一tvm简介一句话概括就是腾讯自家的虚拟化加密壳。把腾讯的安全产品拉入 PE 工具,看到区段中有.tvm0那就没跑了。demo 这次还原用到的demo是前段时间游戏安全技术竞赛的决赛附加题(https 2023-6-5 18:0:21 Author: 看雪学苑(查看原文) 阅读量:49 收藏
一
tvm简介
.tvm0那就没跑了。demo
二
资料
idapython安装以下的库:import capstone
import keystone
import copy
import unicorn
三
混淆
1400d302c : not r10 ,R10 <-- ffffffffffffffff
1400d302f : xchg rax, r10 ,RAX <-- ffffffffffffffff ,R10 <-- 0
1400d3031 : mov [rbp+var_s8], r10
1400d3035 : not rax ,RAX <-- 0
1400d3038 : xchg rax, r10
1400d3031 : mov [rbp+var_s8], rax
idapython/TVMunicornTrace.py .tvmFunTask.mabe_1()1400d5b36 : xchg rax, r11 ,RAX <-- 14006024c ,R11 <-- 0
1400d5b38 : mov rax, [rbp+98h]
1400d5b3f : not rax ,RAX <-- fffffffebff9fdb3
1400d9148 : xchg rax, r11 ,RAX <-- 0 ,R11 <-- fffffffebff9fdb3
1400d914a : not r11 ,R11 <-- 14006024c
1400d5b38 : mov r11, [rbp+98h]
idapython/TVMunicornTrace.py .tvmFunTask.mabe_2()1400d9156 : push r10 ,RSP <-- 1500
1400d9158 : lea r10, loc_1400E1D70+2 ,R10 <-- 1400e1d72
1400d915f : lea r10, [r10-0A812h] ,R10 <-- 1400d7560
1400d9166 : jmp r101400d7560 : pop r10 ,RSP <-- 1508 ,R10 <-- 0
1400d9156 : jmp 1400d7560 1400d7560 : nop
idapython/TVMunicornTrace.py .tvmFunTask.mabe_3_4()1400d7240 : push r10 ,RSP <-- 1500
1400d7242 : mov r10, 14011A470h ,R10 <-- 14011a470
1400d724c : pushfq ,RSP <-- 14f8
1400d724d : add r10, 0FFFFFFFFFFFBF569h ,R10 <-- 1400d99d9 ,RF <-- 3
1400d7254 : popfq ,RSP <-- 1500 ,RF <-- 12
1400d7255 : jmp r101400d99d9 : pop r10 ,RSP <-- 1508 ,R10 <-- 1638
1400d7240 : jmp 1400d99d9 1400d99d9 : nop
idapython/TVMunicornTrace.py .tvmFunTask.mabe_3_4()四
TVM
如何进入虚拟机
idapython/TVMunicornTrace.pytrace_file/tvm入口到出口 去混淆.logtrace_file/tvm入口到出口 未去混淆.log140086efa : call sub_1400085E8 ,RSP <-- 17f8 //这个函数被vm
1400085e8 : jmp sub_1400D2FF4
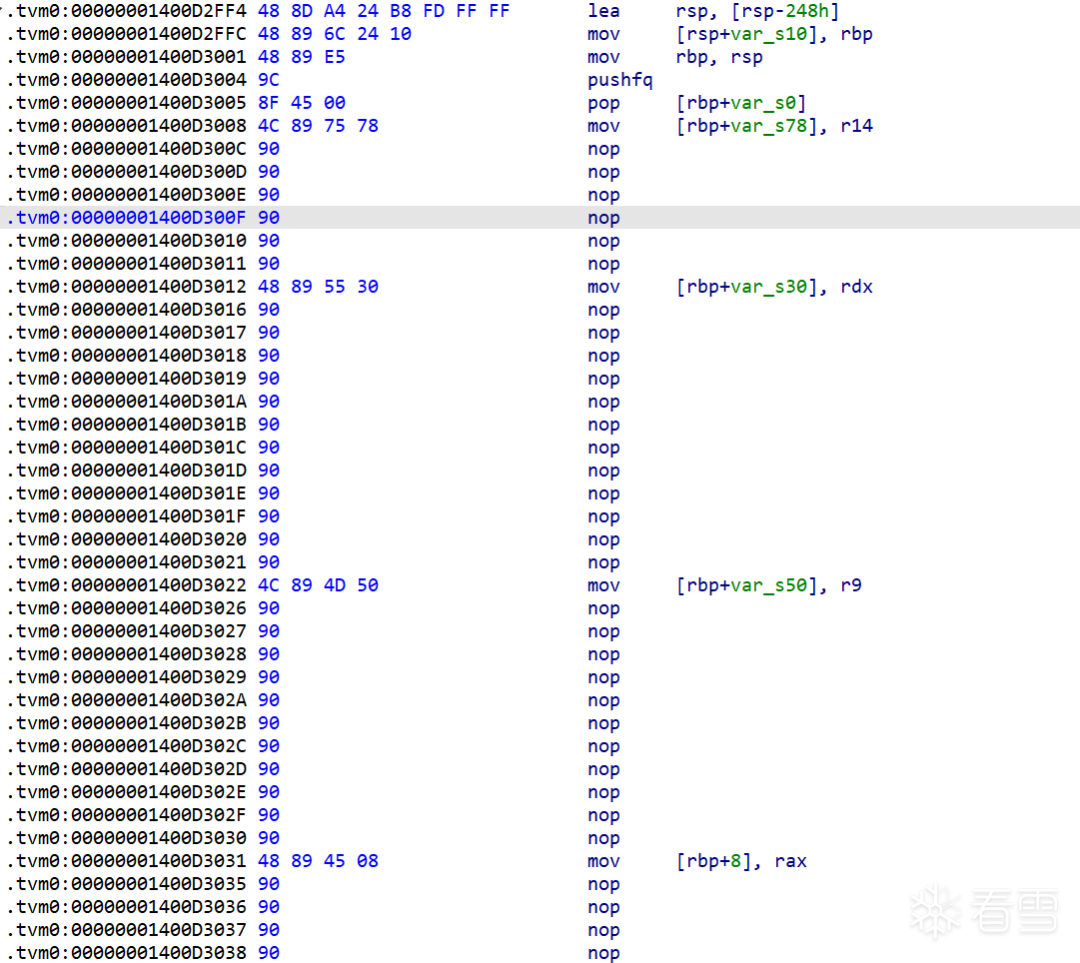
1400d2ff4 : lea rsp, [rsp-248h] ,RSP <-- 15b0 //开辟虚拟机栈空间
1400d2ffc : mov [rsp+10h], rbp //保存进入虚拟机时的寄存器状态
1400d3001 : mov rbp, rsp ,RBP <-- 15b0
1400d3004 : pushfq ,RSP <-- 15a8
1400d3005 : pop [rbp+0h] ,RSP <-- 15b0
1400d3008 : mov [rbp+78h], r14
1400d3012 : mov [rbp+30h], rdx
1400d3022 : mov [rbp+50h], r9
1400d3031 : mov [rbp+8h], rax
1400d303f : mov [rbp+60h], r11
1400d3043 : jmp short loc_1400D3054
1400d305a : mov [rbp+18h], rbx
1400d305e : mov [rbp+40h], rsp
1400d3062 : mov [rbp+28h], rdi
1400d3066 : mov [rbp+70h], r13
1400d306f : mov [rbp+48h], r8
1400d3078 : mov [rbp+80h], r15
1400d3085 : mov [rbp+58h], r10
1400d308f : mov [rbp+38h], rsi
1400d3093 : mov [rbp+68h], r12
1400d3097 : jmp loc_1400D3145
1400d314c : mov [rbp+20h], rcx
1400d3156 : pushfq ,RSP <-- 15a8
1400d3157 : add qword ptr [rbp+40h], 248h #恢复成原来的栈顶
1400d315f : popfq ,RSP <-- 15b0
1400d3160 : lea r11, [rbp+90h] ,R11 <-- 1640
1400d3167 : push qword ptr [rbp+8] ,RSP <-- 15a8
1400d316a : pop qword ptr [r11] ,RSP <-- 15b0
1400d316d : push qword ptr [rbp+18h] ,RSP <-- 15a8
1400d3170 : pop qword ptr [r11+8] ,RSP <-- 15b0
1400d3174 : push qword ptr [rbp+20h] ,RSP <-- 15a8
1400d3177 : pop qword ptr [r11+10h] ,RSP <-- 15b0
1400d317b : push qword ptr [rbp+30h] ,RSP <-- 15a8
1400d317e : pop qword ptr [r11+18h] ,RSP <-- 15b0
1400d3182 : push qword ptr [rbp+40h] ,RSP <-- 15a8
1400d3185 : pop qword ptr [r11+20h] ,RSP <-- 15b0
1400d3189 : push qword ptr [rbp+10h] ,RSP <-- 15a8
1400d318c : jmp loc_1400D30DC
1400d30dd : pop qword ptr [r11+28h] ,RSP <-- 15b0
1400d30e1 : push qword ptr [rbp+38h] ,RSP <-- 15a8
1400d30e4 : pop qword ptr [r11+30h] ,RSP <-- 15b0
1400d30e8 : push qword ptr [rbp+28h] ,RSP <-- 15a8
1400d30eb : pop qword ptr [r11+38h] ,RSP <-- 15b0
1400d30ef : push qword ptr [rbp+48h] ,RSP <-- 15a8
1400d30f2 : pop qword ptr [r11+40h] ,RSP <-- 15b0
1400d30f6 : push qword ptr [rbp+50h] ,RSP <-- 15a8
1400d30f9 : pop qword ptr [r11+48h] ,RSP <-- 15b0
1400d30fd : push qword ptr [rbp+58h] ,RSP <-- 15a8
1400d3100 : pop qword ptr [r11+50h] ,RSP <-- 15b0
1400d3104 : push qword ptr [rbp+60h] ,RSP <-- 15a8
1400d3107 : pop qword ptr [r11+58h] ,RSP <-- 15b0
1400d310b : push qword ptr [rbp+68h] ,RSP <-- 15a8
1400d310e : pop qword ptr [r11+60h] ,RSP <-- 15b0
1400d3112 : push qword ptr [rbp+70h] ,RSP <-- 15a8
1400d3115 : pop qword ptr [r11+68h] ,RSP <-- 15b0
1400d3119 : push qword ptr [rbp+78h] ,RSP <-- 15a8
1400d311c : pop qword ptr [r11+70h] ,RSP <-- 15b0
1400d3120 : push qword ptr [rbp+80h] ,RSP <-- 15a8
1400d3126 : pop qword ptr [r11+78h] ,RSP <-- 15b0
1400d312a : push qword ptr [rbp+0] ,RSP <-- 15a8
1400d312d : jmp loc_1400D30A8
1400d30aa : pop qword ptr [r11+80h] ,RSP <-- 15b0
1400d30b1 : lea r11, byte_14006024B+1 ,R11 <-- 14006024c
1400d30b8 : lea r10, [rbp+88h] ,R10 <-- 1638
1400d30bf : lea rsp, [rsp-8] ,RSP <-- 15a8
1400d30c4 : mov [rsp], r10
1400d30c8 : lea rsp, [rsp-8] ,RSP <-- 15a0
1400d30cd : mov [rsp], r11
1400d30d1 : call sub_1400D5B02 ,RSP <-- 1598
1400d5b02 : lea rsp, [rsp-8] ,RSP <-- 1590
1400d5b07 : mov [rsp+8+var_8], rbx
1400d5b0b : lea rsp, [rsp-8] ,RSP <-- 1588
1400d5b10 : mov [rsp+10h+var_10], rsi
1400d5b14 : lea rsp, [rsp-8] ,RSP <-- 1580
1400d5b19 : mov [rsp+18h+var_18], rdi
1400d5b1d : lea rsp, [rsp-8] ,RSP <-- 1578
1400d5b22 : mov [rsp+20h+var_20], rbp
1400d5b26 : lea rsp, [rsp-8] ,RSP <-- 1570
1400d5b2b : mov [rsp+28h+var_28], r15
1400d5b2f : sub rsp, 68h ,RSP <-- 1508 ,RF <-- 12
1400d5b33 : mov rbp, rsp ,RBP <-- 1508
1400d5b38 : mov r11, [rbp+98h] ,R11 <-- V_RIP
1400d5b42 : jmp loc_1400D9146
1400d914f : mov r10, [rbp+0A0h] ,R10 <-- V_REG_p
1400d9156 : jmp loc_1400D7560
1400d756a : call loc_1400DA21F ,RSP <-- 1500
1400da21f : lea rsp, [rsp+8] ,RSP <-- 1508
1400da224 : lea r9, loc_1400E47B0 ,R9 <-- 1400e47b0
1400da22e : jmp loc_1400D8689
1400d868e : mov [rbp+0], r9
1400d8695 : jmp loc_1400DB455
1400db45f : mov [rbp+8], r11
1400d2ffc到1400d315f,tvm第一次保存进入虚拟机前的寄存器状态:rsp = rbp = 15b0
[15b0](rbp+0) rflag
[15b8](rbp+8) rax
[15c0](rbp+10) rbp (原来的栈底)
[15c8](rbp+18) rbx
[15d0](rbp+20) rcx
[15d8](rbp+28) rdi
[15e0](rbp+30) rdx
[15e8](rbp+38) rsi
[15f0](rbp+40) rsp (原来的栈顶)
[15f8](rbp+48) r8
[1600](rbp+50) r9
[1608](rbp+58) r10
[1610](rbp+60) r11
[1618](rbp+68) r12
[1620](rbp+70) r13
[1628](rbp+78) r14
[1630](rbp+80) r15
1400d3160 : lea r11, [rbp+90h] ,R11 <-- 1640 #接着往栈上保存原始寄存器状态
1400d3160到1400d30aa,保存状态如下:[1640](r11+0) rax
[1648](r11+8) rbx
[1650](r11+10) rcx
[1658](r11+18) rdx
[1660](r11+20) rsp
[1668](r11+28) rbp
[1670](r11+30) rsi
[1678](r11+38) rdi
[1680](r11+40) r8
[1688](r11+48) r9
[1690](r11+50) r10
[1698](r11+58) r11
[16a0](r11+60) r12
[16a8](r11+68) r13
[16b0](r11+70) r14
[16b8](r11+78) r15
[16c0](r11+80) rflag
1400d30b1 : lea r11, byte_14006024B+1 ,R11 <-- 14006024c //这个是V_RIP (即虚拟指令起始点)
1400d30b8 : lea r10, [rbp+88h] ,R10 <-- 1638 //这个是 V_REG_P
1400d30bf : lea rsp, [rsp-8] ,RSP <-- 15a8
1400d30c4 : mov [rsp], r10
1400d30c8 : lea rsp, [rsp-8] ,RSP <-- 15a0
1400d30cd : mov [rsp], r11
[15a0] V_RIP 虚拟指令起始点
[15a8] V_REG_P 1638(虚拟机寄存器)
14006024c这是当前函数的虚拟指令起始点,可以先记住,后面就知道为什么我这么说了。1400d30d1 : call sub_1400D5B02 ,RSP <-- 1598
[1598] = return add(call sub_1400D5B02 下一行的地址 是int3)
1400d5b02 : lea rsp, [rsp-8] ,RSP <-- 1590
1400d5b07 : mov [rsp+8+var_8], rbx
1400d5b0b : lea rsp, [rsp-8] ,RSP <-- 1588
1400d5b10 : mov [rsp+10h+var_10], rsi
1400d5b14 : lea rsp, [rsp-8] ,RSP <-- 1580
1400d5b19 : mov [rsp+18h+var_18], rdi
1400d5b1d : lea rsp, [rsp-8] ,RSP <-- 1578
1400d5b22 : mov [rsp+20h+var_20], rbp
1400d5b26 : lea rsp, [rsp-8] ,RSP <-- 1570
1400d5b2b : mov [rsp+28h+var_28], r15
[1570] r15 rbp = 15b0
[1578] rbp
[1580] rdi
[1588] rsi
[1590] rbx
1400d5b2f : sub rsp, 68h ,RSP <-- 1508 ,RF <-- 12
1400d5b33 : mov rbp, rsp ,RBP <-- 1508
1400d5b38 : mov r11, [rbp+98h] ,R11 <-- V_RIP
1400d5b42 : jmp loc_1400D9146
1400d914f : mov r10, [rbp+0A0h] ,R10 <-- V_REG_p
1400d9156 : jmp loc_1400D7560
1400d756a : call loc_1400DA21F ,RSP <-- 1500
1400da21f : lea rsp, [rsp+8] ,RSP <-- 1508 //进call又rsp+8,假装是jmp
1400da224 : lea r9, loc_1400E47B0 ,R9 <-- 1400e47b0 //这是int3 指令的地址
1400da22e : jmp loc_1400D8689
1400d868e : mov [rbp+0], r9
1400d8695 : jmp loc_1400DB455
1400db45f : mov [rbp+8], r11 V_RIP 放到 [1510]
虚拟机内RBP = RSP = 1508 ,R10 = V_REG_P
[1508] int3指令指针
[1510] V_RIP //当前执行到的位置
.....[1570] r15 rbp = 15b0
[1578] rbp
[1580] rdi
[1588] rsi
[1590] rbx
[1598] = return add(sub_1400D5B02 下一行的地址 是int3)[15a0] V_RIP //虚拟指令起始点,这是不会变的
[15a8] V_REG_P //1638(虚拟机寄存器),这是不会变的[15b0](rbp+0) rflag //这里以下是进入虚拟机前的寄存器状态
[15b8](rbp+8) rax
[15c0](rbp+10) rbp (原来的栈底)
[15c8](rbp+18) rbx
[15d0](rbp+20) rcx
[15d8](rbp+28) rdi
[15e0](rbp+30) rdx
[15e8](rbp+38) rsi
[15f0](rbp+40) rsp (原来的栈顶)
[15f8](rbp+48) r8
[1600](rbp+50) r9
[1608](rbp+58) r10
[1610](rbp+60) r11
[1618](rbp+68) r12
[1620](rbp+70) r13
[1628](rbp+78) r14
[1630](rbp+80) r15[1638] UnKnow V_REG_P = r10 = 1638 //虚拟机的虚拟寄存器从 1638 开始往下都是
[1640](r11+0) rax //这里以下是进入虚拟机前的寄存器状态
[1648](r11+8) rbx
[1650](r11+10) rcx
[1658](r11+18) rdx
[1660](r11+20) rsp
[1668](r11+28) rbp
[1670](r11+30) rsi
[1678](r11+38) rdi
[1680](r11+40) r8
[1688](r11+48) r9
[1690](r11+50) r10
[1698](r11+58) r11
[16a0](r11+60) r12
[16a8](r11+68) r13
[16b0](r11+70) r14
[16b8](r11+78) r15
[16c0](r11+80) rflag
handle分发
1400d7234 : mov r9, [rbp+8] ,R9 <-- 14006024c
1400d7240 : jmp loc_1400D99D9
1400d99db : mov r8b, [r9] ,R8 <-- e8
1400d99de : xor r8b, 5Dh ,R8 <-- b5 ,RF <-- 82
1400d99e2 : mov rdx, 25E9ECA9BDE22AEAh ,RDX <-- 25e9eca9bde22aea
1400d99ec : not rdx ,RDX <-- da161356421dd515
1400d99ef : lea rdx, [r9+rdx] ,RDX <-- da1613578223d761
1400d99f3 : jmp loc_1400D86A6
1400d86a8 : mov r9, 0DA161356421DD513h ,R9 <-- da161356421dd513
1400d86b2 : not r9 ,R9 <-- 25e9eca9bde22aec
1400d86b5 : lea r9, [rdx+r9] ,R9 <-- 14006024d
1400d86bf : mov [rbp+8], r9
1400d86c9 : movzx r8, r8b
1400d86cd : sub r8, 1 ,R8 <-- b4 ,RF <-- 6
1400d86d1 : jmp loc_1400D7E10
1400d7e11 : cmp r8, 0C8h ,RF <-- 93
1400d7e18 : jnb loc_1400D9954
1400d7e1e : lea r9, word_1400DB5AA ,R9 <-- 1400db5aa
1400d7e25 : mov r8, [r9+r8*8] ,R8 <-- d60f2
1400d7e29 : lea r9, cs:140000000h ,R9 <-- 140000000
1400d7e30 : jmp loc_1400D6558
1400d6559 : add r8, r9 ,R8 <-- 1400d60f2 ,RF <-- 2
1400d655c : jmp r8 //进入handle
1400D9954,说明这是未知的tvmopcode,出错。1400D9954是int3指令。小总结:
1.从 tvmopcode --> handle 的方式:
handleTableBase = 0x1400db5aa
Dllbase = 0x140000000
handle = Dllbase + qword[(tvmopcode^0x5d - 1)*8 + handleTableBase]
2.handle的个数:
tvmopcode^0x5d - 1 < 0xC8可以推测一共有 0xc8 ( 0~0xc7 )个 tvmopcode,例:handleTable的第 0x00 项: tvmopcode = (0x00 + 1) ^ 0x5d = 0x5c
......
handleTable的第 0x3c 项: tvmopcode = (0x3c + 1) ^ 0x5d = 0x60
......
handleTable的第 0xc7 项: tvmopcode = (0xc7 + 1) ^ 0x5d = 0x95
导出所有handle
idapython/TVMHandleOut.py)1400d9954 : 9a 9b 98 99 9c 9d e2 e3 e0 e1 e6 e7 e4 eb ec ed f2 f3 f0 f1 f6 f7 f5 fa fb f9 fe ff c2 c0 c1 c6 c7 c4 c5 c8 ce cf cc cd db d8 de df dc dd 23 26 27 24 2a 28 2e 2c 2d 32 33 30 31 36 37 34 35 3a 3b 38 39 3e 3f 3d 02 03 00 07 04 05 0a 0b 08 0e 0f 0d 12 13 10 17 14 15 1a 1b 18 1e 1f 1c 63 61 66 67 64 6b 69 6f 6c 71 76 77 74 7b 79 7e 7f 7c 53 50 55 5b 58 59 5e 5f 5c
1400d8eb1 : 5a
1400d5b5a : 54
1400d5cd8 : 57
1400db3d3 : 56
1400d761b : 51
1400da3e5 : 52
1400dabb0 : 4d
1400d8196 : 4c
1400d6c8c : 4f
1400d82fa : 4e
1400d6e7d : 49
1400d7172 : 48
1400d9374 : 4b
1400daa8e : 4a
1400db0f9 : 45
1400dae51 : 44
1400d8be2 : 47
1400d946b : 46
1400d995a : 41
1400daf90 : 40
1400d7a8a : 43
1400d5e10 : 42
1400d7258 : 7d
1400daecb : 78
1400d5d02 : 7a
1400d974c : 75
1400d7f26 : 70
1400d8e1b : 73
1400d8dbf : 72
1400d8362 : 6d
1400d6fc9 : 6e
1400d7c1f : 68
1400d63cd : 6a
1400d9abb : 65
1400d8431 : 60
1400d7797 : 62
1400da161 : 1d
1400d7313 : 19
1400d92b0 : 16
1400d9c5c : 11
1400dab1e : 0c
1400d86e2 : 09
1400d7352 : 06
1400dad5e : 01
1400d9524 : 3c
1400dad2c : 2f
1400d8b8d : 29
1400d7d39 : 2b
1400d8f7b : 25
1400d696f : 21
1400d71f5 : 20
1400d71b3 : 22
1400d770e : d9
1400da48c : da
1400d74d2 : d5
1400d70ee : d4
1400d95ad : d7
1400d6f6c : d6
1400d84d0 : d1
1400da357 : d0
1400d78f9 : d3
1400d7998 : d2
1400d8561 : c9
1400d624c : cb
1400d9169 : ca
1400d64ac : c3
1400d5c7b : fd
1400d9dd5 : fc
1400d6913 : f8
1400dafcf : f4
1400d7bc7 : ef
1400d7fc4 : ee
1400d9446 : e9
1400d60f2 : e8
1400d69e8 : ea
1400d9584 : e5
1400da10c : 9f
1400d8e89 : 9e
1400d8cdd : 95
handle_out/)。0xe8 p_a b_ULONG64 0x3F26
*(PULONG64)p_a = b_ULONG64;
v_mov_iregll_ll
----------------------------------------//虚线以上是分析出来的0x1400d60f5 : mov r9, [rbp+8]
0x1400d6102 : mov r8w, [r9] 这里取2字节 (取虚拟寄存器都是取2字节)
0x1400d6106 : xor r8w, 3F26h 异或 3F26(不同的handl异或的值不同) 得到 a,
0x1400d610c : mov rdx, 0F84A86395161A270h 所以就是取虚拟机寄存器 V_REG_P + a
0x1400d6116 : not rdx
0x1400d6119 : jmp loc_1400D9077
0x1400d9078 : lea rdx, [r10+rdx]
0x1400d907c : movzx r8, r8w
0x1400d9080 : mov rcx, 7B579C6AE9E5D8Eh
0x1400d908a : not rcx
0x1400d908d : add r8, rcx
0x1400d9090 : lea r8, [rdx+r8] p_a = r8 = V_REG_P + a
0x1400d9094 : lea r9, [r9+2] V_RIP+=2
0x1400d909b : mov rdx, [r9] b_ULONG64 从tvm指令表中取8字节
0x1400d909e : jmp loc_1400DA2DD
0x1400da2ed : mov [r8], rdx 放入 [r8],即放入 p_a
0x1400da2f0 : jmp loc_1400DA9AC
0x1400da9b4 : lea r9, [r9+8] V_RIP+=8
0x1400da9be : mov [rbp+8], r9 V_RIP放回[rbp+8]
0x1400da9c8 : jmp loc_1400DAC79
0x1400dac7c : mov r9, [rbp+8] 这里以下属于下一个handle分发,不用看
0x1400dac89 : mov r8b, [r9]
0x1400dac8c : xor r8b, 5Dh
0x1400dac90 : mov rdx, 0D3676A56DAFF3C65h
0x1400dac9a : jmp loc_1400D7763
0x1400d7764 : not rdx
0x1400d7767 : lea rdx, [r9+rdx]
0x1400d776b : mov r9, 2C9895A92500C398h
0x1400d7775 : not r9
0x1400d7778 : lea r9, [rdx+r9]
0x1400d777f : jmp loc_1400D5B91
0x1400d5b95 : mov [rbp+8], r9
0x1400d5b9e : movzx r8, r8b
0x1400d5ba2 : sub r8, 1; switch 200 cases
0x1400d5ba6 : jmp loc_1400D98A8
0x1400d98aa : cmp r8, 0C8h
0x1400d98b1 : jnb def_1400D655C;
v_opcode_op0_op1_op2_....._opn 例如:
v_mov_iregw_iregw :
从虚拟寄存器op1 取 2字节 放入虚拟寄存器op0
w 表示 USHORTv_mov_ipreg_iregl :
从虚拟机寄存器op1 取4字节,放入以虚拟机寄存器op0作为地址的空间,有点类似与:
mov [reg],regv_mov_iregb_b :
从tvm指令表中取1字节放入虚拟机寄存器op0中,类似于Asm中的立即数赋值:
mov reg,0xffv_and_oregl_iregl_iregl_oregl:(i 就是 in ,o 就是 out 的意思)
取虚拟寄存器op1 和 虚拟寄存器op2进行与运算,并将结果放入虚拟寄存器op0,与运算后的 rflag 放入 虚拟寄存器op3
l 表示 ULONG32v_cmp_iregll_iregll_oregl:
即为 cmp 虚拟寄存器op0,虚拟寄存器op1 ,cmp后的rflag 放入 虚拟寄存器op2
ll 表示 ULONG64
idapython/deTvm.py . tvmHandleTableInit())TVMTABEL.append("v_sar_oregll_iregll_iregb_oregl",0x01,0xF8BE)
TVMTABEL.append("v_or_oregll_iregll_iregll_oregl",0x1D,0x4AA7)
TVMTABEL.append("v_mov_iregll_iregl",0x2B,0xBF3E)
TVMTABEL.append("v_movzx_iregl_iregb",0x2F,0x7EE9)
TVMTABEL.append("v_ror_oregb_iregb_iregb_oregl",0x3C,0xF8E1)
TVMTABEL.append("v_mov_iregl_iregl",0x4A,0x564B)
TVMTABEL.append("v_mov_iregw_iregw",0x4B,0xD916)
TVMTABEL.append("v_add_oregb_iregb_iregb_oregl",0x4C,0xDD9D)
TVMTABEL.append("v_add_oregll_iregll_iregll",0x4D,0x477D)
TVMTABEL.append("v_add_oregl_iregl_iregl_oregl",0x4E,0xA9C7)
TVMTABEL.append("v_add_oregw_iregw_iregw_oregl",0x4F,0x82BC)
TVMTABEL.append("v_sub_oregl_iregl_iregl_oregl",0x5A,0xC198)
TVMTABEL.append("v_sar_oregl_iregl_iregb_oregl",0x06,0x8374)
TVMTABEL.append("v_and_oregl_iregl_iregl_oregl",0x6A,0x5CF0)
TVMTABEL.append("v_and_oregll_iregll_iregll_oregl",0x6D,0xD9B1)
TVMTABEL.append("v_and_oregl_iregl_iregl",0x6E,0xA1CE)
TVMTABEL.append("v_xor_oregl_iregl_iregl_oregl",0x7A,0xD8ED)
TVMTABEL.append("v_mov_ipreg_iregll",0x7D,0xD878)
TVMTABEL.append("v_shr_oregll_iregll_iregb_oregl",0x09,0x9D87)
TVMTABEL.append("v_int3",[0x9a,0x9b,0x98,0x99,0x9c,0x9d,0xe2,0xe3,0xe0,0xe1,0xe6,0xe7,0xe4,0xeb,0xec,0xed,0xf2,0xf3,0xf0,0xf1,0xf6,0xf7,0xf5,0xfa,0xfb,0xf9,0xfe,0xff,0xc2,0xc0,0xc1,0xc6,0xc7,0xc4,0xc5,0xc8,0xce,0xcf,0xcc,0xcd,0xdb,0xd8,0xde,0xdf,0xdc,0xdd,0x23,0x26,0x27,0x24,0x2a,0x28,0x2e,0x2c,0x2d,0x32,0x33,0x30,0x31,0x36,0x37,0x34,0x35,0x3a,0x3b,0x38,0x39,0x3e,0x3f,0x3d,0x2,0x3,0x0,0x7,0x4,0x5,0xa,0xb,0x8,0xe,0xf,0xd,0x12,0x13,0x10,0x17,0x14,0x15,0x1a,0x1b,0x18,0x1e,0x1f,0x1c,0x63,0x61,0x66,0x67,0x64,0x6b,0x69,0x6f,0x6c,0x71,0x76,0x77,0x74,0x7b,0x79,0x7e,0x7f,0x7c,0x53,0x50,0x55,0x5b,0x58,0x59,0x5e,0x5f,0x5c],0x0000)
TVMTABEL.append("v_jmp_iregxR11",0x9E,0x0AD7)
TVMTABEL.append("v_jmp_iregxR10",0x9F,0x2E72)
TVMTABEL.append("v_shl_oregll_iregll_iregb_oregl",0x11,0x5403)
TVMTABEL.append("v_shl_oregl_iregl_iregb_oregl",0x16,0xEEF7)
TVMTABEL.append("v_not_oregll_iregll",0x19,0x1400)
TVMTABEL.append("v_setz_oregb_iregl",0x20,0x0D45)
TVMTABEL.append("v_movsxd_iregll_iregl",0x21,0x8BC8)
TVMTABEL.append("v_setR8d_iregl",0x22,0x77D7)
TVMTABEL.append("v_movsx_iregl_iregb",0x25,0xD8E4)
TVMTABEL.append("v_movzx_iregl_iregw",0x29,0xF10A)
TVMTABEL.append("v_mov_ipreg_iregb",0x40,0xE304)
TVMTABEL.append("v_mov_iregll_ipreg",0x41,0xE229)
TVMTABEL.append("v_mov_ipreg_iregl",0x42,0x5431)
TVMTABEL.append("v_mov_ipreg_iregw",0x43,0x02CB)
TVMTABEL.append("v_mov_iregb_ipreg",0x44,0xBE8C)
TVMTABEL.append("v_mov_iregll_iregll",0x45,0x58FB)
TVMTABEL.append("v_mov_iregl_ipreg",0x46,0x10BC)
TVMTABEL.append("v_mov_iregw_ipreg",0x47,0x6F62)
TVMTABEL.append("v_mov_iregb_iregb",0x48,0xCFFE)
TVMTABEL.append("v_add_oregll_iregll_iregll_oregl",0x49,0x41AA)
TVMTABEL.append("v_not_oregll_iregll",0x51,0xDB42)
TVMTABEL.append("v_add_oregl_iregl_iregl",0x52,0x77C6)
TVMTABEL.append("v_not_oregb_iregb",0x54,0xDCF3)
TVMTABEL.append("v_not_oregl_iregl",0x56,0xE297)
TVMTABEL.append("v_not_oregw_iregw",0x57,0x666D)
TVMTABEL.append("v_or_oregb_iregb_iregb_oregl",0x60,0xFBFD)
TVMTABEL.append("v_or_oregl_iregl_iregl_oregl",0x62,0x7819)
TVMTABEL.append("v_and_oregll_iregll_iregll_oregl",0x65,0x2954)
TVMTABEL.append("v_and_oregb_iregb_iregb_oregl",0x68,0xD8A5)
TVMTABEL.append("v_and_oregb_iregb_iregb_oregl",0x70,0x64D1)
TVMTABEL.append("v_and_oregl_iregl_iregl_oregl",0x72,0x4A64)
TVMTABEL.append("v_and_oregw_iregw_iregw_oregl",0x73,0xB562)
TVMTABEL.append("v_xor_oregll_iregll_iregll_oregl",0x75,0x69C2)
TVMTABEL.append("v_xor_oregb_iregb_iregb_oregl",0x78,0x19C1)
TVMTABEL.append("v_ret_iregx",0x95,0x805C)
TVMTABEL.append("v_shr_oregb_iregb_iregb_oregl",0x0c,0x62D7)
TVMTABEL.append("v_dec_oregl_iregl_oregl",0xc3,0x467C)
TVMTABEL.append("v_inc_oregb_iregb_oregl",0xc9,0x4267)
TVMTABEL.append("v_inc_oregll_iregll_oregl",0xca,0x6EE0)
TVMTABEL.append("v_inc_oregl_iregl_oregl",0xcb,0x7FB4)
TVMTABEL.append("v_test_iregw_iregw_oregl",0xd0,0x0499)
TVMTABEL.append("v_test_iregb_iregb_oregl",0xd1,0x2A99)
TVMTABEL.append("v_test_iregll_iregll_oregl",0xd2,0x8606)
TVMTABEL.append("v_test_iregl_iregl_oregl",0xd3,0x7FDE)
TVMTABEL.append("v_cmp_iregw_iregw_oregl",0xd4,0x87DF)
TVMTABEL.append("v_cmp_iregb_iregb_oregl",0xd5,0x3728)
TVMTABEL.append("v_cmp_iregll_iregll_oregl",0xd6,0x637D)
TVMTABEL.append("v_cmp_iregl_iregl_oregl",0xd7,0xCBEF)
TVMTABEL.append("v_sbb_oregb_iregb_iregb_oregl",0xd9,0x3F78)
TVMTABEL.append("v_sbb_oregll_iregll_iregll_oregl",0xda,0x0E0D)
TVMTABEL.append("v_jmp_iregxRax",0xe5,0xCD84)
TVMTABEL.append("v_mov_iregll_ll",0xe8,0x3F26)
TVMTABEL.append("v_mov_iregl_l",0xe9,0x448A)
TVMTABEL.append("v_mov_iregll_ll",0xea,0x43EF)
TVMTABEL.append("v_mov_iregw_w",0xee,0x44B1)
TVMTABEL.append("v_mov_iregb_b",0xef,0x144C)
TVMTABEL.append("v_mul_oregll_oregll_iregll_iregll",0xf4,0xEB97)
TVMTABEL.append("v_jmp_ll",0xf8,0x0000)
TVMTABEL.append("v_rep stosb_iregll_iregb_iregll",0xfc,0x8D54)
TVMTABEL.append("v_je_iregb_ll_ll",0xfd,0xDE5E)
TVMTABEL.append("v_mov_iregll_ll",0xe8,0x3F26)
TVMTABEL.append("v_jmp_ll",0xf8,0x0000):
因为有一些指令,tvm并没有对其进行模拟,所以需要临时退出虚拟机,然后执行那种指令,再返回虚拟机。(下文细说)TVMTABEL.append("v_je_iregb_ll_ll",0xfd,0xDE5E)
当虚拟机寄存器op0为0x1时,V_RIP + op1 否则 V_RIP + op2,以实现虚拟机内的跳转TVMTABEL.append("v_ret_iregx",0x95,0x805C)
这是退出虚拟机的tvmasm,具体实现是恢复原始寄存器,然后通过ret退出虚拟机。TVMTABEL.append("v_jmp_iregxR11",0x9E,0x0AD7)
TVMTABEL.append("v_jmp_iregxR10",0x9F,0x2E72)
TVMTABEL.append("v_jmp_iregxRax",0xe5,0xCD84)
这三个tvmasm也是恢复原始寄存器,但是是通过jmp 跳出虚拟机 jmp r11、jmp r10、jmp raxTVMTABEL.append("v_mul_oregll_oregll_iregll_iregll",0xf4,0xEB97)
乘法,虚拟机寄存器op2 * 虚拟机寄存器op3
结果高64位放入 虚拟机寄存器op0 ,低64位放入 虚拟机寄存器op1
idapython/deTvm.py . traceTask.track()获取 tvmAsmTrace:
0x140001250参考trace_file/sub_0x140001250.logtraceTask.track(0) + traceTask.traceOut(),输出如下:XXREGNAME = {"PO_rax":0x08,
"PO_rbx":0x10,
"PO_rcx":0x18,
"PO_rdx":0x20,
"PO_rsp":0x28,
"PO_rbp":0x30,
"PO_rsi":0x38,
"PO_rdi":0x40,
"PO_r8":0x48,
"PO_r9":0x50,
"PO_r10":0x58,
"PO_r11":0x60,
"PO_r12":0x68,
"PO_r13":0x70,
"PO_r14":0x78,
"PO_r15":0x80,
"PO_rf":0x88}
[1638] UnKnow V_REG_P = r10 = 1638 //虚拟机的虚拟寄存器从 1638 开始往下都是
[1640](r11+0) rax //这里以下是进入虚拟机前的寄存器状态
[1648](r11+8) rbx
[1650](r11+10) rcx
[1658](r11+18) rdx
[1660](r11+20) rsp
[1668](r11+28) rbp
[1670](r11+30) rsi
[1678](r11+38) rdi
[1680](r11+40) r8
[1688](r11+48) r9
[1690](r11+50) r10
[1698](r11+58) r11
[16a0](r11+60) r12
[16a8](r11+68) r13
[16b0](r11+70) r14
[16b8](r11+78) r15
[16c0](r11+80) rflag
tvmAsm to Asm
v_mov_iregll_iregll ( iregll :PO_rsp ,iregll :[ r10 + 0xa8 ] );
第一个参数必须为 原始寄存器 PO_reg
这一句 ,会将 [r10 + 0xa8]的值放入 PO_rsp ,
那么我们就可以推测,原Asm 可能为 mov rsp,xxx (也不一定对,但至少可以还原出一条Asm)v_mov_ipreg_iregll ( iregll :PO_rsp ,iregll :[ r10 + 0xa8 ] );
同理可以推测 原Asm 为 mov qword ptr[rsp],xxx(也不一定对,但至少可以还原出一条Asm)v_jmp_ll ( ll :0x1400c7588 );
上文说过,tvm并不能模拟全部指令,有一些指令需要临时退出虚拟机去执行,所以遇到这种指令,必然可以还原出一条Asmv_ret_iregx、v_jmp_iregxR11、v_jmp_iregxR10、v_jmp_iregxRax
上文说过,这几个指令可以直接还原成 ret、jmp r11、jmp r10、jmp raxv_je_iregb_ll_ll
这个可以还原出 jcc + jmp (下文详解)v_rep stosb_iregll_iregb_iregll
这个可以还原出 rep stosb ,不用管参数v_test_iregx_iregx_oregl
可以还原成 testv_cmp_iregx_iregx_oregl
可以还原成 cmp
idapython/deTvm.py . traceTask.track())140059e46 : v_mov_iregll_iregll ( iregll :PO_rsp ,iregll :[ r10 + 0xa8 ] );<-----
140059e28 : v_and_oregll_iregll_iregll_oregl ( oregll :[ r10 + 0xa8 ] ,iregll :[ r10 + 0xb8 ] ,iregll :[ r10 + 0xb8 ] ,oregl :PO_rf );
140059e23 : v_not_oregll_iregll ( oregll :[ r10 + 0xb8 ] ,iregll :[ r10 + 0xb8 ] );
140059e07 : v_add_oregll_iregll_iregll_oregl ( oregll :[ r10 + 0xb8 ] ,iregll :[ r10 + 0xb0 ] ,iregll :[ r10 + 0xa0 ] ,oregl :PO_rf );
[r10 + 0xb0]:
140059e02 : v_not_oregll_iregll ( oregll :[ r10 + 0xb0 ] ,iregll :[ r10 + 0xa8 ] );
[r10 + 0xa0]:
140059df7 : v_mov_iregll_ll ( iregll :[ r10 + 0xa0 ] ,ll :0x28 );
140059df2 : v_mov_iregll_iregll ( iregll :[ r10 + 0xa8 ] ,iregll :PO_rsp );
idapython/deTvm.py . traceTask.VRegRecord()idapython/deTvm.py . tvmToAsm.optimize()[r10 + 0xb8] = ~(~rsp + 0x28) = rsp - 0x28 //前五句结合
[r10 + 0xa8] = [r10 + 0xb8] & [r10 + 0xb8] = [r10 + 0xb8] //没变化
sub rsp,0x28
sub rsp,0x28而不是lea rsp,[rsp - 0x28]是有讲究的:v_add_oregll_iregll_iregll_oregl,他是有输出 rflag的,并且放入的位置就是 PO_rf,说明这一句ASM是会影响标志位,而lea是不影响标志位的,所以将它还原成sub。手动还原 Asm
sub rsp,0x28
mov rcx,0x1400011a0
call sub_140005E38 #下文解释为什么 V_jmp_ll(0x1400c7588) 可以转换成 这个
mov byte ptr[0x14000d264],0x0
add rsp,0x28
ret
关于v_jmp_ll
0x1400c7588,然后往下跟(中间是还原真实寄存器),直到出现 mov rsp,[rsp] ,之后的下一句就是真实需要执行的ASM了。即为 call sub_140005E38。idapython/deTvm.py . tvmToAsm.vjmp_handle()补充:
140059dc2 : v_mov_iregb_b ( iregb :[ r10 + 0x90 ] ,b :0x6 );
140059dc6 : v_mov_iregll_ll ( iregll :[ r10 + 0x98 ] ,ll :0x1 );
140059dd1 : v_mov_iregll_ll ( iregll :[ r10 + 0xa0 ] ,ll :0x1 );
140059ddc : v_mov_iregll_ll ( iregll :[ r10 + 0xa8 ] ,ll :0x600 );
140059de7 : v_mov_iregll_ll ( iregll :[ r10 + 0x0 ] ,ll :0x140001250 );
140059df2 : v_mov_iregll_iregll ( iregll :[ r10 + 0xa8 ] ,iregll :PO_rsp );
140059df7 : v_mov_iregll_ll ( iregll :[ r10 + 0xa0 ] ,ll :0x28 );
140059e02 : v_not_oregll_iregll ( oregll :[ r10 + 0xb0 ] ,iregll :[ r10 + 0xa8 ] );
140059e07 : v_add_oregll_iregll_iregll_oregl ( oregll :[ r10 + 0xb8 ] ,iregll :[ r10 + 0xb0 ] ,iregll :[ r10 + 0xa0 ] ,oregl :PO_rf );
traceTaskRegTable为总赋值表, traceTaskRegList为单个虚拟机寄存器的赋值栈,
traceTaskReg为入栈的单个记录。
相关定义参考:idapython/deTvm.py 的三个类,命名同上
140059e02 : v_not_oregll_iregll ( oregll :[ r10 + 0xb0 ] ,iregll :[ r10 + 0xa8 ] );
[ r10 + 0xa8 ]的赋值记录栈traceTaskRegList,然后通过地址找到最近的一次赋值traceTaskReg,然后traceTaskReg记录了这一句traceCode,就可以找到了。140059df2 : v_mov_iregll_iregll ( iregll :[ r10 + 0xa8 ] ,iregll :PO_rsp );
idapython/deTvm.py . traceTask.VRegRecord()一些特殊的例子
xor edi,edi,那么第二个tvmToAsm能翻译成什么呢?mov ecx,edi,因为[r10 + 450]在前面已经放入了PO_rdi,下面又取它放入PO_rcx。v_mov_iregx_iregx(PO_reg , xxxx)那么我们就可以将xxxx的上一次赋值标记为PO_reg。v_mov_iregll_iregll ( iregll:PO_rdi ,iregll:[ r10 + 0x450 ] ); <-----------------
v_mov_iregll_iregl ( iregll:[ r10 + 0x450 ],iregl :[ r10 + 0x98 ] );
PO_rdi,那么当其他的workingTraceCode向上进行查找赋值表的时候,就可以找到PO_rdi,于是就优化为了:idapython/deTvm.py . traceTask.VRegRecord()关于push和pop
mov qword ptr[rsp - 0x8],r13
lea rsp,[rsp - 8]
push r13分开成两句执行,可是如果是pop,那么情况就有点不同了:lea rsp,[rsp + 8]
mov r13,qword ptr[rsp]
pop r13指令,那么问题出在哪呢,我们取消掉变量传播优化再看看:0x14004dca7这一句,idapython/deTvm.py . tvmToAsmAll.outerror()),idapython/deTvm.py . tvmToAsmAll.findPushAndPop()关于 jcc
JO jmp if OF = 1
JNO jmp if OF = 0
JB JC JNAE jmp if CF = 1
JNB JNC JAE jmp if CF = 0
JZ JE jmp if ZF = 1
JNZ JNZ jmp if ZF = 0
JBE JNA jmp if CF = 1 or ZF = 1
JNBE JA jmp if CF = 0 and ZF = 0
JS jmp if SF = 1
JNS jmp if SF = 0
JP JPE jmp if PF = 1
JNP JPO jmp if PF = 0
JL JNGE jmp if SF != OF
JNL JGE jmp if SF = OF
JLE JNG jmp if ZF = 1 or SF != OF
JNLE JG jmp if ZF = 0 and SF = OF
JE:
0x14003c274否则 V_RIP变为0x14003c1fe。je xxx(V_RIP = 0x14003c274)
jmp xxx(V_RIP = 0x14003c1fe)
JG
0x1400369ec,否则 V_RIP =0x140036ac6(其实就是下面那一段,因为优化了所以地址对不上)。0x1400369ec,否则 VRIP =0x1400368ef。jg xxx(V_RIP = 0x1400369ec)
jmp xxx(V_RIP = 0x1400368ef)
提取特征
idapython/deTvm.py . tvmToAsm.vjcc_handle())JBE JNA
0x41 0x1 0x41 0x40 (这其实是错误的,tvm的bug?)JGE JNL
0x880 0x0 0x880 0x880JL JNGE
0x880 0x800 0x880 0x80JG JNLE
0x8C0 0x0 0x8C0 0x880JZ JE
0x40 0x40JNZ JNE
0x40 0x0JS
0x80 0x80JNS
0x80 0x0JC JB JNAE
0x1 0x1JNC JNB JAE
0x1 0x0JA JNBE
0x41 0x0JP JPE
0x4 0x4 0x0 0x0JNP JPO
0x4 0x0JO
0x800 0x800JNO
0x800 0x0JLE JNG
0x8C0 0x40 zf
0x8C0 0x800 of
0x8C0 0x80 sf
0x8C0 0xC0 zf+sf
0x8C0 0x840 zf+of
0x8C0 0x8C0 zf+of+sf
JBE JNA的特征是0x41 0x1 0x41 0x40这其实是错误的:jmp if ZF != CF,真正的JBE JNA是jmp if CF = 1 or ZF = 1,0x41 0x1 0x41 0x40 0x41 0x41,在这个版本的 tvm 中 ,它将JBE JNA错误处理成了jmp if ZF != CFJBE JNA这里的bug就被修复了,就是0x41 0x1 0x41 0x40 0x41 0x41。脚本还原ASM
idapython/deTvm.py . tvmToAsmAll.AllTvmAsmToAsm()第一步,先识别所有的AsmOpcode:
asmOpcode = [
"sar","or","ror","xor","shr","shl","movsxd",
"movsx","movzx","dec","inc","test",
"cmp","rep stosb","sbb","int3"
]
xor edx,edx。如果tvmToAsm只出现了 and,没有出现 not add 那么可以识别成 and
如果tvmToAsm只出现了 not,没有出现 and add 那么可以识别成 not
idapython/deTvm.py . tvmToAsm.setASMOpcode_1()sub:
14004a4c3 : 将 [r10 + 0xb0] 标记为 [not,PO_rsp,False]
14004a4c8 : 将 [r10 + 0xb8] 标记为 [not,PO_rsp,False],[add,0x80,True] //会拷贝前一个的标记
14004a4e4 : 将 [r10 + 0xb8] 标记为 [not,PO_rsp,False],[add,0x80,True],[not,None,False]
-优化-> [None,PO_rsp,False],[sub,0x80,True] //会拷贝前一个的标记
14004a4e9 : 将 [r10 + 0x98] 标记为 [None,PO_rsp,False],[sub,0x80,True] //会拷贝前一个的标记
14004a507这一句指令,我们就可以识别这个tvmToAsm的AsmOpcode了:出现 sub ,且影响标志位,所以为 sub
add:
1400627da : [r10 + 0xa8] 标记 [None,PO_r9,False],[add,0x9,False]
1400627e1 : 同上
1400627e6 : [r10 + 0x91] 标记 [None,PO_r9,False],[add,0x9,False],[mem,None,False]
1400627eb : [r10 + 0x90] 标记 [None,PO_r9,False],[add,0x9,False],[mem,None,False],[add,PO_rax,True]
1400627ff : [r10 + 0xa8] 标记 [None,PO_r9,False],[add,0x9,False]
140062806 : 同上
14006280b这一句指令,我们就可以识别这个tvmToAsm的AsmOpcode了:出现了 add 标记,并且影响标志位,只能是 add
lea:
14004a825 : [r10 + 0xa0] 标记 [None,PO_rsp,False],[add,0x50,False]
14004a82c这一句指令,我们就可以识别这个tvmToAsm的AsmOpcode了:标记中出现了add,且不影响标志位,就只能是 lea
mov:
140062826 : [r10 + 0x98] 标记 [None,PO_r9,False],[add,0x9,False]
14006282d : 同上
140062832 : [r10 + 0x90] 标记 [None,PO_r9,False],[add,0x9,False],[mem,None,False]
140062837这一句指令,我们就可以识别这个tvmToAsm的AsmOpcode了:标记中出现了 add,但不影响标志位,并且出现了 mem ,那么只能是 mov
sub add lea mov分类,参考代码:idapython/deTvm.py . tvmToAsm.record_tage()负责跟踪标记idapython/deTvm.py . tvmToAsm.setASMOpcode_2()负责分类sub add lea mov第二步,操作数识别:
GetAsmPara可以将标记转换成Asm操作数的格式。mov:
140062826 : [r10 + 0x98] 标记 [None,PO_r9,False],[add,0x9,False]
14006282d : 同上
140062832 : [r10 + 0x90] 标记 [None,PO_r9,False],[add,0x9,False],[mem,None,False]
140062837这一条workingTraceCode:v_mov_iregb_iregb ( iregb :PO_rax ,iregb :[ r10 + 0x90 ] );看到第二个参数的类型为 iregb,是8bit宽的操作数。
GetAsmPara( PO_rax ) 返回 "al"GetAsmPara( [r10 + 0x90]) :
通过标记[None,PO_r9,False],[add,0x9,False],[mem,None,False],
返回 "[r9 + 0x9]"我们知道这个tvmToAsm的AsmOpcode为mov,且workingTraceCode的 第二个参数类型为 iregb,
那么我们就可以知道:第一个操作数为 al ,第二个操作数为 byte ptr[r9 + 0x9]于是这个tvmToAsm就可以翻译为:
mov al,byte ptr[r9 + 0x9]
idapython/deTvm.py . tvmToAsm.mov_handle()lea:
14004a825 : [r10 + 0xa0] 标记 [None,PO_rsp,False],[add,0x50,False]
14004a82c这一条workingTraceCode:v_mov_iregll_iregll ( iregll :PO_r8 ,iregll :[ r10 + 0xa0 ] );GetAsmPara( PO_r8 ) 返回 "r8" GetAsmPara( [r10 + 0xa0 ]) :
通过标记[None,PO_rsp,False],[add,0x50,False]
返回 "rsp + 0x50" //没有中括号,标记中出现mem才会有中括号,lea要后面自己加中括号我们知道这个tvmToAsm的AsmOpcode为lea,且workingTraceCode的 第二个参数类型为 iregll,
那么我们就可以知道:第一个操作数为 r8 ,第二个操作数为 [rsp + 0x50]于是这个tvmToAsm就可以翻译为:
lea r8,[rsp + 0x50]
idapython/deTvm.py . tvmToAsm.lea_handle()add sub:
GetAsmPara的是红框框起来的这两个:(对于sub的处理是一样的)1400627ff : [r10 + 0xa8] 标记 [None,PO_r9,False],[add,0x9,False]
140062806 : 同上
GetAsmPara:看类型 iregb ,8bit宽度
GetAsmPara( PO_rax ) 返回 "al"GetAsmPara( [r10 + 0xa8] ):
标记为:[None,PO_r9,False],[add,0x9,False]
因为 [r10 + 0xa8]类型为 ipreg,且8bit宽度
所以返回 "byte ptr[r9 + 0x9]"于是这个tvmToAsm就可以翻译为:
add byte ptr[r9 + 0x9],al
idapython/deTvm.py . tvmToAsm.add_sub_handle()GetAsmParapush:
idapython/deTvm.py . tvmToAsm.push_handle()pop:
idapython/deTvm.py . tvmToAsm.pop_handle()cmp test:
idapython/deTvm.py . tvmToAsm.cmp_test_handle()movzx movsx movsxd
movzx:GetAsmPara。idapython/deTvm.py . tvmToAsm.movzx_movsx_movsxd_handle()not
GetAsmPara。idapython/deTvm.py . tvmToAsm.not_handle()xor sar shr shl sbb ror or and
GetAsmPara。GetAsmPara,以xor为例:idapython/deTvm.py . tvmToAsm.xxx_handle()jcc
workingTrace,它所在的tvmToAsm就是对应的跳转地址,......
je lable1
jmp label2
......
label2: ;(0x14003c0e6往下找第一个tvmToAsm)
mov rax,1 ;只是举个例子
......
label1: ;(0x14003c13b往下找第一个tvmToAsm)
mov rcx,2 ;只是举个例子
......
idapython/deTvm.py . tvmToAsm.jcc_handle()ASM 2 HEX
keystone库函数将Asm编译成十六进制机器码,然后再创建一个段,把内存写进去。详情参考:idapython/deTvm.py . tvmToAsmAll.WriteHex()和main0函数。keystone的一个bug,你们可以试一下:import keystone
ASM2HEX = keystone.Ks(keystone.KS_ARCH_X86, keystone.KS_MODE_64)
asm = """
mov rcx,qword ptr ds:[0x14000d250]
"""
byte,con = ASM2HEX.asm(asm,addr=0x1400ef00a)
for by in byte:
print("%02x"%by,end="")
48 8b 0d 50 d2 00 40
1400ef00a mov rcx, qword ptr [rip + 0x4000d250]
0x1400ef00a+0x7+0x4000d250 != 0x14000d250asm = """
mov qword ptr ds:[0x14000d250],rcx
"""
byte,con = ASM2HEX.asm(asm,addr=0x1400ef00a)
mov reg,qword ptr[xxx],mov reg,qword ptr[rip + yyy],详情参考代码:idapython/deTvm.py . Asm.AsmToHex()五
deTvm.py脚本玩法
main0是对全部ida识别的函数进行特征分析,如果符合tvm函数特征,就对它进行还原。0x140001250它是被vm的,那么你这么写,脚本就会自动特征识别V_RIP。testTrace = traceTask(0x140001250,tvm0base) #tvm0base是tvm0段的起始地址
testTrace.track(0) #开始跟踪 得到traceCode
testTrace.traceOut() #输出原始traceCode
#上一个例子的 函数 0x140001250 它的 V_RIP 就是 0x140059dc2
testTrace = traceTask(0,tvm0base)
testTrace.VStart = 0x140059dc2 #自己找这个vm函数的起始地址 例如V_RIP = 0x140059dc2
testTrace.track(0) #开始跟踪 得到traceCode
testTrace.traceOut() #输出原始traceCode
testTrace = traceTask(0x140001250,tvm0base) #tvm0base是tvm0段的起始地址
testTrace.track(0) #开始跟踪 得到traceCode
testTrace.VRegRecord(True) #如果是False就是不使用标记(上文说过)
testTrace.tvmToAsmAll.printAll() #输出
testTrace = traceTask(0x140001250,tvm0base) #tvm0base是tvm0段的起始地址
testTrace.track(0) #开始跟踪 得到traceCode
testTrace.VRegRecord(True) #如果是False就是不使用标记(上文说过)
testTrace.tvmToAsmAll.optimizeAll() #变量传播优化,push、pop优化
testTrace.tvmToAsmAll.printAll() #输出
testTrace = traceTask(0x140001250,tvm0base) #tvm0base是tvm0段的起始地址
testTrace.track(0) #开始跟踪 得到traceCode
testTrace.VRegRecord(True) #如果是False就是不使用标记(上文说过)
testTrace.tvmToAsmAll.optimizeAll() #变量传播优化,push、pop优化
testTrace.tvmToAsmAll.AllTvmAsmToAsm() #转换成ASM 注意,一定要VRegRecord + optimizeAll 后才可以调用
testTrace.tvmToAsmAll.printAsmAll() #输出ASM
testTrace = traceTask(0x140001250,tvm0base) #tvm0base是tvm0段的起始地址
testTrace.track(0) #开始跟踪 得到traceCode
testTrace.VRegRecord(True) #如果是False就是不使用标记(上文说过)
testTrace.tvmToAsmAll.optimizeAll() #变量传播优化,push、pop优化
testTrace.tvmToAsmAll.AllTvmAsmToAsm() #转换成ASMtvmToAsm_P = testTrace.tvmToAsmAll.tvmToAsmHead #结构为tvmToAsm
while (tvmToAsm_P != None):
tvmToAsm_P.printAsm() #输出Asm
tvmToAsm_P.print() #输出traceCodeAll
print("") #隔开
tvmToAsm_P = tvmToAsm_P.BLink #下一个
六
还原例子
icxxx的函数均为还原成功的函数。七
一些补充
一些闲话
JBE JNA的模拟是错的)。看雪ID:icey_
https://bbs.kanxue.com/user-home-914360.htm
# 往期推荐
球分享
球点赞
球在看
如有侵权请联系:admin#unsafe.sh