一.前言
最近对于虚拟化技术在操作系统研究以及在二进制逆向/漏洞分析上的能力很感兴趣。看雪最近两年的sdc也都有议题和虚拟化相关(只不过出于性能的考虑用的是kvm而不是tcg):
2021年的是"基于Qemu/kvm硬件加速下一代安全对抗平台"
2022年的是"基于硬件虚拟化技术的新一代二进制分析利器"
跨平台模拟执行unicorn框架和qiling框架都是基于qemu的tcg,本文的内容就是描述一下qemu tcg与unicorn的原理。
TCG的英文含义是Tiny Code Generator, Qemu可以在没开启硬件虚拟化支持的时候实现全系统的虚拟化,Qemu结合下面几种技术共同实现虚拟化:
- soft tlb / Softmmu/内存模拟
- 虚拟中断控制器/中断模拟
- 总线/设备模拟
- TCG的CPU模拟
qemu进程代表着一个完整的虚拟机在运行,它没有特殊的权限却能正常的运行各种操作系统如windows/linux等,在没有硬件虚拟化支持的时候靠的最主要的角色就是TCG,它满足了Popek/Goldberg对于虚拟化的三大要求:
- 等价性
- 安全性
- 性能
https://en.wikipedia.org/wiki/Popek_and_Goldberg_virtualization_requirements
后来出现了硬件支持的虚拟化,kvm因此成为主流,在云平台上运行的虚拟化都是有硬件支持的,但是TCG却仍然是不可替代的,因为硬件虚拟化只能在源ISA和目标ISA都相同的情况下才能工作(比如在x86平台虚拟化x86操作系统,或者在arm平台下虚拟化arm操作系统),而如果源ISA和目标ISA不同的情况下如在x86平台运行arm操作系统,只能靠TCG实现。
学习TCG的好处:
- 可以理解像libhoudini.so这样的转码技术是如何实现的
- 对理解应用层的虚拟机如java虚拟机中的jit技术很有帮助
- 可以帮助理解cpu包括整个计算机体系结构是如何工作的
- 可以帮助理解和定制二进制分析框架如unicorn/qiling,因为它们都是基于TCG
- 某些vmp是基于unicorn来实现的,理解TCG可以基于此实现自己的vmp/加深对vmp的理解
二. QEMU TCG
1. DBT
TCG本质上属于DBT,即dynamic binary translation动态二进制转换,相应的还有SBT,即static binary translation静态二进制转换。拿Android平台举例, SBT就相当于ART虚拟机中的AOT(ahead-of-time compilation),而DBT就相当于ART虚拟机中的JIT(Just-In-Time compilation)。
假如想在x86平台运行arm程序,称arm为source ISA, 而x86为target ISA, 在虚拟化的角度来说arm就是Guest, x86为Host。
最简单的解决方案是实现一个解释器,在一个循环中不断的读入arm程序指令,反汇编并用代码去模拟指令的执行。但是解释器的问题在于性能太低,后来就出来了DBT技术(QEMU也有解释器模块,具体搜索CONFIG_TCG_INTERPRETER),它也需要读入arm程序指令并进行反汇编,不过接下来流程会进入即时编译环节,将arm指令转换成x86指令,最终执行的时候会直接跳转到转换过的x86指令执行,得到媲美于本地执行的性能。
DBT和JIT这两个名词经常可以互换使用,不过我的理解是JIT环境中的输入是特意被设计过的可被模拟的指令格式(更多的是高层虚拟机如java虚拟机中的字节码),而DBT的输入则是不同平台的ISA指令。
对于虚拟化来说,可以采用SBT将Guest代码事先编译好然后直接运行吗? 对于模拟某些ISA如x86来说会遇到问题,因为x86的指令是不定长的,和反汇编器会遇到的问题一样,有时候是无法准确区分出哪些是数据哪些是指令,当遇到一些运行时才知道目标的跳转指令,SBT技术会遇到问题。这种问题被称为Code-Discovery Problem。
而DBT则不会有此问题,以下称source ISA中的pc指针为SPC, target ISA中的pc指针为TPC, 对于模拟一个arm系统来说,arm系统刚上电cpu会从物理地址0从开始执行,此时SPC=0, 假设此处的指令为"mov r0, #0", 而经过DBT转换以后,转换的代码位于Qemu进程的虚拟地址0x7fbdd0000100处,此时的TPC=0x7fbdd0000100, 转换后的指令为x86指令
"movl $0, (%rbp)",DBT技术中会实时记录SPC与TPC的关系,遇到跳转指令的时候可以得到跳转指令的目标地址,因此不会有SBT中的问题。
2.QEMU IR
类似于LLVM,QEMU也定义有自己的IR:
https://www.qemu.org/docs/master/devel/tcg-ops.html
转换过程如下:

引入IR的好处自然是当引入一种新的source ISA的时候,只需要完成source binary code到IR的转换,IR到target binary code直接用现成的即可。
从上面QEMU IR的链接中可知,QEMU IR的指令主要分为函数调用指令、跳转指令、算术指令、逻辑指令、条件移动指令、类型转换指令、加载/存储指令等构成,那么问题来了,仅靠固定的IR是无法模拟所有的ISA指令的,比如x86架构的cpuid指令并没有与之对应的IR,遇到这种指令如何生成对应的IR?
这就涉及到执行上下文的概念,QEMU本身是Host上一个普通的进程,运行在QEMU上下文,而执行转换后的目标代码则运行在虚拟机上下文,当运行在虚拟机上下文的程序遇到一些条件时会退出至QEMU上下文处理,像在arm平台执行cpuid指令就是这种情况,需要生成IR调用QEMU中的helper函数来模拟cpuid指令,模拟完了再回退到虚拟机上下文去执行。每个体系结构对应的helper函数在target/xxx/helper.h头文件中定义。
include/tcg/tcg-op.h文件声明了在实现一个生成IR的前端时可以调用的一些函数,这些函数以tcggen开头。
3.Basic Block/Translation Block
TCG的二进制转换是以块为基本单元,即Basic Block,当Guest指令遇到下面几种情况时会被分割成一个Basic Block:
- 遇到分支指令
- 遇到系统调用
- 达到页边界/最大长度限制
而TranslationBlock是QEMU中用来表示转换过的Host指令的数据结构(以下简称TB),执行时的基本控制流程如下:

QEMU TCG Engine运行在QEMU上下文,当一个Basic Block被转换成Tranlated Block以后,QEMU可以直接跳转过去以虚拟化上下文去执行,这种跳转是以函数调用的形式来实现的,因此还需要执行一些prologue"前言"代码来保存函数调用时的信息,需要切换回TCG上下文时需要执行一些epilogue"序言"代码来恢复函数调用前的信息。
拿x86_64平台举例,每次执行上下文切换需要执行大约20条指令(指令还会进行内存的读写),因此DBT的优化措施之一就是减少上下文切换,实现TB之间的直接链接,这种优化措施称为Direct block chaining:

这种优化措施可以显著的增加性能,但是这种优化方式还需要解决自修改代码引发的问题,在收到硬件中断时还需要快速的返回至QEMU上下文处理,等后面具体分析代码的时候会描述。
不过chained tb有一个限制: 两个chained tb对应的guest指令需要在同一个guest的page里。
将指令分割为Basic Block的一个主要原因是TB的缓存机制,当一个Basic Block被DBT转换为TB以后,下次再执行到相同的Basic Block直接从缓存中获取TB执行即可,无需再经过转换:

4.代码环境
以x86_64平台上运行一段arm程序做为研究对象,使用的QEMU源码分支为stable-8.0。
需要准备三个文件startup.s, test.c,test.ld:
startup.s文件内容:
1 2 3 4 5 |
|
test.c文件内容:
1 2 3 4 5 6 7 8 9 10 |
|
test.ld文件内容:
1 2 3 4 5 6 7 8 9 10 11 12 |
|
编译:
1 2 3 4 |
|
以上代码的用途是往串口0x101f1000处写入Hello World,代码的链接地址为0x10000,它期望被加载到物理内存的地址也是0x10000,很多arm机器将内核加载至此。
启动:
1 |
|
会在屏幕上打印出Hello World!,此时退出QEMU的快捷键为Ctrl+A X
qemu-system-arm程序是由QEMU源码编译出来的,-M versatilepb表示模拟的arm硬件为versatilepb(Arm Versatile boards),-m 128参数表示指定的机器内存为128M, -kernel参数为QEMU的Direct Linux Boot机制,由QEMU而不是磁盘上的Bootloade来将内核加载至内存。这种情况下启动,arm会从物理地址0开始执行,事实上0地址处是qemu实现的一小段bootloader,只是用来将控制跳转到0x10000内核处执行(test.bin),代码在hw/arm/boot.c文件中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
5.打印出TCG转换的文件
从qemu 7.1开始反汇编引擎已经替换为Capstone,因此需要安装capstone:
1 |
|
qemu提供了一些调试手段可以显示出TCG转换过程的内容:
1 2 3 4 5 |
|
in_asm.txt为arm反汇编程序的结果
op.txt为生成的IR指令的内容
out_asm为转换后的Host指令的内容
分析TCG的时候,由于它拥有全系统虚拟化的能力,因此需要思考如下几种情况是如何实现的:
- 普通算术逻辑运算指令如何更新Host体系结构相关寄存器
- 内存读写如何处理
- 分支指令(条件跳转、非条件跳转、返回指令)
- 目标机器没有的指令、特权指令、敏感指令
- 非普通内存读写如设备寄存器访问MMIO
- 指令执行出现了同步异常如何处理(如系统调用)
- 硬件中断如何处理
6.TCG相关数据结构
qemu中一个tcg线程可以模拟多个vcpu,也可以多个tcg线程每个对应模拟一个vcpu,后者称为Multi-Threaded TCG (MTTCG),是否为MTTCG由全局变量bool mttcg_enabled决定。对于此处的示例MTTCG是开启状态,不过简单起见这里假设机器只有一个vcpu。
先来看一下TCG的一些重要数据结构:
TranslationBlock:
顾名思义,存放编译后的TB相关信息,包括指向目标机器执行码的指针CPUArchState:
由于是模拟的cpu,因此存放着体系结构的cpu信息,比如对于arm平台它定义在target/arm/cpu.h文件中,成员包括所有通用寄存器以及状态码等模拟cpu硬件所必需的信息。- TCGContext:
存放tcg中间存储数据的结构体,包括转换后的IR, tcg的核心就是围绕此结构展开,前端IR以TCGOp列表的形式存放在TCGContext的ops对象中 - TCGTemp:
对应于tcg IR中的变量,存放在TCGContext的temps数组中,变量有几种不同的作用域类型tcg_temp_new_internal分配TEMP_EBB, TEMP_TB类型的TCGTemp变量tcg_global_alloc分配TEMP_GLOBAL类型的TCGTemp变量tcg_global_reg_new_internal分配TEMP_FIXED类型的TCGTemp变量tcg_constant_internal分配TEMP_CONST类型的TCGTemp变量
TCPTemp每个类型的含义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
那么编译后的Host代码存放在哪里?先看一下这幅图:

在qemu启动的早期会执行一个函数叫tcg_init_machine
在这个函数中会调用qemu_memfd_create()函数创建出一个匿名文件,该匿名文件的大小是根据当前Host机器的物理内存计算出来的,比如我的电脑是64G,最终计算出来的匿名文件大小为1G。
然后对匿名文件做两次映射,一次映射为读写:(PROT_READ | PROT_WRITE),称之为buf_rw。
一次映射为写执行(PROT_READ | PROT_EXEC),称之为buf_rx, buf_rw和buf_rx之间的差值由全局变量tcg_splitwx_diff表示。
tcg在翻译代码的过程中会利用buf_rw写这1G的空间,而执行的过程中则依赖于buf_rx在这1G的空间中执行代码。由于buf_rw和buf_rx映射的是同一个文件且指定了MAP_SHARED参数,因此对buf_rw做出的修改会在buf_rx的空间可见。
tcg_init_machine函数还会调用tcg_target_qemu_prologue函数创建出对应于Host的prologue和epilogue,并且分别由全局变量tcg_qemu_tb_exec和tcg_code_gen_epilogue指向(如上图)。
对于Host为x86_64来说,它的prologue如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
它的epilogue如下:
1 2 3 4 5 6 7 8 9 10 11 |
|
假设现在正在翻译第一个TB,TranslationBlock结构也是在1G的空间内分配,第一个TB紧接着epilogue,并且分配了TB以后TCGContext的code_gen_ptr将会指向TB的末端,该TB对应的Host机器码地址存放在TranslationBlock.tc.ptr中,属于buf_rx空间。
而buf_rw空间中TB对应的Host机器码的开头由TCGContext的code_buf指向,末端由TCGContext的code_ptr指向,两者之差则为机器码的长度。需要翻译第二个TB时,第二个TranslationBlock结构则会在TCGContext.code_ptr的后面再分配,TCGContext的code_buf和code_ptr则再指向第二个TB对应的Host机器码的开头和末端,此时TCGContext的code_gen_ptr则再更新为第二个TB末端的位置。
如何执行编译后的代码?直接执行tcg_qemu_tb_exec()函数即可,该函数接受两个参数,第一个参数为CPUArchState,第二个参数为TranslationBlock.tc.ptr,因此TB执行逻辑为:
- prologue
- TranslationBlock.tc.ptr
- epilogue
如果做了Direct block chaining优化则不会再有epilogue,会跳转到下一个TB执行。
7.tcg执行流程
tcg线程始于mttcg_cpu_thread_fn,执行流程为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
主要执行函数在cpu_exec_loop中,它的执行过程为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
tcg_gen_code在生成Host代码之前还会基于当前的IR做一些优化。优化函数有tcg_optimize, reachable_code_pass,liveness_pass_0,liveness_pass_1,liveness_pass_2等。
8.普通算术逻辑运算指令如何更新Host体系结构相关寄存器
对于一条Guest指令来说,tcg的处理是将它翻译为语义等价的多条IR(称为微码),比如in_asm.txt文件中显示出0地址处的arm指令为:
1 |
|
它编译为微码IR的结果为:
1 2 3 |
|
loc5这种变量为tcg的TCGTemp,而r0则对应着arm的r0寄存器,因此tcg的IR其实并非和llvm中的IR那样和平台完全无关,它是和平台相关的。
这种翻译方式的优点是可以避免处理不同指令集的复杂性,但是缺点是以性能为代价(通常减慢 5-10 倍)。
再来看一下这条指令:
1 |
|
它对应的IR:
1 2 3 4 5 |
|
因此通过组合微码以及结合qemu的helper函数,可以将Guest的所有指令都编译为语义等价的IR,在微码的基础上进行一些优化以后再根据微码一条一条的翻译成Host指令。
DBT需要解决的一个问题是如何进行state mapping状态绑定,拿0x00000000处的指令举例,这条指令将r0寄存器的值赋给0,当执行完编译过的Host指令以后,需要相应的在某个状态中记录下r0寄存器值为0,如果Host的寄存器数量很多,完全可以选一个x86_64寄存器作为arm中r0寄存器的对应物(寄存器绑定),否则就需要保存在内存中了。
对于tcg来说有个特殊的寄存器叫TCG_AREG0,它表示用哪个Host寄存器来指向Guest体系结构的CPUArchState,对于x86_64来说TCG_AREG0为%rbp(对于arm来说TCG_AREG0为r6寄存器),也就是说通过rbp寄存器可以找到arm的CPUArchState。qemu中有专门的TEMP_FIXED类型的TCGTemp用于表示TCG_AREG0:
1 2 |
|
cpu_env在IR中被使用的话,在生成Host代码阶段对于x86_64来说将会绑定到rbp寄存器。
事实上qemu中一共只有两个TEMP_FIXED类型的TCGTemp,一个叫env,一个叫_frame。
来看一下CPUArchState的通用寄存器成员为
因此arm指令
1 |
|
对应编译过的x86_64代码如下:
1 |
|
同样的对于这条arm指令它最终改变了r2:
对应编译过的x86_64代码如下:
1 |
|
当然如果在一个TB内如果每遇到一个指令改变了寄存器都要写入x86_64的rbp对应的内存地址是非常慢的,tcg有个优化措施是可以在TB结束之前只执行一次更新操作从而减少写内存的操作。
因此通过TCG_AREG0寄存器,x86_64指令在执行的时候可以找到CPUArchState结构从而更新所有Guest体系结构的CPU状态。
9. 内存读写如何处理
对于qemu来说读写内存涉及到内存模拟模块,qemu还模拟了tlb,因此读写一块arm的虚拟内存地址(Guest Virtual Address -> GVA)首先会查询tlb,如果tlb不命中的话会走tlb慢路径。tlb慢路径要经由guest的mmu经页表转换为物理内存地址(Guest Physics Address -> GPA),再经过qemu内存管理模块转换为qemu进程的虚拟地址(Host Virtual Address -> HVA)。
那么读写GVA的arm指令编译成X86_64指令就是读写对应的HVA即可。
tlb相应的数据结构在include/exec/cpu-defs.h文件中定义,其中结构体CPUTLB由ArchCPU中的CPUNegativeOffsetState neg所引用。
TLB命中时对应CPUTLBEntry对象的addend + GVA = HVA。
CPUTLBEntry对象的addr_read, addr_write, addr_code分别对应着读写执行指令的地址,地址的构成部分注释中有描述:
1 2 3 4 5 6 |
|
以如下指令举例:
1 |
|
它对应的IR为:
1 2 3 4 5 |
|
上面最主要的是qemu_ld_i32这条IR,loc9的值为GVA,qemu_ld_i32则将loc9地址处的内存加载至loc8变量中并最终赋值给r1寄存器。
qemu_ld_i32这条IR它对应的x86_64代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 |
|
乍一看相当复杂的不知道在做什么,其实上面执行的逻辑是创建出调用qemu tlb的环境,先去tlb查询是否有对应的HVA,如果没有的话会生成一段tlb slow path的代码并跳转到tlb slow path去执行。生成这段x86_64的代码位于tcg/i386/tcg-target.c.inc文件的tcg_out_qemu_ld函数。
一条条来解释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
生成tlb slow path的代码在tcg/tcg.c文件的tcg_gen_code函数中的:
1 2 3 4 5 6 7 |
|
tlb slow path的代码位于每个TB的尾端:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
helper_le_ldul_mmu还会再检测一次tlb是否命中,如果不命中将会调用体系结构相关函数做下一步的处理。
事实上会先访问快速路径,再访问victim tlb, victim tlb机制见:
https://patchwork.ozlabs.org/project/qemu-devel/patch/[email protected]/
1 2 3 4 5 6 7 8 9 10 11 12 |
|
10.分支指令(条件跳转、非条件跳转、返回指令)
这条指令会间接的改变pc的值从而产生跳转(从而终结当前TB)
1 |
|
一个TB终结以后怎么执行有两种可能:
- 直接执行下一个TB
- 回到qemu上下文继续编译执行
它的IR如下:
1 2 3 4 5 6 7 8 9 10 11 |
|
再来具体看一下如下两条IR:
1 2 |
|
那么call lookup_tb_ptr后面的参数是什么含义?具体可以参考tcg/tcg.c文件的tcg_dump_ops函数:
- lookup_tb_ptr为TCGOp对象所对应的TCGHelperInfo对象的name字段
- $0x6为TCGOp对象所对应的TCGHelperInfo对象的flags字段
- $1为TCGOp对象的param2成员,即nb_oargs, 表示输出参数的个数为1
- tmp12为op->args[]中输出参数的字符串表示
- env为op->args[]中输入参数的字符串表示
因此lookup_tb_ptr这个helper函数输入参数个数就是1,即为CPUArchState env, 输出参数为tmp12,然后goto_ptr tmp12就跳转至此地址处从而终结当前TB。
这段IR对应的x86_64 target代码为:
1 2 3 4 |
|
lookup_tb_ptr函数的功能属于tcg相关,因此它的实现位于accel/tcg/cpu-exec.c:
1 |
|
需要跳转的目标地址在env结构的pc成员中,这个函数中会通过hash表查询是否有目标TranslationBlock的缓存。如果有则跳转至TranslationBlock.tc.ptr执行即可(即下一个),如果没有则跳转至tcg_code_gen_epilogue执行。
tcg_code_gen_epilogue指向了tcg的epilogue处,因此如果跳转至tcg_code_gen_epilogue执行最终结果是tcg_qemu_tb_exec(env, tb_ptr)函数返回,从而回到了qemu tcg上下文处进行下一个TB的转换执行。
综上所述这种跳转指令会生成helper函数lookup_tb_ptr,它要么成功找到下一个TB的地址并跳转过去执行要么返回qemu tcg上下文执行。
再看一下另外一种跳转指令:
1 |
|
bl这条指令首先需要反汇编, 会进入到libqemu-arm-softmmu.fa.p/decode-a32.c.inc文件的disas_a32_extract_branch函数,a->imm为pc相对跳转的偏移值。
然后需要转换成IR,对应的函数为target/arm/tcg/translate.c文件的trans_BL函数。
转换以后对应的IR为:
1 2 3 4 5 6 7 8 |
|
这种跳转和上面的跳转不同的是goto_tb $0x0以及exit_tb
在这个jmp_diff函数中还可以看到对arm来说pc真正的值为当前执行指令在arm模式下+8,在thumb模式下是+4:
1 2 3 4 |
|
goto_tb $0x0对应的目标代码如下:
1 2 |
|
它由tcg/i386/tcg-target.c.inc文件中的tcg_out_goto_tb函数生成:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
这个函数除了生成jmp指令跳转到下一条指令外还执行了如下两个函数,作用如下:
1 2 |
|
exit_tb 0x7f666c000280对应的目标代码为:
1 2 3 4 5 |
|

因此总结起来goto_tb $0x0和exit_tb 0x7f666c000280的作用是:
- 设置当前TB的jmp_insn_offset[0]和jmp_reset_offset[0]
- 将当前TB在buf_rx处的指针(0x7f666c000280)赋值给%rax
- 跳转至TB epilogue处即从tcg_qemu_tb_exec(env, tb_ptr)函数处返回
从tcg_qemu_tb_exec(env, tb_ptr)函数处返回以后接着处理下一个TB,因此当前TB就变成了last_tb,返回到cpu_exec_loop函数中执行如下逻辑:
1 2 3 |
|
最终tb_add_jump的逻辑为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
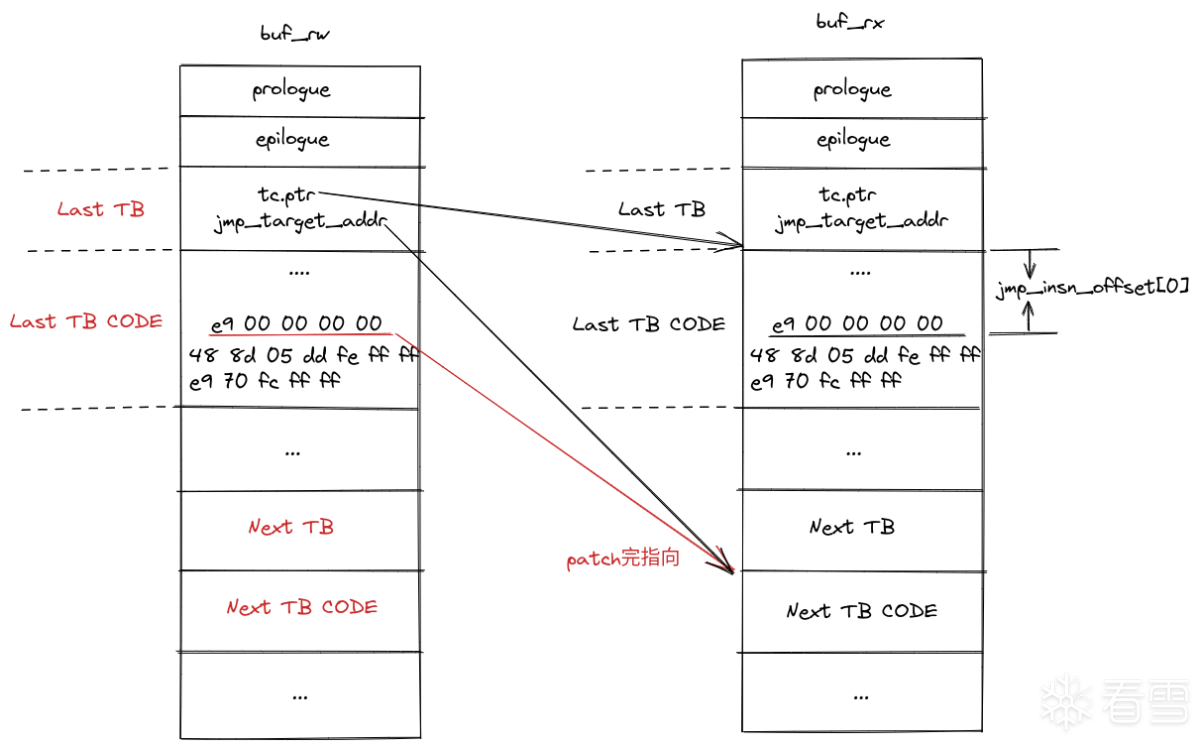
用图来表示是这样的效果:

对内存的修改发生在buf_rw区域,而执行代码则位于buf_rx区域,两个区域是镜像关系。
先看buf_rw区域,需要对Last TB CODE中的"e9 00 00 00 00"进行patch让它指向Next TB CODE,这样下次再执行Last TB CODE时"e9 xx xx xx xx"处将会直接跳转到Next TB CODE处执行,无需再退出至qemu上下文。这个就叫Direct block chaining优化。
上面看到jmp_insn_offset[0]指向的是需要patch的指令在code区域的偏移,而jmp_reset_offset[0]则指向了需要patch指令的下一条指令,当需要断开当前TB与下一条TB的Direct block chaining链接时,再执行patch,目标是jmp_reset_offset[0]即可恢复当前TB的跳转。
Direct block chaining还需要解决的一个问题是自修改代码,即当代码会对代码区域作修改时,这个代码区域之前旧的翻译指令不再有效,它和其他TB之间的链接也可能不再有效。
tcg针对自修改代码也做了处理,结合着soft mmu的机制,当产生自修改代码时会调用do_tb_phys_invalidate函数从而重置TB的一些状态,其中就包括它所链接到其他TB的状态。
11.目标机器没有的指令、特权指令、敏感指令
前面提到过,tcg需要依赖于Guest的helper函数来模拟各种Guest的特殊指令,每个体系结构对应的helper函数在target/xxx/helper.h头文件中声明。
所有helpers的数组结构如下:
1 2 3 4 |
|
比如对于arm的除法指令udiv,在x86_64平台是没有的,最终调用target/arm/helper.c文件udiv函数:
1 2 3 4 5 6 7 8 |
|
比如x86中的cpuid指令, arm平台是没有的,最终调用的函数为:
1 2 3 4 5 6 7 8 9 10 11 |
|
其他的特权指令敏感指令同理。
12.非普通内存读写如设备寄存器访问MMIO
某些内存地址指向的并不是ram,而是设备的寄存器,这种内存地址叫MMIO,tcg必须正确处理这种内存地址访问,当访问MMIO时将与模拟设备进行通信。
这一块涉及到qemu的内存模块MemoryRegion和AddressSpace,是相当复杂的概念,限于篇幅不再描述,只需要知道tcg会生成访问内存的helper函数如helper_le_stl_mmu,然后进入到qemu的内存模块做下一步的处理。
13.指令执行出现了同步异常如何处理(如系统调用)
真实的cpu在执行的过程中会遇到异常和中断,既然是模拟cpu,tcg也需要处理好异常和中断,先以同步异常系统调用举例,其实它是通过长跳转来直接跳出tcg执行循环的,如下面的指令
1 |
|
tcg解析到这条指令的时候会进入到trans_SVC函数.将DisasContextBase的is_jmp设置为DISAS_SWI表示当前tb的终结。
随后退出到tb循环中执行arm_tr_tb_stop函数进入DISAS_SWI分支:
1 2 |
|
生成对应的IR为:
1 2 |
|
最终在执行目标代码时会调用的函数为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
cpu_loop_exit代码如下:
1 2 3 4 5 6 7 8 |
|
最终会退出当前cpu的执行循环进入异常的处理过程:
1 2 3 4 5 6 7 8 |
|
cpu_handle_exception函数通过调用cc->tcg_ops->do_interrupt(cpu)进入最终的异常处理,从而调用到target/arm/helper.c文件中的函数:
1 |
|
也就是通过vbar寄存器(Vector Base Address Register)计算出异常处理函数的地址newpc, 并且通过take_aarch32_exception函数将pc置为异常处理函数地址并跳转过去执行:
1 |
|
因此可以看到对于系统调用来说始终没有跳出tcg线程,因为系统调用为同步异常。
14.硬件中断如何处理
硬件中断属于异步事件,对于真实的cpu来说,它会在执行每条指令以后检查中断引脚的信号判断是否有外部中断产生。对于tcg来说显然粒度做不到这么细,因为这么做性能太低了,但又必须能够及时响应外部中断。
外部硬件中断发生在IO线程,发生硬件中断时会经由平台的模拟中断控制器一堆复杂的逻辑以后最终调用如下函数通知vcpu:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
当把cpu->icount_decr_ptr->u16.high置为-1时就是告诉tcg线程中正在执行的tb尽快退出,回到qemu上下文进行外部中断的处理。icount_decr_ptr还涉及到qemu的一个特性叫TCG Instruction Counting:
https://qemu.readthedocs.io/en/latest/devel/tcg-icount.html
为了让TB执行的时候可以快速响应退出的指令,tcg在每个TB的开头和结尾生成了如下代码:
1 2 3 4 5 6 7 8 |
|
因此tcg对硬件中断的响应是以TB为粒度。
退出执行循环以后会进入
1 |
|
处理中断,下面的代码就是和qemu硬件模拟相关的代码,不再细述。
三.unicorn原理分析
unicorn是基于qemu tcg的,但qemu tcg还是太复杂了,它模拟的是一个完整的系统,unicorn只需要模拟执行一个可执行文件甚至一段代码片段,因此unicorn中的tcg可以说是轻量级的tcg,这也是unicorn被称为cpu模拟器的原因。
unicorn的特点:
- 只保留qemu tcg cpu模拟器的部分,移除掉其他如device,rom/bios等和系统模拟相关的代码
- 尽量维持qemu cpu模拟器部分不变,这样才容易和上游的qemu tcg代码同步
- 重构tcg的代码从而可以更好的实现线程安全性及同时运行多个unicorn实例
- qemu tcg并非一个Instrumentation框架,而unicorn的目标是实现一个有多种语言绑定的Instrumentation框架,可以在多个级别跟踪代码的运行并执行设置好的回调函数。
因此unicorn的研究重点就在于研究它如何提供在指令级别、内存访问级别的dynamic Instrumentation。
unicorn不仅实现了cpu模拟,还需要实现内存模拟,因此让unicorn能运行起来还需要设置内存映射。
unicorn使用qemu的tcg做为cpu模拟的实现,使用tlb/softmmu/MemoryRegion做为内存模拟的实现。
设置内存映射以c语言的设置为例:
1 |
|
这段代码设置了code_start到code_len之间的区域为虚拟cpu所使用的虚拟地址空间,由于unicorn中并没有相应的操作系统代码来设置页表开启mmu,因此unicorn中的mmu并没有开启:
1 2 |
|
在unicorn中虚拟地址(GVA)就等于物理地址(GPA)。
调用uc_mem_map函数设置内存映射,本质是创建出一个MemoryRegion对象,初始化这个对象并添加到system_memory这个全局的MemoryRegion树层次结构中,这里涉及到qemu中的内存对象AddressSpace,MemoryRegion,FlatView和RAMBlock。这块的机制相当复杂,描述它就得需要一两篇博客的篇幅,这里只是简单介绍一下概念:
- AddressSpace是全局的内存视图,它被每个体系结构的cpu结构引用, 它的成员MemoryRegion *root引用根MemoryRegion所表示的MemoryRegion树
- 多个MemoryRegion组成了一个树结构,MemoryRegion它可以表示ram,rom,MMIO等多种类型的内存设备,可以认为MemoryRegion是Guest物理内存设备的表示
- MemoryRegion如果对应着ram内存设备,它的RAMBlock ram_block成员就表示Host一侧分配出来的虚拟地址空间,所有的RAMBlock被存放在RAMList表示的列表中
- MemoryRegion是树结构,它的平坦化线性模型由FlatView对象表示
设置好内存映射,初始化相应的数据结构以后,unicorn就可以设置寄存器,设置好hook回调并且启动unicorn引擎:
1 2 3 4 |
|
1.UC_HOOK_CODE:
unicorn的Hook类型有很多种,一个一个来看,首先是UC_HOOK_CODE类型,它可以设置回调在每条指令执行前调用。
当调用了uc_hook_add函数以后,其实是创建出了struct hook对象并添加到了uc_struct这个全局对象的struct list hook[UC_HOOK_MAX]链表中去,unicorn其实是在IR层添加了相应的代码来设置回调,比如对于
这么一条简单的指令,如果设置了uc_hook_add(uc, &hook, UC_HOOK_CODE, my_callback,&count, 1, 0), 调试打印OPCode:
1 |
|
打印出的IR是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 |
|
第1条到第6条是unicorn添加的用于hook的IR,产生这些IR的代码位于反编译Guest指令之前,对于arm来说就是disas_arm_insn函数中:
1 2 3 4 5 6 7 8 9 |
|
gen_uc_tracecode的逻辑就是创建出调用hookcode_4_55e38928e9a9这个helper函数的IR,这个helper函数的实现就是设置进来的回调函数,它是动态被创建出来并且添加到helper函数的hashtable中的。
代码解读如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
2.UC_HOOK_INSN:
UC_HOOK_INSN回调和UC_HOOK_CODE的回调原理差不多,只不过它可以用于跟踪某些特定指定的执行。比如当追踪x86的inb指令时,当执行到cpu_inb这个helper函数时就会调用回调:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
3.UC_HOOK_BLOCK
UC_HOOK_BLOCK用于跟踪basic block的执行,因此最好的跟踪点是一个basic block在处理之前:qemu/accel/tcg/translator.c的translator_loop函数for循环开始处:
1 2 3 4 5 |
|
用于生成IR的函数仍然是gen_uc_tracecode函数
4.UC_HOOKMEM开头的
以UC_HOOKMEM开头跟踪的是没有映射的内存读写执行、正常的内存读写执行以及和权限相关的内存读写执行。
前面在分析qemu tcg的时候我们可以看到内存读写会先检查tlb是否命中,如果不命中则会调用tlb helper函数走mmu并查找相应的HVA这条路,和内存加载相关的helper函数是load_helper(), 和内存存储相关的helper函数是store_helper()。
那么在这两个函数中添加代码去调用unicorn回调函数不就可以达到跟踪内存访问的目的了吗?
unicorn也正是这么做的,不过如果tlb命中了就不会调用tlb helper函数怎么办?unicorn的解决方案是判断如果有hook mem的回调函数,强制让流程执行tlb slow path:
1 2 3 4 5 6 7 |
|
这样一改所有内存读写都会走load_helper()和store_helper()。
unicorn为了快速判断哪些内存访问属于"UNMAPPED"访问,在uc_struct结构中的MemoryRegion **mapped_blocks成员中存放当前所有设置过内存映射的MemoryRegion区域,给定一个地址,调用如下函数可以快速得到对应的MemoryRegion:
1 |
|
如果获取到的对象为null则表示该内存访问属于"UNMAPPED"访问,从而调用相应的UC_HOOK_MEM_WRITE_UNMAPPED等回调。
5.UC_HOOK_INTR
由于unicorn没有设备模拟的功能,因此UC_HOOK_INTR无法监听硬件中断,只能监听同步异常如系统调用,前面在分析tcg功能的时候提到cpu_handle_exception函数是tcg处理同步异常的地方,unicorn也是在这里处理UC_HOOK_INTR回调的:
1 2 3 4 5 6 7 8 |
|
6.UC_HOOK_INSN_INVALID
对应着非法指令异常,对于arm来说,qemu/target/arm/translate.c文件用于反汇编arm指令,当遇到非法指令时会调用unallocated_encoding()函数引发非法指令异常,该异常号由EXCP_UDEF表示,然后arm_stop_interrput函数判断是否为非法指令异常:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
如果是非法指令异常则在cpu_handle_exception函数中调用非法指令异常的回调函数:
1 2 3 4 5 6 7 8 9 |
|
四.总结:
理解了qemu tcg的机制以后再去理解unicorn的功能就比较容易了,限于篇幅还有一些内容没有描述清楚,欢迎大家一起交流、讨论。
最后于 35分钟前 被飞翔的猫咪编辑 ,原因:
如有侵权请联系:admin#unsafe.sh