正则表达式在文本分析中是一种非常强大的工具,它可以描述一个字符串,我们可以使用这个描述去匹配、搜索字符串。既然正则是对字符串的描述,那么我们可以用这个描述去匹配已知的字符串是否符合这个描述,当然也可以 2023-4-21 17:31:39 Author: Yak Project(查看原文) 阅读量:44 收藏
正则表达式在文本分析中是一种非常强大的工具,它可以描述一个字符串,我们可以使用这个描述去匹配、搜索字符串。
既然正则是对字符串的描述,那么我们可以用这个描述去匹配已知的字符串是否符合这个描述,当然也可以通过这个描述去生符合这个描述的字符串,取反就是生成不符合这个描述的字符串,也可以通过给定几组字符串的子串去找到这些子串的共同特征,然后通过正则语言表述出来,实现自动生成正则了,等等…
本文将为大家介绍如何通过正则去生成符合规则的字符串。
Part 1.正则表达式匹配原理
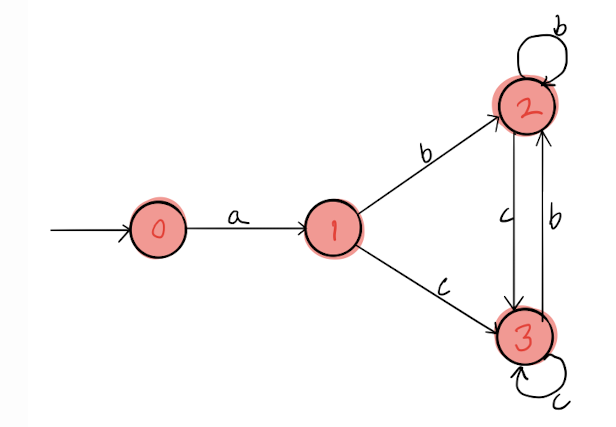
开始之前先了解下正则表达式的工作原理是什么。正则表达式符合正则文法,可以基于有限状态自动机实现,例如表达式 a(b|c)*,对应的确定性有限状态自动机(DFA)
起始状态是0,当输入字符a时状态转为1,输入b时状态变为2,输入c时状态变为3。如果输入的字符串的每一个字符输入都会转移到一个状态,就是这个字符串可以在这个自动机里跑完,那就可以匹配成功。
Part 2.regexp库的解析过程
我们以go的regexp.Match函数为例
可以看见,在Match前需要先编译,再用编译结果Match,那编译过程都做了什么呢
如图是正则编译的过程,把输入的正则表达式编译为各种Op,下面是所有Op翻译后的结果
OpNoMatch:不匹配任何字符串。OpEmptyMatch:匹配空字符串。OpLiteral:匹配指定的字符序列。OpCharClass:将匹配字符解释为范围对列表。OpAnyCharNotNL:匹配除换行符外的任何字符。OpAnyChar:匹配任何字符。OpBeginLine:匹配空字符串,仅限于行首。OpEndLine:匹配空字符串,仅限于行尾。OpBeginText:匹配空字符串,仅限于文本开头。OpEndText:匹配空字符串,仅限于文本结尾。OpWordBoundary:匹配单词边界\b。OpNoWordBoundary:匹配非单词边界\B。OpCapture:捕获子表达式,并可选择提供索引或名称。OpStar:匹配Sub[0]零个或多个次。OpPlus:匹配Sub[0]一个或多个次。OpQuest:匹配Sub[0]零个或一个次。OpRepeat:匹配Sub[0]最少出现Min次,最多出现Max次(如果Max == -1,则无限制)。OpConcat:匹配Subs的连接。OpAlternate:匹配Subs的交替。
下面是部分匹配过程中的代码,就是使用编译过程中生成的Op做匹配的
Part 3.反向生成
如果把这些Op反向解释一下不就是使用正则生成了吗,像下面这样
OpLiteral:生成指定的字符序列。OpAnyCharNotNL:生成除换行符外的任何字符。OpAnyChar:生成任何字符。
幸运的是,go的regexp库提供了regexp.syntax.Parse方法,我们可以直接拿到解析结果,而且官方库的测试案例也提供了使用示例,如图是表达式和编译后的语法对比,可以看见编译后的语法是已经帮我们处理好了层级关系的。
接下来我们只需要反向翻译一下Op就可以了。python有一个反向生成正则的库叫做 Xeger,我们可以参考下他的翻译过程,直接抄作业。
如图是Xeger实现的Op和handle的映射,上面是字符集,下面是op,例如表达式a*编译后的op是max_repeat{literal{a}},在生成时就是先生成字面量a,再max_repeat(因为这里的*是贪婪模式),再看下max_repeat对应的_handle_repeat函数定义
这里repeat的次数是随机的,上限是由_limit参数设定的。
Part 4.YAK的regen
现在YAK已经支持这种操作了(团队师傅完成的),区别于Xreg, YAK的regen库生成时会生成全部符合这个正则表达式的字符串,如果匹配规则很宽泛可能会生成巨量的数据,所以使用时需要小心。
使用案例:
还支持Fuzztag标签使用:
总结
本文介绍了如何使用正则表达式反向生成字符串,并且YAK提供了regen库,我们可以灵活运用,例如需要绕过正则[0-9a-zA-Z]的字符串,我们可以使用[^0-9a-zA-Z]生成,例如:
println(regen.Generate("[^0-9a-zA-Z]")~)
通知!通知!
Yakit最新版使用手册更新至官网啦,师傅们可点击文末阅读原文直接跳转查看,当然,直接去官网看也是可以的~
yaklang.com
另外,Yakit视频教程第二期也已更新,指路某站@yaklang
如有侵权请联系:admin#unsafe.sh