To find out why our mascot for this release has a pitchfork and more on nerdy naming, read below 2023-5-3 23:33:7 Author: binary.ninja(查看原文) 阅读量:38 收藏
To find out why our mascot for this release has a pitchfork and more on nerdy naming, read below the fold. For the summary of Braize’s (3.4) major new features (including one surprise feature that appeared mid-roadmap), here’s the highlights:
- Inherited Types (C++ Support)
- Automatic Outlining
- Sparse Switch Recovery
- Import from BNDB
- Enterprise Improvements
- Debugger Improvements
- Experimental Features
- Many More
You’ll notice the theme of this release has been major improvements in decompilation, we’re really excited with the quality of improvements for the first three major features described above and they’re joined by several other important improvements as well.
So why is the mascot for this release Binjy with a pitchfork? And what is Braize anyway? In case you missed our last announcement, we’ve begun code-naming releases after Sci-Fi/Fantasy planets and in this case Braize is one of the lesser known planets in Brandon Sanderson’s Cosmere, but despite its reputation as a prison/hellscape planet in that universe, as huge nerds, we couldn’t resist including it early in our naming scheme. In this case, super-powered heroes were released from torment there, just like 3.4 has been released into the world with some super powers of its own! It’s also fitting that “C” is Coruscant, with tomorrow being May the 4th! Feel free to send us your suggestions for “E” and beyond.
Major Changes
While major releases get all the press, even our point releases include a huge amount of changes. The first three can produce significantly better decompilation results across a variety of binaries and platforms.
Inherited Types
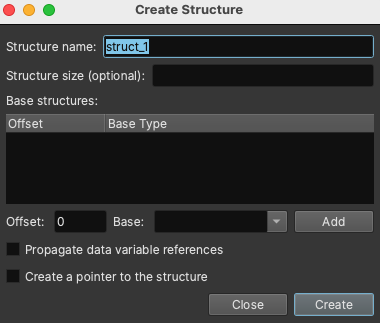
It will take more than one new feature to solve C++ reverse engineering, but one of the biggest obstacles has been resolved with this latest feature: the core type system now supports inherited types. So what does that mean? For starters, the UIs and APIs around creating structures have changed. Now when you use s to create a structure in linear view or the type sidebar, you’ll see many new options:
The updated type system now lets you assign Base Structures, whose members will be inherited by your structure. You can avoid having to create duplicate members for every class in a hierarchy, and cross references will be propagated up the inheritance chain. Base Structures can also be located at an offset, supporting structures with multiple inherited bases.
For virtual function table-like classes, there is now the ability to propagate data variable references to the structure members. Looking at the cross references to a structure member will then include any annotated data variables using that structure. Simply put, if you mark up virtual tables, you can follow their functions from where they are used to what values they could have.
What really matters is what this allows you to do. Consider the following simple example:
struct A __packed
{
struct vtable_for_A* vtable;
int32_t x;
};
struct __base(A, 0) B
{
struct vtable_for_B* vtable;
__inherited int32_t A::x;
int32_t y;
};
struct __base(B, 0) C
{
struct vtable_for_C* vtable;
__inherited int32_t A::x;
__inherited int32_t B::y;
int32_t z;
};
You can create these types in the above UI, or you can use the notation shown there as we’ve extended the clang type parser to include the __inherited keyword.
Notice that the virtual tables support inheritance as well!
struct __data_var_refs __ptr_offset(0x10) vtable_for_A __packed
{
void* field_0;
void* typeinfo;
int32_t (* sum)(struct A* this);
};
struct __base(vtable_for_A, 0) __data_var_refs __ptr_offset(0x10) vtable_for_B
{
__inherited void* vtable_for_A::field_0;
__inherited void* vtable_for_A::typeinfo;
__inherited int32_t (* vtable_for_A::sum)(struct A* this);
};
struct __base(vtable_for_B, 0) __data_var_refs __ptr_offset(0x10) vtable_for_C
{
__inherited void* vtable_for_A::field_0;
__inherited void* vtable_for_A::typeinfo;
void (* sum)(struct A* this);
};
The beauty of this is that, when the types are applied, you get cross-references across the entire binary for not only the base class, but all the children as well. Check out the cross references for A’s virtual table versus B’s virtual table in the following sample file:
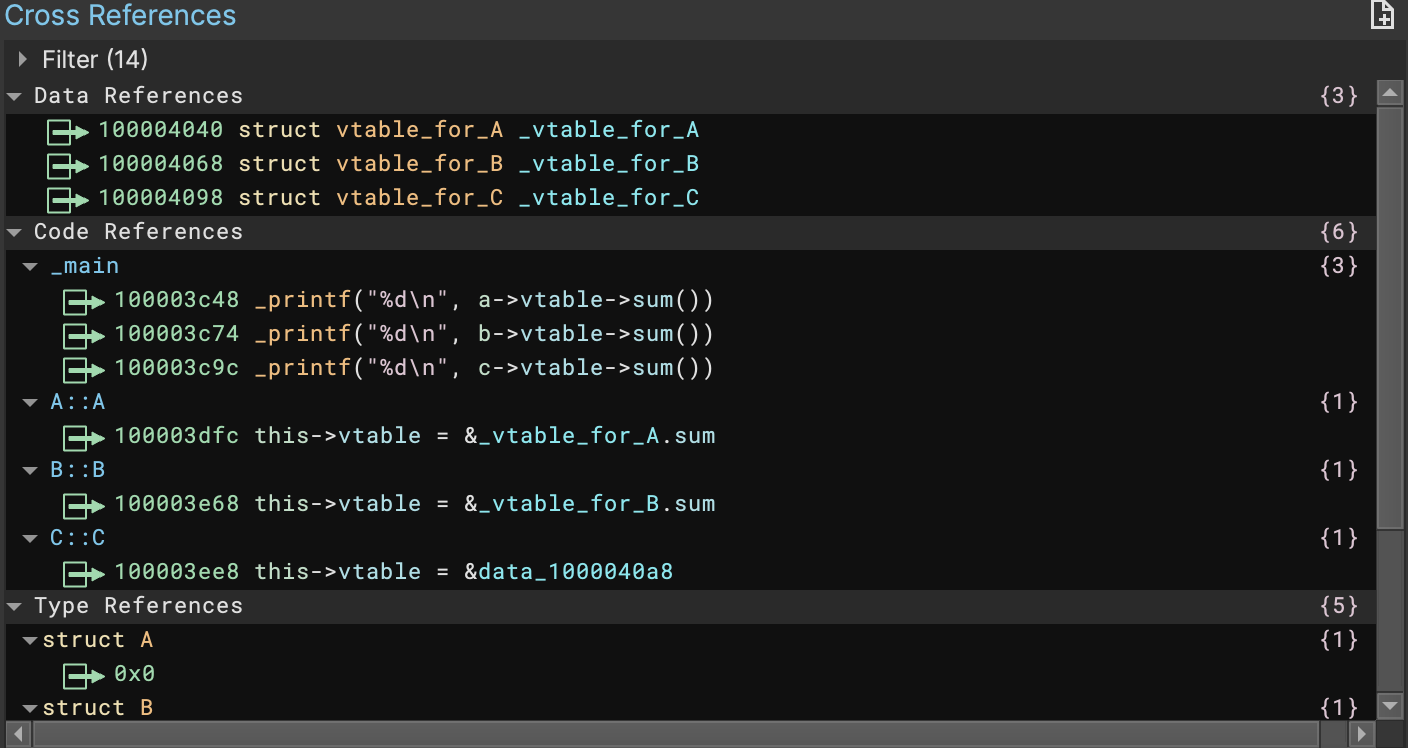
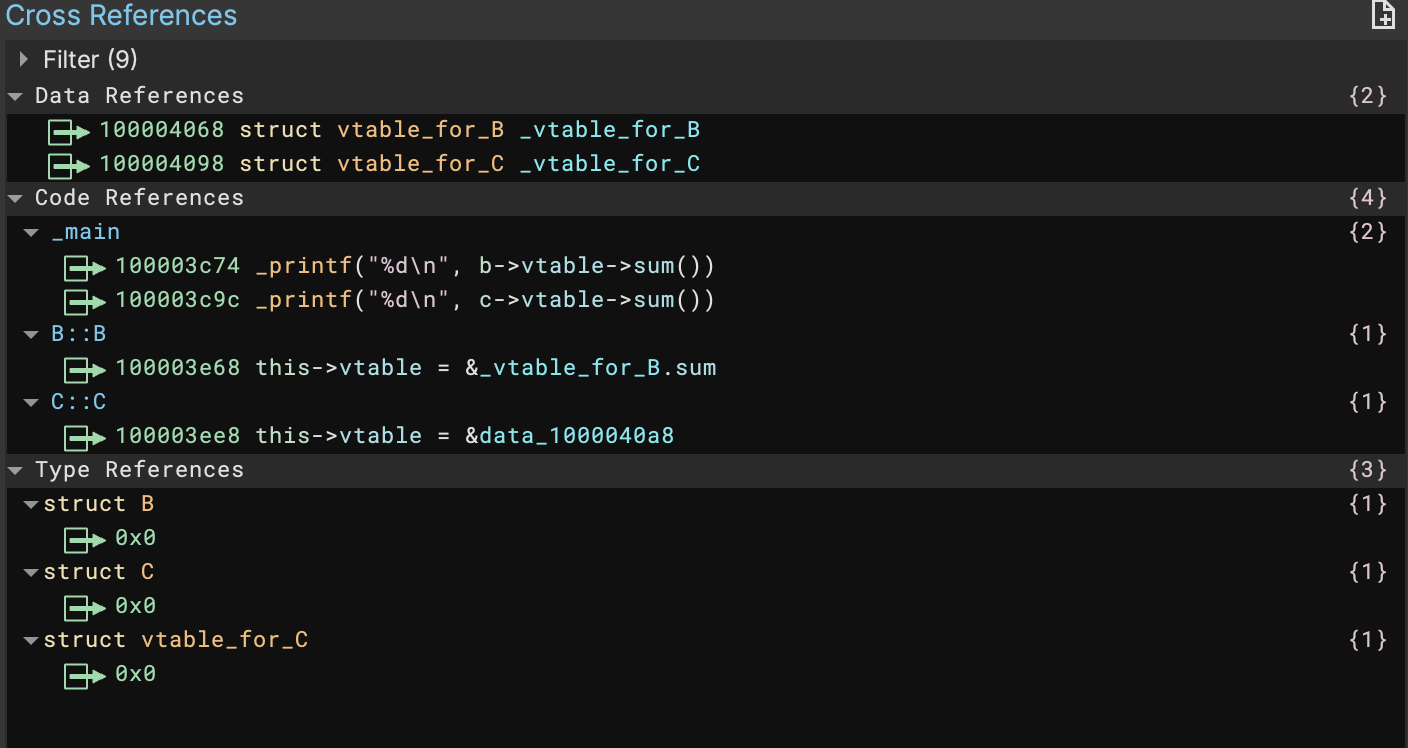
All this combines to make a very powerful type system for object oriented languages like C++. For more details and an even more complicated example showing multiple inheritance, check out the C++ Types help document.
One thing to keep in mind is that compilers don’t always follow the layout you expect! While debug info formats like PDBs contain the true data, your types may not always copy/paste directly from source code, so creating and applying the appropriate types may require some manual effort (for now!).
Automatic Outlining
Yes, we’ve talked about it before, but not only is the feature now enabled by default, it has had some important upgrades! To recap, this feature identifies instances where either a function call like strcpy might have been inlined and turns it back into an outlined function, or even just identifies situations where memory setting operations might have been unrolled (think initializing a stack array or structure to zero) and replaces them with a more convenient to a memset operation.
You can tell the feature is enabled by looking in your analyzed binary view for a .synthetic_builtins section:

This fake section is created and appended to your existing memory layout, as a place to store function prototypes for these built in functions. Then we re-write analysis to point to those built-in methods, replacing anywhere they are inlined. This makes it easy to select one of the function prototypes to identify all the places in the binary where it was applied via cross references:
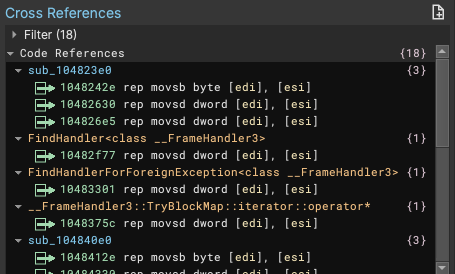
In this new release, outlining can identify stack and global memory being used for similar patterns. It avoids some false positives by following type alignment constraints, adds supports for UTF-16 wide strings, and will also outline memcpy and memset for some well-known native architecture instructions such as rep stos* and rep movs*.
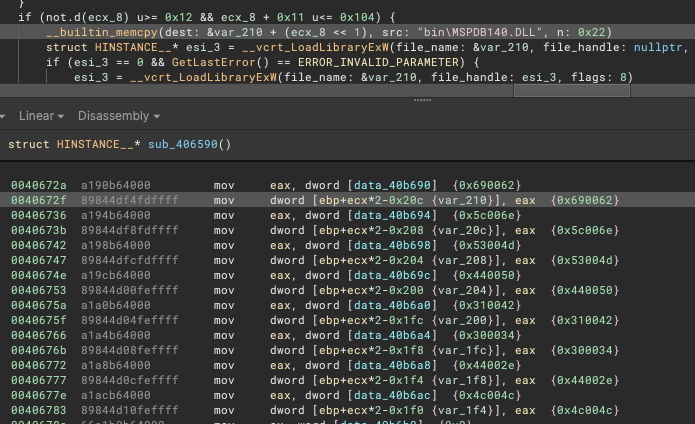
This new feature can dramatically improve decompilation. As you create variables, the analysis will create memset calls based on your types, automatically converting sequences of assignments to more concise outlined calls. It may happen in some unexpected cases, but properly defining your types should improve results.
Sparse Switch Recovery
Next on the theme of decompiler improvements, we’ve enhanced our switch statement recovery to make it much more robust in the face non-contiguous values! In practice, that means you’ll see nested groups of if-statements recovered as switch statements:
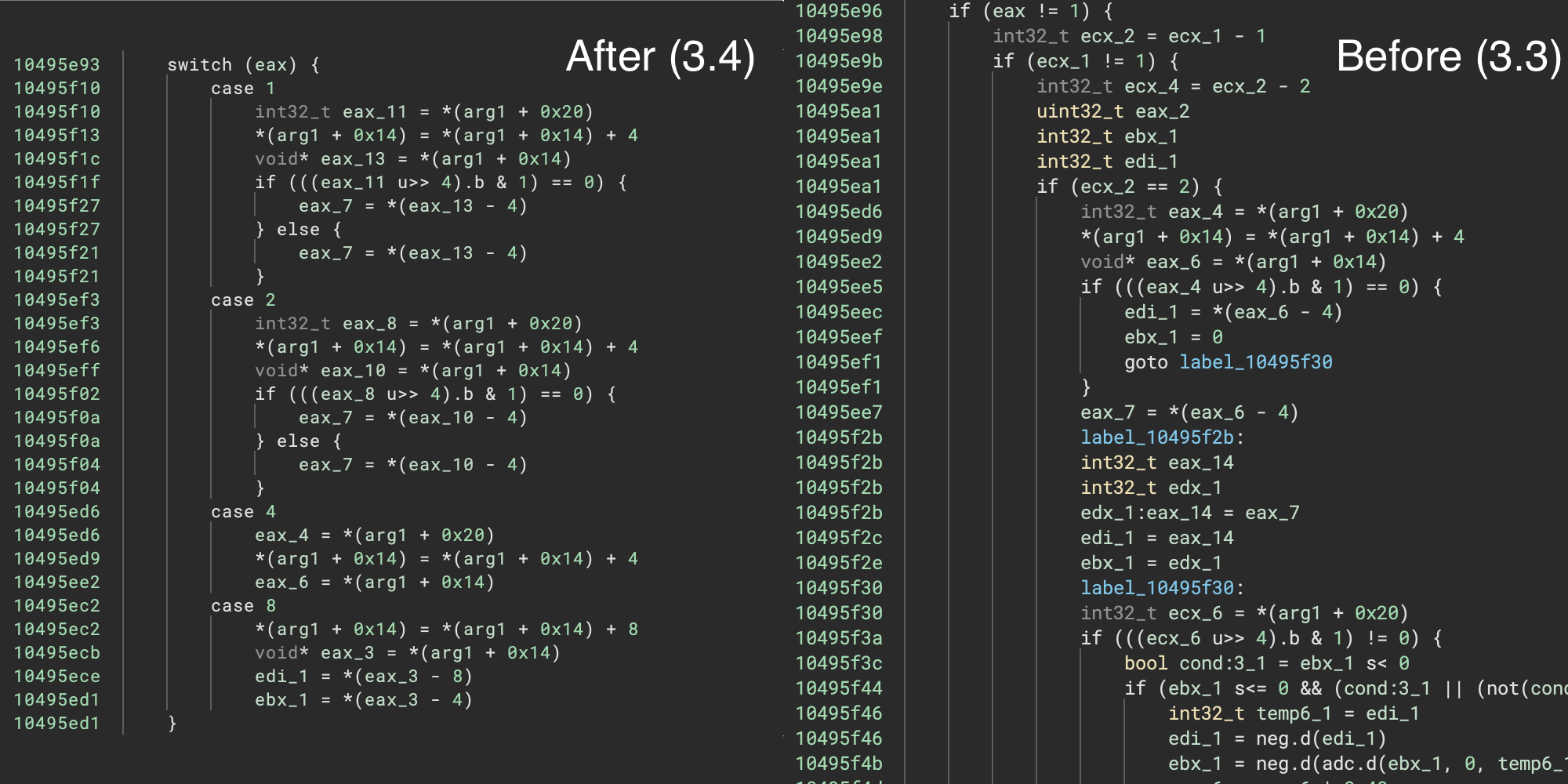
How often does this happen? We weren’t sure ourselves so we took a few hundred random binaries from the the Decompiler Explorer (Dogbolt), and compared the switch statement recovery before and after:
| Total Switch Statements 3.3 | 861 |
|---|---|
| Total Switch Statements 3.4 | 1023 |
| Improvement | 18.82% |
| Binaries Scanned | 184 |
| Binaries Improved | 53 |
Turns out, what we thought was a small ability to better handle sparse switch statements resulted in almost a 20% improvement in recovering switch statements!
Import from BNDB
Have you ever wanted to copy data from a previous BNDB into a new one? That process just got a whole lot easier with the new Import from BNDB dialog.
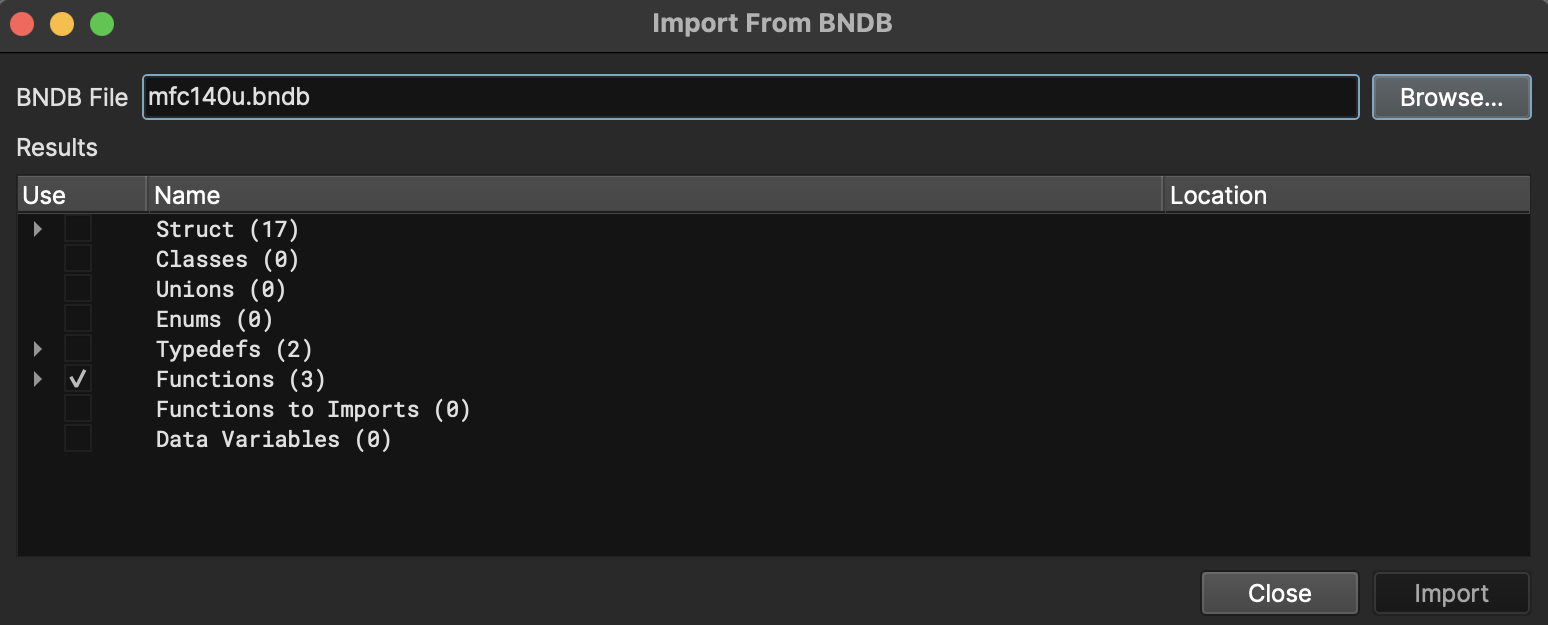
The Import from BNDB feature imports types from a previous BNDB into your currently open file. In addition, it applies types for matching symbols in functions and variables. Import BNDB will not port symbols from a BNDB with symbols to one without – the names must already match. To first match similar functions without symbols and port symbols over, consider using BinDiff, whose binexport plugin works with Binary Ninja.
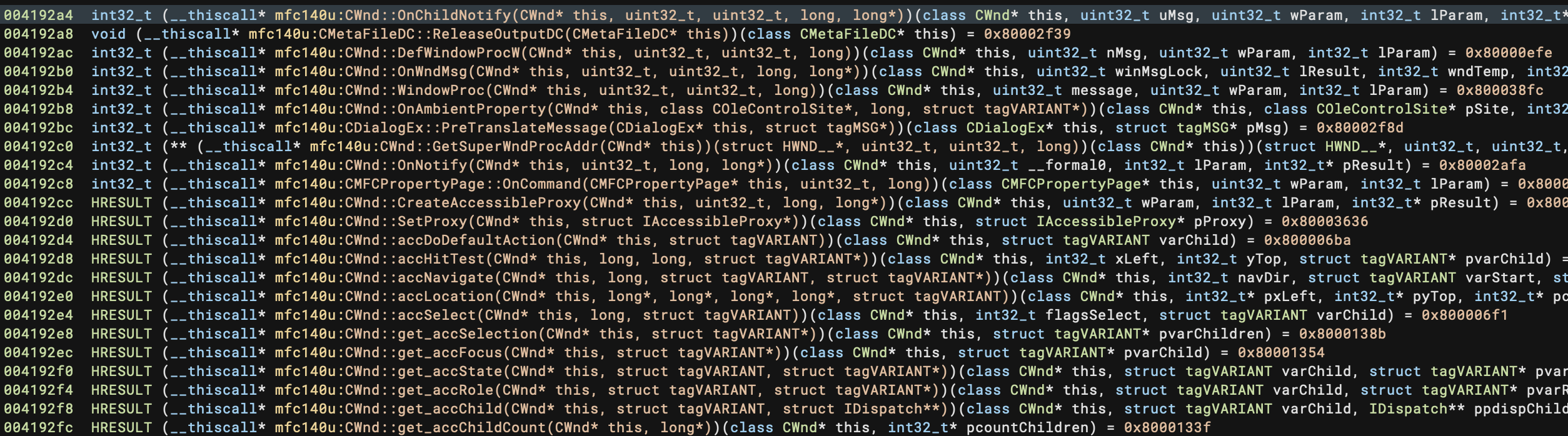
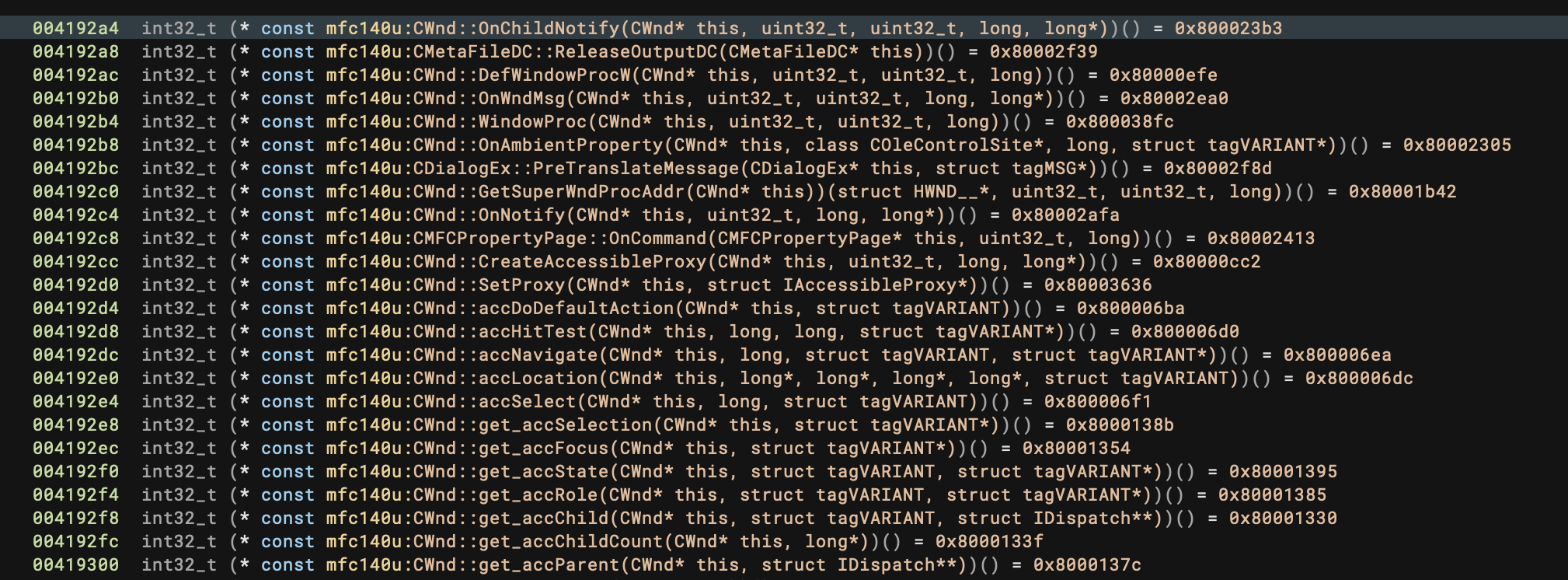
Enterprise Improvements
For this release, we’ve focused on providing additional support for deploying the Enterprise server in different environments. We’ve also done a round of updates on the user experience of managing an Enterprise server. And, finally, we’ve addressed some annoying performance issues and some reported bugs.
Up until now, deploying an Enterprise server has been easy, simple, and fast…but, also somewhat inflexible. We are still working to address this inflexibility in future releases, but beta support for cloud deployments on Azure and deployments with Podman (which improves our Red Hat compatibility) have landed in this release. We’ve also changed the way we handle SSL, and now operate more cleanly behind edge routers, web application firewalls, and reverse proxies.
One of the major changes we’ve made server-side is moving Enterprise user data into an object store. For customers that are deploying the Enterprise server on local hardware, we provide one and migrate your data automatically. But, for customers that have a cloud deployment and want to store their data with their cloud provider, we can now support external S3-compatible object stores.
In the client, we’ve improved network and UI performance for files with a large amount of snapshots and projects with a large number of files. We’ve also addressed a number of edge-cases that could lead to errors or crashes.
Debugger Improvements
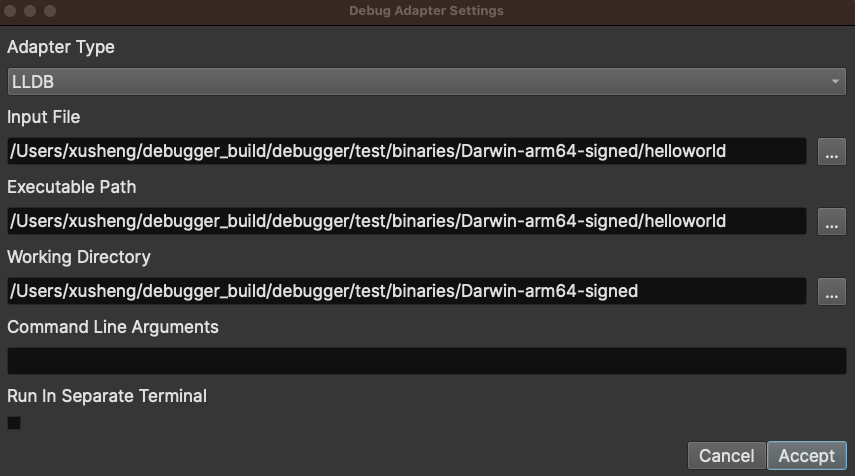
Thanks to Xusheng’s hard work, the debugger has really flourished since the last stable release, and we’ve heard from many users that they’ve been leveraging it with good results. The full list of debugger improvements is below, but the headliner is the ability to debug dynamic libraries. You’ll want to use the debug adapter settings menu option item to specify the binary launcher (for example, rundll32), distinct from the “input file” which would be the DLL or shared library itself:
Experimental Features
Experimental features are those that are disabled by default but still available for users to try out with some limitations. Two features that didn’t quite make the cut-off for reliability and performance are still available for early testing in this release.
Components UI
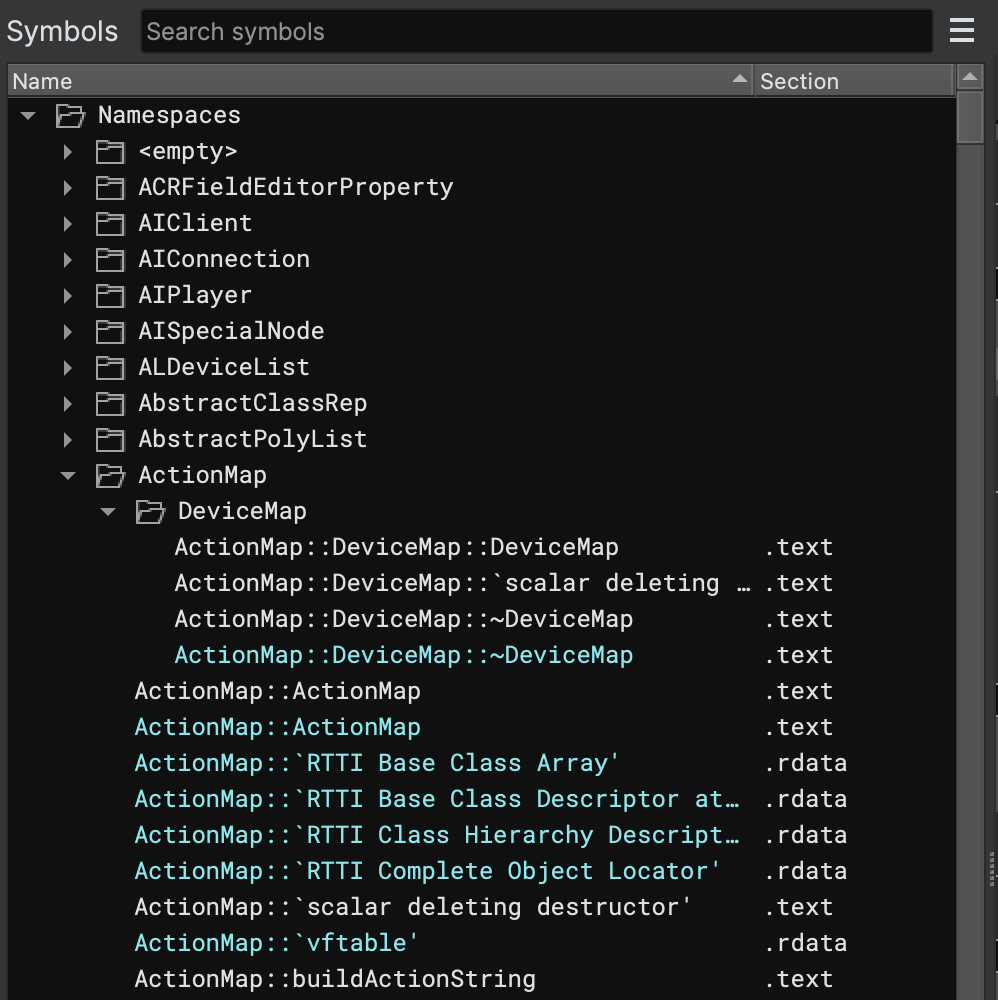
The new Components UI gives you a new way to organize your analysis. You can use it to your symbols into folders based on names, compiler units, or anything your heart desires! If you like scripting, there is a convenient API to enable you to write your own automatic organization. While performance for small and medium-sized binaries is good, for those working with large binaries that have large numbers of functions or global variables (on the order of >100k), the performance of the Components UI isn’t quite up to snuff yet. That said, we encourage everyone to give it a try! You can enable it with the ui.components.enabled setting.
MH_FILESET
MH_FILESET is a new Mach-O feature in recent macOS and iOS binaries where kernel extensions and libraries are collected into a single large file. The new support for these files can extract these modules without needing an external tool. This experimental feature is enabled by opening a Mach-O file using “Open with Options” and enabling the loader.macho.processFileset setting:
Note that this feature is disabled by default due to some crashes that have not yet been resolved. If robust MH_FILESET support is important for your workflow, make sure to switch to the dev branch as we expect improvements to the feature on that branch after the 3.4 release.
Other Updates
Special thanks to op2786, WhatTheFuzz, Joe Rozner, and mkrasnitski, for your contributions to our open source components during this release cycle!
UI Updates
- Feature: Header Import Dialog now assigns types for matching Import/Export symbols.
- Feature: Plugin dependencies can now be installed out of the box on MacOs (matching Linux/Windows)
- Feature: Show enumeration value on hover
- Feature: Shift+double-click now opens in a new pane
- Feature: Added context menu for Dock icon on macOS
- Feature: Added new ‘Dark Ninja’ theme
- Feature: Add
current_*_ssato the python console - Improvement: Upgraded to Qt 6.4.3
- Improvement: Reduce UI lag due to symbols view
- Improvement: Command line arguments are now preserved on restart
- Improvement: Windows task manager description
- Improvement: Install/Reinstall/Uninstall state in Plugin Manager
- Improvement: Plugin Manager UI consistency fixes
- Improvement: Counts are shown next to tag types in Tags View
- Improvement: Plugin Manager plugin dependencies are now reinstalled on update.
- Improvement: Type View now has horizontal scrolling when necessary
- Fix: Make Triage View update as analysis updates (exports, base address, etc.)
- Fix: Disambiguate
RestartfromRestart and Reopen - Fix:
help()in the python console now works on Windows - Fix: Issue where type would be duplicated when renamed
- Fix: Issue where Symbol list would miss double-clicks
- Fix: Focus of import file picker dialog
- Fix: Issue where python console could throw exceptions
- Fix: Synchronized navigation for LLIL/LLIL-SSA to MLIL-SSA
- Fix: ‘Item Type’ field in Create Array Dialog could be wrong
- Fix: Width calculation of plugin manager to avoid truncation of descriptions
- Fix: Condition where ESC key wouldn’t be processed in “Filter Views”
- Fix: Crash resulting from malformed stack variable
- Fix: Issue where Linear View wouldn’t update when a type was updated
- Fix: Crash caused by Linear View sticky header
- Fix: Crash in Triage View when platform is null
- Fix: Bug that caused Enumeration member values to change sign when passed through the API
- Removed: Legacy BNDB Merge Tool
Binary View Improvements
- Improvement: ELF View now creates an array for
.init_array - Improvement: Parsing of Mach-O exported symbols
- Improvement: Create names for functions in the
__mod_init_funcsection - Fix: Issue where ELF View could create sections outside of the address space of the file
- Fix: Don’t create entry point at Binary View start
- Fix: Issue where TLS, SEH, and CFG related function pointers weren’t properly handled when rebasing
Analysis
- Feature: Initial support for >8 byte constant propagation
- Feature: Recover untyped symbols in PDB
- Feature: Add Type Libraries for MFC ordinals
- Improvement: Don’t show parameter name if its the same as the argument name
- Fix: Issue where structure member cross references could become stale
- Fix: Inlining of tail calls within tail calls
- Fix: Display of enumeration constants for small width enumerations
- Fix: Enumeration display where ~value == 0
- Fix: Handling of namespaces in the type parser
- Fix: Showing the wrong size token in Pseudo-C
- Fix: PDB parser continuing to run after closing the file
- Fix:
charsignedness - Fix: Issue where no-return status wasn’t accounted for when overriding call type
- Fix: Occasional crash when using objective-c workflow on Apple silicon
- Fix: Crash parsing malformed __convention()
- Fix: Stack parameter resolution on x86 tailcalls
- Fix: Dead store elimination for partial writes
- Fix: Crash related to inlined code
- Fix: Properly propagate parameters through thunks
- Fix: Issue where small types used as returns were not properly handled
API
- Feature: Add APIs for dumping Type Libraries to JSON
- Feature:
IsConstantDataAPI now available on C++RegisterValueAPI - Feature: implemented
__bool__for BinaryView, Segment, and Section classes - Feature: Added
MetadataChoiceDialog - Feature: New API for handling Constant Data Expressions
- Feature: Set the
__version__property of the python API - Feature: New API for getting/setting application font
- Feature: Data Variables can now be added to Components
- Feature: New
visitmethods on IL instructions. - Feature: Many new APIs for handling derived structures
- New Example: minidump implemented in Rust
- Improvement:
TypeLibrary::Finalize()not returnstrueon success - Improvement: Make
splitPanereturn the created pane - Improvement: Expose
GetSymbolsByRawNamein the C++ API - Improvement: Implemented Rust version of
interaction::get_form_input - Improvement:
BinaryReader.seekhas new optionalwenceparameter - Improvement: Document that you can’t create databases in the context of analysis callbacks
- Improvement: Add additional documentation on how to access types
- Improvement: Update the
instruction_iterator.pyexample to work headlessly - Improvement:
install_api.pyscript has been refactored with new options - Improvement: Deprecation warnings now
LogWarninstead ofLogError - Fix: Prevent plugins from calling
GetMinimumCoreABIVersionwhile loading to avoid… shenanigans - Fix: HLIL SSA memory and variable version bug
- Fix:
set_comment_atin the scripting console - Fix: Issue where segment could be truncated
- Fix: Crash when creating zero width enumerations
- Fix: Crash in
get_instruction_infowhen returning the wrong type - Fix: Suppress warning about partial string in
get_string_atAPI - Fix: Bug in
bv.get_symbol_atwhen Namespace was not None and symbol was an auto symbol - Fix: Rust headless Binary View not loading correctly
- Fix: Many deficiencies in the C++ Binary View API including UAF and Type object leaks
- Fix:
InstructionTextTokendefault constructor not initializing members - Fix:
ScriptingProviders.update_localsraising exceptions causing console entry to fail - Fix: Bug in C++ demangler not clearing output buffer.
- Fix: Issue where you couldn’t read a Data Variable’s array members inside a struct
- Fix: In C++ the
Confidence::operator==was broken - Fix: Many many type hint improvements
- Deprecation:
__len__of Segment objects in the python API - Deprecation:
Function.function_typeis deprecated in favor ofFunction.type - Deprecation:
Function.explicitly_defined_typeis deprecated in favor ofFunction.has_explicitly_defined_type
Architectures
- Improvement: rep mov/stos x86/x64 instructions are now lifted as intrinsics
- **Improvement: **Default carry/zero flag behavior around shifts/rotates
- Improvement: x86/x64 floating point comparisons and loads
- Fix: R_AARCH64_RELATIVE Relocation
- Fix: Thumb2 case labels for switch cases based on address.
- Fix: Aarch64 lifting of
UMULH/SMULHinstructions
Debugger
- Feature: Added a safe mode that prohibits launching any file
- Improvement: Updated LLDB to 16.0.0
- Improvement: Added a button to open the debug adapter settings dialog from the debugger side bar
- Improvement: Show a progress bar when adding a binary view into the debugger binary view
- Improvement: Do not save the debugger binary view into the database
- Improvement: Confirm the launch operation when a file is launched for the first time
- Improvement: Open the register’s value in a new tab when a register value is middle-clicked
- Improvement: Register dereference now recognizes wide chars, utf16/utf32 strings, functions, and data variables
- Improvement: Show a preview for the address when hovering over an register
- Improvement: Support editing register value by pressing the “E” key
- Improvement: Support adding a breakpoint from the breakpoints widget
- Fix: Breakpoints do not work after the module has been rebased
- Fix: LLDB adapter crashes when connecting to a remote process using gdb-remote on a real remote host
- Fix: LLDB adapter reports the launch as failure if the target launches and then exits without hitting a breakpoint
- Fix: Fix a memory leak and properly free the debugger binary view after the target exits
- Fix: Clicking the three-dots button in the debug adapter settings dialog now opens the folder the file is in
- Fix: Disable resizing the debug adapter settings dialog
- Fix: Fix a crash when opening a database that has been saved during debugging
- Fix: Fix a UAF in attach process dialog
- Fix: Pressing ESC does not close the attach process dialog
- Fix: Do not add an entry breakpoint if the module has no entry function
- Fix: Properly set the default platform and architecture for the debugger binary view
- Fix: Keybindings do not work in register/breakpoint/threads widget
- Fix: Properly calculate the width of the hint column in the register widget
- Fix:
DebuggerController.register_event_callbackdoes not work - Fix: DbgEng adapter cannot debug a file whose name is a valid hex integer
- Fix: Font settings do not hot-update when they are changed
- Fix: Demo version of BN crashes when there are at least two tabs open
Enterprise
- Feature: Enterprise server storage now uses an S3-compatible object store, rather than relying on having a local filesystem available (which can be replaced with an external object store, if required)
- Feature: Added a
get_bundlecommand to the management interface as another way to obtain a copy of the offline install bundle - Feature: Added a
--latest-onlyflag to theclient_updates downloadcommand in the management interface, which will download Enterprise client updates for only the lateststableanddevchannel builds - Feature: Added preliminary support for Podman deployments
- Improvement: Re-wrote the handling of progress functions, which makes cancelling certain actions far more responsive
- Improvement: Enabled links in file metadata
- Improvement: The “Focus Chat” action now focuses inside the text input box
- Improvement: The sync button display logic was re-written, causing it to visually change far less frequently
- Improvement: The Remote Browser is now properly themeable
- Improvement: “Remember Me” option is now on by default
- Improvement: Performance improvements for servers with a large number of project files
- Improvement: Added caching for projects in the client
- Improvement: Added support for alternate Docker Swarm stack names
- Improvement: Added support for turning off server TLS (connections with Enterprise are still required to be encrypted, but this makes hosting behind an existing proxy far easier)
- Improvement: The management interface’s
installcommand now states which version has been installed or updated to - Improvement: Offline updates downloaded from the management interface now use our much smaller “bundle” format by default (use
--legacy-formatif you need the old one for clients older than version 3.0) - Improvement: Added support for changing internal service hostnames (required for supporting ACI deployments)
- Improvement: A more helpful message is shown while the backend container is still starting up
- Improvement: Client downloads are now gated behind user login
- Improvement: Users are now able to log into the server using SSO via the browser (previously, only the client was able to use SSO)
- Fix: Files can now be uploaded directly into a project folder, instead of always being uploaded to the root of the project
- Fix: Prevent duplicate license checkouts due to client missing response from server
- Fix: Clear saved credentials when server login fails
- Fix: The collaboration API examples are included with the client again
- Fix: Server key changes are now handled more gracefully in the client
- Fix: The refresh action now correctly updates project file lists
- Fix: Renamed the C++ Enterprise API module (matches the Python API)
- Fix: Fixed a crash in the Remote Browser when selecting a deleted project
- Fix: Fixed a crash when dropping an item onto a deleted project folder
- Fix: Fixed a crash when quickly navigating back-and-forth between projects
- Fix: Added an error message for when downloading an original file fails
- Fix: Added missing param name in the
Project.upload_new_fileAPI - Fix: Filename extensions are no longer stripped from uploaded BNDBs
- Fix: Temporary chat and user position disconnects are now warnings, not errors
- Fix: Large merge conflicts will now no longer hang the client
- Fix: The logic for merging tags now has less superfluous conflicts
- Fix: Newly uploaded files no longer show as “Unknown File” in the New Tab widget
- Fix: The Remote Browser’s folder sorting now works as expected
- Fix: Address parsing in chat no longer fails to properly identify a linked address in certain circumstances
- Fix: Added missing Docker Swarm support for the
backup,restore, andchange_passwordmanagement interface commands - Fix: A more appropriate error message is returned when trying to delete the last remaining snapshot in an uploaded project file
- Fix: Set a more appropriate default range for license reservation stats
- Fix: Updated Enterprise server dependencies to address potential denial of service opportunities
- Fix: Client now properly uses the local trust store for certificates on macOS
Documentation
- Feature: Offline search now works in user documentation!
- Improvement: Update docs for parse_expression
- Improvement: Do not import packaging in deprecation.py
- Improvement: Document that progress functions must return True to continue loading
- Improvement: Using latest mkdocs and sphinx
- Improvement: Better documentation on python dependency installation
- Improvement: New cookbook examples
- Improvement: Document silent install process on windows
- Fix: Fonts in offline documentation were still using online fonts
Miscellaneous
…and, of course, all of the usual “many miscellaneous crashes and fixes” not explicitly listed here. Check them out in our full milestone list: https://github.com/Vector35/binaryninja-api/milestone/18?closed=1
如有侵权请联系:admin#unsafe.sh