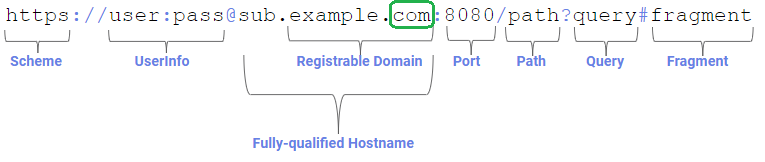
The Top Level Domain (TLD) is the rightmost label in a fully-qualified domain name:The m 2023-5-13 22:50:54 Author: textslashplain.com(查看原文) 阅读量:45 收藏
The Top Level Domain (TLD) is the rightmost label in a fully-qualified domain name:

The most common label you’ll see is com, but you may be surprised to learn that there are 1479 registered TLDs today. This list can be subdivided into categories:
- Generic TLDs (gTLD) like
.com - Country Code TLDs (ccTLDs) like
.uk, each of which is controlled by specific countries - Sponsored TLDs (sTLDs) like
.museumwhich are designed to represent a particular community - … and a few of more esoteric types
Some TLD owners will rent domain names under the TLD to any buyer (e.g. anyone can register a .com site), while others impose restrictions:
- a ccTLD might require that a registrant have citizenship or a business nexus within their country to register a domain in their namespace; e.g. to get a domain with the
.ieccTLD, you have to prove Irish citizenship - a sTLD may require that the registrant meet some other criteria; e.g. to register within the
.bankTLD, you must hold an active banking license and meet other criteria
ZIP and MOV
Recently, there’s been some excitement about the relatively-new .ZIP and .MOV top-level domains.
Why?
Because the characters .zip and .mov also represent longstanding file extensions used to represent ZIP Archives and video files, respectively.
The argument goes that introducing .zip and .mov TLDs means that there’s now ambiguity: if a human or code encounters the string "example.zip", is that just a file’s name, or a bare hostname?
Alert readers might immediately note: “Hey, that’s also true of .com, the most popular TLD– COM files have existed since the 1970s!” That’s true, as far as it goes, but it is fair to say that .com files are rarely seen by users anymore: on Windows, .com has mostly been supplanted by .exe except in some exotic situations.
Thanks to the popularity of the TLD, most people hearing dotcom are going to think “website” not “application”.
Okay, so what’s the badness that could result?
Automatic Hyperlinking
In poking the Twitter community, the top threat that folks have identified is concern about automatic hyperlinkers: If an author types a filename string into an email, or their blog editor, or Twitter, etc, it might be misinterpreted as a URL and automatically converted into one. Subsequently, readers might see the automatically-generated link, and click it under the belief that the author intended to include it as a URL.
This isn’t a purely new concern– for instance, folks talking about the ASP.NET platform encounter this issue all the time, but that’s a fairly constrained scenario, and the https://asp.net website is already owned by the developers of ASP.NET, so there’s no harm.
In contrast, what if I sent an email to my family saying, “hey, check out VacationPhotos.zip” with a ZIP file of that name attached to my email. My email editor might automatically turn my text, VacationPhotos.zip, into a link to https://VacationPhotos.zip/.
I concede that this is absolutely possible, however, it does not seem terribly exciting as an attack vector, and I remain unconvinced that normal humans routinely type filename extensions in this sort of communication.
Having said that, I would agree that it probably makes sense to exclude .mov and .zip from automatic hyperlinkers. Many (if not most) such hyperlinkers do not automatically link any string that contains any of the 1479 of the current TLDs, and I don’t think introducing autolinking for these two should be a priority for them either.
(As an aside, if I was talking to an author of an automatic hyperlinker library, my primary concern would be the fact that almost all such libraries convert example.com into a non-secure reference to http://example.com instead of a secure https://example.com URL.)
User Confusion
Another argument goes that URLs are already exceedingly confusing, and by introducing a popular file extension as a TLD, they might become more so.
I do not find this argument compelling.
URLs are already incredibly subtle, and relying on users to mentally parse them correctly is a losing game. There’s no requirement that a URL contain a filename at all. Even before the introduction of the ZIP TLD, it was already possible to include the characters “.zip” in the Scheme, UserInfo, Hostname, Path, Filename, QueryString, and Fragment components of a URL. The fact that a fully-qualified hostname can now end with this string does not seem very interesting.
General Skepticism
Finally, there’s a general skepticism around the introduction of new TLDs, with pundits proclaiming that they simply represent an unnecessary “money grab” on the part of ICANN (because the fees to get an official TLD are significant).
“Why do we even need these?” pundits protest, sometimes making an argument that boils down to “.com ought to be enough for anybody.”
This does not feel like a compelling argument for a number of reasons:
- COM was intended for “commercial entities”, and many domain owners are not commercial at all
- COM is written in English, a language not spoken by many of the world’s population
- The legacy COM/NET/ORG namespace is very crowded, and name collisions are common. For example, one of my favorite image editors is
Paint.Net, but that domain name was, until recently, owned by a paint manufacturer. Now it’s “parked” while the owner tries to sell it for likely thousands of dollars.
Other pundits make a slightly more constrained argument: “Fine, new gTLDs are generally okay, but these two specifically seem unnecessarily confusing.” That’s a reasonable conversation to have.
Some pundits argue “Hey, domains under these new TLDs are often disproportionately malicious”, pointing at .xyz as an example.
That tracks, insofar as the biggest companies tend to stick to the most common TLDs. However, the vast majority of malicious registrations under non-.COM TLDs don’t happen because getting a domain in a newer TLD is “easier” or subject to fewer checks or anything of that sort. If anything, new TLDs are likely to have more stringent registration requirements than a legacy TLD.
New TLDs Represent New, More Secure Opportunities
One very cool thing about the introduction of a new TLD is that it gives the registrar the ability to introduce new requirements of the registrants without the fear of breaking legacy usage.
In particular, a common case is HSTS Preloading: a TLD owner can add the TLD to the browser’s HSTS preload list, such that every link to every URL within that TLD’s namespace is automatically HTTPS, even if someone (a human or an automatic hyperlinker) explicitly specified a http:// prefix.
There are now 40 such TLDs: android, app, bank, chrome, dev, foo, gle, gmail, google, hangout, insurance, meet, page, play, search, youtube, esq, fly, eat, nexus, ing, meme, phd, prof, boo, dad, day, channel, hotmail, mov, zip, windows, skype, azure, office, bing, xbox, microsoft, notably including ZIP and MOV.
Beyond HSTS-preload, some TLDs have other requirements that can reduce the likelihood of malicious behavior (e.g. getting a phony domain under bank or insurance is harder).
Unfortunately, software today does little to represent these protections to the end-user (there’s nothing in the browser that indicates “Hey, this is a .bank URL so it’s much more likely to be legitimate), but a domain’s TLD can be used as an input into URL reputation services to help avoid false positives.
-Eric
如有侵权请联系:admin#unsafe.sh