
(In the Blog Post, we will demonstrate a Proof-of-Concept on how to use a OpenAI’s Large Languag 2023-5-30 17:48:53 Author: blog.nviso.eu(查看原文) 阅读量:44 收藏
(In the Blog Post, we will demonstrate a Proof-of-Concept on how to use a OpenAI’s Large Language Model to craft Elastic SIEM queries in an automated way. Be mindful of issues with accuracy and privacy before trying to replicate this Proof-of-Concept. More info in our discussion at the bottom of this article.)
Introduction
The primary task of a security analyst or threat hunter is to ask the right questions and then translate them into SIEM query languages, like SPL for Splunk, KQL for Sentinel, and DSL for Elastic. These questions are designed to provide answers about what actually happened. For example: “Identify failed login attempts, Search for a specific user’s login activities, Identify suspicious process creation, Monitor changes to registry keys, Detect user account lockouts, etc.”
The answers to these questions will likely lead to even more questions. Analysts will keep interrogating the SIEM until they get a clear answer. This allows them to piece together a timeline of all the activities and explain whether it is a false positive or an actual incident. To do this, the analysts need to know a bunch of things. First, they need to be familiar with several types of attacks. Next, they need to understand the infrastructure (cloud systems, on-premises, applications, etc.). And on top of all that, they must learn how to use these SIEM tools effectively.
Is GPT-3 capable of generating Elasticsearch DSL queries?
In this blog post, we will explore how a powerful language model by OpenAI can automate the last step and bridge the gap between human language questions and SIEM query language.
We will be presenting a brief demo of a custom chat web app that allows users to query Windows event logs using natural language and obtain results for incident handling. In our example, we used the TextDavinci-3 model from OpenAI and Elastic as a SIEM. We built the custom chat app, using vanilla JS for the client and NodeJS for the backend.
Architecture
In our design, we send the analysts question to OpenAI using their API within a custom prompt. Subsequently, the resulting Elastic Query is sent to the Elastic SIEM using its API. Lastly, the result from Elastic is returned to the user.

A: User asking in the chat
B: The web app sends the initial input, enhanced with a standard phrase, to guide the model in generating more relevant and coherent responses.
C: It gets back the response: corresponding Elasticsearch query
D: The web app sends the query to Elasticsearch, after some checks
E: Elasticsearch sends back the result to web app
F: Present the results to the user in table format
Demo
In this demo, we focused on querying a specific log source, namely the “winlogbeat” index. However, it is indeed possible to expand the scope of the query by incorporating a broader index pattern that includes a wider range of log sources, such as “Beats-*” (if we are utilizing Beats for log collectors). Another approach would be to perform a search across all available sources, assuming the implementation of the Elastic Common Schema (ECS) within Elasticsearch. For instance, if we have different log types, such as Windows event logs, Checkpoint logs, etc. and we want to retrieve these logs from a specific host name, we can utilize the “host.name” key in each log source (index). By specifying the desired host name, we can filter the logs and retrieve the relevant information from the respective log sources.

Deep drive
Below, we will go into detail on how we built the application.
To create this web app, the first thing we need is an API key from OpenAI. This key will give us access to the gpt-3 models and their functionalities.

Next, we will utilize the OpenAI playground to experiment and interact with the TextDavinci-3 model. In this particular example, we made an effort to craft an optimal prompt that would yield the most desirable responses. Fortunately, the TextDavinci-3 model proved to be the ideal choice, providing us with excellent results. Also, the OpenAI API allows you to control the behavior of the language model by adjusting certain parameters:
- Temperature: The temperature parameter controls the randomness of the model’s output. A higher temperature, like 0.8, makes the output more creative and random, while a lower temperature, like 0.1, makes it more focused and deterministic.
- Max Tokens: The max tokens parameter allows you to limit the length of the model’s response. You can set a specific number of tokens to restrict the length of the generated text. Be aware that setting an extremely low value may result in the response being cut off and not making sense to the user.
- Frequency Penalty: The frequency penalty parameter allows you to control the repetitiveness of the model’s responses. By increasing the frequency penalty (e.g., setting it to a value higher than 0), you can discourage the model from repeating the same phrases or words in its output.
- Top P (Top Probability): The top_p parameter, also known as nucleus sampling or top probability, sets a threshold for the cumulative probability distribution of the model’s next-word predictions. Instead of sampling from the entire probability distribution, the model only considers the most probable tokens whose cumulative probability exceeds the top_p value. This helps to narrow down the possibilities and generate more focused and coherent responses.
- Presence Penalty: The presence penalty parameter allows you to encourage or discourage the model from including specific words or phrases in its response. By increasing the presence penalty (e.g., setting it to a positive value), you can make the model avoid certain words or topics. Conversely, setting a negative value can encourage the model to include specific words or phrases.
Following that, we can proceed to export the code based on the programming language we are using for our chat web app. This will allow us to obtain the necessary code snippets tailored to our preferred language.
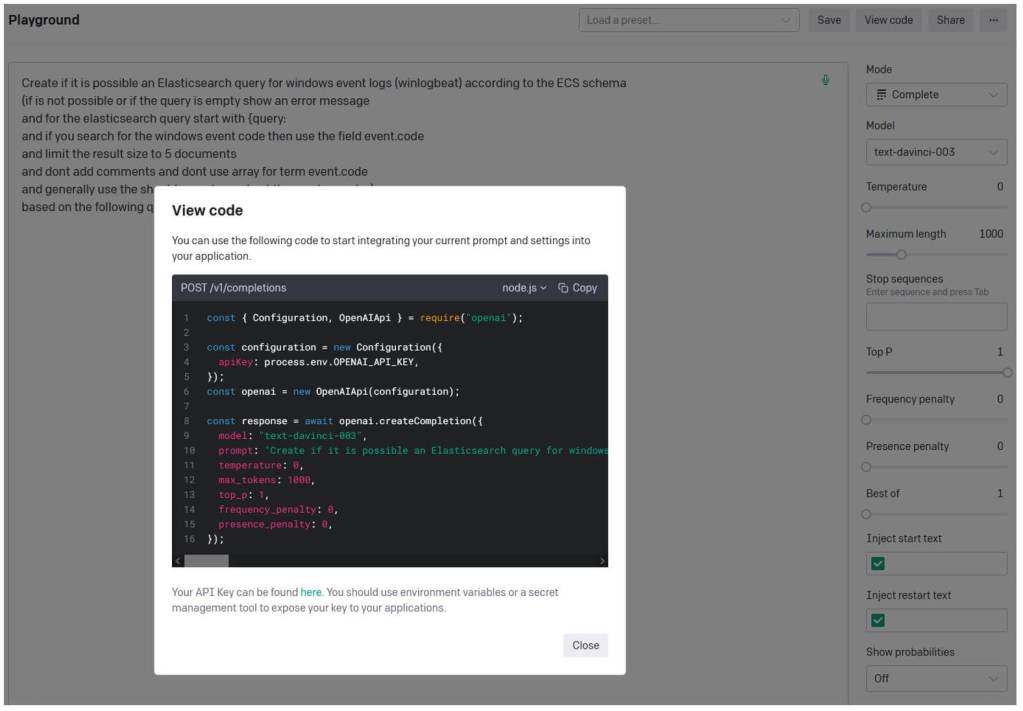
Also, it is worth mentioning that we stumbled upon an impressive attempt at dsltranslate.com, where you can check how ChatGPT translate a search sentence into an Elasticsearch DSL query (even SQL).
Returning to our experimental use case, our web app consists of two components: the client side and the server side. On the client side, we have a chat user interface (UI) where users can input their questions or queries. These questions are then sent to the server side for processing.

On the server side, we enhance the user’s questions by combining them with a predefined text to create a prompt. This prompt is then sent to the OpenAI API for processing and generating a response.
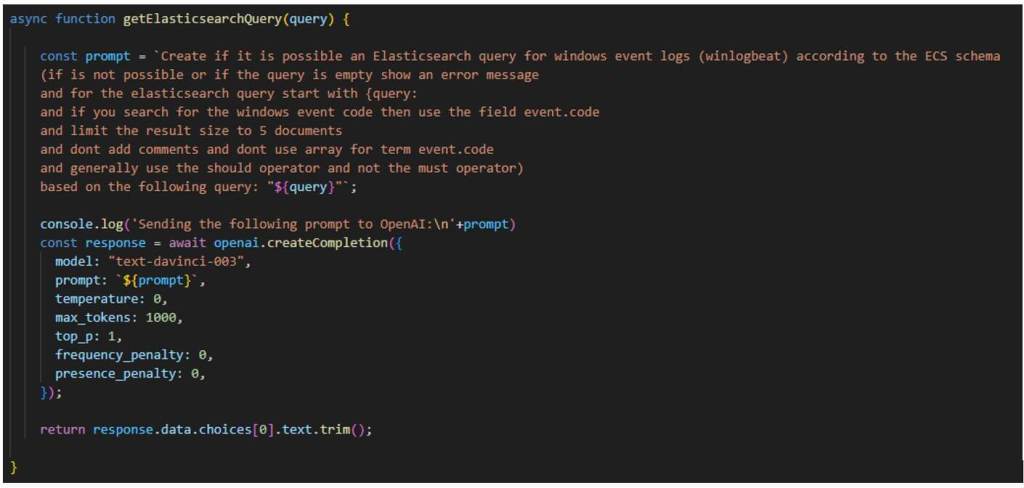
Once we receive the response, we perform some basic checks, such as verifying if it is a valid JSON object, before forwarding the query to our SIEM API, which in this case is Elastic. Finally, we send the reply back to the client by transforming the JSON response into an HTML table format.
Discussion
But many of the responses from OpenAI API are not correct…
You are absolutely right. Not all responses from the OpenAI API can be guaranteed to be correct or accurate. Fine-tuning the model is a valuable approach to improve the accuracy of the generated results.
Fine-tuning involves training the pre-trained language models like GPT-3 and TextDavinci-3 on specific datasets that are relevant to the desired task or domain. By providing a training dataset specific to our use case, we can enable the model to learn from and adapt to the context, leading to more accurate and tailored responses.
To initiate the fine-tuning process, we would need to prepare a training dataset comprising a minimum of 500 examples in any text format. This data set should cover a diverse range of scenarios and queries related to our specific use case. By training the model on this dataset, we can enhance its performance and ensure that it generates more accurate and contextually appropriate responses for our application.
Example:
{"prompt": "show me the last 5 logs from the user sotos", "completion": " {\n\"query\": {\n \"match\": {\n..... "}
{"prompt": "...........", "completion": "................."}
....Even if we invest efforts in fine-tuning the model and striving for improvement, it is important to acknowledge that new versions and functionalities are regularly integrated into the Elasticsearch query language. It is worth noting that the knowledge perspective of ChatGPT is limited to information available up until September 2021. Similar to numerous companies, Elastic has recently developed a plugin that enable ChatGPT to tap into Elastic’s up-to-date knowledge base and provide assistance with the latest features introduced by Elastic.
Everything seems perfect so far, but…what about security and privacy of data?
Indeed, privacy and security are important concerns when dealing with sensitive data, especially in scenarios where queries or requests might expose potentially confidential information. In the described scenario, the actual logs are not shared with OpenAI, but the queries themselves reveal certain information, such as specific usernames or host names (ex. “find the logs for the user mitsos” or “show me all the failed logon attempts from the host WIN-SOTO.”).
In accordance with the data usage policies of OpenAI API (in contrast to ChatGPT), it refrains from utilizing the data provided through its API to train its models or enhance its offerings. It is worth noting, however, that data transmitted to their APIs is handled by servers situated in the United States, and OpenAI retains the data you submit via the API for a period of up to 30 days for the purpose of monitoring potential abuses. Nevertheless, OpenAI grants you the ability to choose not to participate in this monitoring, thereby ensuring that your data remains neither stored nor processed. To exercise this option, you can make use of the provided form. Consequently, each API call initiates and concludes your data’s lifecycle. The data is transmitted through the API, and the API call’s response contains the resulting output. It does not retain or preserve any data transmitted during successive API requests.
In conclusion, by leveraging OpenAI’s language processing capabilities, organizations can empower security analysts to express their query intentions in a natural language format. This approach streamlines the SIEM query creation process, enhances collaboration, and improves the accuracy and effectiveness of security monitoring and incident response. With OpenAI’s assistance, bridging the gap between human language and SIEM query language becomes an achievable reality in the ever-evolving landscape of cybersecurity. Last but not least, the privacy issue surrounding ChatGPT and OpenAI API usage raises a significant point that necessitates thoughtful consideration, before creating new implementations.

Nikos Samartzopoulos
Nikos is a Senior Consultant in the SOC Engineer Team. With a strong background in data field and extensive knowledge of Elastic Stack, Nikos has cultivated his abilities in architecting, deploying, and overseeing Elastic SIEM systems that excel in monitoring, detecting, and swiftly responding to security incidents.
如有侵权请联系:admin#unsafe.sh