本文翻译自:https://kubernetes.io/blog/2021/12/22/kubernetes-in-kubernetes-and-pxe-bootable-server-farm/作者 2023-6-5 08:2:17 Author: Docker中文社区(查看原文) 阅读量:38 收藏
本文翻译自:https://kubernetes.io/blog/2021/12/22/kubernetes-in-kubernetes-and-pxe-bootable-server-farm/
作者:Andrei Kvapil
本文翻译自Andrei Kvapil的文章,其中对文字有部分的整理和删减。
WEDOS Internet a.s工作,今天我将向您展示我的两个项目——Kubernetes-in-Kubernetes【1】 和 Kubefarm【2】。使用它们,就可以使用Helm在一个Kubernetes集群中部署一个完整的Kubernetes集群。
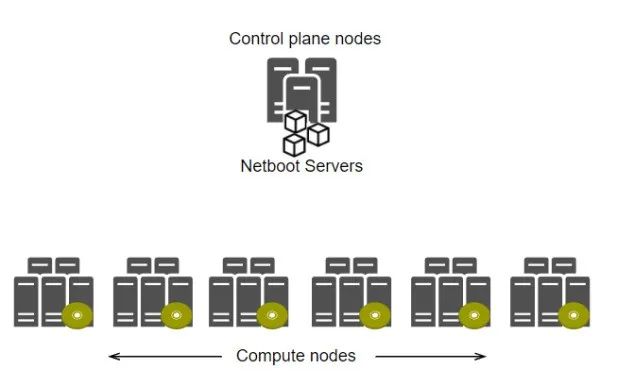
首先介绍一下我们基础设施是如何工作的。我们将物理服务器分为两组:控制平面和计算节点。其中控制平面通常是手动设置并且安装稳定的操作系统,旨在运行包括Kubernetes在内的所有集群服务,这些节点用于保障Kubernetes集群本身的稳定运行。而计算节点是没有安装任何操作系统的,在需要的时候,会直接通过控制平面节点通过网络下载镜像。
当节点把镜像下载下来过后,它们就可以继续后续的工作而不需要一直和PXE服务器建立连接。也就是说,PXE 服务器只保存 rootfs 映像,不保存任何其他复杂的逻辑。在我们的节点启动后,我们可以安全地重新启动 PXE 服务器,它们不会发生任何严重的事情。当计算节点启动后,就需要使用
kubeadm join命令将其加入Kubernetes集群,这样才会将Pod调度到该计算节点并且启动工作负载。从一开始,当节点加入到用于控制平面节点的同一集群时,就使用了该方案并且稳定运行了两年多,后面我们决定向里面添加容器化的Kubernetes。现在我们可以很容易的在控制平面生成新的Kubernetes集群,而且这些计算节点也变成了特殊的集群成员。截至目前,根据不同的配置可以将计算节点加入到不同的集群中。
Kubefarm
Kubefarm项目的目标是让任何人都可以使用Helm来部署基础设施已达到预定的效果。
为此,我们放弃了单集群的想法。事实证明,在同一个集群中管理多个开发团队的工作不是很方便,并且Kubernetes 从未被设计为多租户解决方案,因为它并没有提供足够的项目之间的隔离手段。因此,为每个团队运行单独的集群被证明是一个好办法, 但是集群不能太多,不然不方便管理。
重构之后,我们集群的可扩展性明显更好,拥有的集群越多,故障域越小,它们的工作就越稳定,作为回报,我们得到了一个完全声明式描述的基础设施, 因此,现在您可以像在 Kubernetes 中部署任何其他应用程序一样部署新的 Kubernetes 集群。
它使用 Kubernetes-in-Kubernetes【1】作为基础,LTSP 作为 PXE-server,节点从中启动,并使用 dnsmasq-controller 自动配置 DHCP 服务器。
它是如何工作的?
现在我们来看看它是如何工作的。
如果从应用角度来看Kubernetes,你可以发现它完全遵循十二要素【3】的所有原则,因此,如果仅仅将Kubernetes当成一个应用,将其部署到Kubernetes中是一件理所当然的事情。
在Kubernetes中运行Kubernetes
现在来看看Kubernetes-in-Kubernetes【1】项目,它提供现成的Helm Chart【4】,帮助我们快速的在Kubernetes中部署Kubernetes。
使用以下命令,就可以在Kubernetes中部署一套Kubernetes集群。
helm repo add kvaps https://kvaps.github.io/charts
helm install foo kvaps/kubernetes --version 0.13.1 \
--namespace foo \
--create-namespace \
--set persistence.storageClassName=local-path
描述文件在value.yaml文件中,它主要描述了Kubernetes控制器组件:Etcd集群、apiserver、controller-manager、scheduler等,这些都是标准的Kubernetes组件。
如果你打算使用kubeadm安装集群,value.yaml就是其配置,但是除了kubernetes之外,还有一个管理容器,其主要包含两个二进制文件:kubectl和kubeadm,它们用于为kubernetes集群生成kubeconfig并执行集群初始化,除此之外,你还可以通过这个管理容器来检查和管理你的kubernetes集群。
待集群部署完成过后,就可以看到一系列的Pod:admin-container,apiserver,controller-manager,etcd-cluster,scheduller以及初始化集群的Job。在最后会展示如何进入admin-container的命令,如下:
另外,我们可以通过以下命令查看kubernetes集群证书。如果使用过kubeadm安装过kubernetes集群,一定知道/etc/kubernetes/pki 目录,它是用来存放kubernetes证书的。对于Kubernetes-in-Kubernetes,你可以使用cert-manager对集群证书进行管理,只需要在使用Helm进行安装的时候传递证书参数,cert-manager就可以帮你自动生成所有证书。
我们来查看其中一个证书,比如apiserver,你可以看到它有一个DNS名称和IP地址列表,如果想通过外部访问集群,只需要在配置文件中描述额外的DNS名称并更新版本,cert-manager就会帮助我们重新生成证书,并且不必担心kubeadm证书更新的问题,因为cert-manager会管理并自动更新它们。
现在,我们可以进入管理容器查看集群状态和节点信息,当然,现在集群是没有节点的,因为我们仅仅部署了kubernetes控制平面,但是我们可以在kube-system名称空间下coredns pod以及一些configmap,如下。
下面是一个集群示意图,你可以看到kubernetes的整个控制平面:apiserver、controller-manager、etcd-cluster以及scheduler。还有一些流量的转发路径。
改图是通过argocd生成---argocd是一个gitops工具,如上的图表只是它的工具之一。
编排物理服务器
通过上面的介绍,我们知道如何在Kubernetes中部署控制平面,但是并没有添加任何工作节点,我们应该如何添加它们呢?我之前介绍过,我们所有的服务器都是裸机,不使用任何虚拟化来运行Kubernetes,而是自己编排所有的物理服务器。
此外,我们非常积极的使用Linux网络引导功能(注意这里指的是网络引导而不是某种自动化安装)。当节点启动时,我们只为它运行一个现成的镜像,也就是说,如果要修改或者更新节点,只需要更新镜像,然后重启即可,这是不是非常容易、简单和方便。
为此,我们创建了kubefarm【5】项目,它可以自动完成上述的操作。样例操作可以参考examples【6】目录,其中稳定版我们命名为:generic,我们可以到value.yaml中查看配置信息。
generic/values.yaml
我们可以在value.yaml中定义传递给kubernetes-in-kubernetes chart的参数,如果想从外部访问控制平面,可以在value.yaml中定义IP地址,除此之外,还可以定义一些DNS。
在PXE的服务配置中(ltsp模块),我们可以指定时区、可以添加SSH密钥以及在系统引导期间的内核模块以及参数等。
接下来就是nodePools的配置,即work节点的配置,如果你之前使用过GKE的terraform ,那你应该能快速上手。在这里,我们通过以下参数来描述所有work节点。
Name:主机名 MAC-address:我们有带有两个网卡的节点,每个节点都可以在此处指定MAC地址,然后以指定的MAC地址启动 IP-address:用于DHCP服务发现
在上面的value.yaml中,我们定义了两个node pools:第一个pool定义了5个node节点,第二个pool定义了一个node节点,不过定义了两个tags,tag是用来描述节点配置的。比如,你可以为某些特定的pool添加DHCP选项用于启动PXE服务以及一组KubernetesLabels和KubernetesTaints选项。
比如,在上面的配置中的第二个pool里配置了一个节点,这个pool分配了debug和foo标记,现在查看kubernetesLabels中的foo标记选项,其意味着m1c43节点将分配这两个labels和taint。一切看起来都那么简单,下面将进行具体的实践。
样例实践
到example【6】目录中更新kubefarm的chart包,其中generic目录下是通用配置,如下图更新即可。这时候查看集群Pods,就可以看到一个PXE服务和许多的job被添加运行。Job是用来部署Kubernetes集群和创建Token,它每隔12小时会创建一个新的Token,以便这些节点能连接到你的集群。
在argocd的图表上查看如下,apiserver进行对外暴露。
在图中,IP 以绿色突出显示,可以通过它访问 PXE 服务器。目前,Kubernetes 默认不允许为 TCP 和 UDP 协议创建单个 LoadBalancer 服务,因此您必须创建两个具有相同 IP 地址的不同服务, 一个用于 TFTP,第二个用于 HTTP,通过它下载系统映像。
当然这只是一个简单的示例,有时候你需要在启动的时候修改逻辑,比如在advanced_network【7】目录下,其中有一个带有简单 shell 脚本的值文件。我们称之为network.sh,它是用来修改网络相关的配置:
network.sh
该脚本所做的只是在启动时获取环境变量,并根据它们生成网络配置, 它会创建一个目录并将 netplan 配置放入其中。例如,在这里创建一个绑定接口。基本上,这个脚本可以包含你需要的一切。它可以保存网络配置或生成系统服务,添加一些钩子或描述任何其他逻辑。,任何可以用 bash 或 shell 语言描述的东西都可以在这里工作,并且会在启动时执行。
现在我们来看看其是如何被部署的,通过传递一些value文件来传递参数,这是Helm的正常使用方式。这种方式可以传递一些secrets,但是在这个示例中,扩展配置文件在第二个values.yaml中。
我们可以查看针对netboot的配置文件foo-kubernetes-ltsp,确保network.sh是存在的,这些配置主要在网络引导时使用。
你可以在这里【8】查看其工作原理,可以通过输入show node list查看所有的节点,如下:
你也可以通过show node macaddr all命令来查看节点的mac地址。我们定义了一个Operator自动从机箱搜集Mac地址并传递给DHCP服务器。实际上,它只是为同一个管理集群中的dnsmsap-controller创建自定义配置,另外,通过这个接口可以控制节点本身,比如打开或者关闭它们。
如果您没有通过 iLO 进入机箱并为您的节点收集 MAC 地址列表的机会,您可以考虑使用包罗万象的集群模式。纯粹来说,它只是一个带有动态 DHCP 池的集群。因此,所有未在其他集群的配置中描述的节点将自动加入该集群。
如上,你可以看到该集群的work节点就是通过自动加入的方式加入集群的,它们的名字是通过其MAC地址自动生成。你可以通过node-shell 命令连接节点并查看其状态,你也可以在这里初始化它们,比如设置文件系统或将其加入其他的集群。
现在让我们连接到其中一个节点并观察其是如何启动的。当BIOS之后,就会配置网卡,并通过特定的MAC地址向DHCP服务器发送请求,然后会被重定向到PXE服务,最后通过HTTP方式从服务端下载kernel和initrd镜像。
kernel加载完成过后,work节点就会下载rootfs镜像并将控制权交给systemd,引导会继续进行,然后会加入Kubernetes集群。
如果你查看fstab文件,你可以看到只有两个目录挂载:/var/lib/docker和/var/lib/kubelet,它们被挂载为tmpfs。同时,根分区挂载为overlayfs,因此,你对系统做的任何修改在下次重启过后都会丢失。
查看节点上的块设备,您可以看到一些 nvme 磁盘,但它还没有挂载到任何地方, 还有一个loop设备 - -这是从服务器下载的确切 rootfs 映像,目前它位于 RAM 中,占用 653 MB 并使用loop选项安装。
如果你查看/etc/ltsp,你可以看到network.sh文件在启动的时候被执行。通过docker ps查看容器的话,可以看到kube-proxy和pause容器。
以上就完成了work节点初始化并加入Kubernetes集群。
其他
Network Boot Image
我们的主镜像从哪里来呢?这里其实是有个小技巧,节点的镜像是通过这个Dockerfile【9】构建而来,Docker的多阶段构建允许你灵活添加一个包和模块,我们可以通过链接来看看这个Dockfile【9】。
首先,我们使用Ubuntu 20.04镜像并安装需要的软件包,我们会安装kernel、lvm、systemd、ssh。一般来说,你期望节点拥有什么能力都应该在这里配置描述。这里我们还安装了带有kubelet和kubeadm的Docker,用于将node加入集群。
然后我们执行额外的配置。在最后阶段,我们只需安装 tftp 和 nginx(将我们的映像提供给客户端)、grub(引导加载程序), 然后将先前阶段的根复制到最终图像中并从中生成压缩图像。实际上,我们得到了一个 docker 镜像,其中包含我们节点的服务器和启动镜像,我们可以通过更改 Dockerfile 轻松更新配置。
Webhooks and API aggregation layer
我特别关注webhooks和api aggregation layer的问题。一般来说,webhook是Kubernetes的一项功能,它允许你响应任何资源的创建和修改,因此,你可以添加一个处理程序,以便在应用资源时,kubernetes必须向某个pod发送请求检查该资源的配置是否正确,或者对其进行额外的修改。
但是关键的问题在于如果要让webhook工作,apiserver必须能够直接访问它正在运行的集群。如果它像我们的案例一样在单独的集群启动或者在其他集群分开启动,这时候我们就要借助Konnectivity【10】服务来为我们提供帮助。Konnectivity是Kubernetes官方支持的插件。
让我们以四个节点的集群为例,每个节点都运行一个 kubelet,我们还有其他 Kubernetes 组件在外部运行:kube-apiserver、kube-scheduler 和 kube-controller-manager。默认情况下,所有这些组件都直接与 apiserver 交互——这是 Kubernetes 逻辑中最知名的部分。但实际上,也存在反向连接,例如,当您要查看日志或运行 kubectl exec 命令时,API 服务器会独立建立与特定 kubelet 的连接。
但问题是,如果我们有一个 webhook,那么它通常作为标准 pod 运行,并在我们的集群中提供服务。当 apiserver 尝试访问它时,它将失败,因为它将尝试访问名为 webhook.namespace.svc 的集群内服务,但是该服务位于实际运行的集群之外。
这时,Konnectivity 可以帮助我们。Konnectivity 是一个专门为 Kubernetes 开发的代理服务器。它可以部署为 apiserver 旁边的服务器,并且 Konnectivity-agent 直接部署在您要访问的集群中的多个副本中,代理建立与服务器的连接并设置稳定的通道以使 apiserver 能够访问集群中的所有 webhook 和所有 kubelet。因此,现在与集群的所有通信都将通过 Konnectivity-server 进行。
计划
当然,我们不会停留在这个阶段。对这个项目感兴趣的人经常给我写信。如果有足够多的感兴趣的人,我希望将 Kubernetes-in-Kubernetes 项目移到 Kubernetes SIGs 下,以官方 Kubernetes Helm Chart的形式表示。也许,通过使这个项目独立,我们将聚集一个更大的社区。
我也在考虑将它与机器控制器管理器集成,这将允许创建工作节点,不仅是物理服务器,例如,用于使用 kubevirt 创建虚拟机并在同一个 Kubernetes 集群中运行它们。顺便说一句,它还允许在云中生成虚拟机,并在本地部署控制平面。
我还在考虑与 Cluster-API 集成的选项,以便您可以直接通过 Kubernetes 环境创建物理 Kubefarm 集群。但目前我并不完全确定这个想法。如果您对此事有任何想法,我很乐意听取他们的意见。
如有侵权请联系:admin#unsafe.sh