前言
这篇文章介绍我们前段时间被计算机安全四大顶会之一的USENIX Security 2023接收的论文,也是笔者作为第一作者的第二篇安全四大。
论文题目为“QFA2SR: Query-Free Adversarial Transfer Attacks to Speaker Recognition Systems”,作者信息如下图,均来自上海科技大学的系统与软件安全实验室,课题组PI宋富教授为通讯作者,其他作者包括课题组已通过博士学位答辩考核的张业迪博士以及赵哲博士:
论文信息
我们针对声纹识别系统的语音对抗样本鲁棒性,提出了一种不需要知道待攻击系统任何内部信息(黑盒)以及语音对抗样本生成过程中不需要对待攻击系统进行任何查询(无查询)的攻击。在无查询设置下,该攻击在4个商用API上的攻击成功率比已有最好攻击高20.9%-70.7%,如在微软的Azure上取得了89.6%的有目标对抗攻击成功率以及99.6%的无目标对抗攻击成功率;在3个语音助手上取得了46%-70%的攻击成功率,并且我们的攻击对人类听觉感知的影响可以忽略不计。
我们向涉及的供应商汇报了我们的攻击暴露的安全漏洞,除致谢外,其中一个供应商将我们汇报的漏洞定位为中等等级漏洞,并且给予我们现金奖励。
背景
声纹识别,又称说话人识别,指的是根据一个人的语音推断一个人的身份,被广泛用于访问控制,包括智能家居中设备的权限控制和App的声纹登录(如微信以及上海银行的声纹锁);身份鉴别,如TD-bank和Citi-bank在客户通话中使用声纹识别进行身份校验,天猫精灵支持声纹支付;语音助手的个性化唤醒和激活,如Siri和Google Assistant只能被注册的设备所有者激活。声纹识别可以分为说话人辨认(1:N)以及说话人确认(1:1)两种任务。前者有多个注册说话人,系统判定输入语音来自哪一个注册说话人或不来自任意注册说话人(即认为是假冒者),后者只有一个注册说话人,系统判定输入语音是否来自该注册说话人。
针对声纹识别的语音对抗样本攻击可以达到以下目的:使得来自说话人A的语音被声纹识别系统判定为来自说话人B。本文中我们关注三个典型的攻击场景:(1)1:N任务中,说话人A是假冒者(即非注册说话人),说话人B为注册说话人组中指定的一人(有目标攻击);(2)1:N任务中,说话人A是假冒者,说话人B为注册说话人组中任意一人(无目标攻击);(3)1:1任务中,说话人A是假冒者,说话人B是注册说话人。
已有的攻击要么假设攻击者知道待攻击系统的内部信息(白盒攻击),要么需要在生成语音对抗样本过程中对待攻击系统进行黑盒查询(如我们发表在计算机安全四大顶会之一的IEEE S&P 2021的FakeBob攻击),且为了取得较好攻击效果,查询次数往往较大。但对于商用系统,白盒攻击不现实,黑盒查询需要收费或有查询频率限制,且语音助手等系统不提供用于查询的API接口。针对这个问题,我们提出了一种不需要知道待攻击系统任何内部信息(黑盒)以及语音对抗样本生成过程中不需要对待攻击系统进行任何查询(无查询)的攻击。
攻击方法
我们攻击的主要思路是利用语音对抗样本的迁移性,即在一个模型上生成的语音对抗样本有可能在另一个模型保留对抗性,因此攻击者可以在白盒的本地系统模型上产生对抗样本,然后尝试迁移到待攻击系统上。但这里存在的挑战是,语音对抗样本的迁移性很低,我们的实验显示,即使本地和待攻击系统的架构和训练集完全一样,迁移率也不足6%。
针对这个问题,我们提出了三个方法用于语音对抗样本的迁移性,分别为Tailored Loss Functions, SRS Ensemble以及Time-Freq Corrosion。注:SRS是speaker recogntion system的简称。
Tailored Loss Functions
由于语音对抗样本的生成被建模为一个优化问题,因此我们认为优化的损失函数是很重要的。基于这个假设,我们对每个攻击场景考虑了多种损失函数,包括其他领域常用的Cross-entropy和Margin损失函数,以及我们设计的新的损失函数。
如下两图所示,Cross-entropy和Margin损失函数,特别是后者的性能明显低于其他损失函数。这是由声纹系统独特的基于阈值的决策机制决定的,语音对抗样本的最大得分必须要超过某个阈值才能攻击成功。Cross-entropy和Margin损失函数在优化的时候会“走捷径”,通过降低其他注册说话人的得分来减小损失函数,而不是像我们设计的其他损失函数一样通过提高指定注册说话人的得分来减小损失函数。
f_CE和f_M分别是Cross-entropy和Margin损失函数
f_CE^s和f_M^s分别是Cross-entropy和Margin损失函数
SRS Ensemble
顾名思义,该方法使用多个本地白盒模型,同时在他们上面生成语音对抗样本,使得生成的语音对抗样本能“愚弄”尽可能多的本地模型,这样就有更多的可能性对未知的待攻击系统具有对抗性。
模型集成攻击并非我们首次提出,我们的独特贡献在于针对声纹识别系统独特的得分特性提出了两个策略来增强集成攻击的效果:(1)之前的模型集成攻击往往对所有模型采用相等的集成权重。由于声纹识别系统的打分方法的不同,系统的输出以及计算得到的损失函数的范围会差异很大,如PLDA这种打分方法理论上是没有上下界的,而余弦相似度这种打分方法的范围为[-1,1]。因此,如果沿用之前的权重设置方法,会使得模型集成攻击偏重输出值大的模型,从而削弱模型集成攻击的效果。针对此,我们通过动态维护和更新每个模型的损失函数的均值和方差,自动和动态地为每个模型设置合适地权重。如图所示,除了两个模型,我们的方法远远胜于采用相等的集成权重。
表中ASR代表攻击成功率;S和T分别代表本地模型和待攻击的黑盒模型;Best-single指最好的单一本地模型攻击(不使用模型集成);Uniform-Ens和Dynamic-Ens分别指采用相等的集成权重以及我们的动态权重
(2)由于我们考虑的三个攻击场景的原始语音来自假冒者,对无目标攻击,由于不同本地模型上的注册说话人打分排序不同,不同本地模型的优化方向(即要使得语音对抗样本被识别为哪一个注册说话人)可能有差异,这样情况下的模型集成会互相牵制,削弱模型集成效果。针对这个问题,我们基于注册说话人打分在单个模型上的排序(称为local rank)定义两种global rank (基于voting以及基于summation)。使用global rank可以统一化不同本地模型的优化方向。如下图所示,采用global rank的无目标攻击的成功率远远超过local rank。
same-enroll/differ-enroll指本地模型和待攻击模型的注册语音相同/不同
Time-Freq Corrosion
我们猜想语音对抗样本迁移性差的原因在于,由于架构、训练集、语音声学特征以及打分方法等差异,本地模型和待攻击模型学习到的分布以及决策边界有较大差异。基于此,我们设计许多带随机性的转换函数,这些转换函数被嵌入到本地模型的合适位置,在生成语音对抗样本的每次迭代,中间的语音对抗样本会被随机处理变换,通过这种方法去尽量模拟和逼近待攻击模型的分布和决策边界。
和图像识别等视觉系统不同,目前的语音处理系统(包括声纹识别)往往仍需要依赖于人工的特征工程,即神经网络的输入是对波形进行频域处理得到的语音声学特征。受此启发,我们从时域以及频域设计转换函数。两者的区分在于转换函数的输入分别为波形以及语音声学特征。
时域转换函数:加混响、加高斯噪声、调整语音速率、舍弃部分语音片段、舍弃部分频率分量。
频域转换函数:时域扭曲、时域掩盖、频域掩盖。
更多有关转换函数的信息可参考我们的论文。我们还考虑了这些转换函数的顺序和并行结合。如下图所示,每种转换函数均能提高迁移率,且它们的结合取得了最好的效果,远远优于baseline攻击。
Serial: 顺序结合;parallel: 并行结合
实验结果
商用APIs(Microsoft Azure; TalentedSoft; iFLYTEK; Jingdong)
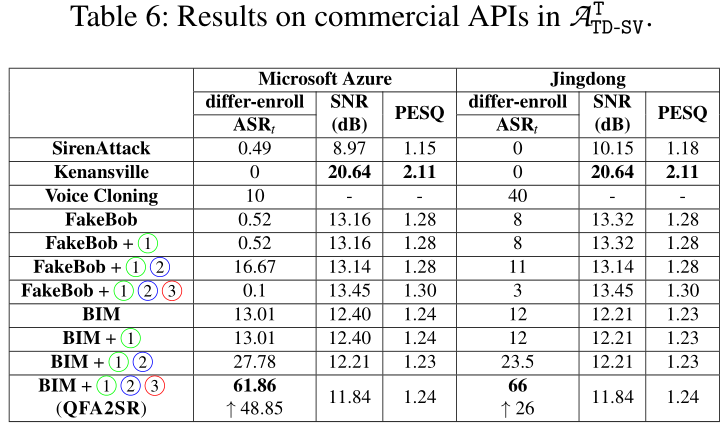
如下两图可见,我们提出的攻击远远优于已有攻击,取得比最好的已有攻击高20.9%-70.7%的有目标攻击成功率。特别是在微软的Azure平台上,本文提出的方法取得了89.6%的有目标对抗攻击成功率以及99.6%的无目标对抗攻击成功率。并且,在大多数情况,我们提出的三个方法对提升迁移性都是有贡献的,其中Time-Freq Corrosion的贡献最大。
攻击场景(1)和(2):ASR为攻击成功率,SNR和PESQ为衡量人类听觉感知的指标
攻击场景(3)
针对语音助手的攻击:谷歌语音助手;苹果Siri; 阿里天猫精灵
其他实验结果:
我们还进行了人类听觉测试,证实我们的攻击在提高迁移性的同时,不会恶化语音对抗样本的不可感知性(隐蔽性)。
我们还实验验证了在1:N任务中(对应攻击场景2和3),当攻击者只知道且仅拥有目标受害者的语音时,我们的攻击的有效性要么变化不大,要么仍远远高于已有攻击。
另外,我们实验验证了本文提出的攻击方法对拥有大量注册说话人的声纹识别系统的scalability。
实验评估了输入变换类防御和语音活性检测两种防御对我们攻击的防御效果。
讨论
我们论文里讨论了后续可行的工作,详见论文章节8:
如何进一步提高攻击的迁移性,如是否可以集成动量的方式等。
对抗迁移性差不仅存在于声纹识别里,语音识别和字典攻击等也是一样的问题,那么很自然的一个问题是我们提出的方法是否对这些任务的迁移性有利?
后记
欢迎大家拍砖、交流以及合作!
如果你想进一步了解我们的工作,可以访问:
QFA2SR论文:https://arxiv.org/abs/2305.14097(点击阅读原文即可跳转)
QFA2SR网站(攻击音频+视频):https://sites.google.com/view/qfa2sr
另外,也欢迎观摩我们之前3项关于声纹识别对抗鲁棒性的工作,均发表于计算机安全顶级会议或期刊,如下:
[1] Oakland 2021论文:FakeBob https://zhuanlan.zhihu.com/p/165665859 [2] IEEE TDSC论文:AS2T https://zhuanlan.zhihu.com/p/539808768 [3] IEEE TDSC: SpeakerGuard https://speakerguard.github.io
作者:陈光科
编辑:赵哲
如有侵权请联系:admin#unsafe.sh