- 数据:指事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的原始素材。它是可识别的、抽象的符号。
- 敏感数据:丢失、滥用、变改或未经许可存取会损害个人隐私或利益、商业秘密 (the Privacy or Welfare of an Individual, Trade Secrets of a Business),甚至国家的安全和国际关系 (the Security and International Relations of a Nation) 的信息 。其将 “敏感信息” 分为涉及企业秘密、国家安全两大类。
- 数据分类:通过具有某种共同属性或特征的数据归并其类别的属性或特征来对数据进行区别。遵循约定的分类原则和方法,实现数据共享和提高处理效率,从而更好地管理和使用数据的过程。
- 数据分级:按照数据的价值、内容敏感程度、影响和分发范围不同对数据进行敏感级别划分,从而为数据的开放和共享安全管控策略提供支撑的过程。
随着网络技术的快速发展,大量数据在各种业务活动中产生,数据价值越来越凸显,在商业策略、社会治理和国家战略制定过程中,数据都起到了重要的决策支撑作用。
为了保证企业、组织和国家机关数据安全性,应该对数据进行有效发现和分类,避免一刀切的控制方式,而应采用更加精细的管理措施,使数据资产在共享使用和安全使用之间获得平衡。敏感数据,或者叫做敏感信息就是一类特殊的数据类型,需要采用特殊的手段进行管理。
0x1:敏感数据发现对国家安全的意义
2019 年 1 月,一桩被称为 “Collection#1” 的 “史上规模最大公共数据泄露事件” 遭到了曝光,包含将近 7.73 亿个独立电子邮件地址、2122 万多个独立密码。据调查,此次曝光的内容仅是冰山一角,Collection #1 的文件大小约为 87GB,而整个信息合集的总量是这个数字的十倍之多。2018 年 1 月,印度 10 亿公民身份数据库 Aadhaar 被曝遭网络攻击,该数据库除了名字、电话号码、邮箱地址等之外还有指纹、虹膜纪录等极度敏感的信息。
除了隐私和商业秘密之外,一些 “公开” 数据开始展现出新的面貌和价值,越来越多的计算资源被用于从非涉密数据中提炼敏感信息,获取涉密内容和重要情报,这更应引起高度警惕:2017 年 11 月,美国一款记录健身者运动轨迹的软件——Strava,用两年时间积累的用户数据,制作发布了一幅 “全球运动热力地图”。2018 年 1 月 28 日,一名 20 岁的澳大利亚学生纳森·鲁泽研究这份热力图后,通过分析特定区域的一些运动轨迹,找到了美俄等国设在叙利亚、伊拉克和阿富汗等国的基地,有的从未向外界公布过。纳森·鲁泽公布他的 “发现” 后,越来越多的基地通过这种途径被 “挖掘” 出来,其中包括美国中情局在索马里摩加迪沙的基地、俄罗斯在叙利亚的赫梅米姆空军基地等。而且,从热力图的轨迹中,能看到的不仅仅是基地的位置,基地内部的人员轨迹也清晰可见,专业人士可以从中研究出这些军事设施的运转方式。
电子政务、互联网、物联网等领域已经产生海量数据,并且在国家大数据战略下流转,但目前这些数据基本处于 “裸奔” 状态,面临数据泄露的威胁。大量非密、敏感的信息碎片在高技术深窃密的帮助下可以聚合、叠加形成影响国家安全的涉密信息。对数据进行有选择性地保护是政府控制信息的传统方法,大数据时代此法可能不再奏效,这就要求重新审视需要保守的国家秘密范围,对一些通过大数据分析有可能被准确预测,且确实关系国家安全的敏感信息,要研究如何识别和管理,并切断获取、分析和预测的途径。
0x2:敏感数据发现对企业的意义
大数据时代,所有数据都具有了一定的价值。企业在获得了大量的个人数据之后,他们会利用人工智能等技术来处理、分析数据,并且挖掘出有价值的信息,然后根据这些信息来促进业务的发展。随着组织规模的不断扩大和敏感信息(如信用卡号和个人财务数据)传播到多个位置,发现和分类过程变得非常重要。这通常发生在以下几个场景中:
- 兼并和收购的背景下
- 系统运行时间超过了原始所有者,数据属主发生了转移
- 数据被频繁使用和传输,数据创始者失去了对数据存储和流转路径的全局把控
- 商业间谍,企业员工离职窃取企业核心资产
因此,敏感数据可能存在于当前拥有该数据的人员所不知道的范围内。 这是一个常见但极易受攻击的场景,因为除非您知道敏感数据存在,否则无法对其进行保护。
敏感数据发现场景涉及企业安全性的三个关键方面:
- 发现:查找环境中任何位置存在的敏感数据。这一步的基础是数据分类分级,否则面临大量的虚假告警而无法抓住管控的重点。
- 保护:在访问敏感数据时进行监视和警报。
- 合规性:创建审计跟踪以复审敏感数据发现过程的结果。
0x3:敏感数据发现对个人的意义
保护个人的人身权利。
0x1:数据分类分级的产生背景
于大部分的企业对数据的管理方式五花八门,数据定义混乱,导致数据分散成信息孤岛,而过期失效的数据又占用了大量的资源,企业想要统一、有效地管理分散在各业务的数据,合理有效地分配存储数据的资源,更是难上加难。而企业对数据资产管理混乱,没有清楚地梳理,对于敏感数据分布在哪些数据资产中,关联了哪些业务,暴露在哪些人员面前等情况了解得不够清晰全面。这无疑又增加了数据泄露的风险,极有可能在不经意间就将内部的敏感信息泄露了出去。
而传统数据安全主要着力于数据作为资产的保密、完整和可靠性性,更多的停留在硬件和边界保护层面。但随着信息化的高速发展,传统的边界防护方法已经无法满足当下的需求,各种数据安全事件层出不穷。
根据Risk Based Security的最新报告,2020年第一季度数据泄露的数据量猛增至84亿,与2019年第一季度相比增长了273%,创下至少自2005年详细报告开始以来的同期记录。同时,IBM 的年度数据泄露成本报告显示,数据泄露的平均总成本接近 400 万美元。

为此,数据安全已经成为企业、消费者、监管机构的头等大事。这就要求新数据安全需要更加关注数据在采集、传输、存储、处理、交换、销毁方面对外部可能造成的危害。对数据进行更精细化的管理。
同时国家也相继出台了各种数据保护法规:《中华人民共和国国家安全法》、《中华人民共和国网络安全法》、《信息安全技术网络安全等级保护基本要求》、《信息安全技术网络安全等级保护测评要求》及《信息安全技术网络安全等级保护安全设计技术要求》等国家标准。
0x2:数据分类分级的发展现状
数据分类分级作为数据安全的“桥头堡”,在数据安全治理过程中至关重要,一般企业的数据可以分为公开数据、非公开数据(敏感数据)。为此我们需要把主要精力放在敏感数据的管控上,制定精细化的管控原则。根据不同数据级别,实现不同的安全防护,避免敏感数据泄露给公司造成重大损失。
工业和信息化部办公厅在20年2月27日发布《工业数据分类分级指南(试行)》,国内地方和行业上也有相应的指南发出,例如贵州省的《政府数据 数据分类分级指南》、金融行业的《金融数据安全 数据安全分级指南(送审稿)》和《证券期货业数据分类分级指引》等。
从以往实施的分类分级案例来看,有分类分级需求的企事业单位主要是基于以下几种情况:
-
满足合规需求。大部分的企业对于数据分类分级管理,首先就是要满足合规的要求。在法律法规的框架下,根据行业法规制定行业内的数据分类分级标准。
-
数据安全需求。有一部分企业由于数据资产建立初期管理比较粗放,随着企业信息化的发展,管理难度也随之加大。想通过对数据全面梳理,建立敏感数据的分类分级管控策略,减少企业数据安全风险。
-
数据使用价值需求。少数企业希望基于业务的分类可以更好地将数据资产化,充分了解数据资产中敏感数据的情况,使管理者能够通过分级分类来有效管控,持续为企业提供精准的数据服务。
0x3:看待数据分类分级的不同角度
原则上,数据分类分级自身是一个统一、规范地体系,笔者之所以要带读者朋友辨析看待数据分类分级的不同角度,主要目的是想说明,虽然都是叫敏感数据分类分级,但是在不同的行业、不同的部署场景、不同的需求侧重点,对敏感数据分类分级产品的要求侧重点也会不同。
1、从数据自身属性角度看数据分类分级
1)组织敏感数据/商业机密
对于企业或一个组织来说,敏感信息包括
- 客户资料
- 技术资料
- 重大决策信息
- 主要会议纪要
- 财务预算信息
- 各种财务报表等高价值数据
这些数据以不同形式存在于企业资产中。
2)个人敏感信息
个人信息是指以电子或者其他方式记录的能够单独或者与其他信息结合识别特定自然人身份或者反映特定自然人活动情况的各种信息,如姓名、出生日期、身份证件号码、个人生物识别信息、住址、通信通讯联系方式、通信记录和内容、账号密码、财产信息、征信信息、行踪轨迹、住宿信息、健康生理信息、交易信息等。
判定某项信息是否属于个人信息,应考虑以下两条路径:
- 一是识别,即从信息到个人,由信息本身的特殊性识别出特定自然人,个人信息应有助于识别出特定个人。
- 二是关联,即从个人到信息,如已知特定自然人,则由该特定自然人在其活动中产生的信息(如个人位置信息、个人通话记录、个人浏览记录等)即为个人信息。符合上述两种情形之一的信息,均应判定为个人信息。
以《GBT 35273-2017 信息安全技术个人信息安全规范》为例,个人信息有:
- 个人基本资料:个人姓名、生日、性别、民族、国籍、家庭关系、住址、个人电话号码、电子邮箱等
- 个人身份信息:身份证、军官证、护照、驾驶证、工作证、出入证、社保卡、居住证等
- 个人生物识别信息:个人基因、指纹、声纹、掌纹、耳廓、虹膜、面部特征等
- 网络身份标识信息:系统账号、IP 地址、邮箱地址及与前述有关的密码、口令、口令保护答案、用户个人数字证书等
- 个人健康生理信息:个人因生病医治等产生的相关记录,如病症、住院志、医嘱单、检验报告、手术及麻醉记录、护理记录、用药记录、药物食物过敏信息、生育信息、以往病史、诊治情况、家族病史、现病史、传染病史等,以及与个人身体健康状况产生的相关信息,及体重、身高、肺活量等
- 个人教育工作信息:个人职业、职位、工作单位、学历、学位、教育经历、工作经历、培训记录、成绩单等
- 个人财产信息:银行账号、鉴别信息(口令)、存款信息(包括资金数量、支付收款记录等)、房产信息、信贷记录、征信信息、交易和消费记录、流水记录等,以及虚拟货币、虚拟交易、游戏类兑换码等虚拟财产信息
- 个人通信信息:通信记录和内容、短信、彩信、电子邮件,以及描述个人通信的数据(通常称为元数据)等
- 联系人信息:通讯录、好友列表、群列表、电子邮件地址列表等
- 个人上网记录:指通过日志储存的用户操作记录,包括网站浏览记录、软件使用记录、点击记录等
- 个人常用设备信息:指包括硬件序列号、设备 MAC 地址、软件列表、唯一设备识别码(如IMEI/android ID/IDFA/OPENUDID/GUID、SIM 卡 IMSI 信息等)等在内的描述个人常用设备基本情况的信息
- 个人位置信息:包括行踪轨迹、精准定位信息、住宿信息、经纬度等
- 其他信息:婚史、宗教信仰、性取向、未公开的违法犯罪记录等
个人敏感信息是指一旦泄露、非法提供或滥用可能危害人身和财产安全,极易导致个人名誉、身心健康受到损害或歧视性待遇等的个人信息。通常情况下,14岁以下(含)儿童的个人信息和自然人的隐私信息属于个人敏感信息。
可从以下角度判定是否属于个人敏感信息:
- 泄露:个人信息一旦泄露,将导致个人信息主体及收集、使用个人信息的组织和机构丧失对个人信息的控制能力,造成个人信息扩散范围和用途的不可控。某些个人信息在泄漏后,被以违背个人信息主体意愿的方式直接使用或与其他信息进行关联分析,可能对个人信息主体权益带来重大风险,应判定为个人敏感信息。例如,个人信息主体的身份证复印件被他人用于手机号卡实名登记、银行账户开户办卡等。
- 非法提供:某些个人信息仅因在个人信息主体授权同意范围外扩散,即可对个人信息主体权益带来重大风险,应判定为个人敏感信息。例如,性取向、存款信息、传染病史等。
- 滥用:某些个人信息在被超出授权合理界限时使用(如变更处理目的、扩大处理范围等),可能对个人信息主体权益带来重大风险,应判定为个人敏感信息。例如,在未取得个人信息主体授权时,将健康信息用于保险公司营销和确定个体保费高低。
下面列出个人敏感信息的示例:
- 个人财产信息:银行账号、鉴别信息(口令)、存款信息(包括资金数量、支付收款记录等)、房产信息、信贷记录、征信信息、交易和消费记录、流水记录等,以及虚拟货币、虚拟交易、游戏类兑换码等虚拟财产信息
- 个人健康生理信息:个人因生病医治等产生的相关记录,如病症、住院志、医嘱单、检验报告、手术及麻醉记录、护理记录、用药记录、药物食物过敏信息、生育信息、以往病史、诊治情况、家族病史、现病史、传染病史等,以及与个人身体健康状况产生的相关信息等
- 个人生物识别信息:个人基因、指纹、声纹、掌纹、耳廓、虹膜、面部识别特征等
- 个人身份信息:身份证、军官证、护照、驾驶证、工作证、社保卡、居住证等
- 网络身份标识信息:系统账号、邮箱地址及与前述有关的密码、口令、口令保护答案、用户个人数字证书等
- 其他信息:个人电话号码、性取向、婚史、宗教信仰、未公开的违法犯罪记录、通信记录和内容、行踪轨迹、网页浏览记录、住宿信息、精准定位信息等
3)行业敏感信息
4)国家敏感信息
对于国家政府部门来讲,敏感信息是介于保密信息与公开信息之间的特殊信息,这类信息不符合定密标准,不能按照国家秘密的形式进行保护,但是如果公开,却有可能造成某种损害或潜在损害,因此需要限制公开或控制其传播。
2017 年 5 月 24 日,全国信息安全标准化技术委员会秘书处发布了国家标准《信息安全技术 大数据安全管理指南》征求意见稿中提到:“组织应对已有数据或新收集的数据进行分级,数据分级时需要组织的业务部门领导、业务专家、安全专家等共同确定。政府数据分级参照 GB/T 31167-2014 中6.3执行,将非涉密数据分为公开、敏感数据”。
2、从数据流动看数据分类分级
本质上说,数据只有在流动中才能产生价值,同时也只有在流动中才会产生风险。因此,根据流动方向和流动原因的不同,敏感数据识别的侧重点也不同,
- 主动流动的敏感数据
- 员工外发数据
- 被动流动的敏感数据
3、从地域、文化差异看数据分类分级
实际上关于如何鉴定和分类 “敏感数据” 这一核心问题,不同国家、区域在界定过程中存在很多差异。
- 首先,依据伊兹欧尼的观点,“测定数据的敏感程度应当反映所在社会的价值观”,敏感数据的判断标准受到该社会特定规范性文化的影响。但即便是文化传统相似的欧盟成员国之间依然存在一些差异,例如,在一些欧盟国家,“照片可被用来区分公民的民族/种族”,因而被视为敏感数据,而欧盟数据保护工作小组 (The Working Party) 并不将网络照片归为敏感一类。
- 其次,即便是在同一个同家、州或城市,不同的法律或部门也可能对同一类数据的归类不尽相同。以美国为例,《金融隐私权法》规定,客户的金融信息、银行账户信息被视为高度敏感数据,美国联邦贸易委员会 (FTC) 公布的五大敏感数据也包括财务信息,但HIPAA法案却将其排除在外。
- 再者,同一文化或社会中,敏感数据的标准还会随着时间而改变。不同年代的人有着不同的隐私期待或判断标准。
综上不难看出,对于敏感数据,企业和组织、甚至国家层面都要针对自身性质以及业务情况,制定更符合实际情况的分类。
4、从概念数据模型看数据分类分级
大数据时代中常见的三类数据类型,
- 结构化数据
- 数据库字段
- 半结构化数据
- 非结构化数据
- 图像,需要通过ocr将像素矩阵转化为文字序列
- 文本文件
- 文档等
这三类数据的最主要区别在于是否存在预先定义好数据模型,更确切的说是概念数据模型。
参考链接:
https://cloud.google.com/dlp/docs/sensitivity-risk-calculation?hl=zh-cn https://help.aliyun.com/document_detail/322244.html https://www.tc260.org.cn/upload/2018-01-24/1516799764389090333.pdf
- 敏感数据识别与添加标签。从海量数据中将数据进行分类分级,方便进行不同粒度和级别的安全管理。
- 数据泄露趋势预警。如果出现频繁访问敏感数据的异常行为,可以及时进行风险告警。
- 数据静态脱敏、数据水印。对于已标记特定安全级别的敏感数据,可在对外提供数据时进行脱敏或者加水印。
- 敏感数据防泄漏。对于已经标定为敏感标志的数据文件,在应用和网络层面阻断其外发。
- 数据安全合规检查。通过对敏感数据的分析,制定数据安全合规管理制度,帮助企业建设以及改善信息安全合规管理体系
参考链接:
https://support.huaweicloud.com/usermanual-dataartsstudio/dataartsstudio_01_1009.html
0x1:企业如何落地数据分类分级
在实际分类分级落地过程中有以下几点关键处则尤为重要。
1、推进数据分类分级落地,要从制度建立着手
要想推动分类分级落地,需要将数据分类分级作为制度流程工作落实到组织管理制度中,确定分类分级中涉及的部门、职责,以及需要梳理的数据资产、敏感类型、分类分级方式、管控原则等,确保分类分级落地。
数据安全成熟度模型(DSMM)中对此也有相关的说明,组织应设立负责数据安全分类分级工作的管理岗位和人员,主要负责定义组织整体的数据分类分级的安全原则,应定期评审数据分类分级的规范和细则,考虑其内容是否完全覆盖了当前的业务,并执行持续的改进优化工作。

2、清楚企业数据资产状况,明白敏感数据分布
现在企业对哪些数据是敏感数据,需要保护的数据分布在哪?敏感数据是否都得到了保护并不清楚。传统做法是对企业数据进行打标签,存在人工整理跨部门沟通难、导入数据湖的数据不全、有未知数据源、人工整理时间人力成本高等问题和难处。
针对数据安全的风险,应以数据为中心,向外对业务、网络、设备、用户采取“零信任”的态度,既然每个环节都不可信,那么管控手段就要覆盖全部环节,任意环节失信后都能实现熔断保护。
- 用户侧
- 终端侧
- 网络侧
- 业务侧
- 数据中心
都要做好安全防护措施。
- 外向内防攻击、防入侵、防篡改
- 内向外防滥用、防伪造、防泄露
最关键的是,要对全部纵深防护环节进行整体控制,实现环境感知,可信控制和全面审计。
比较推荐的方式是借助敏感数据发现工具进行数据梳理发现,基于IP段或流量对数据资产进行自动扫描,包括未知的暗数据资产,自动化发现减少人工成本。全方位发现数据资产,增强资产梳理效率与发现能力,减少人工整理成本。清晰各数据库类型、文件类型等数据资产的分布情况。
3、根据相关指引,科学地对数据进行分类分级
对于企业来讲,敏感数据主要集中在商业秘密和个人隐私部分。为达到精细化管控的要求,需制定一份完整且恰当的数据分类分级方案。而一份适合企业自身需求的数据分类分级方案需要满足以下基本要求:
- 数据定级应满足国家法律法规及行业主管部门有关规定。
- 定级规则应避免过于复杂,以保证其在数据分级过程中的可行性。
- 应结合自身(或集团)数据管理需要(如战略需要、业务需要、对风险的接受程度等);应根据本机构数据的类型、敏感程度等差异,划分不同的数据安全层级,并将数据划分至不同的级别中,不宜将所有数据集中划分到少数几个级别中等。
除此之外,还需考虑
- 两种或两种以上低敏感程度的数据经过组合、关联和分析后,可能产生高敏感程度的信息,如汇聚融合。
- 同一数据在不同服务场景中可能处于不同的类别,应根据服务场景及作用实施针对性的保护措施。
4、数据分类分级是方法,精细化管控是目的
数据分类分级的目的是通过对数据全盘梳理,分类分级后对不同级别的敏感数据采用不同的管控策略,实现精细化管控。例如:
- 《金融数据安全指南》里规定:最高级C3类别包括用于用户鉴别的个人生物识别信息、账户、登录密码等,管控策略可以把C3级别的数据直接进行数据脱敏。
所以,这就要求我们选用的数据安全产品应具有系统结合的能力,根据分类分级制定不同的管控策略进行下发其他安全产品,例如:
- 数据库审计:数据库审计在接收到管控策略时,可基于数据的分类分级标签,对不同的数据类型和级别设定不同的审计策略。在实际应用中,数据库审计能够获取到每次数据库操作的返回结果集,返回结果集中会包含本次操作的字段名与字段值。管控策略中也提供了每个字段对应的数据分类与分级标签,只需要进行简单匹配即可与现有的审计策略进行联动。在数据库审计过程中,虽然很多时候命中了高风险策略,但是这些操作行为对象大部分是低敏感数据,如果存在大量的类似告警,会将真正的高风险操作淹没在告警里。在结合了分类分级管控策略之后,可针对高敏感级的数据进行高优先级的风险告警,从而实现数据库审计的精细化审计,减少误报。
- 数据脱敏:指在对数据源进行分类分级的基础上,对敏感数据进行转换、加密或替换等方式的处理,达到数据脱敏的效果。随后将脱敏数据进行存储,使脱敏后的敏感数据能够安全的应用于测试、开发、分析和第三方使用环境中。
- 水印溯源:指通过对外发数据/文件添加含有责任人标识的水印信息的方式,实现了当数据/文件发生泄露时,可以从中提取出水印信息,从而达到责任溯源的目的,避免了因内部人员泄露信息等事件导致的重大损失,大大提高了数据外发的安全性。
- EDLP防泄漏:指在对PC端外发数据监控并分类分级的基础上,对不同风险等级的数据实行不同的管控策略,例如对高风险的IM聊天工具外发商密文件进行即时阻断、对低风险的简历外发只记录日志用于后期审计。
5、周期对敏感数据扫描发现,防患于未然
企业的信息化建设是不断更新发展的,传统情况下依靠人工进行数据梳理已经跟不上如今的发展需求,一是效率慢、成本高,二是数据变化快,无法长期维护更新。
这就要求企业需要选择分类分级的安全产品来替代人工定时/周期的敏感数据发现,自动化更新企业敏感数据目录,且能根据用户选择的数据资产及合规组,自动生成安全风险评估报告。可以通过报告知道有哪些非合规数据以及数据的位置,对数据资产进行脱敏或加密等安全整改,以推进数据安全建设工作。
0x2:敏感数据分类分级中的痛点
1、企业安全人员对敏感数据类型及分布情况不完全了解
很多时候,企业没有专职的CRO,甚至即使有专职CRO,由于企业数据分布零散、缺少历史观测数据等原因,导致企业安全人员很难提前编写出准确的识别规则,也很难保证覆盖率的完整。
针对这个问题,有以下几个思路进行缓解:
- 通过部署敏感数据发现系统对企业内数据资产进行全面梳理,并依据不同垂直行业通用的敏感数据类型和通用识别规则对数据内容进行全面扫描,为安全人员初步构建的企业敏感数据分布全景视图
2、企业为满足其业务需要,其数据包含特有的敏感数据类型或数据存储格式习惯,不能被厂商提供的行业通用数据识别规则完全覆盖
这个问题对商业产品来说是一个比较大的挑战,本质上属于非标需求定制,商业化产品往往只能按照一定的数据安全规范圈出一个范围,对范围外的非标敏感数据,有以下几个思路进行缓解:
- 基于安全产品捕获到的数据流动,在云端自动进行分词、词频统计、词频权重分析等处理,自动化生成敏感数据词云,用于辅助用户
- 在产品UI上提供用户自定义字典配置接口,由企业的安全同学根据自己企业的实际情况定义一些专属地敏感数据字典
- 对特定客户进行定制化服务,参照行业分类分级要求并调研企业实际开展业务所存储的敏感数据类型,统计当前敏感发现系统结果中尚未发现的敏感数据种类,通过字段名称、列注释、样本类型等特征信息在全局扫描结果中二次定位,对未发现的敏感数据类型进行新增或规则调整,并与数据组人员取得确认调整规则是否准确
3、不同场景下数据敏感级别可能发生变化,不能准确界定敏感级别的变化规则
针对这个问题,有以下几个思路进行缓解:
- 敏感数据发现系统根据不同场景下的敏感数据变化支持同一敏感数据类型拥有不同的判别依据和定级结果,提供包括不同业务场景、数据汇聚融合在内的多种不同场景下的敏感数据变更规则,满足规则灵活适用,判别标准统一准确的要求
4、满足合法合规要求且适合企业自身要求的规则需同时满足分级过程中的可执行性要求,如果太过复杂导致执行成本巨大
这个问题本质上是说如何用一个相对统一的商业化产品,去满足不同行业、不同发展阶段,不同需求侧重的企业需求。针对这个问题,有以下几个思路进行缓解:
- 参照行业规范和已调整完善的敏感类型识别范围,找出每个分类下的一个或多个关键识别类型和实际业务开展中出现的组合存储规律,为每个分类生成一个或多个匹配规则,形成数据分类定级的自动化标识方案,从而实现了行业规范要求的落地。
- 设置对敏感数据周期性进行自动扫描发现,自动给数据打上标签信息
- 云端技术人员通过持续性更新敏感数据分类分级目录,识别可能存在的未脱敏的敏感数据、未加密的敏感数据,生成数据安全风险报告,本质上是一种SaaS化能力提供
- 敏感数据识别模块需要关联水印溯源、数据脱敏、数据防泄漏等安全产品实现精细化管控。极大地帮助却降低人工成本、时间成本、确保了数据的使用价值,满足了行业合规要求,减少了数据安全风险。
0x3:敏感数据安全管理框架
1、数据分类框架 (Data Classification Framework)
按照敏感性程度由高到低,分别是:
- 受限 (Restricted)
- 高度机密 (Highly Confidential)
- 机密 (Confidential)
- 公开 (Public)
对于会接触到敏感数据的人群,也需要进行明确的分组,分别是数据所有者/受托人 (Data Owners / Trustees),数据保管人 (Data Custodians),以及数据用户 (Data Users)。不同组人群接触到的分类数据也不同。

2、敏感性分类管理策略
前面提到,对于任何企业或者机构而言,数据安全策略的执行取决于对数据的准确分类。公司应该构建一个金字塔型的数据应用生态系统,分别制定了数据所有者指南、组织级指南和企业级指南来实施数据管理 (Data Stewardship),一旦实施分类准则出现冲突或者难以界定的情况时,将按所遵从指南的等级高低进行评判。

以程序源代码的敏感级别判别过程为例:
一般说来,程序源代码判别应遵循企业级指南,默认情况下,工程源代码会被归类为高度机密。但是在组织级指南中有规定,关键或新兴项目源代码要被归类为受限,也就是说拥有更高的敏感程度。同时,数据所有者指南指出,Skyjet 项目源代码应归类为高度机密,但 I/O board FPGA 项目源代码实际上归类为机密。
因此,虽然都是源代码,但是按照指南的等级,Skyjet 项目源代码和 I/O board FPGA 项目源代码分别会被分类为高度机密和机密。
3、数据的敏感性识别方法
可以确定的是,数据的敏感性识别绝对不是孤立的一环。实际上,数据发现、数据图谱、数据分类等众多领域在识别数据敏感程度方面都可能发挥着重要作用,我们需要将这些方法协同起来形成一致性推断结果。
Cisco 提出了一种基于用例方法的数据应用场景分类模型,这种模型能够有效地将用户分类判断和自动化分类判断联合起来。

基于用例的数据应用场景分类模型
Step1:构建决策/场景模型 (Building decision/context models)
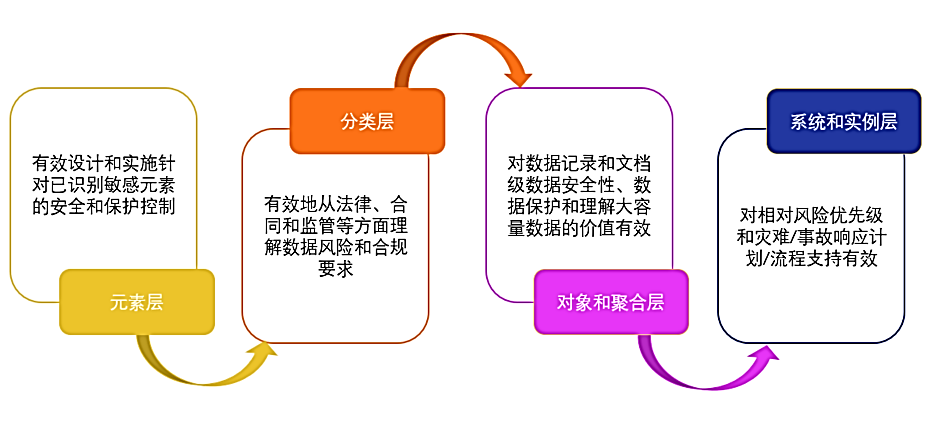
(1)识别正确的处理和数据保护单元
- 从元素层面上说,针对已识别的敏感元素要有效地设计和实施安全和保护控制
- 从类别层面上看,在数据风险和合规要求的法律、合同和监管理解方面应该是有效的
- 对象和聚合级别上,对于记录和文档级安全性和数据保护应该是高效的,并且有助于了解批量数据的价值
- 在系统和实例级别上,对相对风险优先级和支持灾难(事件)响应计划(流程)有效

在不同层级上识别正确的处理和数据保护单元
(2)识别用于数据场景提取的正确数据对象
比如公司的收入数据,可能会以非常多的形式存在,比如 Word,Excel,TCP包,数据库文件等等,这些数据都是以非常具体的形式存在的,但这种具体化无形中会增加分类的复杂性,在这种情况下,需要对其进行抽象,所有与收入相关的数据,无论其形式、存储位置和表达方式,都应该归为收入类数据。

从不同数据场景提取数据对象
(3)场景分类的业务相关性
可以根据以下业务相关性(业务定义的属性),识别适合场景分类的数据对象,
- 任务关键度
- 数据量
- 用户数量
- 个人验证信息或非个人验证信息
并非所有数据对象都适用于场景分类,比如静态数据分类和错误的数据处理或保护单元。
Step2:提取场景——问正确的问题

数据分类时依据的问题
为了更好的提取场景,需要明确一些问题,包括数据的特殊属性、数据使用和产生的相关修改、存储库/实例属性、聚集和时间敏感度、数据类别的含义、个人信息的适用性、风险和影响分析等等。
Step3:与数据所有者一起构建模型
在做好了所有的准备之后,和数据所有者一起按照如下的流程构建模型,将数据分为低敏感性、中等敏感性和高度敏感三类。

数据分类模型构建流程
Step4:保留场景并实施正确的控制
需要提出一个全面的业务解决方案来支持 “使用前分类”模式。
- 数据必须在使用前就被良好的分类
- 如果有可能的话,数据应该在创造时就被分类
- 分类级别必须不断调整以反映业务场景的变化
有三个关键活动定义了分类解决方案:

Step5:整体解决方案

参考链接:
https://www.freebuf.com/articles/database/254780.html https://www.alibabacloud.com/help/zh/dataworks/latest/manage-sensitive-field-types https://www.ibm.com/docs/zh/guardium/11.5?topic=discover-sensitive-data https://blog.csdn.net/m0_73803866/article/details/127238102 https://www.secrss.com/articles/11810 https://www.dsmm.org.cn/skin/files/2021-09-15/%E6%95%B0%E6%8D%AE%E5%AE%89%E5%85%A8%E8%83%BD%E5%8A%9B%E5%BB%BA%E8%AE%BE%E5%AE%9E%E6%96%BD%E6%8C%87%E5%8D%97%20V1.0.pdf https://www.esafenet.com/sysjaq https://docs.aws.amazon.com/zh_cn/wellarchitected/latest/framework/sec_data_classification_identify_data.html https://www.leagsoft.com/plan-detail/66
在我国国家政策的大力支持下,大数据应用正在引领各垂直化领域变革,这种趋势下,数据流动将产生越来越多的价值。然而数据的使用也是一把双刃剑,只要数据处于流动的过程中会存在敏感数据泄露的风险。要提高数据的使用价值,避免敏感信息泄露产生的不良后果,这就需要规范和建立敏感信息分级保护机制,并搭建高效的敏感数据安全管理体系。
目前国内敏感信息监控产品大多还将功能定位在特定信息的检查和流通渠道的管控上,尚未形成一套支撑大数据环境下敏感信息综合监管的有效体系。为了更好的保护国家、企业和个人的数据资产,国内的敏感信息监管产品厂商需要对数据状况进行深入研究,特别是数据的类型化、层级化研究,同时应树立起一种意识,那就是敏感信息管理不是简单依靠一套产品就能够解决的,而应该通过产品引导客户建立敏感数据安全管理的理念,形成适用于自身组织特点的数据分级和管控体系,这才是国产敏感信息监管产品今后一个阶段的发展方向。
具体来说,整个敏感信息监管体系应该遵循以下流程建立:
- 1、帮助客户甄别其组织内部的敏感数据
客户所需要管控的敏感信息类型很多,可能涉及个人隐私、企业商业秘密、政府部门甚至国家数据资产,应该在不同客户数据资产类型对数据进行梳理,定义不同敏感信息的类别和级别,进行数据标签化。
以网络运营商此类企业管理的数据类型为例,可能包括网络用户身份相关数据、用户服务内容数据、用户服务衍生数据和运营管理数据等,这些数据根据对第三方价值和泄露后产生的后果可以进行分级,下表是运营商客户数据敏感性分级定义。

针对不同敏感级的数据应该计划采用不同的管控措施。
- 2、从客户信息类型出发,识别与内部、外部敏感客户信息相关的信息系统与部门岗位,绘制敏感信息的分布视图。
识别过程:对被监控端所有文档的编辑工作进行监控,根据策略自动分析文档的敏感性,在发现文档高敏感级甚至是可能涉密的情况下,完成识别。
分级分类过程:对所有检测出的敏感数据,根据之前数据分级分类方法进行级别和类别的归类。
可视化展示:对客户敏感数据进行分类分级的基础上,通过地理分布图或者是网络分布图等方式实现敏感数据分布情况的可视化展示。

- 3、建立起一套切实可行的数据安全管理制度和数据安全监控体系,对数据的全生命周期进行管理

参考链接:
https://www.aqniu.com/tools-tech/52080.html
如有侵权请联系:admin#unsafe.sh