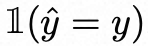
2023-7-24 16:44:0 Author: www.cnblogs.com(查看原文) 阅读量:20 收藏
受到人类做决策的思维过程的启发,即通过将一个问题逐个分解为多个子问题,并按照链式的方式串行思考,最终得到思考结果,这个过程被成为”思维链(chain-of-thoughts)“。
研究表明,中间推理过程(intermediate reasoning (“rationales”))可以显著提高语言模型在数学或常识回答等复杂推理任务中的表现。
在中间推理过程中,经过良好预训练的LLM可以使用中间步骤的“暂存器(scratchpads)”可以在算术问题上获得完美的分布性能,以及强大的训练任务数据分布外泛化能力。
而相比之下,专门训练用来直接回答答案的one-shot model则无法很好地应对训练任务数据分布外泛化能力。
这些研究工作表明,在给出最终答案之前先给出明确的推理理由(rationale generation),对LLM在各种任务中都很有帮助,包括数学推理、常识推理、代码评估、社会偏见推理和自然语言推理等任务。
目前进行rationale generation有两种主要方法:
- fine-tune based on rationale dataset:一种方法是构建rationale generation的的微调数据集,微调训练出一个具备rationale generation能力的fine-tune model。
- few-shot examples promot method:一种方法是通过手写或者自动模板生成技术,生成出一套rationale generation examples prompt template,引导LLM遵循examples的实例,进行内部rationale generation推理,得到最终答案。如下图所示,

然而,目前进行rationale generation的两种主要方法都有严重的缺点。
- 人工构造微调数据的方法很昂贵,并且也很难为每个问题任务域都构建一个微调数据集,从时间和效率上是几乎是不可行的。
- 基于prompt模板的方法(人工 or 自动生成)只能解决已知的问题任务域,对于未知任务的泛化能力无法保证效果。
在本文中,我们采用了不同的方法:即利用LLM自身包含的推理能力,通过迭代,引导LLM产生高质量的rationales的。
具体的流程大致如下:
- 准备一个pre-train LLM,该基模型在整个迭代算法中保持不变,以及一个包含初始few-shot prompts的数据集。
- 拷贝一份pre-train LLM作为当前最新sft-model容器,该容器在后续的迭代轮次中不断更新为最新的sft-model,用于生成中间推理过程。
- 通过few-shot技术,引导当前最新sft-model容器自我生成rationales推理过程,得到一个rationales dataset。
- 专家介入进行数据蒸馏,从本轮rationales dataset中筛选出能够得到正确结果的rationales dataset,得到一个ground truth rationales dataset。注意!LLM自我生成的rationales可能会出错导致无法得到最终答案,或者是遇到泛化外的新领域问题LLM会出现幻觉等问题,这个时候需要人工介入进行修正(Rationalize),将修正后的rationales融合入后续的rationales dataset中,可以显著提升精度度和泛化效果。
- 基于ground truth rationales dataset,对pre-train LLM进行微调,并将微调训练得到的模型更新到当前最新sft-model容器中。注意!每次得到一份新的ground truth rationales dataset后,不能直接基于上一轮的sft-model进行微调训练,那样容易导致过拟合,正确地做法是使用新的ground truth rationales dataset对pre-train LLM重新进行微调训练。
- ....
- 不断重复【3-5】步骤,直到当前最新sft-model的性能得到收敛。

以上迭代过程是一个协同进化过程,rationale generation提升了微调数据集的质量,而微调数据集通过增强sft-model的能力,进一步也提升了rationale generation的效果。
综合以上过程,我们开发了自学推理器(Self-Taught Reasoner,STaR,下图 1)方法,

Figure 1: An overview of STaR and a STaR-generated rationale on CommonsenseQA. We indicate the fine-tuning outer loop with a dashed line. The questions and ground truth answers are expected to be present in the dataset, while the rationales are generated using STaR.
这是一种可扩展的引导方法,允许模型学习产生自己的推理过程,同时也能够解决不断出现的新领域问题。
参考链接:
https://www.promptingguide.ai/techniques/cot https://learnprompting.org/docs/intermediate/chain_of_thought
0x1:Rationale Generation Bootstrapping(STaR Without Rationalization)
首先,我们有一个预训练 LLM,M。以及一个关于问题 x 的初始数据集D,并包含正确的最终答案 y:
![]() 迭代优化从一个小prompt数据集(包含中间推理过程r)P开始:
迭代优化从一个小prompt数据集(包含中间推理过程r)P开始:
![]()
其中 P ≪ D(例如P = 10),这里表示prompt示例集远小于初始数据集数量,完整的Rationale需要在后续的迭代中逐步补全。
接下来,与标准的few-shot prompting一样,我们将prompt示例集连接到 D 中的每个示例,即:
![]()
将拼接后的数据集 xi 输入LLM,基于概率预测原理,LLM生成对应的![]() 以及与之对应的
以及与之对应的![]()
接下来是专家修正过程(Rationalize),我们假设产生正确答案的Rationale,相比产生那些产生错误答案的Rationale,质量更高。因此,我们过滤出能够产生正确答案的Rationale。
接下来,我们基于过滤后的数据集(xi,yi,ri),微调LLM,得到一个新的sft-model。
最后,我们基于新微调的sft-model,继续从prompt开始重复整个流程。
我们不断上述重复这个过程,直到性能达到稳定水平。
从强化学习的角度看,STaR 可以看作是 RL 风格的策略梯度目标(RL-style policy gradient objective)算法的近似。
M 可以被视为离散潜变量模型(discrete latent variable model):
![]()
换句话说,M 在预测 y 之前首先对潜在推理原因 r 进行采样。
奖励函数函数来自专家的ground truth反馈![]() ,整个数据集的总奖励期望为:
,整个数据集的总奖励期望为:

其中梯度是通过策略梯度的标准对数导数技巧获得的。
注意,指标函数会丢弃所有无法得出正确结果的rationales采样的梯度的答案yi。因此, STaR 会采用贪婪模式,通过对![]() 采样进行解码,不断缩小当前值和估计值之间的损失,以此完成 J 的近似优化。
采样进行解码,不断缩小当前值和估计值之间的损失,以此完成 J 的近似优化。
这种近似优化方法,使得 STAR 成为一个简单且广泛的通用LLM训练方法。
0x2:Rationalization
对于导致失败的rationales,算法无法获得任何训练信号。
为了解决这个问题,我们提出了“合理化(rationalizationb)”的技术。 具体来说,我们通过输入一个hint(合理推理提示词),引导LLM生成显而易见地推理过程以及正确答案。但是,当向我们的数据集添加合理化生成的rationales时,我们不会在其数据集中包含hint(合理推理提示词),就好像模型在没有提示的情况下就得出了基本原理。
过滤后,我们将先前生成的数据集与合理化生成的数据集进行整合,并进行微调训练。

Figure 2: A few-shot prompt hint we use for rationalization (and not for rationale generation), using the rationale from [6], with its hint included in green, followed by the rationale and the answer generated by the model.
参考链接:
https://github.com/ezelikman/STaR
如有侵权请联系:admin#unsafe.sh