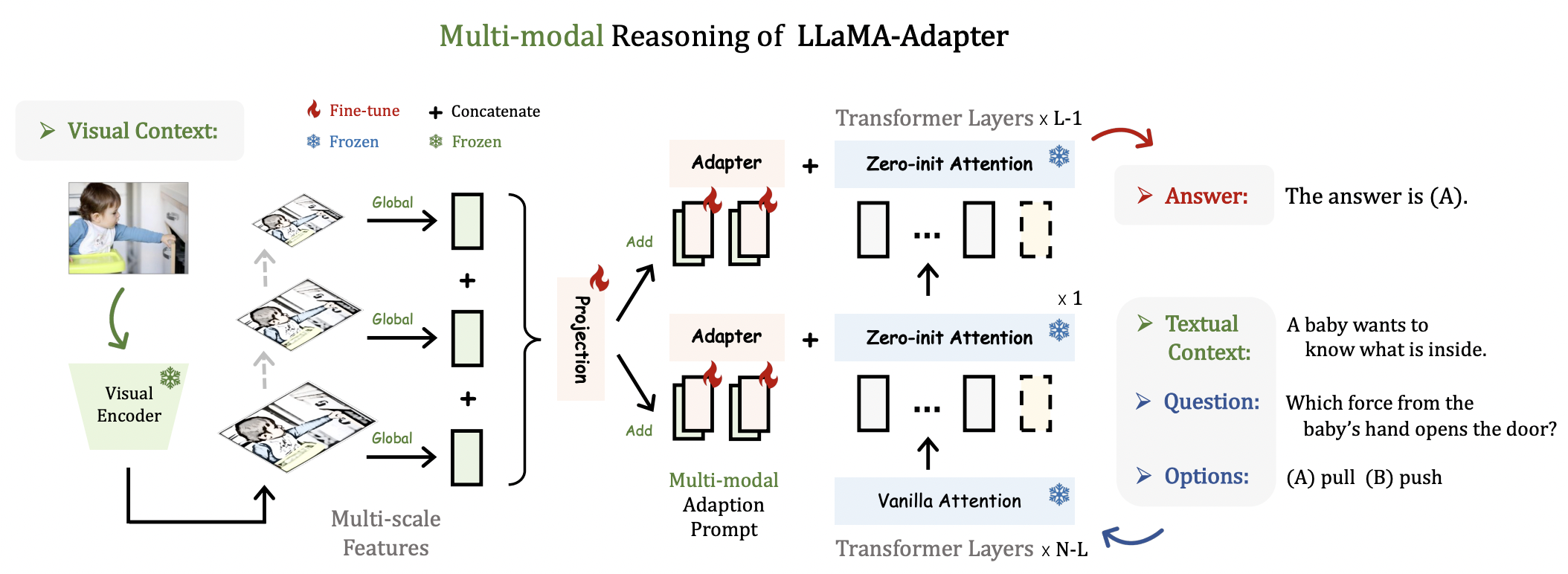
Our approach can be simply extended to Multi-modal Input Instructions.
0x2:使用LLaMA-Adapter基模型进行文本生成
下载llama-7b模型:
git clone https://huggingface.co/nyanko7/LLaMA-7B
下载LLaMA-Adapter模型权重:
https://github.com/ZrrSkywalker/LLaMA-Adapter/releases/download/v.1.0.0/llama_adapter_len10_layer30_release.pth
文本生成:
conda create -n llama_adapter -y python=3.8 conda activate llama_adapter # install pytorch conda install pytorch cudatoolkit -c pytorch -y # install dependency and llama-adapter pip install -r requirements.txt pip install -e . CUDA_VISIBLE_DEVICES=0 python3 example.py --ckpt_dir ./models/llama-7b --tokenizer_path ./models/llama-7b/tokenizer.model --adapter_path ./models/llama-7b torchrun --nproc_per_node 1 example.py --ckpt_dir models/7b/ --tokenizer_path models/7b/tokenizer.model --adapter_path models/7b torchrun --nproc_per_node 1 example.py --ckpt_dir ./models/llama-7b --tokenizer_path ./models/llama-7b/tokenizer.model --adapter_path ./models/llama-7b
0x3:fine-tune重训练
下载数据集:
https://raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json

启动训练:
cd alpaca_finetuning_v1 torchrun --nproc_per_node 1 finetuning.py --model Llama7B_adapter --llama_model_path ../models/llama-7b/ --data_path ../data_dir/alpaca_data.json --adapter_layer 30 --adapter_len 10 --max_seq_len 512 --batch_size 4 --epochs 5 --warmup_epochs 2 --blr 9e-3 --weight_decay 0.02 --output_dir ../models/llama-7b/checkpoint/ # 单显卡 CUDA_VISIBLE_DEVICES=0 python3 finetuning.py --model Llama7B_adapter --llama_model_path ../models/llama-7b/ --data_path ../data_dir/alpaca_data.json --adapter_layer 30 --adapter_len 10 --max_seq_len 512 --batch_size 4 --epochs 5 --warmup_epochs 2 --blr 9e-3 --weight_decay 0.02 --output_dir ../models/llama-7b/checkpoint/
参考链接:
https://arxiv.org/abs/2303.16199 https://github.com/ZrrSkywalker/LLaMA-Adapter https://huggingface.co/spaces/csuhan/LLaMA-Adapter https://github.com/tatsu-lab/stanford_alpaca
0x1:项目背景
This repository contains code for reproducing the Stanford Alpaca results using low-rank adaptation (LoRA). We provide an Instruct model of similar quality to text-davinci-003 that can run on a Raspberry Pi (for research), and the code is easily extended to the 13b, 30b, and 65b models.
In addition to the training code, which runs within hours on a single RTX 4090, we publish a script for downloading and inference on the foundation model and LoRA, as well as the resulting LoRA weights themselves. To fine-tune cheaply and efficiently, we use Hugging Face's PEFT as well as Tim Dettmers' bitsandbytes.
Without hyperparameter tuning, the LoRA model produces outputs comparable to the Stanford Alpaca model. (Please see the outputs included below.) Further tuning might be able to achieve better performance; I invite interested users to give it a try and report their results.
0x2:lora-fine-tune训练
准备训练数据集:
https://huggingface.co/datasets/yahma/alpaca-cleaned/tree/main

启动训练:
screen python3 finetune.py --base_model 'decapoda-research/llama-7b-hf' --data_path 'yahma/alpaca-cleaned' --output_dir './lora-alpaca' screen python3 finetune.py --base_model 'decapoda-research/llama-7b-hf' --data_path 'yahma/alpaca-cleaned' --output_dir './lora-alpaca' --batch_size 64 --micro_batch_size 4 --num_epochs 30 --learning_rate 1e-6 --cutoff_len 1024 --val_set_size 2000 --lora_r 8 --lora_alpha 16 --lora_dropout 0.05 --lora_target_modules '[q_proj,v_proj]' --train_on_inputs --group_by_length # 本地训练集 screen python3 finetune.py --base_model 'decapoda-research/llama-7b-hf' --data_path './data_dir/alpaca_data_cleaned.json' --output_dir './lora-alpaca' --batch_size 128 --micro_batch_size 4 --num_epochs 30 --learning_rate 1e-5 --cutoff_len 1024 --val_set_size 2000 --lora_r 8 --lora_alpha 16 --lora_dropout 0.05 --lora_target_modules '[q_proj,v_proj]' --train_on_inputs --group_by_length # Official weights screen python3 finetune.py --base_model 'decapoda-research/llama-7b-hf' --data_path './data_dir/alpaca_data_cleaned.json' --output_dir './lora-alpaca' --batch_size 128 --micro_batch_size 4 --num_epochs 30 --learning_rate 1e-5 --cutoff_len 1024 --val_set_size 2000 --lora_r 8 --lora_alpha 16 --lora_dropout 0.05 --lora_target_modules '[q_proj,k_proj,v_proj,o_proj]' --train_on_inputs --group_by_length
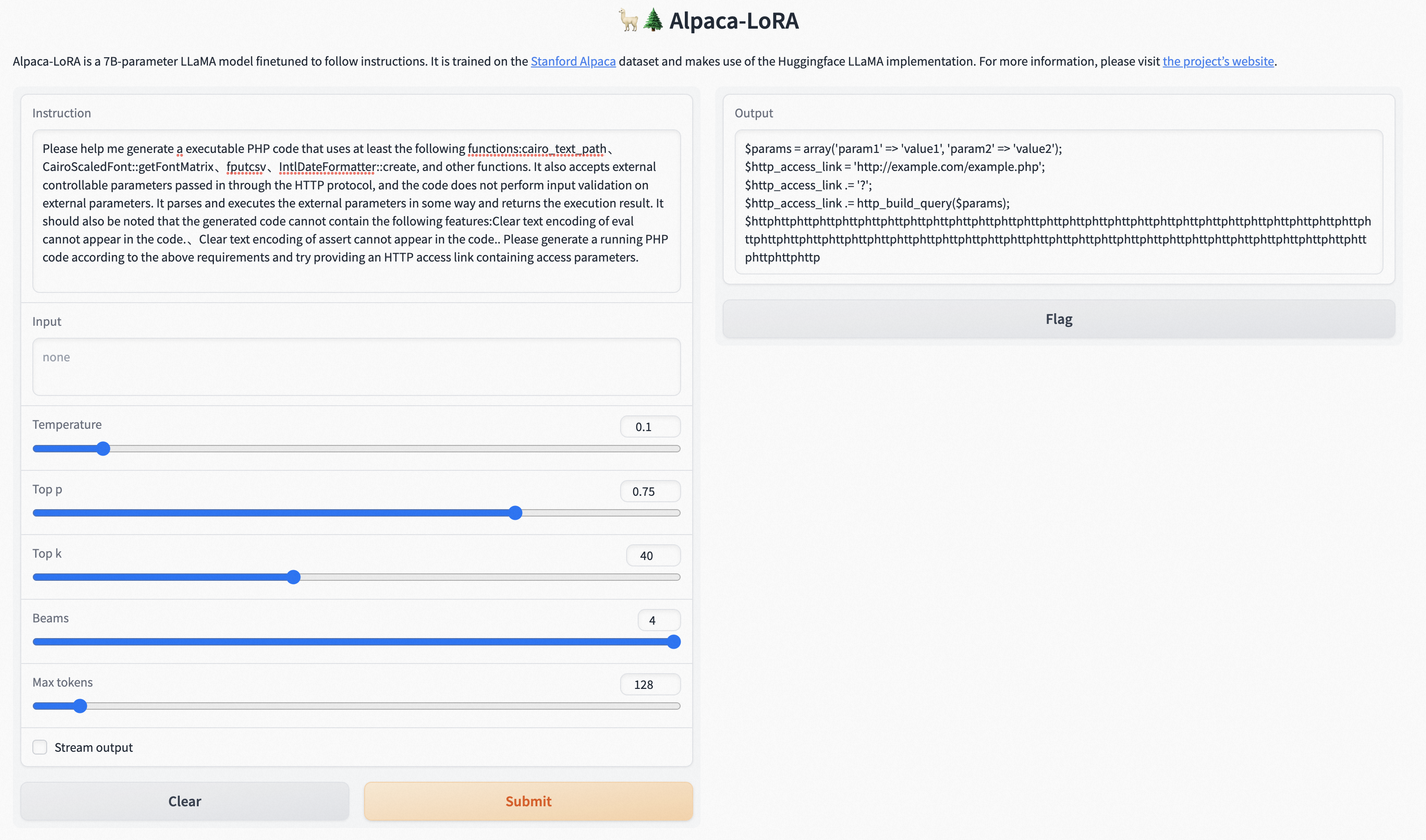
0x3:文本生成
This file reads the foundation model from the Hugging Face model hub and the LoRA weights from tloen/alpaca-lora-7b, and runs a Gradio interface for inference on a specified input.
python3 generate.py --load_8bit --base_model 'decapoda-research/llama-7b-hf' --lora_weights 'tloen/alpaca-lora-7b'

0x4:Checkpoint export (export_*_checkpoint.py)
These files contain scripts that merge the LoRA weights back into the base model for export to Hugging Face format and to PyTorch state_dicts. They should help users who want to run inference in projects like llama.cpp or alpaca.cpp.
GPT-4系列技术的集中出现,同时在人工智能技术/人工智能技术研发/人工智能领域应用,三个领域引发了不同程度的范式革命的讨论。笔者现在还不确定这个范式转移是否会,以及多大程度上发生,这里梳理了一下简单的思考和推理过程。
0x1:GPT大模型研发范式
- 第一梯队:openAI(GPT-4、xxx)、facebook(llama)、bloom、文心一言、通义千问等一线有庞大算力和数据的科技公司,这些大模型是真正的”大模型基准“,整个行业基本都依赖这些基模型的api和开源模型
- 第二梯队:llama-lora、alpace、chinese-llama等等等等,这个部分占比最大,这部分又分为两个主要流派
- 具有一定科研/算法能力的组织机构,在开源llama模型基础上,对模型本身的结构/连接参数、参数个数、优化方式等进行修改和优化,意图在模型层面设计出
- 从事IT/信息产业的业务人员,他们拥有具体的业务场景和场景数据,基于开源/二开的开源大模型(例如llama、llama-lora)进行fine-tune/prompt-tune,研发适配于特定垂直领域的大模型
- 第三梯队:没有能力进行自主研发,只能基于开源大模型或二开的大模型,直接应用到自己的业务pipeline中
在这三个范式之下,业内还有很多团队focus在计算架构和训练效率的优化,例如petf、deepsppeed、lora、torchrun技术等。
需要注意的是,大模型的研发和调优,对CPU内存/GPU主频配置/GPU显存等因素都有不同以往的要求,这对很多开发者和机构来说可能也是一个不小地门槛。
0x2:GPT大模型应用范式
1、prompt统一范式
- 基于大模型”in-context learning“能力,将领域问题转化为”生成任务“
- 基于大模型”chain-of-thought“能力,将领域问题转化为”推理任务“
- 基于大模型”knowledge reasoning“,将领域问题转化为”抽取/总结任务“
1)生成任务
恶意代码生成(智能武器库)
设计一个代码使用描述,例如:
- 具备哪些功能
- 使用哪些编码方式
- 需要具备哪些免杀手段
- 目前遇到的防火墙/文件拦截返回码,用于指示模型要规避一些特定的代码特征
- ....
将上述要求拼接成一个prompt模板,将原始非结构化样本数据处理为instruction-output格式的成对训练集。
- instruction:代码对应的功能、危害性描述
- output:代码
恶意代码检测
- instruction:原始代码
- output:illegal/legal
2)推理任务
智能入侵溯源
- instruction:事件发生时间窗口内的进程、网络、文件读写、敏感系统api调用、告警事件详情日志
- output:可能的入侵原因描述,清理建议,加固建议
3)抽取/总结任务
代码分析、代码解释
- instruction:代码
- output:代码对应的功能、危害性描述
用于在安全运营和应急响应中,向安全和IT人员提供样本的可读化描述,提升事件处理效率。
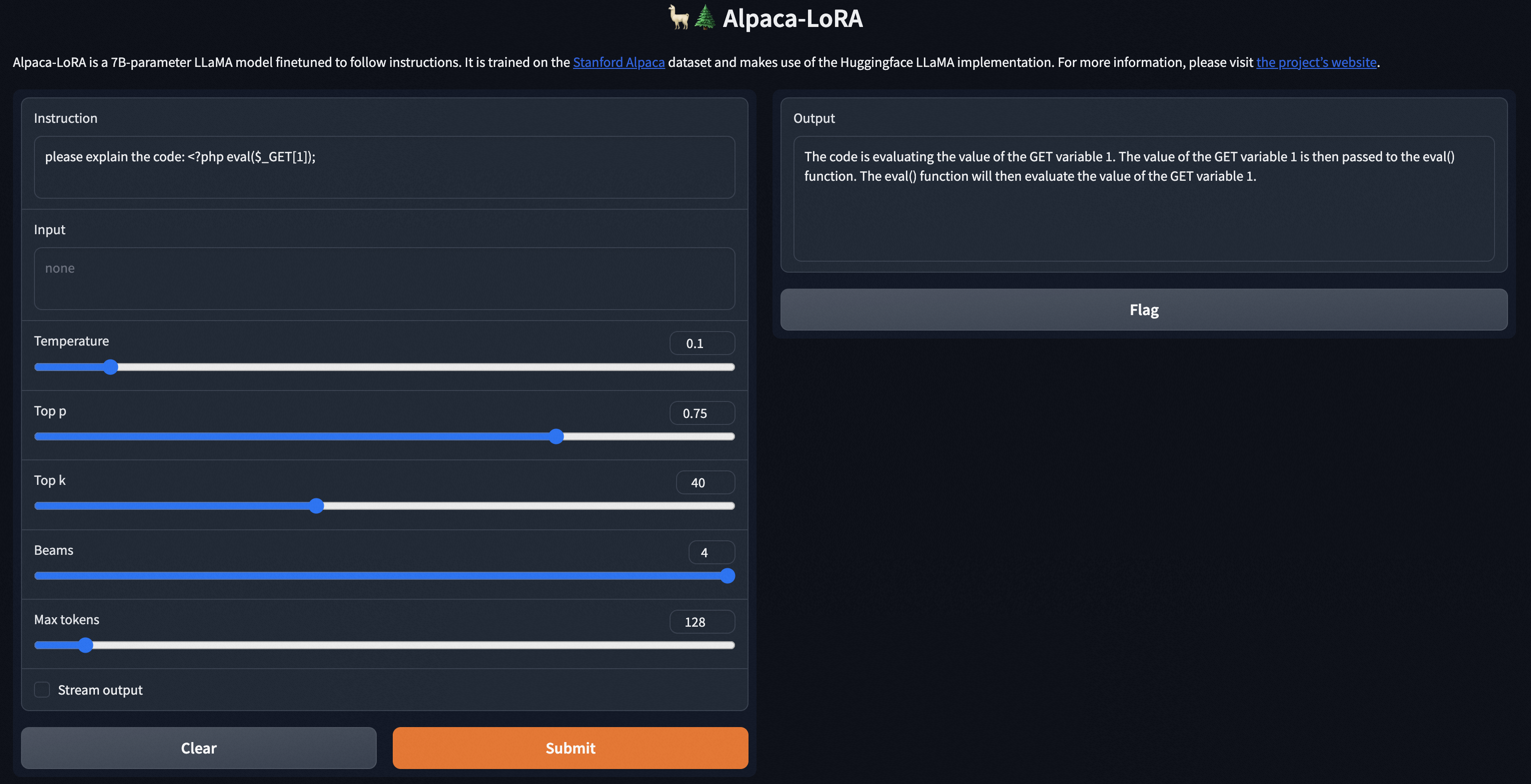
攻击日志分析
- instruction:waf http request日志、4层流量日志、7层防火墙日志
- output:利用的漏洞描述/漏洞号等,攻击成功后可能造成的危害
如有侵权请联系:admin#unsafe.sh