说点虚的云原生数据库、shared-nothing、算存分离… 这些概念性的东西,网上资料一大把,看完以后感觉懂了,但是尝试用自己的话复述出来时,又感觉没懂。为什么会有这种感觉呢?我觉得原因在于看 2023-4-24 08:4:10 Author: Docker中文社区(查看原文) 阅读量:105 收藏
说点虚的
云原生数据库、shared-nothing、算存分离… 这些概念性的东西,网上资料一大把,看完以后感觉懂了,但是尝试用自己的话复述出来时,又感觉没懂。
为什么会有这种感觉呢?我觉得原因在于看完了网上的资料,我知道了 what;但是很多资料并没有解释 why,所以我无法把知识转变成自己的,也就无法用自己的语言把这些概念解释一遍。只有搞清楚为什么会出现这种设计,才能够消化知识,只知道 what 的话,只能靠死记硬背才能“掌握”知识。
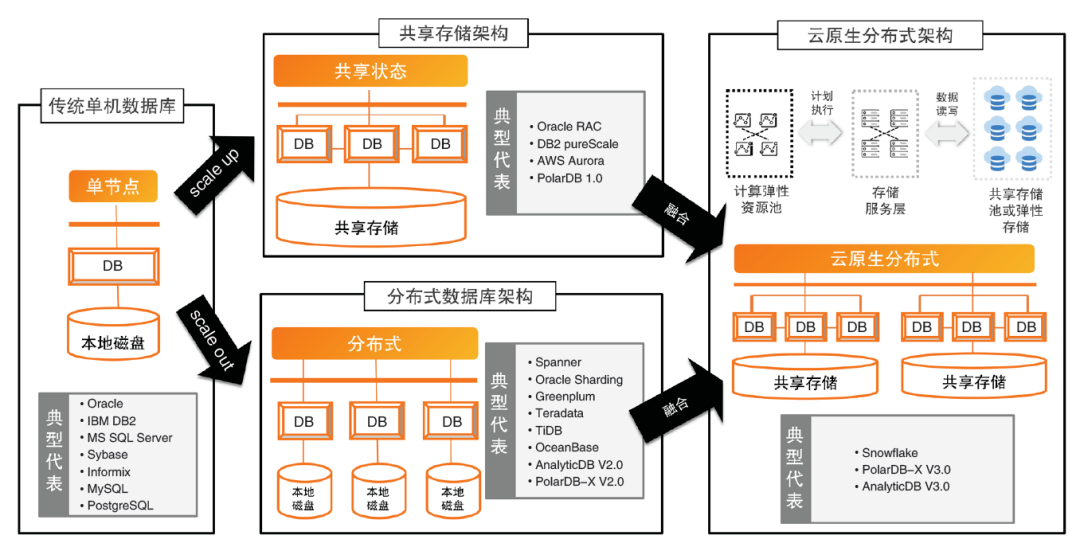
这张图来自于👉李飞飞的文章,一张图就把数据库的过去和未来说清楚了。我尝试在这张图的基础上补充自己的理解:
单机数据库
首先传统单机数据库是一种shared-everything的架构,这里的everything指的是冯·诺依曼架构中的「计算」和「存储」;而shared指的是单机数据库可以随意使用「计算」和「存储」的能力。
分布式数据库
在单机数据库面对可扩展性问题时,就需要通过加机器的方式解决,这时出现了两种解决方案:Scale up 和 Scale out。
这里 Scale up 并不是单机 scale up,而是从宏观角度来看,在资源层面的 scale up,也就是资源池化,比如存储池化(采用 SAN 技术的块存储、NAS 分布式文件存储、S3 对象存储)。这时从整个数据库服务的宏观角度来看,数据库是shared-storage的,而各个实例的内存和 cpu 资源是各自独立的。
scale out 则是各个数据库实例独立运行,实例之间通过 raft/paxos 等共识算法进行数据同步,这就是一种shared-nothing架构,也就是从宏观角度看,数据库服务没有任何存储或计算资源的池化,完全依赖于应用层,也就是多个 DB 实例,利用机器的本地资源,去做高可用和强一致,实现分布式事务。
云原生数据库
云原生数据库 = 分布式数据库(scale out) + 资源池化(scale up)。
云原生 = 云 + 原生。「云」就代表着 IaaS 资源池化,「原生」意味着应用(PaaS、SaaS)天然就是针对这种池化的特性进行设计的。
现在的分布式数据库大多是shared-nothing的,例如 tidb 和 ob,使用了本地盘。一旦使用本地盘,就意味着无法上云,因为云的特性就是资源池化,所以要上云,就要使用公有云厂商提供的 EBS、S3 等云盘。而云盘的性能没有本地盘好,这就要求应用层,也就是 DB 这一层,是面向公有云的基础服务进行设计的。这就是云原生的数据库,即在数据库设计的时候,就考虑各种资源是在云上,以池化的方式提供。这种方式意味着shared-nothing和shared-everything 的结合,宏观上看,是shared-everything的(未来 cpu 和内存也会池化),从微观上看,又是分布式的shared-nothing。
这是一种真正的算存分离:在单机部署情况下,通信就是计算通过 Memory Bus、IO Bus 和内存、存储通信。但在集群部署的情况下,计算和存储的通信就是网络。在硬件还不够牛逼的情况下,单机上的存储访问速度要快于集群,但是在硬件,特别是在摩尔定律失效(单机 cpu 的性能很难再突破)、存储和网络的硬件越来越牛逼的情况下,我觉得资源的池化一定是未来,数据库上云一定是未来。
搞点实际的
分布式数据库上 k8s 会遇到哪些问题呢?
由于分布式数据库在设计上就不是云原生的,一般比较适合
on-primises部署,而不是部署到云上。由于使用本地盘,分布式数据库不适合通过 k8s 进行部署。但是,随着基础设施硬件的不断发展,池化后的资源不会再成为性能瓶颈,所以云原生数据库一定是数据库的未来,现在的分布式数据库也在往云原生数据库的方向演进,到那一天,有状态应用就可以在 k8s 上发挥它最大的威力。
本地盘
statefulset 对本地盘的支持并不好,这就导致为了支持本地盘搞出来了各种增强型的 statefulset。 本地盘使用的是静态 PV,不支持 scale up,灵活性差。 本地盘要做 IOPS 的隔离并不容易,且 cgroup v1 的资源隔离机制有缺陷。 要保证跨 AZ 高可用,有时可能要做节点迁移。本地盘在做节点迁移时,非常难受,如果用网盘,则只需要 umount 和 mount 两个动作。 没法利用 k8s 的自我修复能力。比如节点挂了,你可以通过起一个新的 Pod 的方式进行修复。但是如果用了本地盘,这个 Pod 必须调度到原节点。
网盘
在公有云上,使用网盘最大的问题第一是延迟抖动;第二是性能比本地盘要差很多。如何在软件层面克服这种问题是云原生数据库要攻克的难关。
现有的云原生数据库(比如 snowflake)一般都是面向 OLAP 的数据仓库,原因在于数据仓库对于吞吐的要求其实是更高的,对于延迟并不是那么在意,一个 query 可能跑五秒出结果就行了,不用要求五毫秒之内给出结果,特别是对于一些 Point Lookup 这种场景来说,Shared Nothing 的 database 可能只需要从客户端的一次 rpc,但是对于计算与存储分离的架构,中间无论如何要走两次网络,这是一个核心的问题。Aurora 是一个计算存储分离架构,但它是一个单机数据库,Spanner 是一个纯分布式的数据库,纯 Shared Nothing 的架构并没有利用到云基础设施提供的一些优势。
原文链接:https://cvvz.github.io/post/the-difficulty-of-distributed-db-on-cloud/
本文转载自:「云原生实验室」,原文:https://tinyurl.com/35s923f6,版权归原作者所有。
《Docker中Image、Container与Volume的迁移》
免责声明:本文内容来源于网络,所载内容仅供参考。转载仅为学习和交流之目的,如无意中侵犯您的合法权益,请及时联系Docker中文社区!
如有侵权请联系:admin#unsafe.sh