阅读: 19
在2023年的RSA会议上,弗吉尼亚行为健康和发展服务部的CISO和研究员分享了题为“机器崛起:通过人工智能实现数据安全与分析”的议题。他们提出了使用人工智能的方法来快速合成“去识别”(de-identified)数据,从而避免了大量资源消耗和人为误差。本文将解读该议题及其涉及的相关技术基本原理。
统计学习(Statistical Learning)、机器学习(Machine Learning)、符号学习(Symbolic Learning)、神经网络(Neural Network)…… AI发展至今,已经形成了庞大的分支。每个分支上都存在着各种不同的技术。通过利用这些技术,我们使得机器更加智能。它们可以帮助我们进行分类和预测任务、物体识别任务、动作捕捉任务以及语音的识别和转录任务,如图 1所列举。然而,要训练这些机器,我们需要大量的数据作为支持。因此,一个出色的模型通常需要大量的训练数据。
这引出了一个问题:如何获取如此庞大的数据?而这个问题又会带来一系列相关问题:在个人信息保护法的要求下,如何合规合法地收集去识别和脱敏的数据?如何确保在对数据进行识别和脱敏后,仍然能够有效地用于训练?
在会议上,Glenn Schmitz提出了使用合成数据(synthetic data)的方法,即利用人工智能自动合成数据,跳过传统的数据收集过程,将由人工智能合成的数据用于其他人工智能的训练或数据分析。如图2所示,通过CycleGAN技术,我们可以将真实图片转换为虚拟图片,例如将冬天的景象转变为夏天的景象。Glenn Schmitz在会议中提出了三种不同的方法:合成少数过采样技术(SMOTE),变分自编码器(VAEs)和生成对抗网络(GAN)。
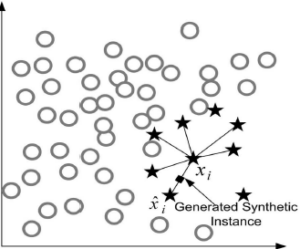
SMOTE一种使用真实数据进行数据合成(data synthesis with real data)的方法。这种方法使用已有的真实数据集作为基础,并通过对其进行处理和转换来生成新的数据集。通常,这涉及对原始数据进行采样、转换、增强或添加噪声等操作,以生成更多的样本。使用真实数据进行数据合成的主要优点是生成的数据能够反映出原始数据集的真实特征和分布。具体而言SMOTE通过在少数类样本之间进行插值,生成合成样本来增加少数类样本的数量。如图3所示,SMOTE方法选择一个少数类样本和其最近邻的样本,然后在它们之间随机插值生成新的样本。这样可以增加少数类样本的数量,平衡数据集,并提高机器学习算法对少数类的分类性能。
与之相对,VAEs和GAN都是不使用真实数据进行数据合成(data synthesis without real data)的方法。这种方法不依赖于任何真实数据集(生成的数据不依赖于真实数据集,模型的训练可能需要),而是使用各种建模技术来生成合成数据。通过学习原始数据集的特征和分布,这些模型可以生成与原始数据类似的合成数据。不使用真实数据进行数据合成的优点是可以生成大量的数据样本,即使在原始数据稀缺或难以获得的情况下也能够进行模型训练和算法评估。然而,由于生成的数据不是基于真实观测数据,因此可能无法完全捕捉真实世界中的复杂性和不确定性。
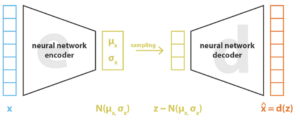
具体而言,VAEs是一种基于概率模型的数据合成方法。它结合了自编码器和变分推断的思想,可以用于生成合成数据。通过学习数据的潜在表示空间,如图4中通过encoder学习到数据的概率分布,VAES在该空间中采样来生成新的合成数据样本。它的优势在于能够生成具有多样性的数据,同时还能保持数据的连续性和一致性,因为它们是对数据的生成过程进行建模,并且能够通过调整潜在空间中的参数来控制生成样本的特征。
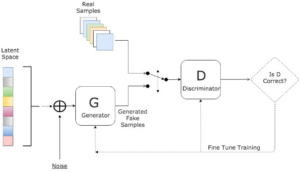
而GAN是通过两个部件——生成器与判别器来合成数据。其中,生成器负责生成合成数据样本,而判别器则负责区分真实数据和合成数据。如图5所示,通过对抗性训练,生成器可以逐渐学习生成逼真的合成数据,同时判别器也不断提升辨别真实与合成数据的能力。这种对抗性训练过程使得GAN能够生成具有高度逼真度和与真实数据相似性的合成数据。
对于合成数据的应用场景,Glenn Schmitz提到了四个目前取得成果的例子,如图6所示。首先,FACS(Facial Action Coding System)发表了应用合成数据用于骨科手术的案例。其次,DeepAI利用合成数据训练了图像分割和目标提取模型。第三,OpenAI利用合成数据进行了语义识别的研究。最后,Ilge Akkaya发表了使用合成数据训练机器人手臂的成果。
总的来说,合成数据在许多应用场景中发挥着重要作用。它可以用于增强真实数据集的规模和多样性,从而提高机器学习模型的性能和泛化能力。合成数据还可以用于填补缺失数据或处理数据不平衡的问题,以平衡数据集的分布。此外,合成数据也可以在隐私保护方面发挥作用,通过生成合成数据来替代敏感信息,以保护个人隐私。在模拟和仿真领域,合成数据可以用于创建虚拟环境和场景,以进行测试、验证和训练,从而降低成本和风险。总之,合成数据具有广泛的应用场景,为各种领域的数据分析、建模和决策提供了有价值的资源。
Glenn Schmitz指出,尽管合成数据方便了训练数据的获取,但它仍然存在一些争议和风险。从AI的伦理和道德角度来看,合成数据的生成过程,因为设计原因,可能本身带有一定的“偏见”,使得生成的数据具有强烈的“个人属性”。此外,从使用的角度来看,当合成数据用于”精细任务”时,它所引入的误差可能带来巨大的使用风险。如图 7所示,使用时,需要全面的考虑到利弊,同时也需要在道德,偏差与目标做权衡。
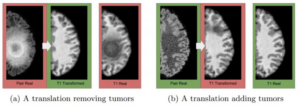
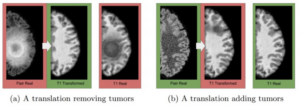
正如CycleGAN的研究者在论文中所指出的,CycleGAN的输出是对“如果……它会是什么样子”的预测,虽然这些预测看似合理,但与基本事实可能存在很大差异。因此,在根据CycleGAN的输出作出关键决策的领域中,需要谨慎使用和校准。特别是在医学应用中,例如将MRI数据转换为CT数据时,这一点尤为重要。就像CycleGAN可能在天空中添加奇特的云彩,使其看起来像梵高的画作一样,它可能会在医学图像中添加不存在的肿瘤或者移除真实存在的肿瘤,如图 8所示。
为了方便研究人员和开发者使用,Glenn Schmitz列举了一些常用的数据合成工具,如图9所示,包括:
1)Mimesis:一个多语言的假数据生成库,可以生成各种类型的数据,如姓名、地址、电子邮件等。
2)The Synthetic Data Vault(SDV):一个开源工具,用于生成合成数据集,它基于统计模型和机器学习算法,可以模拟真实数据的分布和属性。
3)Transaction data simulator:用于模拟交易数据的工具,可以生成合成的交易数据集,用于测试和分析目的。
4)YData Synthetic:一个用于生成合成数据的平台,提供了各种数据类型和生成方法,可以根据需求创建合成数据集。
5)Faker:一个用于生成合成数据的Python库,可以生成各种类型的数据,如姓名、地址、日期等。
此外,还有一些常用的Python库,如sklearn(Scikit-learn)、faker module、PYOD(Python Outlier Detection)、CTGAN(Conditional Tabular GAN),它们提供了丰富的功能和算法,用于生成和处理合成数据。
[1] Glenn Schmitz, Angus Chen, Rise of the Machines: Achieving Data Security and Analytics with AI, RSAC, 2023
[2] Blagus R, Lusa L. SMOTE for high-dimensional class-imbalanced data[J]. BMC bioinformatics, 2013, 14: 1-16.
[3] Joseph Rocca, Understanding Variational Autoencoders (VAEs), towardsdatascience, 2019
[4] Sik-Ho Tsang, CGAN — Conditional GAN (GAN), Artificial Intelligence in Plain English, 2020
[5] Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision (pp. 2223-2232).
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。
文章来源: http://blog.nsfocus.net/rsa-ai/
如有侵权请联系:admin#unsafe.sh