在 3 月份 OPENAI 发布 GPT-4 的时候,在其博客中就提到了 Visual Inputs 视觉输入功能,GPT-4 模型不仅支持文本内容,实际上也是支持图像识别的,只不过到现在该功能都没有公开发布。
目前已经有部分用户收到 OPENAI 发送的邀请,可以在 ChatGPT 中测试 GPT-4 with Vision (Alpha),这个功能能实现的场景其实很多,识别图像中的物体只是最基础的应用。
在 OPENAI 自己提供的示例中,是将 Sketch 转换为代码,也就是给定一个设计文件,GPT-4 识别设计文件并帮你编写代码,这对前端工作者来说或许有不小的帮助。
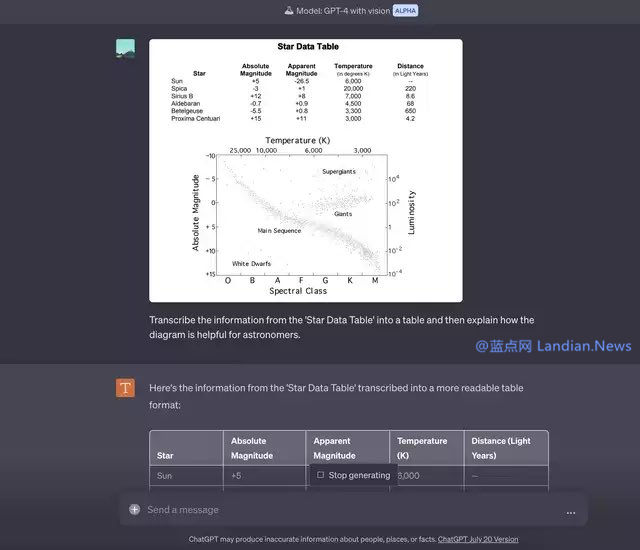
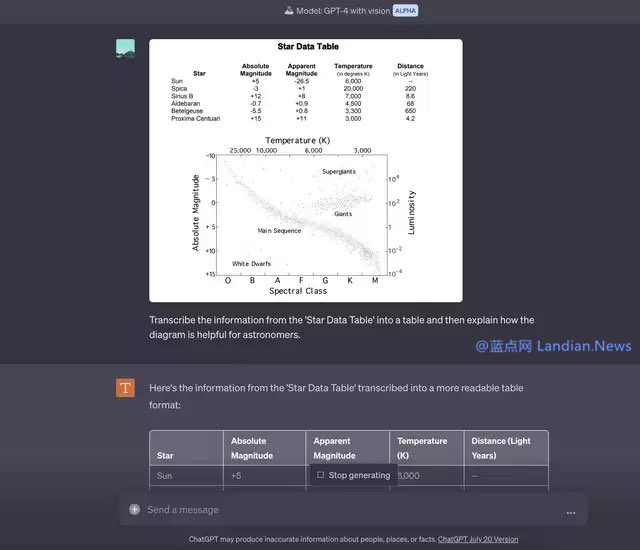
还有使用场景就是类似于 OCR 识别了,例如对打印的 Excel 表格进行拍照,然后将其转换为电子簿,这类功能在很多应用里已经支持,现在 GPT-4 也支持类似功能了,不过不知道 GPT-4 是不是也用的 OCR 类技术。
在实际使用方面,用户可以批量输入内容,而不是单次输入一张图片去识别,例如可以将文本和图片穿插发送给 GPT-4,这样也可以识别并且可能还会有助于用户理解。
例如在很多论文中就有大量配图,GPT-4 (暂时不考虑输入上限问题) 可以识别论文内容搭配图片进行理解,可以增强思维链,帮助 GPT-4 给出更好的回答。
由此还能衍生出一个使用场景,那就是可以利用此功能来帮助视力障碍用户,可惜 GPT-4 的联网模式没了,不然视力障碍用户可以直接把链接发给 GPT-4,让 GPT-4 识别链接内容的同时,也可以解释网页里的配图。
OPENAI 称图像输入功能目前属于研究测试阶段,不公开提供,所以除非用户收到邀请,否则暂时无法使用此功能。
版权声明:感谢您的阅读,除非文中已注明来源网站名称或链接,否则均为蓝点网原创内容。转载时请务必注明:来源于蓝点网、标注作者及本文完整链接,谢谢理解。