
Loading...


At Cloudflare, we are constantly monitoring and optimizing the performance and resource utilization of our systems. Recently, we noticed that some of our TCP sessions were allocating more memory than expected.
The Linux kernel allows TCP sessions that match certain characteristics to ignore memory allocation limits set by autotuning and allocate excessive amounts of memory, all the way up to net.ipv4.tcp_rmem max (the per-session limit). On Cloudflare’s production network, there are often many such TCP sessions on a server, causing the total amount of allocated TCP memory to reach net.ipv4.tcp_mem thresholds (the server-wide limit). When that happens, the kernel imposes memory use constraints on all TCP sessions, not just the ones causing the problem. Those constraints have a negative impact on throughput and latency for the user. Internally within the kernel, the problematic sessions trigger TCP collapse processing, “OFO” pruning (dropping of packets already received and sitting in the out-of-order queue), and the dropping of newly arriving packets.
This blog post describes in detail the root cause of the problem and shows the test results of a solution.
TCP receive buffers are excessively big for some sessions
Our journey began when we started noticing a lot of TCP sessions on some servers with large amounts of memory allocated for receive buffers. Receive buffers are used by Linux to hold packets that have arrived from the network but have not yet been read by the local process.
Digging into the details, we observed that most of those TCP sessions had a latency (RTT) of roughly 20ms. RTT is the round trip time between the endpoints, measured in milliseconds. At that latency, standard BDP calculations tell us that a window size of 2.5 MB can accommodate up to 1 Gbps of throughput. We then counted the number of TCP sessions with an upper memory limit set by autotuning (skmem_rb) greater than 5 MB, which is double our calculated window size. The relationship between the window size and skmem_rb is described in more detail here. There were 558 such TCP sessions on one of our servers. Most of those sessions looked similar to this:

The key fields to focus on above are:
- recvq – the user payload bytes in the receive queue (waiting to be read by the local userspace process)
- skmem “r” field – the actual amount of kernel memory allocated for the receive buffer (this is the same as the kernel variable sk_rmem_alloc)
- skmem “rb” field – the limit for “r” (this is the same as the kernel variable sk_rcvbuf)
- l7read – the user payload bytes read by the local userspace process
Note the value of 256MiB for skmem_r and skmem_rb. That is the red flag that something is very wrong, because those values match the system-wide maximum value set by sysctl net.ipv4.tcp_rmem. Linux autotuning should not permit the buffers to grow that large for these sessions.
Memory limits are not being honored for some TCP sessions
TCP autotuning sets the maximum amount of memory that a session can use. More information about Linux autotuning can be found at Optimizing TCP for high WAN throughput while preserving low latency.
Here is a graph of one of the problematic sessions, showing skmem_r (allocated memory) and skmem_rb (the limit for “r”) over time:
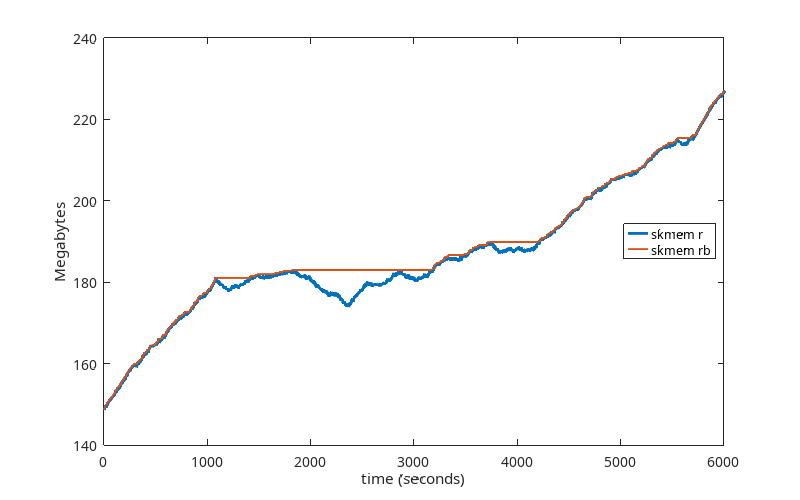
This graph is showing us that the limit being set by autotuning is being ignored, because every time skmem_r exceeds skmem_rb, skmem_rb is simply being raised to match it. So something is wrong with how skmem_rb is being handled. This explains the high memory usage. The question now is why.
The reproducer
At this point, we had only observed this problem in our production environment. Because we couldn’t predict which TCP sessions would fall into this dysfunctional state, and because we wanted to see the session information for these dysfunctional sessions from the beginning of those sessions, we needed to collect a lot of TCP session data for all TCP sessions. This is challenging in a production environment running at the scale of Cloudflare’s network. We needed to be able to reproduce this in a controlled lab environment. To that end, we gathered more details about what distinguishes these problematic TCP sessions from others, and ran a large number of experiments in our lab environment to reproduce the problem.
After a lot of attempts, we finally got it.
We were left with some pretty dirty lab machines by the time we got to this point, meaning that a lot of settings had been changed. We didn’t believe that all of them were related to the problem, but we didn’t know which ones were and which were not. So we went through a further series of tests to get us to a minimal set up to reproduce the problem. It turned out that a number of factors that we originally thought were important (such as latency) were not important.
The minimal set up turned out to be surprisingly simple:
- At the sending host, run a TCP program with an infinite loop, sending 1500B packets, with a 1 ms delay between each send.
- At the receiving host, run a TCP program with an infinite loop, reading 1B at a time, with a 1 ms delay between each read.
That’s it. Run these programs and watch your receive queue grow unbounded until it hits net.ipv4.tcp_rmem max.
tcp_server_sender.py
import time
import socket
import errno
daemon_port = 2425
payload = b'a' * 1448
listen_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_sock.bind(('0.0.0.0', daemon_port))
# listen backlog
listen_sock.listen(32)
listen_sock.setblocking(True)
while True:
mysock, _ = listen_sock.accept()
mysock.setblocking(True)
# do forever (until client disconnects)
while True:
try:
mysock.send(payload)
time.sleep(0.001)
except Exception as e:
print(e)
mysock.close()
break
tcp_client_receiver.py
import socket
import time
def do_read(bytes_to_read):
total_bytes_read = 0
while True:
bytes_read = client_sock.recv(bytes_to_read)
total_bytes_read += len(bytes_read)
if total_bytes_read >= bytes_to_read:
break
server_ip = “192.168.2.139”
server_port = 2425
client_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_sock.connect((server_ip, server_port))
client_sock.setblocking(True)
while True:
do_read(1)
time.sleep(0.001)
Reproducing the problem
First, we ran the above programs with these settings:
- Kernel 6.1.14 vanilla
- net.ipv4.tcp_rmem max = 256 MiB (window scale factor 13, or 8192 bytes)
- net.ipv4.tcp_adv_win_scale = -2
Here is what this TCP session is doing:
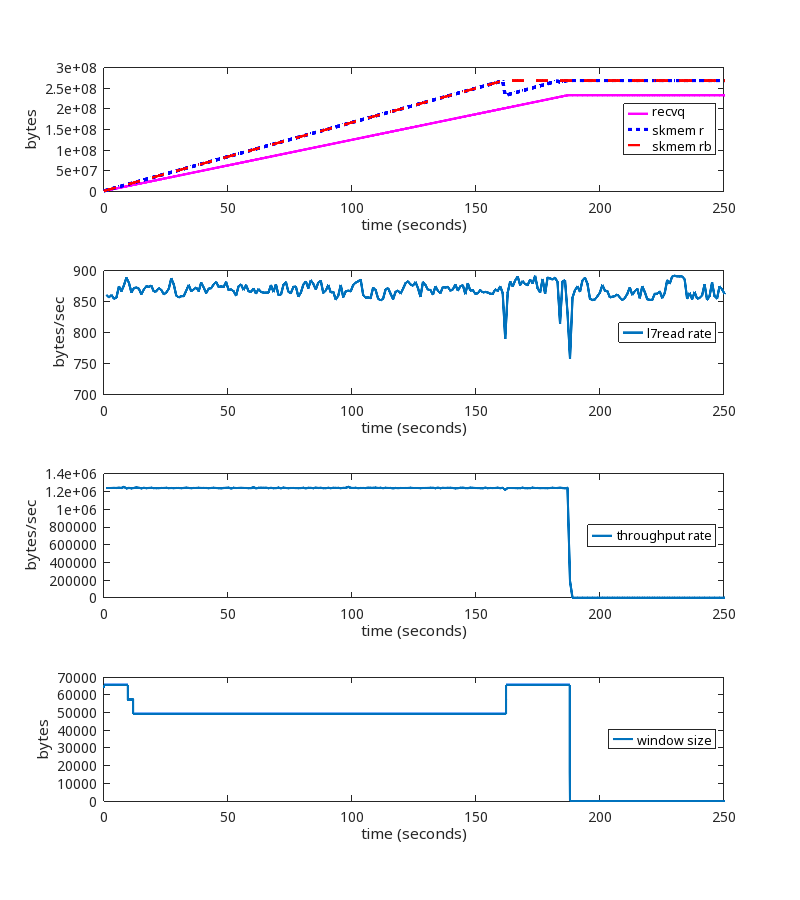
At second 189 of the run, we see these packets being exchanged:
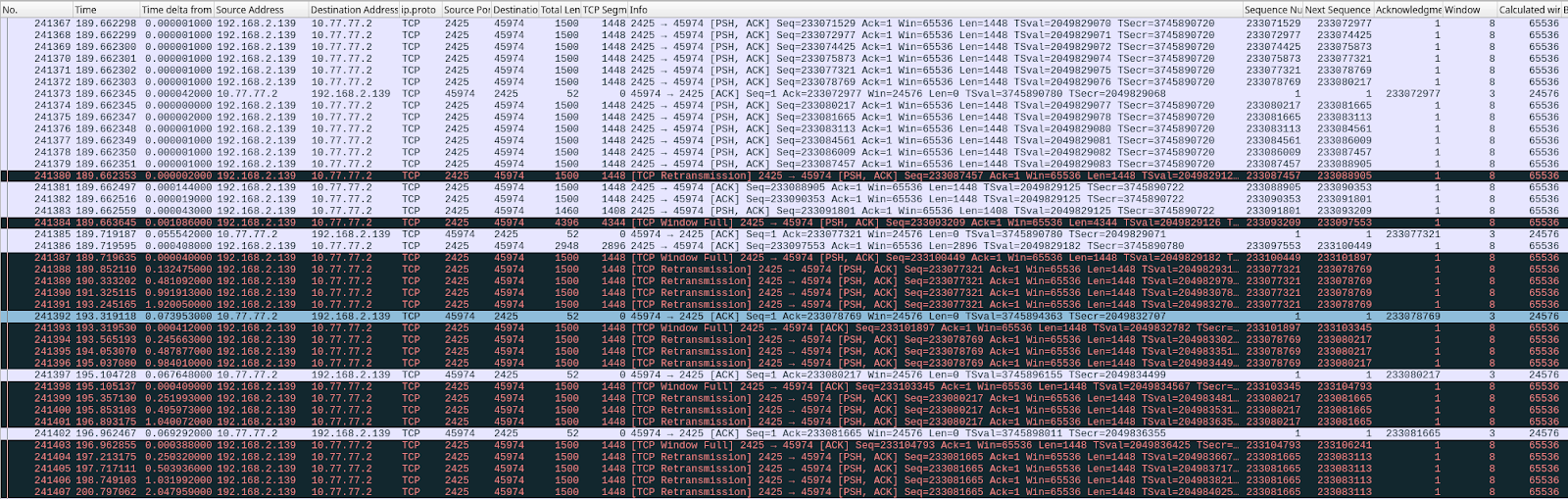
This is a significant failure because the memory limits are being ignored, and memory usage is unbounded until net.ipv4.tcp_rmem max is reached.
When net.ipv4.tcp_rmem max is reached:
- The kernel drops incoming packets.
- A ZeroWindow is never sent. A ZeroWindow is a packet sent by the receiver to the sender telling the sender to stop sending packets. This is normal and expected behavior when the receiver buffers are full.
- The sender retransmits, with exponential backoff.
- Eventually (~15 minutes, depending on system settings) the session times out and the connection is broken (“Errno 110 Connection timed out”).
Note that there is a range of packet sizes that can be sent, and a range of intervals which can be used for the delays, to cause this abnormal condition. This first reproduction is intentionally defined to grow the receive buffer quickly. These rates and delays do not reflect exactly what we see in production.
A closer look at real traffic in production
The prior section describes what is happening in our lab systems. Is that consistent with what we see in our production streams? Let’s take a look, now that we know more about what we are looking for.
We did find similar TCP sessions on our production network, which provided confirmation. But we also found this one, which, although it looks a little different, is actually the same root cause:
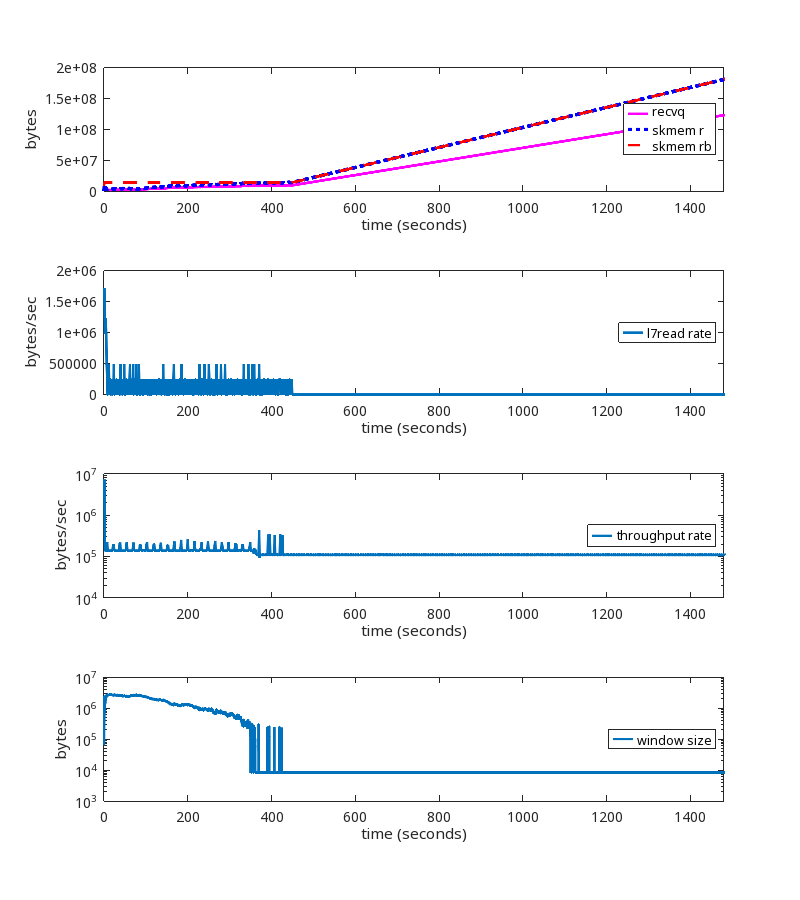
During this TCP session, the rate at which the userspace process is reading from the socket (the L7read rate line) after second 411 is zero. That is, L7 stops reading entirely at that point.
Notice that the bottom two graphs have a log scale on their y-axis to show that throughput and window size are never zero, even after L7 stops reading.
Here is the pattern of packet exchange that repeats itself during the erroneous “growth phase” after L7 stopped reading at the 411 second mark:

This variation of the problem is addressed below in the section called “Reader never reads”.
Getting to the root cause
sk_rcvbuf is being increased inappropriately. Somewhere. Let’s review the code to narrow down the possibilities.
sk_rcvbuf only gets updated in three places (that are relevant to this issue):
Actually, we are not calling tcp_set_rcvlowat, which eliminates that one. Next we used bpftrace scripts to figure out if it’s in tcp_clamp_window or tcp_rcv_space_adjust. After bpftracing, the answer is: It’s tcp_clamp_window.
Summarizing what we know so far,
part I
tcp_try_rmem_schedule is being called as usual.

Sometimes rmem_alloc > sk_rcvbuf. When that happens, prune is called, which calls tcp_clamp_window. tcp_clamp_window increases sk_rcvbuf to match rmem_alloc. That is unexpected.
The key question is: Why is rmem_alloc > sk_rcvbuf?
Why is rmem_alloc > sk_rcvbuf?
More kernel code review ensued, reviewing all the places where rmem_alloc is increased, and looking to see where rmem_alloc could be exceeding sk_rcvbuf. After more bpftracing, watching netstats, etc., the answer is: TCP coalescing.
TCP coalescing
Coalescing is where the kernel will combine packets as they are being received.
Note that this is not Generic Receive Offload (GRO). This is specific to TCP for packets on the INPUT path. Coalesce is a L4 feature that appends user payload from an incoming packet to an already existing packet, if possible. This saves memory (header space).
tcp_rcv_established calls tcp_queue_rcv, which calls tcp_try_coalesce. If the incoming packet can be coalesced, then it will be, and rmem_alloc is raised to reflect that. Here’s the important part: rmem_alloc can and does go above sk_rcvbuf because of the logic in that routine.
Summarizing what we know so far,
part II
- Data packets are being received
- tcp_rcv_established will coalesce, raising rmem_alloc above sk_rcvbuf
- tcp_try_rmem_schedule -> tcp_prune_queue -> tcp_clamp_window will raise sk_rcvbuf to match rmem_alloc
- The kernel then increases the window size based upon the new sk_rcvbuf value
In step 2, in order for rmem_alloc to exceed sk_rcvbuf, it has to be near sk_rcvbuf in the first place. We use tcp_adv_win_scale of -2, which means the window size will be 25% of the available buffer size, so we would not expect rmem_alloc to even be close to sk_rcvbuf. In our tests, the truesize ratio is not close to 4, so something unexpected is happening.
Why is rmem_alloc even close to sk_rcvbuf?
Why is rmem_alloc close to sk_rcvbuf?
Sending a ZeroWindow (a packet advertising a window size of zero) is how a TCP receiver tells a TCP sender to stop sending when the receive window is full. This is the mechanism that should keep rmem_alloc well below sk_rcvbuf.
During our tests, we happened to notice that the SNMP metric TCPWantZeroWindowAdv was increasing. The receiver was not sending ZeroWindows when it should have been. So our attention fell on the window calculation logic, and we arrived at the root cause of all of our problems.
The root cause
The problem has to do with how the receive window size is calculated. This is the value in the TCP header that the receiver sends to the sender. Together with the ACK value, it communicates to the sender what the right edge of the window is.
The way TCP’s sliding window works is described in Stevens, “TCP/IP Illustrated, Volume 1”, section 20.3. Visually, the receive window looks like this:
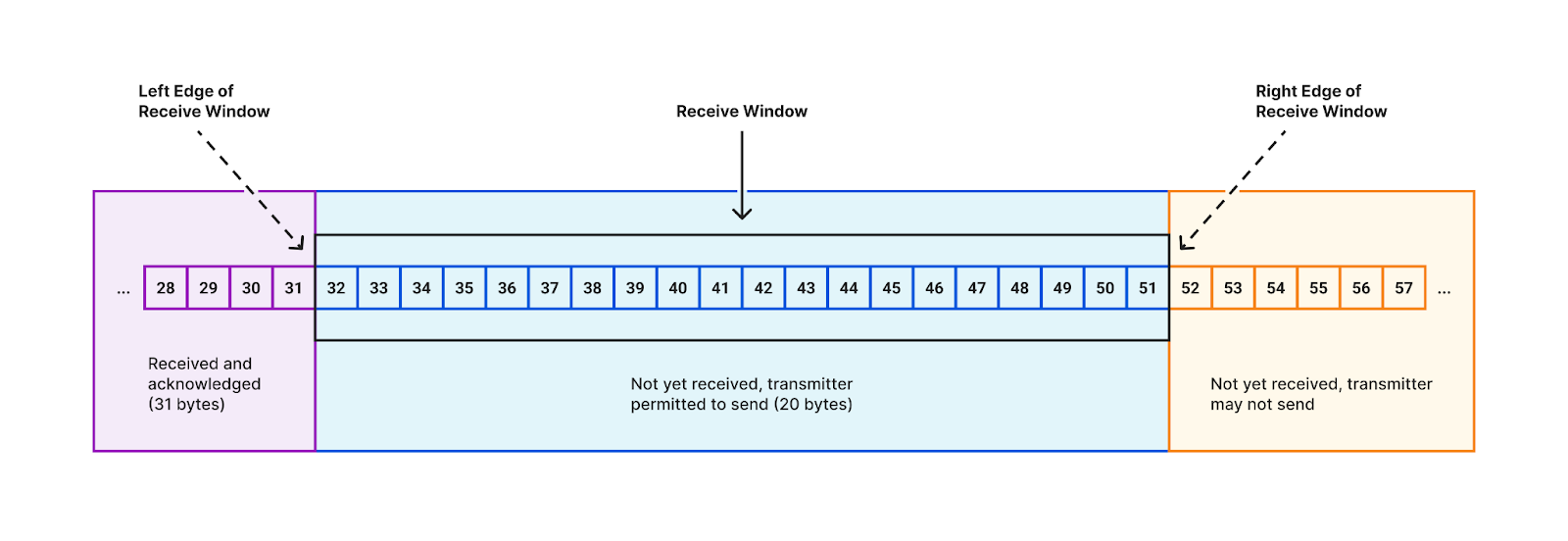
In the early days of the Internet, wide-area communications links offered low bandwidths (relative to today), so the 16 bits in the TCP header was more than enough to express the size of the receive window needed to achieve optimal throughput. Then the future happened, and now those 16-bit window values are scaled based upon a multiplier set during the TCP 3-way handshake.
The window scaling factor allows us to reach high throughputs on modern networks, but it also introduced an issue that we must now discuss.
The granularity of the receive window size that can be set in the TCP header is larger than the granularity of the actual changes we sometimes want to make to the size of the receive window.
When window scaling is in effect, every time the receiver ACKs some data, the receiver has to move the right edge of the window either left or right. The only exception would be if the amount of ACKed data is exactly a multiple of the window scale factor, and the receive window size specified in the ACK packet was reduced by the same multiple. This is rare.
So the right edge has to move. Most of the time, the receive window size does not change and the right edge moves to the right in lockstep with the ACK (the left edge), which always moves to the right.
The receiver can decide to increase the size of the receive window, based on its normal criteria, and that’s fine. It just means the right edge moves farther to the right. No problems.
But what happens when we approach a window full condition? Keeping the right edge unchanged is not an option. We are forced to make a decision. Our choices are:
- Move the right edge to the right
- Move the right edge to the left
But if we have arrived at the upper limit, then moving the right edge to the right requires us to ignore the upper limit. This is equivalent to not having a limit. This is what Linux does today, and is the source of the problems described in this post.
This occurs for any window scaling factor greater than one. This means everyone.
The window size specified in the TCP header is the receive window size. It is sent from the receiver to the sender. The ACK number plus the window size defines the range of sequence numbers that the sender may send. It is also called the advertised window, or the offered window.
There are three terms related to TCP window management that are important to understand:
- Closing the window. This is when the left edge of the window moves to the right. This occurs every time an ACK of a data packet arrives at the sender.
- Opening the window. This is when the right edge of the window moves to the right.
- Shrinking the window. This is when the right edge of the window moves to the left.
Opening and shrinking is not the same thing as the receive window size in the TCP header getting larger or smaller. The right edge is defined as the ACK number plus the receive window size. Shrinking only occurs when that right edge moves to the left (i.e. gets reduced).
RFC 7323 describes window retraction. Retracting the window is the same as shrinking the window.
Discussion Regarding Solutions
There are only three options to consider:
- Let the window grow
- Drop incoming packets
- Shrink the window
Let the window grow
Letting the window grow is the same as ignoring the memory limits set by autotuning. It results in allocating excessive amounts of memory for no reason. This is really just kicking the can down the road until allocated memory reaches net.ipv4.tcp_rmem max, when we are forced to choose from among one of the other two options.
Drop incoming packets
Dropping incoming packets will cause the sender to retransmit the dropped packets, with exponential backoff, until an eventual timeout (depending on the client read rate), which breaks the connection. ZeroWindows are never sent. This wastes bandwidth and processing resources by retransmitting packets we know will not be successfully delivered to L7 at the receiver. This is functionally incorrect for a window full situation.
Shrink the window
Shrinking the window involves moving the right edge of the window to the left when approaching a window full condition. A ZeroWindow is sent when the window is full. There is no wasted memory, no wasted bandwidth, and no broken connections.
The current situation is that we are letting the window grow (option #1), and when net.ipv4.tcp_rmem max is reached, we are dropping packets (option #2).
We need to stop doing option #1. We could either drop packets (option #2) when sk_rcvbuf is reached. This avoids excessive memory usage, but is still functionally incorrect for a window full situation. Or we could shrink the window (option #3).
Shrinking the window
It turns out that this issue has already been addressed in the RFC’s.
RFC 7323 says:

There are two elements here that are important.
- “there are instances when a retracted window can be offered”
- “Implementations MUST ensure that they handle a shrinking window”
Appendix F of that RFC describes our situation, adding:
- “This is a general problem and can happen any time the sender does a write, which is smaller than the window scale factor.”
Kernel patch
The Linux kernel patch we wrote to enable TCP window shrinking can be found here. This patch will also be submitted upstream.
Rerunning the test above with kernel patch
Here is the test we showed above, but this time using the kernel patch:
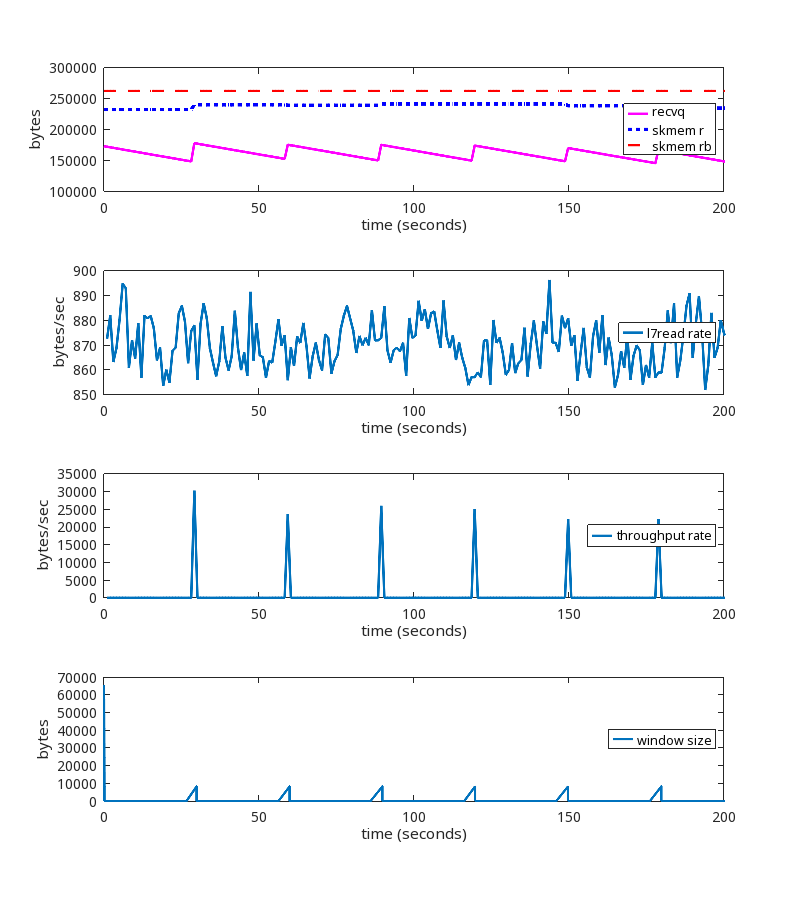
Here is the pattern of packet exchanges that repeat when using the kernel patch:

We see that the memory limit is being honored, ZeroWindows are being sent, there are no retransmissions, and no disconnects after 15 minutes. This is the desired result.
Test results using a TCP window scaling factor of 8
The window scaling factor of 8 and tcp_adv_win_scale of 1 is commonly seen on the public Internet, so let’s test that.
- kernel 6.1.14 vanilla
- tcp_rmem max = 8 MiB (window scale factor 8, or 256 bytes)
- tcp_adv_win_scale = 1
Without the kernel patch
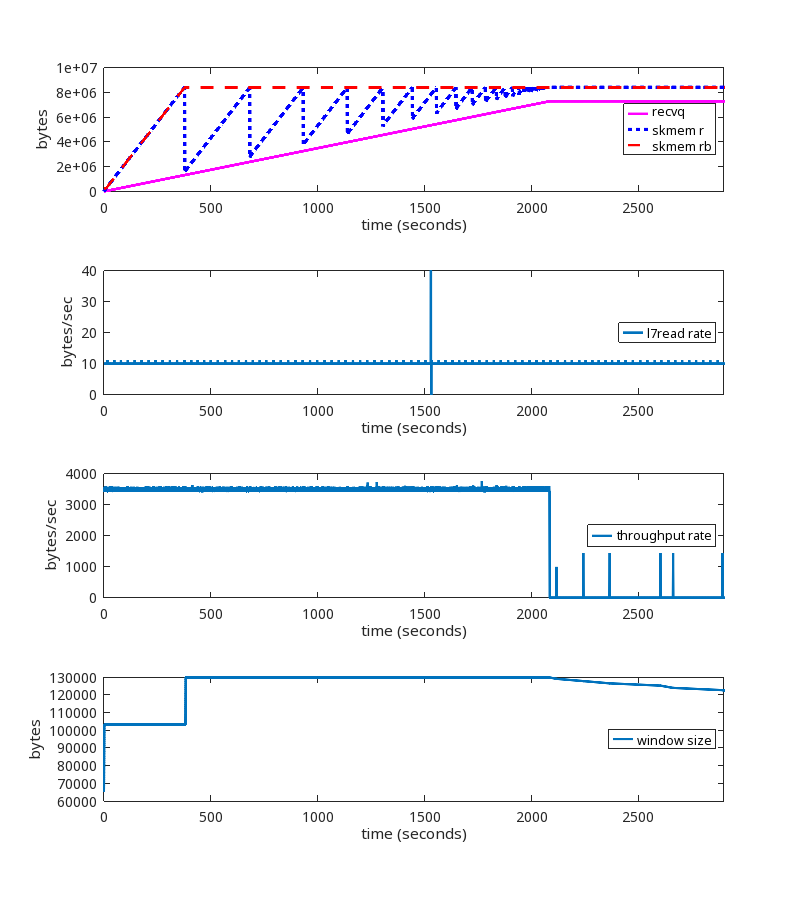
At the ~2100 second mark, we see the same problems we saw earlier when using wscale 13.
With the kernel patch
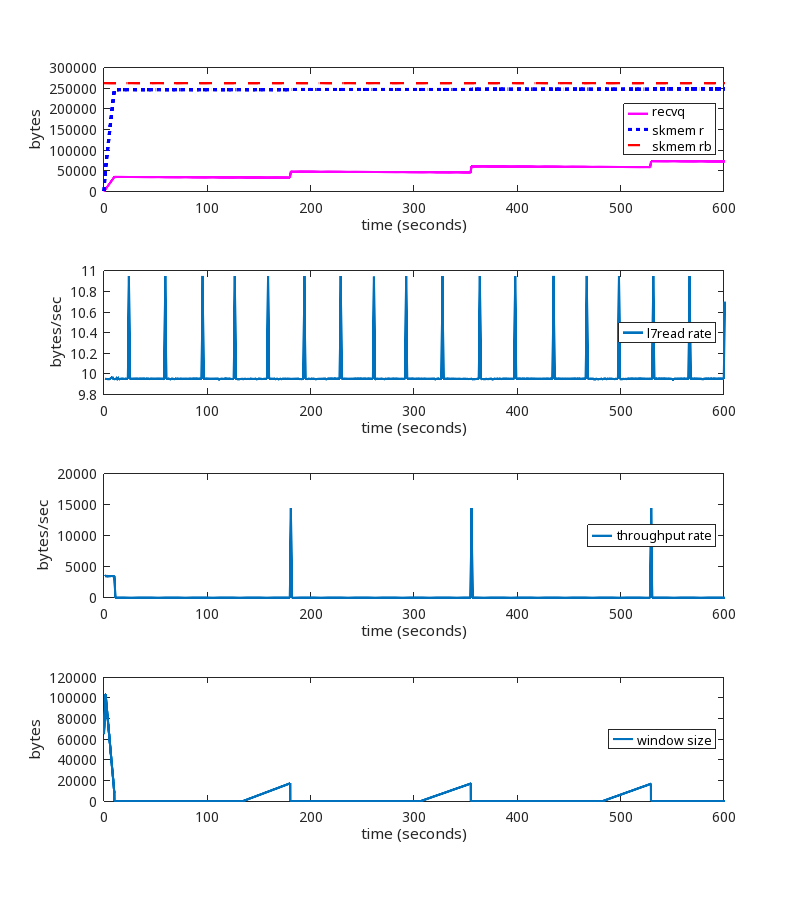
The kernel patch is working as expected.
Test results using an oscillating reader
This is a test run where the reader alternates every 240 seconds between reading slow and reading fast. Slow is 1B every 1 ms and fast is 3300B every 1 ms.
- kernel 6.1.14 vanilla
- net.ipv4.tcp_rmem max = 256 MiB (window scale factor 13, or 8192 bytes)
- tcp_adv_win_scale = -2
Without the kernel patch
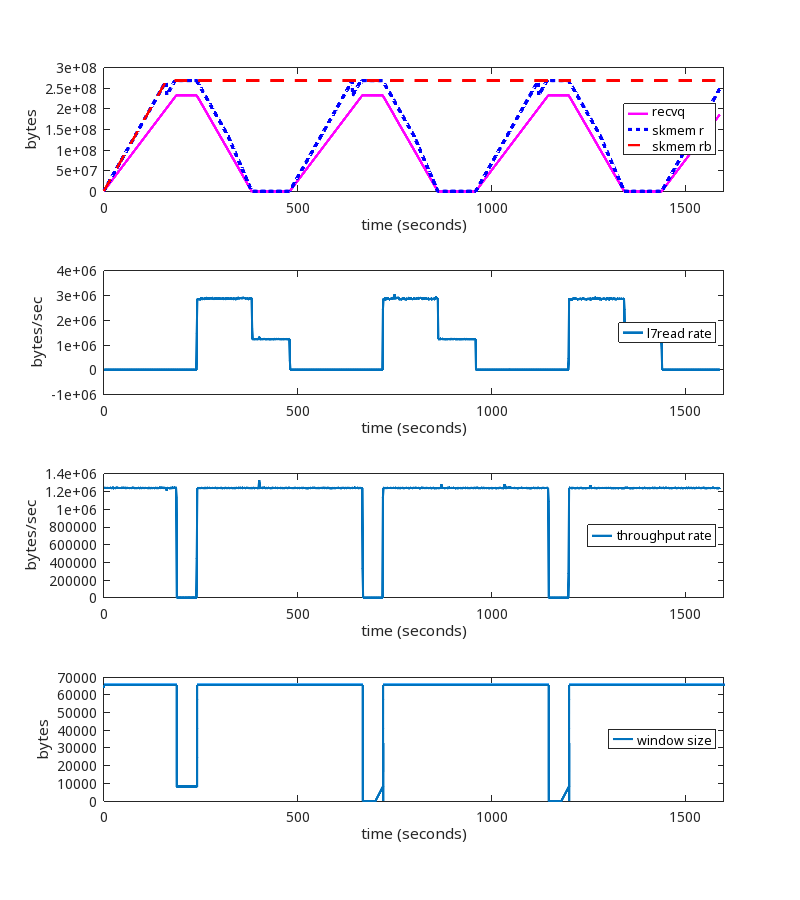
With the kernel patch
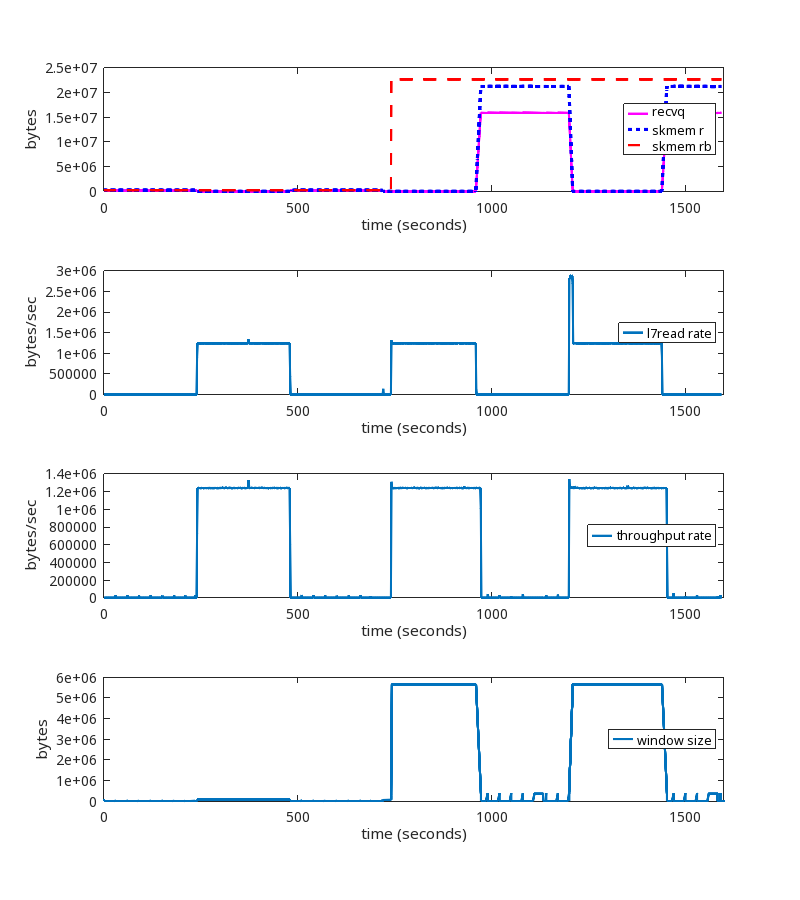
The kernel patch is working as expected.
NB. We do see the increase of skmem_rb at the 720 second mark, but it only goes to ~20MB and does not grow unbounded. Whether or not 20MB is the most ideal value for this TCP session is an interesting question, but that is a topic for a different blog post.
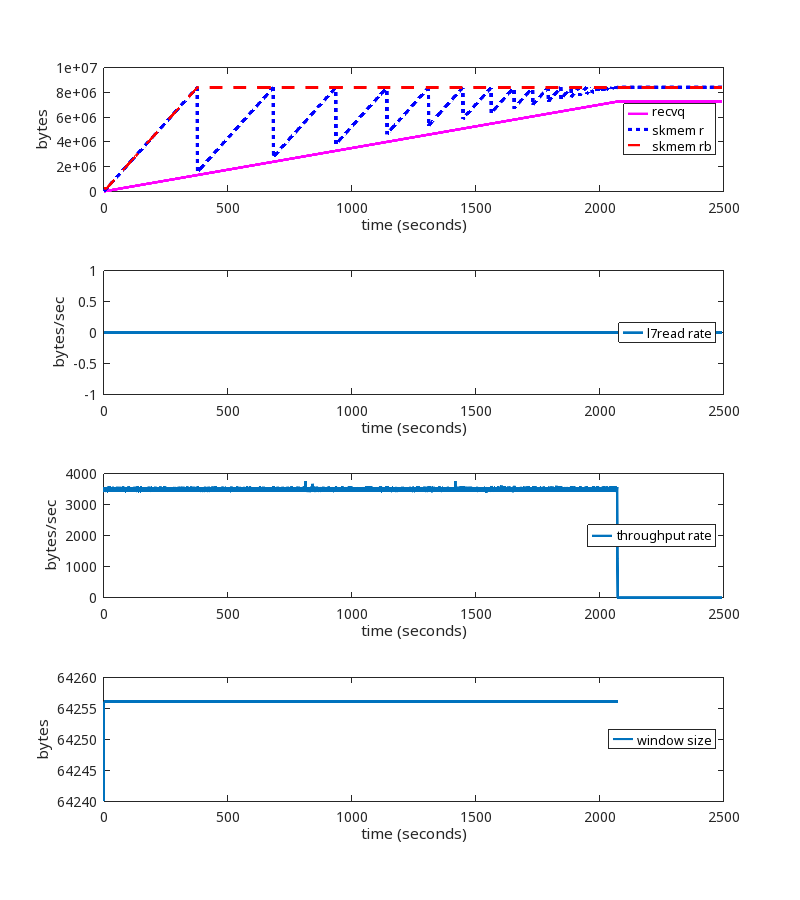
Reader never reads
Here’s a good one. Say a reader never reads from the socket. How much TCP receive buffer memory would we expect that reader to consume? One might assume the answer is that the reader would read a few packets, store the payload in the receive queue, then pause the flow of packets until the userspace program starts reading. The actual answer is that the reader will read packets until the receive queue grows to the size of net.ipv4.tcp_rmem max. This is incorrect behavior, to say the very least.
For this test, the sender sends 4 bytes every 1 ms. The reader, literally, never reads from the socket. Not once.
- kernel 6.1.14 vanilla
- net.ipv4.tcp_rmem max = 8 MiB (window scale factor 8, or 256 bytes)
- net.ipv4.tcp_adv_win_scale = -2
Without the kernel patch:
With the kernel patch:
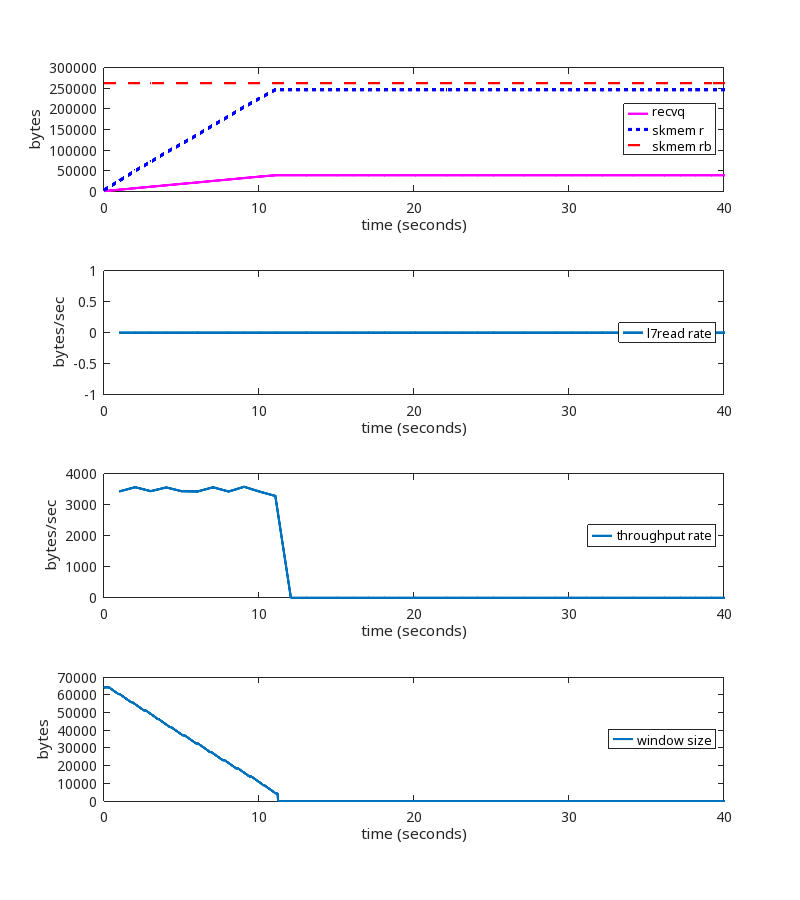
Using the kernel patch produces the expected behavior.
Results from the Cloudflare production network
We deployed this patch to the Cloudflare production network, and can see the effects in aggregate when running at scale.
Packet Drop Rates
This first graph shows RcvPruned, which shows how many incoming packets per second were dropped due to memory constraints.
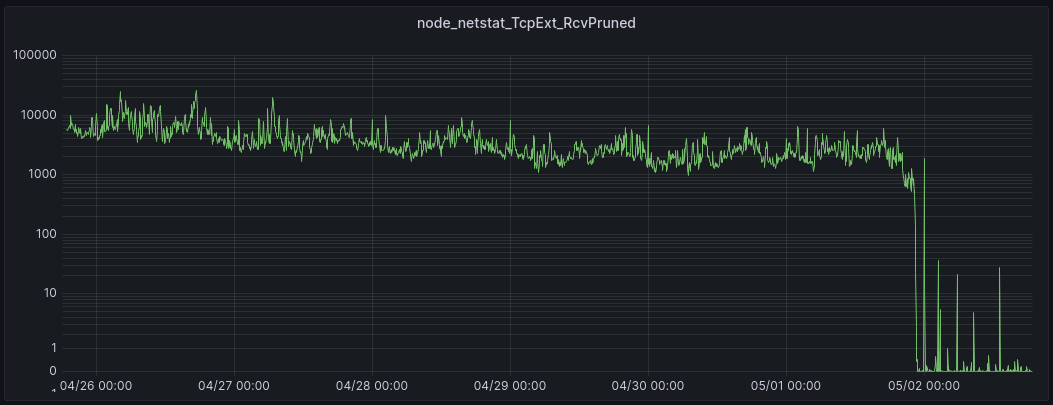
The patch was enabled on most servers on 05/01 at 22:00, eliminating those drops.
TCPRcvCollapsed
Recall that TCPRcvCollapsed is the number of packets per second that are merged together in the queue in order to reduce memory usage (by eliminating header metadata). This occurs when memory limits are reached.
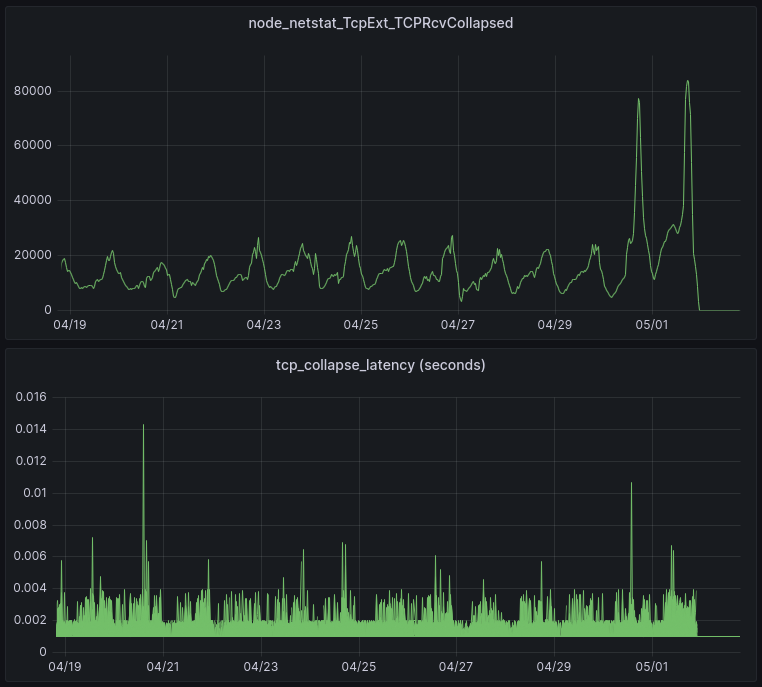
The patch was enabled on most servers on 05/01 at 22:00. These graphs show the results from one of our data centers. The upper graph shows that the patch has eliminated all collapse processing. The lower graph shows the amount of time spent in collapse processing (each line in the lower graph is a single server). This is important because it can impact Cloudflare’s responsiveness in processing HTTP requests. The result of the patch is that all latency due to TCP collapse processing has been eliminated.
Memory
Because the memory limits set by autotuning are now being enforced, the total amount of memory allocated is reduced.
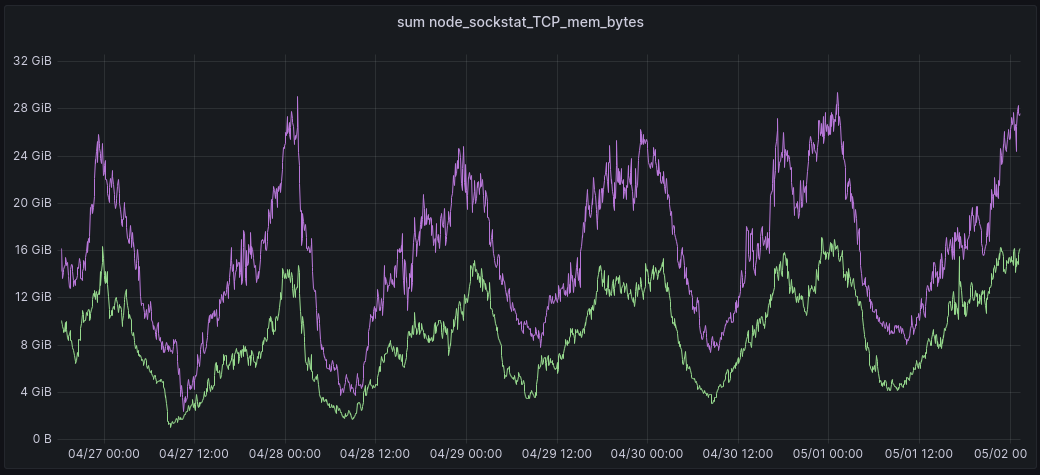
In this graph, the green line shows the total amount of memory allocated for TCP buffers in one of our data centers. This is with the patch enabled. The purple line is the same total, but from exactly 7 days prior to the time indicated on the x axis, before the patch was enabled. Using this approach to visualization, it is clear to see the memory saved with the patch enabled.
ZeroWindows
TCPWantZeroWindowAdv is the number of times per second that the window calculation based on available buffer memory produced a result that should have resulted in a ZeroWindow being sent to the sender, but was not. In other words, this is how often the receive buffer was increased beyond the limit set by autotuning.
After a receiver has sent a Zero Window to the sender, the receiver is not expecting to get any additional data from the sender. Should additional data packets arrive at the receiver during the period when the window size is zero, those packets are dropped and the metric TCPZeroWindowDrop is incremented. These dropped packets are usually just due to the timing of these events, i.e. the Zero Window packet in one direction and some data packets flowing in the other direction passed by each other on the network.
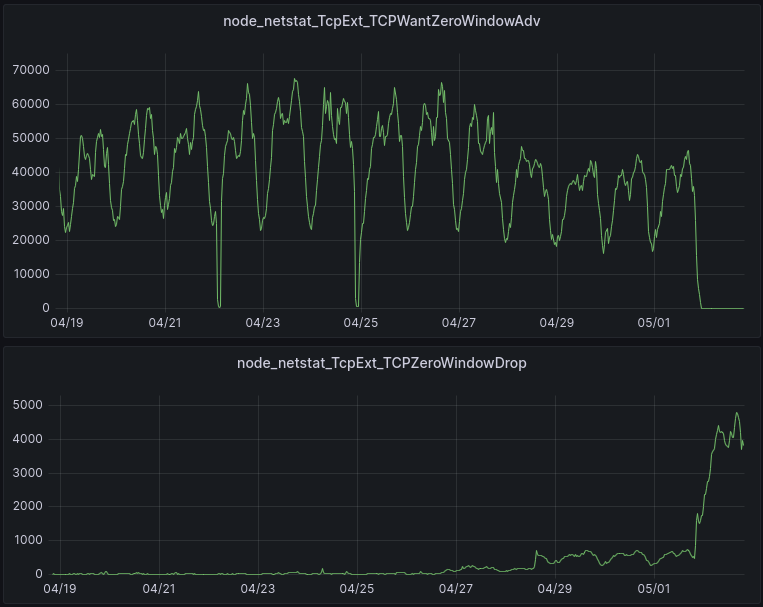
The patch was enabled on most servers on 05/01 at 22:00, although it was enabled for a subset of servers on 04/26 and 04/28.
The upper graph tells us that ZeroWindows are indeed being sent when they need to be based on the available memory at the receiver. This is what the lack of “Wants” starting on 05/01 is telling us.
The lower graph reports the packets that are dropped because the session is in a ZeroWindow state. These are ok to drop, because the session is in a ZeroWindow state. These drops do not have a negative impact, for the same reason (it’s in a ZeroWindow state).
All of these results are as expected.
Importantly, we have also not found any peer TCP stacks that are non-RFC compliant (i.e. that are not able to accept a shrinking window).
Summary
In this blog post, we described when and why TCP memory limits are not being honored in the Linux kernel, and introduced a patch that fixes it. All in a day’s work at Cloudflare, where we are helping build a better Internet.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.