
Loading...



At Cloudflare, we are building proxy applications on top of Oxy that must be able to handle a huge amount of traffic. Besides high performance requirements, the applications must also be resilient against crashes or reloads. As the framework evolves, the complexity also increases. While migrating WARP to support soft-unicast (Cloudflare servers don't own IPs anymore), we needed to add different functionalities to our proxy framework. Those additions increased not only the code size but also resource usage and states required to be preserved between process upgrades.
To address those issues, we opted to split a big proxy process into smaller, specialized services. Following the Unix philosophy, each service should have a single responsibility, and it must do it well. In this blog post, we will talk about how our proxy interacts with three different services - Splicer (which pipes data between sockets), Bumblebee (which upgrades an IP flow to a TCP socket), and Fish (which handles layer 3 egress using soft-unicast IPs). Those three services help us to improve system reliability and efficiency as we migrated WARP to support soft-unicast.
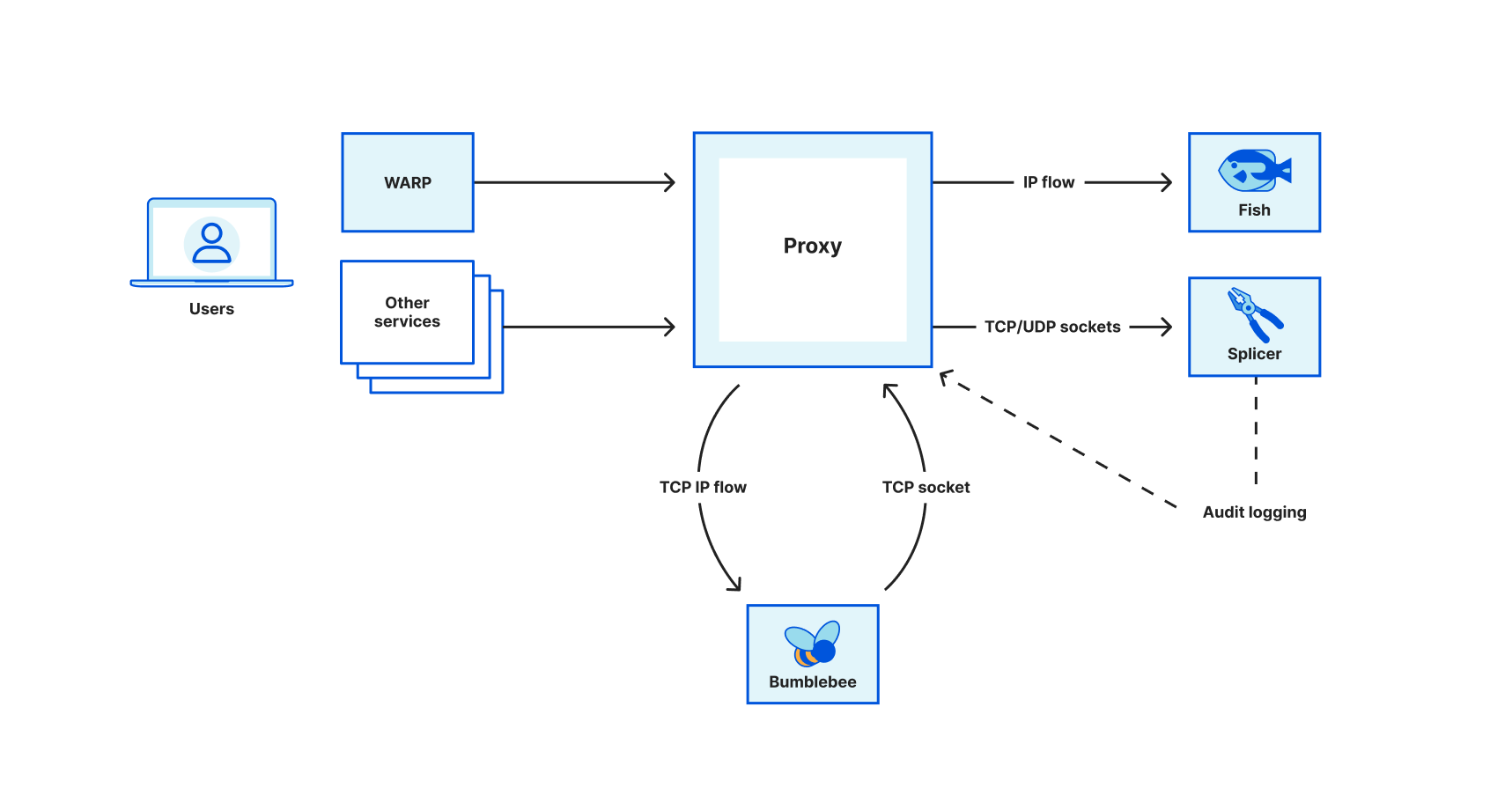
Splicer
Most transmission tunnels in our proxy forward packets without making any modifications. In other words, given two sockets, the proxy just relays the data between them: read from one socket and write to the other. This is a common pattern within Cloudflare, and we reimplement very similar functionality in separate projects. These projects often have their own tweaks for buffering, flushing, and terminating connections, but they also have to coordinate long-running proxy tasks with their process restart or upgrade handling, too.
Turning this into a service allows other applications to send a long-running proxying task to Splicer. The applications pass the two sockets to Splicer and they will not need to worry about keeping the connection alive when restart. After finishing the task, Splicer will return the two original sockets and the original metadata attached to the request, so the original application can inspect the final state of the sockets - for example using TCP_INFO - and finalize audit logging if required.
Bumblebee
Many of Cloudflare’s on-ramps are IP-based (layer 3) but most of our services operate on TCP or UDP sockets (layer 4). To handle TCP termination, we want to create a kernel TCP socket from IP packets received from the client (and we can later forward this socket and an upstream socket to Splicer to proxy data between the eyeball and origin). Bumblebee performs the upgrades by spawning a thread in an anonymous network namespace with unshare syscall, NAT-ing the IP packets, and using a tun device there to perform TCP three-way handshakes to a listener. You can find a more detailed write-up on how we upgrade an IP flows to a TCP stream here.
In short, other services just need to pass a socket carrying the IP flow, and Bumblebee will upgrade it to a TCP socket, no user-space TCP stack involved! After the socket is created, Bumblebee will return the socket to the application requesting the upgrade. Again, the proxy can restart without breaking the connection as Bumblebee pipes the IP socket while Splicer handles the TCP ones.
Fish
Fish forwards IP packets using soft-unicast IP space without upgrading them to layer 4 sockets. We previously implemented packet forwarding on shared IP space using iptables and conntrack. However, IP/port mapping management is not simple when you have many possible IPs to egress from and variable port assignments. Conntrack is highly configurable, but applying configuration through iptables rules requires careful coordination and debugging iptables execution can be challenging. Plus, relying on configuration when sending a packet through the network stack results in arcane failure modes when conntrack is unable to rewrite a packet to the exact IP or port range specified.
Fish attempts to overcome this problem by rewriting the packets and configuring conntrack using the netlink protocol. Put differently, a proxy application sends a socket containing IP packets from the client, together with the desired soft-unicast IP and port range, to Fish. Then, Fish will ensure to forward those packets to their destination. The client’s choice of IP address does not matter; Fish ensures that egressed IP packets have a unique five-tuple within the root network namespace and performs the necessary packet rewriting to maintain this isolation. Fish’s internal state is also survived across restarts.
The Unix philosophy, manifest
To sum up what we are having so far: instead of adding the functionalities directly to the proxy application, we create smaller and reusable services. It becomes possible to understand the failure cases present in a smaller system and design it to exhibit reliable behavior. Then if we can remove the subsystems of a larger system, we can apply this logic to those subsystems. By focusing on making the smaller service work correctly, we improve the whole system's reliability and development agility.
Although those three services’ business logics are different, you can notice what they do in common: receive sockets, or file descriptors, from other applications to allow them to restart. Those services can be restarted without dropping the connection too. Let’s take a look at how graceful restart and file descriptor passing work in our cases.
File descriptor passing
We use Unix Domain Sockets for interprocess communication. This is a common pattern for inter-process communication. Besides sending raw data, unix sockets also allow passing file descriptors between different processes. This is essential for our architecture as well as graceful restarts.
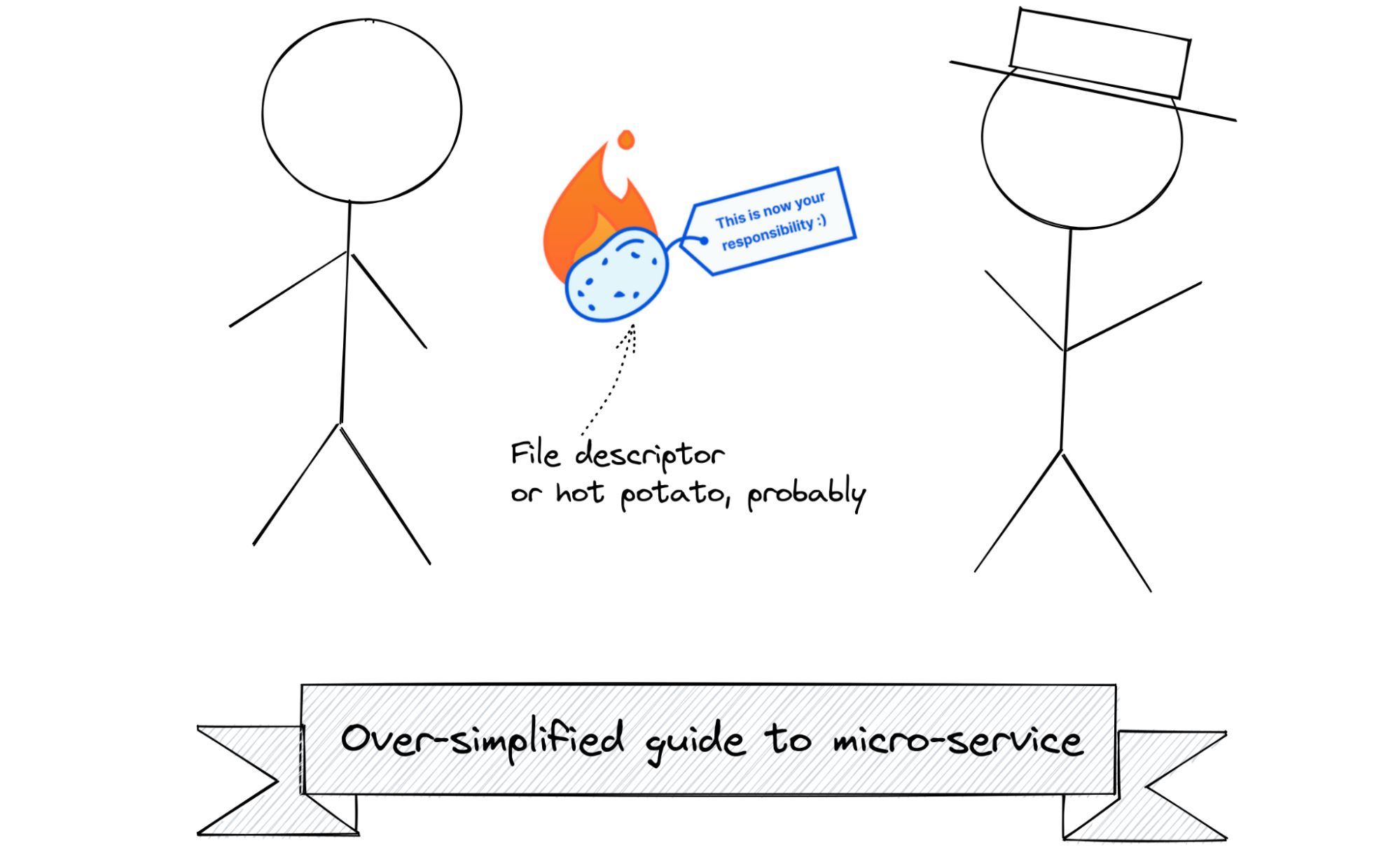
There are two main ways to transfer a file descriptor: using pid_getfd syscall or SCM_RIGHTS. The latter is the better choice for us here as the use cases gear toward the proxy application “giving” the sockets instead of the microservices “taking” them. Moreover, the first method would require special permission and a way for the proxy to signal which file descriptor to take.
Currently we have our own internal library named hot-potato to pass the file descriptors around as we use stable Rust in production. If you are fine with using nightly Rust, you may want to consider the unix_socket_ancillary_data feature. The linked blog post above about SCM_RIGHTS also explains how that can be implemented. Still, we also want to add some “interesting” details you may want to know before using your SCM_RIGHTS in production:
- There is a maximum number of file descriptors you can pass per message
The limit is defined by the constant SCM_MAX_FD in the kernel. This is set to 253 since kernel version 2.6.38 - Getting the peer credentials of a socket may be quite useful for observability in multi-tenant settings
- A SCM_RIGHTS ancillary data forms a message boundary.
- It is possible to send any file descriptors, not only sockets
We use this trick together with memfd_create to get around the maximum buffer size without implementing something like length-encoded frames. This also makes zero-copy message passing possible.
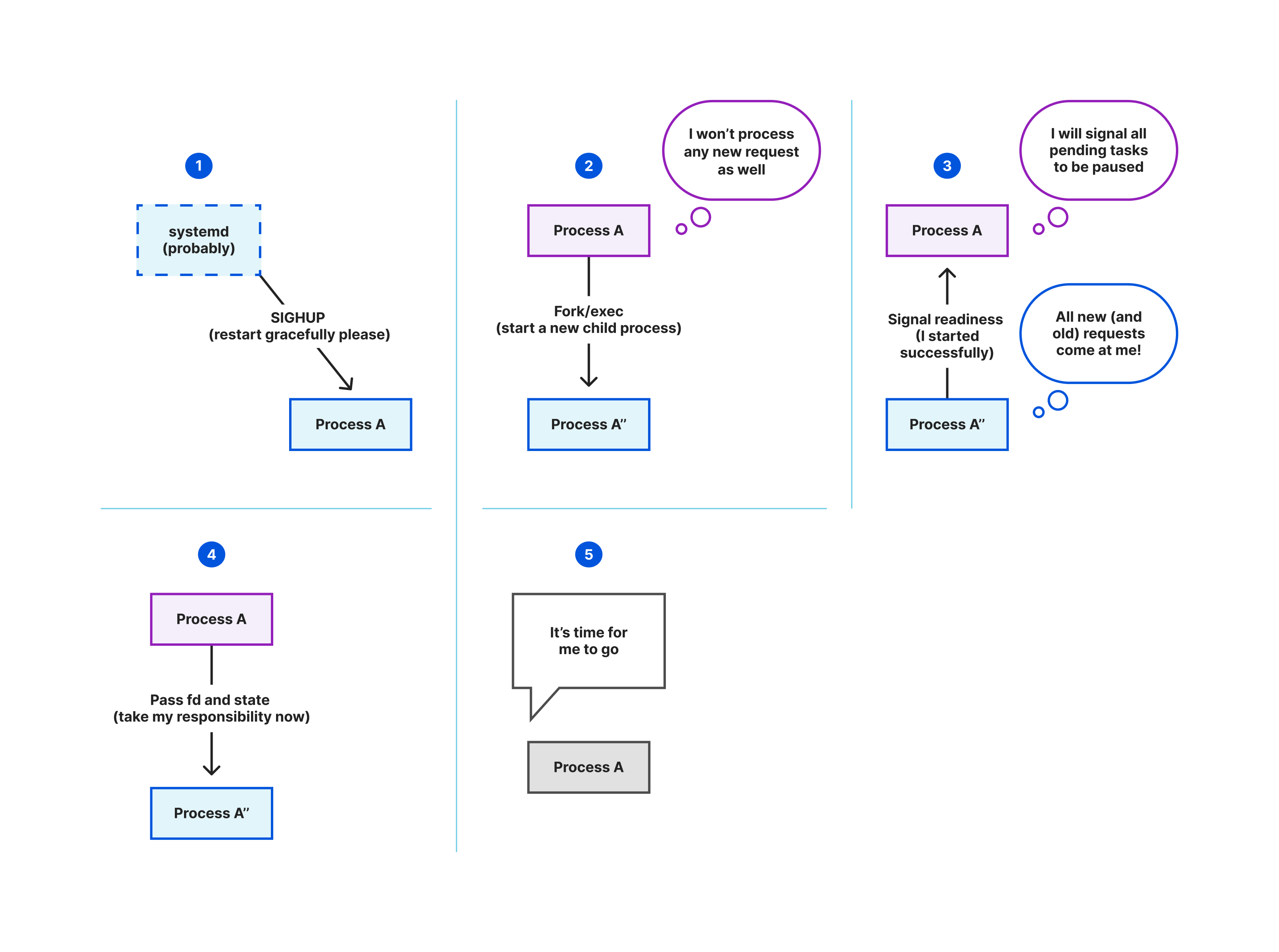
Graceful restart
We explored the general strategy for graceful restart in “Oxy: the journey of graceful restarts” blog. Let’s dive into how we leverage tokio and file descriptor passing to migrate all important states in the old process to the new one. We can terminate the old process almost instantly without leaving any connection behind.
Passing states and file descriptors
Applications like NGINX can be reloaded with no downtime. However, if there are pending requests then there will be lingering processes that handle those connections before they terminate. This is not ideal for observability. It can also cause performance degradation when the old processes start building up after consecutive restarts.
In three micro-services in this blog post, we use the state-passing concept, where the pending requests will be paused and transferred to the new process. The new process will pick up both new requests and the old ones immediately on start. This method indeed requires a higher complexity than keeping the old process running. At a high level, we have the following extra steps when the application receives an upgrade request (usually SIGHUP): pause all tasks, wait until all tasks (in groups) are paused, and send them to the new process.
WaitGroup using JoinSet
Problem statement: we dynamically spawn different concurrent tasks, and each task can spawn new child tasks. We must wait for some of them to complete before continuing.
In other words, tasks can be managed as groups. In Go, waiting for a collection of tasks to complete is a solved problem with WaitGroup. We discussed a way to implement WaitGroup in Rust using channels in a previous blog. There also exist crates like waitgroup that simply use AtomicWaker. Another approach is using JoinSet, which may make the code more readable. Considering the below example, we group the requests using a JoinSet.
let mut task_group = JoinSet::new();
loop {
// Receive the request from a listener
let Some(request) = listener.recv().await else {
println!("There is no more request");
break;
};
// Spawn a task that will process request.
// This returns immediately
task_group.spawn(process_request(request));
}
// Wait for all requests to be completed before continue
while task_group.join_next().await.is_some() {}
However, an obvious problem with this is if we receive a lot of requests then the JoinSet will need to keep the results for all of them. Let’s change the code to clean up the JoinSet as the application processes new requests, so we have lower memory pressure
loop {
tokio::select! {
biased; // This is optional
// Clean up the JoinSet as we go
// Note: checking for is_empty is important 😉
_task_result = task_group.join_next(), if !task_group.is_empty() => {}
req = listener.recv() => {
let Some(request) = req else {
println!("There is no more request");
break;
};
task_group.spawn(process_request(request));
}
}
}
while task_group.join_next().await.is_some() {}
Cancellation
We want to pass the pending requests to the new process as soon as possible once the upgrade signal is received. This requires us to pause all requests we are processing. In other terms, to be able to implement graceful restart, we need to implement graceful shutdown. The official tokio tutorial already covered how this can be achieved by using channels. Of course, we must guarantee the tasks we are pausing are cancellation-safe. The paused results will be collected into the JoinSet, and we just need to pass them to the new process using file descriptor passing.
For example, in Bumblebee, a paused state will include the environment’s file descriptors, client socket, and the socket proxying IP flow. We also need to transfer the current NAT table to the new process, which could be larger than the socket buffer. So the NAT table state is encoded into an anonymous file descriptor, and we just need to pass the file descriptor to the new process.
Conclusion
We considered how a complex proxy app can be divided into smaller components. Those components can run as new processes, allowing different life-times. Still, this type of architecture does incur additional costs: distributed tracing and inter-process communication. However, the costs are acceptable nonetheless considering the performance, maintainability, and reliability improvements. In the upcoming blog posts, we will talk about different debug tricks we learned when working with a large codebase with complex service interactions using tools like strace and eBPF.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.