原文标题:A Systematic Evaluation of Static API-Misuse Detectors原文作者:Sven Amann, Hoan Anh Nguyen, Sarah N 2023-5-9 18:51:4 Author: 安全学术圈(查看原文) 阅读量:27 收藏
原文标题:A Systematic Evaluation of Static API-Misuse Detectors
原文作者:Sven Amann, Hoan Anh Nguyen, Sarah Nadi, Tien N. Nguyen, and Mira Mezini
原文链接:https://arxiv.org/pdf/1712.00242.pdf
发表会议:TSE'18
笔记作者:[email protected]安全学术圈
笔记小编:黄诚@安全学术圈
1 研究介绍
应用程序编程接口 (Application Programming Interfaces, API) 通常具有一定的使用规范,例如调用顺序或者是一些调用条件。而 API 误用(misuse)则会导致软件崩溃、错误甚至漏洞。在过去的 20 年,针对 API 误用的检测器有许多,但 API 误用在现在仍然是个很常见的现象,因此针对现有 API 误用检测器的大规模评估十分重要,从而提升技术水平。
而本文的主要工作在于如下几点:
提出 API 误用分类法 MUC,提供了一个概念框架来对比 API 滥用检测器的功能 针对现有的 12 个检测器进行了评估 完成一个针对 API 误用检测器的公开自动化基准测试管道 MUBenchPipe
2 背景知识
由于这是第一次分享关于 API-Misuse 领域的文章,这里简单介绍一下有关的背景知识。
Misuse detector:误用检测器。用于自动化检测一个程序、代码库是否存在误用情况的工具,并且根据使用的技术可进一步分为静态、动态、混合检测器。其中静态误用检测器是本文的研究对象。其主要思想是异常检测(当出现不常用的 API 使用方法时,将其视为误用。但很明显,这样处理可能会存在极大的误报,当使用了罕见的正确 API 时)。
MUBENCH:一个领域的 Benchmark 数据集。该数据集来自论文 MUBench: a benchmark for API-misuse detectors,而这篇论文同样来自与该实验室。该数据集主要来源于是将该领域中 4 个常用数据集、Github、SourceForge 等中的一些数据,共 89 个误用 API。此外,本文在该数据集的基础上,进一步扩展到了 100 个误用。
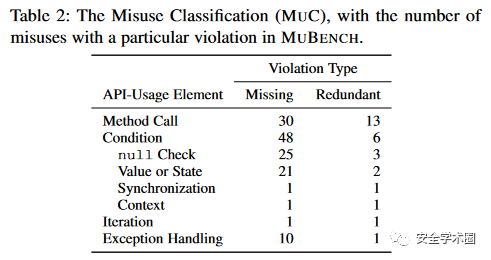
Classification:是本文细化的一个 API 误用类型。他将每个误用实例定义为一对的 API-element 和 Violation Type 构成。由于一个 Misuse 可能包含多种错误,所以总数可能大于本项目所述的 100,如图 1 所示。
API-element 代表误用元素,包括 method calls,conditions,iteration,Exception Handling Violation Type 代表给定的用法约束,包括缺失 (missing) 和冗余 (redundant)
MUBENCHPIPE:本文提出的一个基准测试管道(就是一套自动化脚本程序)。它将整个评估过程自动化,包括目标程序的检索、编译,以及运行检测器并收集返回数据等。
3 模型调查
在对模型的测试和了解后,发现当下这些模型针对 API-Misuse 的类型有限,只有 4 个检测器能够识别缺失的空检查,只有 3 个能够识别缺失迭代,只有 2 个可以识别丢失的异常处理,并且没有任何一个检测器能够识别所有类别。
图 3 中 Target Projects 代表目标项目数量,评估设置如表注所示,Reviewed Finding 和 precision 代表的是对检测器发现的固定误用数目时的精度测量。
4 实验效果
首先,由于不同模型针对的语言类型存在差异,因此本文主要针对 Java API 误用进行测量。经过重重筛选,选择了的 JADET、GROUMINER、TIKANGA 和 DMMC。而在这些工具当中,GROUMINER 需要输入源码,其余的需要输入字节码,因此为了满足输入,本项目选择了同时具有字节码和源码的项目。
Experiment P
精度实验。各个模型对所选的 5 个项目进行 misuse 发现,这里截取的是没个项目的前 20 个发现,但由于有的项目发现不足 20 个,因此图 4 中第一列总数并不为 100。可以看到的是,每个项目的精度很差,最好的不过 11.4%,但具体误报的原因大多是由于 API 不常见、分析不精准(具体可以看下分析情况)等。
Experiment RUB
探测能力实验。评估目标探测器的探测能力,即在假设他们始终挖掘所需模式的前提下,测量其召回率的上限。这里主要是对比经验召回(发现的真正误用占数据集所有误用的比例)和概念召回(模型发现的潜在误用占所有误用的比例)。而对于一个理想的检测器来说,两者应该是相同的。然而我们能看到的是模型的召回均不高。具体原因在于表示方式不精确,模式匹配不精准等。
Experiment R
召回实验。评估探测器的召回率。实验从 64 个误用中进行添加和去除后,剩下 53 个。而模型的召回率均很差。原因在于在模型对 misuse 的排名当中,真正的 misuse 往往排名很靠后,而不是在前 20 当中。(这里没太搞懂和上面的经验召回的区别在哪里?不同点可能在于 RUB 实验提供了正确用法,而 R 并未提供相关参考)
5 个人思考
首先这份工作确实是在静态分析检测器上完成的一个系统化工作,其工作的主要意义在于首先提出了对 API-Misuse 的分类,并且对 Java API 的检测器进行了系统评估,对当前领域的研究现状、误报漏报具体原因进行了分析,有利于后期工作的推进。但也存在部分局限性。
论文很好的总结了当前领域静态检测器的研究现状,但语言仅在 Java 上面做了测试,C 语言的模型也有很多,这个也是可以继续延伸的路径之一
实验的数据论述部分感觉有些不够清晰,有时会添加人工样本,有时会做相关处理,这部分有点没太看懂
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh