前言
HTTP 代理给页面注入 JS 是很常见的需求。由于上游服务器返回的页面可能是压缩状态的,因此需解压才能注入,同时为了节省流量,返回下游时还得再压缩。为了注入一小段代码,却将整个页面的流量解压再压缩,白白浪费大量性能。
是否有高效的解决方案?本文从注入位置、压缩格式、校验算法进行探讨。
注入位置
常见的注入方式,是对某个 HTML 标签进行替换,例如将 <head> 替换成 <head><script>...。
字符匹配的方式虽然简单,但并不严谨。假如页面中没有出现 <head>,那么就不会注入了。若要考虑大小写、标签存在属性的情况,还得使用正则匹配。更极端的情况,例如匹配点出现在注释、字符串中,并且只替换一次的话,那么注入的代码根本不会运行:
<!doctype html>
<html>
<!-- <head></head> -->
<head></head>
<body></body>
</html>
至于在网关上解析 HTML 这样的重量级操作,通常不会考虑。
现实中使用正则匹配足以支持大多数情况。不过正则匹配仍有一定的开销,是否有更轻量甚至零开销的注入方式?
其实可以有,直接将代码注入到页面最顶端!这种做法虽然不规范,但主流浏览器都支持。如果担心 doctype 失效,可以在注入的代码里补上:
<!doctype html><script src="inject.js"></script>
<!doctype html>
<html>
<head></head>
<body></body>
</html>
这样网关无需任何替换操作,只需转发时将注入的代码拼在第一个 chunk 之前即可。
不过这只是明文传输的情况。如果上游返回的是压缩流量,那么在其之前拼上「压缩后的注入代码」,是否仍有效?
我们以 gzip 为例接着探讨。
文件格式
gzip 使用 DEFLATE 算法压缩数据(下图 body 部分),并在前面加上 10 字节的文件头、不定长的可选头(记录文件名等),末尾加上 8 字节的文件尾:
| struct | field | length |
|---|---|---|
| header | magic number (1f 8b) | 2 |
| compression method (08) | 1 | |
| flags | 1 | |
| timestamp | 4 | |
| compression flags | 1 | |
| operating system ID | 1 | |
| extra headers (optional) | ... | ... |
| ... | ... | |
| body | block1 | ... |
| block2 | ... | |
| ... | ... | |
| trailer | CRC32 | 4 |
| uncompressed data length | 4 |
由于我们的数据在最前面,因此需提供文件头,并删除上游返回的文件头。
此外,还需要确定如下问题:
-
文件尾的 CRC32 校验是否需要更新
-
压缩数据中每个 block 块是否独立
第一个问题即使不调研,大概也能猜到,在浏览器端肯定是不需要的。因为网页是流模式的,收到一些渲染一些。等渲染完成后才说数据有问题,那网页是留着还是不让显示?至少到目前还没见过网页提示 gzip 校验失败的错误。
第二个问题,在 RFC1951 中有讲解:
Each block is compressed using a combination of the LZ77 algorithm
and Huffman coding. The Huffman trees for each block are independent
of those for previous or subsequent blocks; the LZ77 algorithm may
use a reference to a duplicated string occurring in a previous block,
up to 32K input bytes before.
Each block consists of two parts: a pair of Huffman code trees that
describe the representation of the compressed data part, and a
compressed data part. (The Huffman trees themselves are compressed
using Huffman encoding.) The compressed data consists of a series of
elements of two types: literal bytes (of strings that have not been
detected as duplicated within the previous 32K input bytes), and
pointers to duplicated strings, where a pointer is represented as a
pair<length, backward distance>. The representation used in the
"deflate" format limits distances to 32K bytes and lengths to 258
bytes, but does not limit the size of a block, except for
uncompressible blocks, which are limited as noted above.
每个块可能会引用之前块的数据,好在引用方式是从当前位置计算的(<长度, 反向距离>),因此是个相对值,不会因数据流开头插入我们的块而受到干扰。
此外还需注意的是,每个块的头部有个 BFINAL 字段标记当前是否为最后一块,因此我们的块中该字段不能被标记,否则后续块就不会解析了。
尝试
我们用 Node.js 实现一个初步演示:
import zlib from 'node:zlib'
import http from 'node:http'
// 上游返回的 gzip 数据(出于演示,未使用流模式)
const htmlGzipBuf = zlib.gzipSync('<h1>Hello World</h1>')
// 注入代码的 gzip 数据(部分压缩,防止被标记成最后一个 block)
let injectGzipBuf = Buffer.alloc(0)
const tmp = zlib.createGzip()
tmp.on('data', buf => {
injectGzipBuf = Buffer.concat([injectGzipBuf, buf])
})
tmp.write('<!doctype html><script>console.log("Hi Jack")</script>')
tmp.flush()
http.createServer((req, res) => {
res.setHeader('content-type', 'text/html')
res.setHeader('content-encoding', 'gzip')
// 输出压缩态的注入代码
res.write(injectGzipBuf)
// 跳过上游的 gzip 文件头(默认 10 字节)
res.end(htmlGzipBuf.subarray(10))
}).listen(8080)
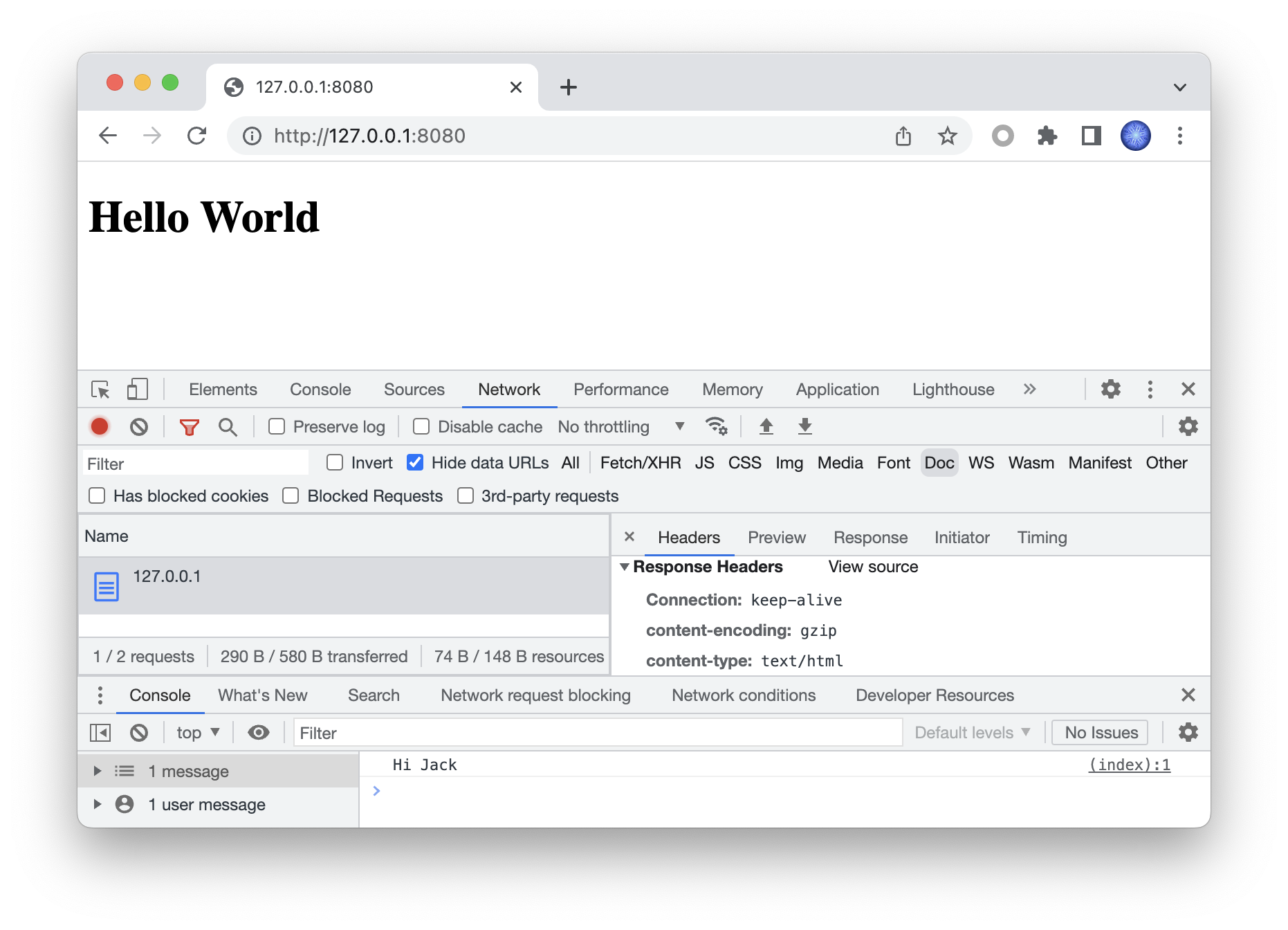
这个案例中,我们两次输出的都是压缩态数据,最终被浏览器成功解析。

经测试所有主流浏览器都没问题,curl 也没问题。但也有一些库会校验 CRC,例如 Node.js 的 fetch:
const res = await fetch('http://127.0.0.1:8080/')
const reader = res.body.getReader()
for (;;) {
const {done, value} = await reader.read()
if (done) {
break
}
console.log(value)
}
读取最后块时报错:
Uncaught TypeError: terminated
at Fetch.onAborted ...
[cause]: Error: incorrect data check
at Zlib.zlibOnError [as onerror] ...
code: 'Z_DATA_ERROR'
导致读取的数据比预期少。
校验算法
如何更新校验值?最笨的办法,就是把上游流量全都解开,重新计算一次 CRC。毕竟解压的开销比压缩小很多,还是可以接受的。
不过本文追求的是低开销甚至零开销,因此这个方案很不完美。记得曾经开发防火墙时,如果数据包只修改很小一部分,那么 checksum 是不用重新计算的,只需稍加修正即可。这个思路是否可用在 CRC 上?毕竟 CRC 又不是什么密码学 hash 算法,就几个简单的 xor 运算,大概是可以玩出一些花招的。
一查文档,发现不仅可以,甚至这个奇技淫巧还被 zlib 库收录了,提供了一个 crc32_combine 函数,用于合并两个 CRC32 值:
crc32_combine(crc1, crc2, len2)
Combine two CRC-32 check values into one. For two sequences of bytes,
seq1 and seq2 with lengths len1 and len2, CRC-32 check values were
calculated for each, crc1 and crc2. crc32_combine() returns the CRC-32
check value of seq1 and seq2 concatenated, requiring only crc1, crc2, and
len2.
至于原理细节,可参考:
https://stackoverflow.com/questions/23122312/crc-calculation-of-a-mostly-static-data-stream/23126768
https://github.com/stbrumme/crc32/blob/master/Crc32.cpp#L560
我们预先计算出注入 JS 的 CRC 作为 crc1,而上游返回的 gzip 文件尾正好携带了 crc2 和 len2,因此可直接算出新的 CRC。
使用这个方案,即可兼容所有 HTTP 客户端。
完整演示
前面的演示出于简单,未考虑 gzip 扩展文件头,并且直接使用 Buffer 代替数据流。下面分享一个更完整的演示:
https://github.com/EtherDream/gzip-js-injector

后记
几年前研究流量劫持时写的文章,不过一直没发布,前段时间翻新了下并补了个 demo。由于那时还没 brotli 压缩,因此也没调研。之后有时间再补充。
如有侵权请联系:admin#unsafe.sh