每周文章分享2023.06.19-2023.06.25标题: Game of Drones: Multi-UAV Pursuit-Evasion Game With Online Motion Pla 2023-6-24 07:11:49 Author: 网络与安全实验室(查看原文) 阅读量:33 收藏
每周文章分享
2023.06.19-2023.06.25
标题: Game of Drones: Multi-UAV Pursuit-Evasion Game With Online Motion Planning by Deep Reinforcement Learning
期刊: IEEE Transactions on Neural Networks and Learning Systems, 2022.
作者: Ruilong Zhang, Qun Zong, Xiuyun Zhang, Liqian Dou, and Bailing Tian.
分享人: 河海大学——冯子骁
研究背景
竞争和合作是自然界中许多复杂生态系统的两个基本要素,就像一群狼在大草原上猎羊一样。它们被认为是生物和社会进化的驱动力。由于其重量轻、机动性高、成本低的特点,单架四轴飞行器很难单独完成复杂的任务。因此,四轴飞行器衍生出了“无人群系统”的应用模式,其中包括合作伙伴之间的合作和与敌人的竞争。四轴飞行器的一个典型应用是在障碍物环境下的目标追踪。传统方法的主要思想是不断减少逃逸者在被追踪者捕获之前可以安全到达的点集,并采用粒子群优化(PSO)、人工势场和其他优化方法来解决碰撞和避障问题. 然而,现有的大多数传统方法在解决避障问题时忽略了追踪器的物理尺寸,仿真环境不能反应真实的情景,并假设追踪器的速度比目标的速度快。在这篇文章中,研究了障碍环境下的多四轴飞行器和目标追踪规避博弈。
关键技术
文章中为了高质量地模拟城市环境,提出了一种追踪规避场景(PES)框架,通过物理引擎创建环境,使四轴飞行器代理能够采取行动并与环境交互。在此基础上,通过对多智能体深度确定性策略梯度(MADDPG)公式的矢量化扩展,构造了多智能体冠状双向协同目标预测网络(CBC-TP-Net),以确保受损“集群”系统在追击-躲避任务中的有效性。与传统的强化学习不同,本文还在通用框架下创新性地设计了一个目标预测网络(TP-Net),以模仿人类的思维方式:情境预测总是先于决策。
该方法的创新和贡献如下:
1)创建了一个具有高质量渲染的仿真框架PES,该框架使四架直升机代理能够与多障碍环境进行实时交互,从而更真实地模拟四架直升机在城市环境中执行任务的过程。
2)在传统的DRL框架内扩展了预测网络,通过预测目标的未来轨迹来提高四直升机代理的决策能力。
3)在MADDPG的集中训练和分散执行机制的基础上,提出了一种改进的DRL框架CBC-TP网络,为未受损和受损的“集群”系统生成合作行动策略。
算法介绍
(1)PES仿真环境
图1 PES仿真环境
图1是文章提出的PES仿真环境,它的设计方法是将物理引擎(Unity 3-D)与基于Pytorch的DRL框架集成,并通过Unity ML Agents Toolkit进行通信。图1(a)表示环境的初始化过程,多个四轴飞行器(蓝色)随机初始化在城市环境的角落,被追踪者(红色)处于环境中央位置。图1(b)表示追踪的过程。图1(c)则表示捕获成功,逃逸者没有了可以躲避的空间。图1(d)表示的则是在仿真过程中,四轴飞行器可能出现的驶入大楼,发生损坏的情况。
PES的主要优点如下:
1)DRL框架直接与物理引擎通信,物理引擎可以实时显示代理的全局状态。
2)真实环境的场景可以被尽可能地模仿。例如,四架直升机如果撞上障碍物就会受损。
3)可以通过替换物理引擎中的一些参数来改变街区布局,这可以方便地生成一个新的城市环境。
(2) 目标预测网络
图2 目标预测网络(TP-Net)框架
预测目标的未来位置可以帮助智能体更有效地做出决策。RNN有一个或多个带反馈回路的神经网络,可以有效解决时间序列信号中的记忆问题。因此,文章提出了一种基于深度LSTM的TP网络来预测目标未来k时间步的轨迹,如图2所示。
考虑到接下来的k个时间段(t)∼(t+k)目标的位置需要通过使用n个时
间段的历史目标状态数据进行预测。对于TP网络训练,在DRL的动作探索过程中,我们将(n+k)时间步目标状态数据存储到一个单独的目标轨迹回放缓冲区中,包括n个时间步训练数据p_x(目标位置、四旋翼机代理位置和速度)和k个时间步标签数据p_y(目标位置)。我们用监督学习训练TP网络。TP的Pς可以通过最小化以下损失来更新:
(3) CBC-TP网络
由于全连接的网络结构的限制,导致网络的输入不可变,但四轴飞行器代理可能因故障而受损,所以MADDPG 不适用于可变数量的代理的协作。在本文,提出了一个新的 CBC-TP 网络,它可以允许通信之间的可变数量的代理。总的来说,CBC-TP 网络由一个多代理策略网络和一个针对每个代理的多代理评论网络组成,如图3所示。
图3 CBC-TP 网络的策略和评价网络结构
图3中,四轴飞行器智能体对应于最初和最终的双向 LSTM 单元,辅助智能体信息对应于其他双向 LSTM 单元。图3(a)是 CBC-TP 网络策略网络。图3(b)是 CBC-TP Net 的Q网络。对于智能体i,其对应的CBC-TP网络的最终输入如图4所示:
图4 CBC-TP 策略网络中智能体i的输入细节
(4) 奖励函数设置
PES 的目标是控制四轴飞行器在避开障碍物的同时追踪目标。仅使用全局奖励或个人奖励的一个潜在缺点是它忽略了一个事实,即团队协作通常由个人协作组成。因此,奖励函数应包括团队合作奖励和个人奖励。此外,在实践中,每个主体往往有一个共同的目标和自己的目标(符合共同的目标) ,这推动了协作。为了对此建模,文章提出了一个全局个体报酬函数:
其中 r_co,i 和 r_self,i分别表示全局和个体奖励,它们被定义为:
其中,dis (j,tar)是四轴飞行器 j 到目标的距离,dis (j,obs)表示四轴飞行器 j 到最近障碍物的距离。dis_safe定义了四轴飞行器与最近障碍物之间的不安全缓冲距离,ρ 是将奖励平衡为(0,1)的归一化因子,k 是常数参数,在实验中设置为10^-3。
实验结果分析
1. 实验设置:
图5为CBC-TP网络的网络参数设置:
图5 CBC-TP网络参数设置
2. 与其他强化学习算法的比较
为了评估在竞争环境中学到的策略的性能,我们将 CBC-TP 四轴飞行器代理与 DDPG 代理进行对比。文章用4000集和超过100万个步骤来训练模型,然后通过平均1000次进一步迭代的各种指标来评估它们。同时,也将使用 PPO,DDPG,MADDPG,Bi-CNet 和 MAAC ,这是在相同的环境中培训,作为参考。
文章为了衡量DRL模型性能提出了三种性能指标:
1. 任务成功率:
图6 PES 中 CBC-TP 网络和其他算法在每100集训练中的任务成功率
图6中,我们可以看到,随着训练的进行,四轴飞行器智能体开始成功地追逐目标,并且在800集之后获胜率曲线有了令人印象深刻的增长。经过2000集的训练,我们的四轴飞行器几乎可以完成100% 的追踪任务。与MADDPG的曲线相比,CBC-TP 网络架构在PES方面表现出色及稳定。
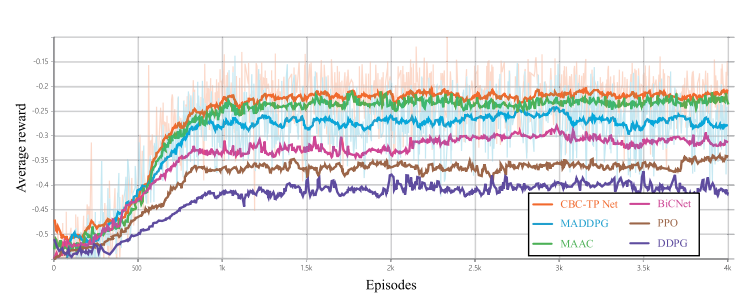
2. 平均奖励:
图7 PES系统中 CBC-TP 网络和其他算法的平均奖励
CBC-TP Net 和 MADDPG 四轴飞行器平均奖励曲线如图7所示。两种 DRL 方法的平均回报在开始时都有明显的增加,在训练期间稳步增长,并在大约1000集后保持平稳。然而,CBC-TP 网络四轴飞行器代理人的平均奖励曲线在大约500集后比 MADDPG 有更快的上升趋势。
3. 每集完成所需步数:
图8 PES 训练中 CBC-TP Net 等算法四轴飞行器代理的发射步骤。
如图8所示,在这个阶段,CBC-TP 网络的四轴飞行器可以用较少的步骤追踪目标,因为其可以预测目标的轨迹。最后,四轴飞行器已经学会了一种适当的行动策略,以追求目标而不发生碰撞,他们能够在几乎100至150个步骤的合作捕获目标。
3. TP-Net的作用
图9 PES 每100集训练中 CBC-TP Net和 CBC Net的任务成功率
图10 PES 训练中 CBC-TP Net和 CBC Net的总步骤
在图9中,没有目标轨迹预测,任务成功率在开始500-1000集时低于40% 。在曲线的后半部分,CBC-TP Net 四轴飞行器代理能够保持较高的成功率,但 CBC Net 代理的成功率曲线在0.9 ~ 1之间波动。我们可以直观地看到,与图10中的 CBC-TP 网络相比,CBC-TP 网络四轴飞行器代理在3000集后每集需要的步骤少于80步。
在这里,文章设计了一个对比实验,设置两个初始条件和目标规避策略相同的PES,如图11所示。
图11 CBC-TP Net四轴飞行器代理轨迹与 CBC Net四轴飞行器代理轨迹的比较。
CBC-TP Net(b)CBC Net
从图11中可以看到,如果没有 TP Net,CBC Net四轴飞行器代理只根据目标的当前状态生成操作策略。这种行动策略导致四轴飞行器代理人一直在追逐目标,但不能完成任务。然而,CBC-TP Net 四轴飞行器代理可以根据目标的当前和未来状态生成当前操作策略。因此,CBC-TP Net直升机代理可以学习如何围困目标,快速完成 PES 任务。
总结
本文主要研究障碍物环境下四轴飞行器的追逃博弈。在这篇文章中,贡献如下,包括:1)提出了一个基于Unity 3-D和python的PES DRL交互环境;2) 引入了一个向量化的AC框架CBC-TP Net,其中每个维度对应于已有的四轴飞行器代理,并在传统的强化学习框架中扩展了一个TP Net用于目标轨迹预测;3)设计了用于CBC-TP Net更新的分层多智能体DRL算法和用于训练的有效全局个体奖励函数。
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh