0×01 前言
关于企业安全威胁数据收集分析是一个系统工程,每天在我们网络环境中,都会产生各种形式的威胁数据。为了网络安全防护,会收集各种流量日志、审计日志、报警日志、上网设备日志,安防设备日志等等。很多公司都有自己的数据处理流程,大数据管理工具。我们根据过去的实践经验,总结出了一个威胁数据处理模型,因为引用增长黑客的模型的命名方式,我们称这种模式为:沙漏式威胁信息处理模型。
网络环境下构建的安全发现设备或服务,其主要的作用是,增加我方的防御厚度,减缓攻方的攻速,能通过足够厚的防御措施,在攻方攻破之前发现威胁,残血坚持到最后等回血,并且提醒友方人员的服务不要轻易送人头。
0×02 沙漏威胁处理模型

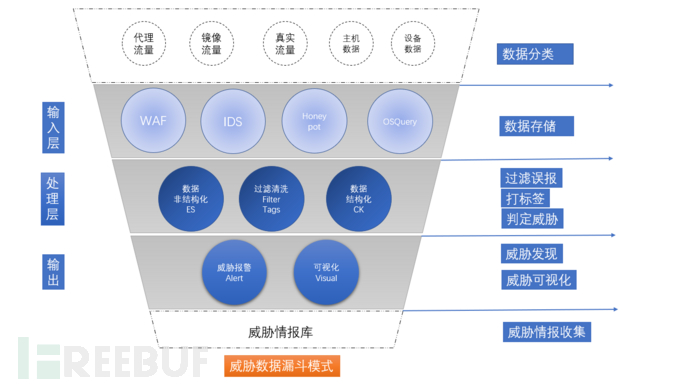
图1.威胁分析沙漏模型
威胁数据组织:
我们参考软件设计模式、神经网络层、增长黑客模型的归纳方法,归纳出一个威胁数据处理模型。通过这个模型,可以看出数据收集、处理、展现基本流程脉络,根据自己的实际需求情况,精简模型或是扩展模型,来够建我们的防御系统。
下面我们根据实际情况,概况出一个基本的模型,由若干层和多种元素构成。一个综合威胁信息聚合模型,像一个软件系统服务一样, 有输入层、处理层、输出层。输入层的数据源来自不同的分类数据类型:代理流量、镜像流量、真实流量、主机数据、设备数据、扫描数据等等。
通过收集不同级别的威胁信息数据碎片,根据威胁信息碎片类型分类、价值权重级别、数据的属性。将低信息量的威胁信息数据碎片,用信息化手段升级。将不同属性的数据碎片组合,提升威胁发现能力。
代理流量:代理是一种概括的统称,很多企业都有网关设备,7层或4层,这种设备服务会产生流相关量日志数据,并具有准入认证的功能。
镜像流量:镜像流量比较常见,通过流量镜像发给威胁分析设备与分析服务,设备系统反馈威胁检测报警。
真实流量:Nginx日志, 蜜罐日志等真实服务的流量数据产生的落地日志信息。
主机数据: 无论是探针APM、Zabbix Agent、OSQuery、HIDS都会产生与主机相关的指标数据, 这些数据异常阀值同样能起动预示报警的作用。
设备数据:重要敏感设备产生的数据, 这数据有自己的异常数据监控。
扫描数据:主动扫描采集的数据:端口、服务扫描等。
层次划分:
第一层:输入层(数据集中):在输入层出现了以上提到的各种服务、设备产生的数据。这一层关键点是数据的收集,如果没有数据的收集,后续的横向和垂直的分析工作都无数据可分析处理。
第二层:处理层(数据加工):数据只是收集而不处理,只是一种数据的堆砌。在数据处理层做了几件事情,
1.比如数据的快速非格式化。(切割)
2.后期数据聚类统计提纯的结构化。(整形)
3.数据清洗过滤与打标签。(加工)
威胁情报数据可以有多种形态,基于流数据形式的信息,比较适合使用管道处理模式,在管道处理模式,根据不同的信息数据输入,在处理槽中,采用部署不同的数据处理技能单元。
装备、技能:
| 输入 | 处理 | 输出 |
|---|
| WAF | IDS | 蜜罐 | 扫描 | HIDS | 采集 | 整型 | 切割 | 过滤 | 报警 | 报警 | 可视化 |
|---|
第三层:输出层(威胁发现):对数据进行去伪存真后,根据被打过的标签进行策略分析落地,最后根据策略分析产出威胁信息数据。根据安全规则进行报警信息推送。对加工好的威胁数据,进行统计展示给用户。
为什么采用漏斗的方式表达这种模型,因为威胁情报,去误报的过程,整体就是过滤信息的过程,威胁信息由多变少的,逐渐的减少误报。最后将过滤后的威胁情报进行汇总,积累成区域型威胁情报库,不断的更新迭代。
0×03 安全角色分工
安全运维人员当面对如此之多的日志数据时,如何组织这些数据,在这些数据当中发现有价值的信息,是一件很多挑战的事情,不同的人在整个威胁发现系统构建的过程中担当不同的角色。
每一种职业种类,都有自己特长的和弱点,在某些场景下工作,有人适合在对抗路,有人适合在后期发力。各种职业人对威胁信息碎片组合不一样,不同威胁碎片信息的属性,不同的职业有不同的解读和运用。
安全运维:
对于安全维护相关人员来说,最喜欢的体验是,将每天产生的原始威胁数据情报当中的可疑信息,选最重要与危害最大的问题进行优先报警,并找到相关责任人推送报警信息。安全运维人员,需要不断的迭代制作安全策略与报警规则。
数据运维:
将各种可见的威胁信息日志,进行整理集中,运用各种大数据工具,将数据进行合理的存储,保证数据完整性、有效性。
安全开发:
提供操作界面,都所有可用的日志数据,提供查询界面,查询接口,完成信息查询交互。
大数据算法:
AI分析是安全分析的大脑。安全威胁发的方式方法有很多的种类,比如DNS解析相关、僵尸网络相关、 WEB相关的,比如:XSS反射、SQL注入等等。
面一种同一种威胁事件数据,有多种检测方法,比如针对 SQL注意和XSS注入这种威胁的发现方式就有:
1.基于正则匹配。
2.基于SQL Injection模式配对。
3.基于自然语言处理算法。
4.基于神经网络算法。
同样是神经网络,使用的具体算法不同,样本不同,效果也不同, 比如:LSTM、MLP等。
有开源的检测软件,有商业软件都具备威胁分析报警的功能,可以作为平时网络环境中检测威胁事件的手段。商业软件的威胁分析过程是黑盒完成,用户看不到具体威胁实现的方法策略,属于产品核心的一部分。并且,无论是商业软件,还是开源软件都存在误报的情况的,还有漏报的情况。针对这种情况,在实践过程,我们采用相应方法处理。
为了强化某些防御技能,加厚防御,有时需要叠加防御装备,而叠加的防御装备又不能千篇一律,可以根据不同的攻击类型,在增加防御的同时,有减速的攻击防御手段,有迷惑眩晕的对方的防御手段,有终结阻断的对方攻击的防御手段,有抵抗对方挖矿控制快速脱离受控的手段,等等。
过滤:交叉检查(垂直)
叠加检测分析装备与服务,提取头部信息,是为了尽量的消除误报。
举例来说,我们能通过流量镜像的方式,将网络中的一部分流量,导入某个威胁分析系统,分析系统会为我们产生各种类型的报警信息,但是,报警信息是会存在误报的。我们就可以用冗余威胁手段多次,对同一个威胁信息,进行威胁重叠判断,降低误报。
比如,我们可以对于基于正则模式匹配XSS分析结果,再用自然语言处理的方式进行确认,也可以对基于自然语言处理的报警,通过神经网络算法,或是开源威胁分析库的方式多次分析,通过交叉检查的方式,进行误报过滤,交叉检查是对威胁信息多重检查,叠加确认的过程。
因为每种威胁分析都可能会产生误报,产生误报叠加。这时候我们更应该关注的是,每种分析方法的头部威胁分析结果。
关联:关联检查(横向)
网络环境中不只有一种监测手段存在,我们可以从不同的维度进行,对资产进行安全监控保护:
叠加堆砌威胁分析设备与服务,是为了提高发现的威胁准确率,减少漏报。有时会用多种不同的装备在同一区域叠加使用,强化某一效果,A装备效果不够快,可以用B装备。A看不见的,B可以看见。A不便于部署的,B可以便于部署。
举例来说, 相同网络环境:
第1种:流量监听,我们可以会把相关某一区域的网络流量,镜像给网络检查分析模块(开源商业),通过流量分析,分析出针对某台服务操作的可疑流量数据,及威胁报警。
第2种:部署蜜罐,我们会在重要服务器所在环境部署蜜罐系统,通过蜜罐检查当前网段的可疑行为。
第3种:加入审计监听,我们可以对服务器安装类似OSQuery这种主机审计组件,分析主机配置变化的可疑行为。
第4种:主动扫描,我们可以定时对服务器发起主动扫描,服务扫描和端口扫描,通过扫描返回结果,建立漏洞库等相关情况,判断主机是否异常。
第5种:访问控制,我们可以建立服务主机的访问控制,生成通信聚类的白名单与黑名单,分析异常访问行为。
第6种:威胁情报库,我们可以将访问服务的IP与威胁情报库进行对比,发现异常访问行为。
横向的威胁检查方法可能还会很多,这里只是举例一些。
他们都有一个公同之处:这些检测分析服务都会产生,围绕同一主体的威胁报警信息,所以对于同一IP主体,可以通过各种检测手段,垂直确认后,再横向与其它分析模块的威胁数据进行比较。
威胁的确认,误报的情况是可能发生的,但是如果多种检测方式,都出现了威胁事件的发生,就降低了误报的可能性,具体的控制细节需要实施者具体控制的。
比如:一台机器,同时有扫描行为,还访问敏感端口,还触碰蜜罐,服务负载情况在异常时间发生异常变化,这一系列的操作,多个威胁事件同时指向一个主体,说明服务可能真的出现问题了。
如果用各种装备来强化防御厚度,并且可灵活上下线, 可以终结控制,可以阻断访问,效果更佳。
0×04 实现工具技术栈
图2.威胁分析沙漏模型(技术栈)
如果有多种检查手段,我们一定有多种威胁情报的,从技术工具层面,我们如果管理这些数据,如何挖掘、利用、驱动这些数据是一个问题。
今天的开源社区变的异常的强大,可以用各种开源软件,构建我们的安全检测系统,大家使用有类似的技术栈、像ELK、Hadoop、Spark这种工具都非常的常见,大家使用的技术工具手段都非常常见。
实现技术:技术属于技能属性,不同职业人有着自己领域专属的技能元素,人是技术技能的一种载体。
实现工具:工具是构建服务的武器,武器有不同的属性。
威胁发现系统是一个渐进发展的过程,在时间线上,根据规模和发展的状况不同,调用合适工具武器来达到自己夺标的目的,规模小的时候,发展初期,可以使用一般的统计工具就可以, ES单结点,Mysql数据,随着规模和时间的发展, 适应大的数据量,就可以更重型的武器来解决,更复杂的需求。
ES单结点无法满足就使用集群,一个集群不够,使用多个集群。 MySQL不够就用ClickHouse。
系统都是从小到大,不断迭代的过程,数据也从单机到集群,从一个集群到多个集群。检测系统、设备、日志格式都在不断的积累增多,越变越复杂。但是基础模式越来越清晰。
我们从实现的技术栈的角度分析具体使用过技术手段。
第一层.输入层:对于数据输入收集阶段,各种各样的数据收集手段都能利用上。filebeat、nxlog、logstash、syslog等,各种能便捷取得数据的手段都可以用,根据不同的平台。
第二层.处理层:数据的处理之前是要对数据进行存储的,不然也没法分析数据。安全大数据中很重要的一点是数据缓存,解决输入数据量过大,处理不过来的问题。ElasticSearch是现在最行的一种数据存储方案之一,我们也不例外的使用的ES保存数据。
用ES一个很大的好处是,我们不用想使用关系型数据库时先创建表结构,可快速想报警数据收集。对安全威胁数据来说,ES前期收集数据更快捷。高危的报警数据,理论上应该和交通数据不一样,那么巨大的并发量,所以一般的ES就可以,另外ES本身可以扩展吞吐量。
我们对大量的日志数据驱动,还是比较担心的,所以我们用了ClickHouse。ClickHouse相对于其它的大数据工具,上手更快,更轻量,但是效果速度确实相当的好。我们可以在Clickhouse对威胁进行打标签。如果数据的级别没有达到这个量,可以使用Mysql。其实ES同样可以实现索引的SQL查询。
第三层.输出层: 数据准备就位以后,可以用各种手段分析、展示、报警数据,可能根据偏向技术栈,使用开源的解决方案,比如商业BI分析工具superset等。
沙漏模式就是将数据由多变少,人肉一天处理几万报警,是处理不过来的。
0×05 流模式威胁处理模型
图3.威胁分析处理流模型
威胁数据的湖泊海洋都是由一条条的数据河流汇聚而成的。在早期“数据流”模式,收集数据操作起来灵活方便。因为数据,无论是接入,还是存储都不能一步到位的,采用增量的流模式数据处理比较适合。
各种信息数据,就像小河汇入湖泊一样,积少成多,最后形成更大数据动势,对于新的威胁检查手段加入,灵活的新加入一条威胁信息数据流,流入到我们的数据池子中就好。
使用ES收集数据的几个好处,如果结构化数据库相关于“定长表”来说, ES的储存是一种“变长表”,数据的“字段”可以灵活的增加或是减少。当输入段的数据结构发生变化时,数据结构不用频繁变更字段的定义,不用频繁的修改表结构。利用这种灵活性,可以在这个阶段对数据进行整形处理,数据的维护成本会降低。
采用 ClickHouse与MySQL数据库是为了结构化查询,能用SQL解决的问题,其实不用再多写很多的脚本,可减少脚本编写量,SQL本身可以当成很强大的DSL使用,对于主机审计应用OSQuery来说,支持SQL审计也是一种提高审计效率的方法。
0×06 威胁数据处理过滤模式(PULL、PUSH)
图4.传统威胁处理模型A
面对各种分类的海量数据,如何进行数据处理?
方法一个个针对性的处理。从历史发展迭代出来,基本可以归类的模式有2种,实际的威胁分析应用,本质上就是两大操作:
1.单数据流的威胁垂直多重威胁判定确认。
2.多分析模块间的威胁数据的横向比较关联。
A/B模式数据采集与威胁分析过程
1.PULL模式:分析服务主动拉取各威胁分析模块的威胁报警信息数据,集中监听模式分析。需要把各种报警,分表异结构存储。(多表异构)
2.PUSH模式:各威胁过滤模块,针对不同的报警进行垂直过滤后,将过滤后的数据
按同样的结构推送到,集中的威胁数据表中。(单表同构)
图5.传统威胁处理模型B
实际情况是, 威胁分析的模式这两种情况是并存的。
随着数据的集中处理工作的演进, 这种两种模,最后混合成到了一起,只是不同的场景运用了不同有的分析模式。
A/B模式的优缺点对比
PULL处理模式:
优点:快速审计分析,PULL模式最快,不同分析模块间的威胁数据互相不干扰,处理异构数据,操作很多关联数据,但是对单威胁数据流审计,没有那些关联数据操作。
缺点:数据不集中,相对不利于统计,要进行各种SQL和脚本的关联。
PUSH处理模式:
优点:如果单Stream数据流过滤之后,多准备一份数据处理,把报警威胁信息过滤后,本地存一份,在集中表中再存储一份同构数据。之后统计威胁关联,只操作一份数据就可以了,减少了关联数据的多次操作。
缺点:威胁数据过于耦合。
0×07 碰撞表:威胁检测模式
图6.威胁分析碰撞表模型
如果我们采用了PUSH模式,将各种数据收集,我们就可以对不同标签来源数据进行整合。在威胁数据被格式化之前,我们都是针对不同的威胁数据进行了一定程度的垂直过滤。然后把可能是真的威胁,放入我们的中心威胁情报表结构:
为了便于记忆,叫威胁比对模式为:碰撞表。
所谓碰撞表,就是能过建立一个统一属性结构的威胁报警二维关系表,将不同设备和服务的报警数据集中存储,根据威胁情报在表中,重复次数的多少,威胁等级的高低,综合累计威胁事件的多寡,来判断威胁的严重性。
简单说,同一个IP有多个威胁事件发生的越多,并且情报源来自不同服务和设备,威胁越大。
PULL的模式是对数据进行关联, 通 过脚本读取结构数据关联,通过表关联。
而在PUSH处理模式下生成的集中碰撞表,是按威胁共通属性进行威胁信息集中的,无论是什么类型的威胁那都是威胁,区别在于威胁级别和威胁分析有来源不一样,如果我们在碰撞表中,发现同一个IP多次出现,来自不同的威胁分析模块,而且威胁的级别还很高。各种威胁事件发生都这个IP相关,就需要关注一下这个IP。
我们对不同的威胁级别打分,并对同一IP累计分数,最后得出一个分数, 最后根据得分的高低,匹配不同的处理级别,报警级别。
攻击者的情报,我们可以在积累的内外部威胁情报中, 寻找回溯历史数据。被攻击者的情报, 我们可以在CMDB资产系统中,找到资产对应的责任人。将爆破表中的威胁情报,进行分类、统计、可视化给安全运维人员做报警提示。
以上就是举例说明,威胁信息能过沙漏威胁处理模型,进行威胁数据信息处理的一种策略举例。
0×08 总结
不同规模的环境中:
输入层:输入源的收集数据信息的多寡,数据量大小。
处理层:对数据分析处理逻辑复杂程度。
输出层:信息提示的多样性。综合起来决定的防护系统防护能力和构建成本。
过去我们在运用ES和ClickHouse大数据工具的实践中,迭代演进,总结出了这种沙漏式的威胁处理模型,然后摸索出了一些共通性的内容,这篇没有过多涉及到具体的代码和工具使用方法。
*本文原创作者:糖果L5Q,本文属FreeBuf原创奖励计划,未经许可禁止转载
如有侵权请联系:admin#unsafe.sh