1 问题背景
街景数据通过不同设备进行采集获取,以各种摄像头采集的视频图像及各种雷达采集的点云为主要载体。其中,摄像头采集的视频图像具有低成本、易获取的特点,是最为常见的街景数据类型,而本文处理的街景数据主要为视频图像数据。街景视频图像数据作为室内外场景的重要信息载体,是计算机视觉众多任务的关键研究对象。
为了从视频图像数据中解析有效的街景信息,计算机视觉各项技术融汇互补,实现对交通道路、室内外空间等街景进行深度全面的理解,这个过程通常被称为街景理解。街景理解相关技术的发展在计算机视觉技术演进中扮演着非常重要的角色,同时也对众多下游任务(例如场景重建、自动驾驶、机器人导航等)发挥着重要的作用。
总的来说,街景理解技术融汇了众多计算机视觉技术,从不同技术的识别结果的表示形式上,可以划分为四个层级:点级、线级、面级、体级,以及每个层级内、不同层级间要素的逻辑关系。其中:
- 点级提取技术用于解析各种与“点”相关的信息,以提取坐标及特征描述子为主,包括通用特征点、语义关键点等各种点级信息的提取技术,处理对象包括各种要素,用于表征要素的位置、特征等信息。
- 线级提取技术用于解析各种与“线”相关的信息,以提取线条为主,包括车道线、地平线、各类曲线/直线等各种线级信息的提取技术,处理对象包括各种线条,用于表征要素的位置、矢量、拓扑等信息。
- 面级提取技术用于解析各种与“面”相关的信息,以提取区域为主。街景视频图像数据由于透视投影的成像方式,所有信息均展示在二维平面上,该平面根据不同语义、不同实例被划分为不同区域,这些区域表征了要素的二维位置、轮廓、语义等信息。本层次能力包括语义分割、实例分割等提取技术。
- 体级技术用于解析各种与“体”相关的信息,以提取三维结构为主,包括深度估计、视觉显式/隐式三维重建等提取技术,用于表征场景及要素的三维结构信息。
- 逻辑关系提取技术基于以上技术的提取的要素及场景信息,通过时序信息融合及逻辑推理,提取不同层级或同一层级要素间的逻辑关系,包括点的匹配关系、线的拓扑关系、要素的多帧跟踪及位置关系等。
具体到现实场景,点级、线级、面级提取技术的的识别结果,如下图1所示:

在街景理解中,各类视频图像分割技术是“面级”提取和“逻辑关系”提取中的关键技术,实现对街景二维信息的像素级表征。在街景分割中,由于实际场景的复杂性,面临众多难题。
首先,街景分割的突出难点是要素的形状、尺寸差异大,如图2第一列所示(图像示例来自于数据集[1])。由于现实场景中各种目标的多样性以及视频图像成像的局限性,采集数据中目标存在各种异型或不完整问题。此外,由于透视成像的问题,远处与近处的相同目标在图像中大小差异极大。这两个问题要求街景分割算法具备鲁棒的复杂目标精准分割能力。
其次,街景分割的另一难点是恶劣自然条件带来的干扰,如图2第二、三列所示(示例来自于数据集[2])。由于实际场景中恶劣天气或极端光照条件是经常出现的,采集数据中目标往往受到自然条件的影响,存在可见度低、遮挡或模糊等问题。这要求街景分割算法具备困难目标的发现与识别能力。
此外,由于街景理解中需要利用视频/图像等不同数据形式不同结果表征的分割技术,如何构建高效率迭代的分割技术?如何保证不同分割算法间相互配合、性能互补,同时保证多种算法在有限的计算资源与维护成本下共存?如何将分割任务与其他任务结合,变得更加统一开放?也是街景分割亟需解决的难题。

为了解决以上难题,美团街景理解团队在分割技术上做了大量探索,构建了一系列真实复杂场景下的高精度分割算法,实现了复杂目标精准分割及困难目标的发现识别。同时,也对高效率分割技术进行了实践,实现了分割模型的高效迭代与应用,并探索了统一开放的的街景视觉分割技术。最终,提出的相关技术在街景理解中取得了明显的效果,相关算法被CVPR 2023接收为Workshop论文,并且在国际竞赛中取得了2项冠军1项季军的成绩。
2 研究现状
2.1 分割技术体系
分割作为计算机视觉三大基础任务(分类、检测、分割)之一,对目标进行像素粒度的位置和轮廓信息表示。计算机视觉进入深度学习时代之后,分割任务根据不同的应用场景进一步细分发展出各种子任务,按照数据形式的不同分为两大类:图像分割和视频分割,如下图3所示(图片来自[3][15]等文献):

图像分割任务的处理对象是单张图像,根据输出结果表示形式的不同,逐渐发展出语义分割、实例分割、全景分割等。其中,语义分割将图像中每个像素分配到对应的语义类别,代表工作有FCN[4]、U-Net[4]、DeepLab[6]、OCRNet[7]、SegFormer[8]等。实例分割的目标是将图像中每个实例进行分割,并识别出每个实例的语义类别,代表工作有Mask-RCNN[9]、YOLACT[10]、SOLO[11]等。全景分割的目标是将图像中所有像素分配到对应的语义类别中,并区分不同实例,代表工作有EfficientPS[12]、Panoptic-DeepLab[13]、UPSNet[14]等。除了以上分割任务以外,还有一些其他图像分割技术在许多场景有应用需求,如抠图、显著性目标分割等图像分割任务。
视频分割任务的处理对象具有时序关系的视频序列,其不仅关注单帧的空间维度信息,同时关注多帧间的时序维度信息。按照输入和输出结果的表示形式的不同,视频分割分为视频目标分割、视频语义分割、视频实例分割、视频全景分割等;视频目标分割根据输入形式的不同,进一步分为自动视频目标分割、半自动视频目标分割、交互式视频目标分割、语言引导的视频目标分割等子任务。自动视频目标分割仅利用视频帧作为输入,分割出视频序列目标所在区域,代表工作有OSVOS[16]、MATNet[17]等。半自动视频目标分割除了输入视频序列以外还输入指定所要分割的目标,代表工作有SiamMask[18]、STM[19]、AOT[20]等。交互式视频目标分割是指在用户的交互下,对视频前景目标进行分割,代表工作有MiVOS[21]等。语言引导的视频目标分割通过输入文本来指定所要分割的目标,代表工作有CMSANet[22]等。
除了按照以上方式对分割任务进行分类以外,也可以根据模型学习范式或者监督程度来进行分类,根据训练数据标注信息受限程度的不同,分为强监督分割、无监督分割、半监督分割、弱监督分割等。当分割模型实际运行时,许多应用场景下设备的计算资源往往是受限的,例如一些移动端设备提供的计算资源十分有限,然而实际需求又要求模型具备一定的实时性,这就要求分割模型在模型架构设计上具备高效性。一些工作聚焦于此进行研究,如BiSeNet[23]、STDCNet[24]等。此外,真实世界中的语义类别复杂多样,各个类别的数据分布也不均匀,因此也衍生出了开集分割、长尾分割等研究方向。
2.2 街景分割现状
针对街景分割中存在的问题,许多方法提出了相应解决方案。
为了解决复杂目标的精准分割问题,PSPNet[25]提出金字塔池化模型,利用不同尺度上下文信息实现不同尺度物体的分割。OCRNet[7]引入物体上下文特征表示模块用于上下文信息增强的特征,预测每个像素的语义类别。SegFormer[8]提出一种新的层次结构Transformer编码器输出多尺度特征,同时引入多层感知机解码器聚合来自不同层的信息,得到不同目标的分割结果。此外,也有一些基于视频的方法,例如TMANet[26]通过利用相邻帧的特征对当前帧进行增强,解决目标精准分割问题。目前已有的方法中,基于图像的方法主要从上下文特征增强的角度出发,但由于单帧单视角的信息对于场景的信息刻画不够完整,因此对于复杂目标的精准分割是困难的。同时,基于视频的方法主要利用周围帧的特征增强当前帧的特征,但由于多帧特征的对齐与融合存在困难,因此复杂目标的精准分割仍难以解决。
为了解决困难目标的发现与识别问题,难样本挖掘技术通用被用于增强特征的辨别能力。为了减少识别难样本的计算开销,已有的工作主要在两个方向进行了探索:每个batch内的精确搜索、整个数据集的近似搜索。例如,OHEM[27]基于损失函数的反馈在batch中自动选择困难样本,以使训练更有效和更高效,减少了繁重的启发式搜索做法和超参数。此外,UHEM[28]通过分析视频序列上经过训练的检测器的输出来自动获得大量困难的负样本。此外,SCHEM[29]使用类别签名在训练期间以较小的额外计算成本在线跟踪特征嵌入,通过使用该签名识别困难负样本。目前已有的方法中,通过优化训练策略的方式增强难样本的学习能力,从而实现困难目标的发现与识别,但由于这些方案都是通过约束模型训练从而间接达到目标发现的目的,因此并不能完全解决困难目标的发现与识别问题。
为了解决分割模型的高效率迭代问题,研究人员也做出了许多努力。为了提高分割任务的标注效率,ScribbleSup[30]、FocalClick[31]、MiVOS[21]等通过交互式分割的方式加快对图像或视频目标的像素级标注。此外,由于长尾分布的存在,CANet[32]、PADing[33]等通过少样本学习和零样本学习的方法减少对稀少类别数据样本的依赖,还有一些工作通过重采样、类别平衡损失函数等方法在训练过程中缓解长尾问题。另外,在模型结构的设计上需要注重效率,例如BiSeNet[23]、STDCNet[24]等模型通过多分支网络结构获取更好的实时性,ShuffleNet[34]、MobileNet[35]等通过特殊算子和模块减少模型的计算量和参数量。
随着分割技术的发展,衍生出了许多不同的分割子任务,如语义分割、实例分割、全景分割等,其在数据标注形式、输出表征方式、模型结构设计等方面都存在着一定的差异。在不同的分割算法间找到统一的解决方案,充分利用不同形式的分割标注数据等都是重要的研究问题。MaskFormer[36]、OneFormer[37]等方法提出了通用的分割模型结构,其将语义分割、实例分割、全景分割等任务统一起来,并且能较为容易地由图像分割推广到视频分割。近期提出的Segment Anything Model[38]则作为一个零样本基础分割模型,能够“分割一切”,基于SAM可以进一步开发出许多的分割下游应用,如语义分割、实例分割等、视频目标分割等。
3 核心技术
本部分针对街景理解分割任务存在的问题,从真实复杂场景下的高精度分割、分割模型的高效率迭代以及通向统一开放的街景分割等三个方面介绍相应的解决方案。
3.1 复杂场景下的高精度分割
3.1.1 基于时空对齐的复杂目标精准分割
复杂目标的精准分割问题,表现为复杂目标中经常存在部分区域的预测结果具有高不确定性,导致该区域难以精准分割甚至分割错误。通常,通过融合周围帧的预测信息,可以提高当前帧目标分割的确定性,从而提高该目标的分割精度。为解决复杂目标的精准分割问题,街景理解团队提出了一种基于时空对齐的复杂目标精准分割框架(Motion-State Alignment Framework,简称MSAF),如下图4所示:

MSAF重新思考了视频信号带来的信息增益:视频中包含的语义信息可分为动态语义和静态语义,动态语义存在于连续多帧的时序关系中,能够增益目标区域的位置信息和特征描述;静态语义存在于确定时刻的单帧图像中,能够有效恢复目标区域的细节信息。动静态语义能够为分割模型带来不同方面的确定性信息增益。
MSAF首先提取视频相邻多帧的特征,通过动态特征对齐机制及静态特征对齐机制,分别对当前帧的动静态语义特征进行增强,接着从动态语义特征中提取目标区域描述子、从静态语义中提取目标像素描述子,然后求解像素描述子与区域描述子的特征距离,为每个像素指定准确的区域类别,实现复杂目标的精准分割。
最终,与主流的图像、视频级分割方法相比,基于时空对齐的复杂目标精准分割方法在Cityscapes[1]、CamVid[39]等数据集上均达到领先的精度,并具有较快的推理速度。
3.1.2 基于样本自动挖掘的困难目标发现
为了解决困难目标发现与识别的问题,街景理解团队提出了一种基于样本感知、挖掘、净化的困难目标发现框架(Perceive, Excavate and Purify,简称PEP),如下图5所示:

首先,利用特征金字塔主干网络提取不同尺度的特征,然后将不同尺度特征分别输入到三个分支:实例感知分支、实例描述分支、特征学习分支。
实例感知分支对主干特征每个像素点进行分类,初步确定像素点位置是否存在实例;实例描述分支学习不同实例的原始特征描述子,同时利用样本挖掘子网络来挖掘困难目标,并表征为提取描述子。此外,引入实例关联子网络来提高相同实例的相似性、降低不同实例的相似性,实现目标净化,进一步提高分割性能。最后,原始的和挖掘的实例描述子与特征学习分支的通用特征实施卷积操作得到各个目标的分割结果。
最终,与主流的分割方法相比,基于样本自动挖掘的困难目标发现方法在COCO[40]等数据集上达到领先的精度。
3.2 分割模型的高效率迭代
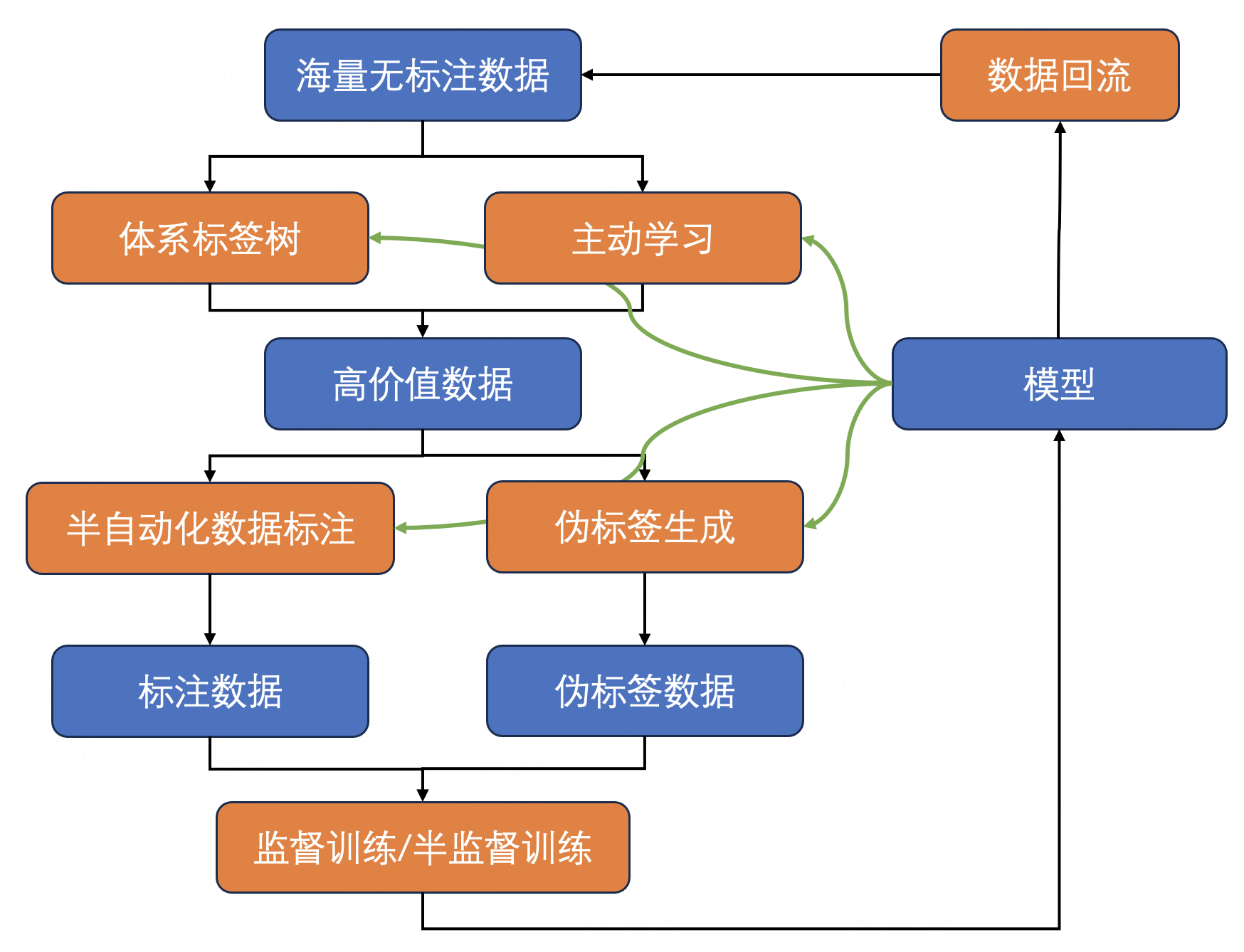
为了更好地适应街景理解中变化多样的真实场景,满足各种不断新增的实际业务需求,街景分割模型需要不断进行迭代。因此,建立一种高效率的迭代方式是十分必要的。街景理解团队经过长期探索,构建了一套面向分割任务的高效数据-模型闭环,能够以有限的成本积累大量的高质量有标签分割数据集,不断提升分割模型的性能,还能够高效地完成模型迭代,以满足实际业务场景的定制化需求。数据-模型闭环的整体流程图如下图6所示:

实际的街景理解业务场景中通过数据回流可以获取海量的无标注数据,这些无标注数据经过众多街景理解模型的推理预测可以得到丰富多样的标签属性,由此可以构建能够覆盖各种复杂场景、层次结构丰富的街景理解体系标签树。在新增的业务需求到来时,依靠体系标签树可以及时高效地获取大量与需求相关性较高的数据。此外,模型在数量众多的无标注数据上通过主动学习也可以筛选挖掘出不确定性更高、对模型迭代更加有价值的数据。
面对高价值的数据,通过模型与标注人员高效协同作业的半自动化数据标注,可以获得标注质量更有保证的数据,也可以通过伪标签技术,基于已有的模型获取大量带有伪标签的数据,然后通过有监督或半监督训练完成模型迭代。迭代之后,性能更加优异、能力更加丰富的新模型不仅能够在业务场景中更好地赋能,还能够更好地助力数据-模型闭环中的各个环节。由此,数据-模型闭环实现不断迭代、循环。
在分割模型的实际部署应用时,需要平衡好业务侧的识别精度和模型的计算资源。为此,构建了包括轻量级、中等量级、重量级的分割模型族。轻量级的分割模型凭借其较小的参数量和极高的吞吐量,常用于计算资源有限的端侧部署或者调用量极大的服务端部署等场景;中等量级的分割模型则用于对精度要求更高,调用量规模中等的场景;重量级的分割模型则凭借其极高的模型容量和识别精度,通过模型蒸馏、伪标签生成、预标注生成等手段助力更加轻量的模型的性能提升和数据-模型闭环,使其优势能够发挥到实际业务场景的前线。
此外,通过模型量化、高性能部署等手段,可以进一步提高模型的执行效率,降低计算成本,实现分割模型的高效率应用。
3.3 通向统一开放的街景分割
近期,随着ChatGPT[41]、Stable Diffusion[42]等自然语言处理、多模态大模型的火爆,人们对大模型、统一模型的关注度持续提升,统一的视觉大模型的热度也不断上升,Segment Anything Model[38]、UniAD[43]等的出现也显示出了通用统一的基础模型在视觉领域的潜力。街景理解团队在分割统一大模型上也在不断探索。
在图像分割上,探索涵盖语义分割、实例分割、全景分割、边缘检测等多任务的统一分割模型结构,并通过多任务训练充分发挥多种类型分割标注数据的潜力,保证不同任务间相互配合,取得增益。在视频分割上,也在探索涵盖视频语义分割、视频实例分割、视频全景分割、视频目标分割等任务的统一分割模型结构,在视频分割标注困难的情况下充分利用已有的各种视频分割标注及图像标注数据。此外,将图像和视频的各自分割任务中学习到的知识迁移到另一个任务中也是十分重要的研究内容。
另外,分割任务与其他视觉任务的相互融合、相互配合也是一个十分重要的方向,其在街景理解技术体系中有着重要的作用。如分割任务与分类、检测任务的融合,不仅能够在计算资源有限的场景下降低资源的占用,提高系统整体的吞吐,还能充分发挥不同视觉任务监督信息的潜力。
除了视觉任务内各个任务之间的融合和统一,与分割任务相关的跨模态研究也有着重大潜力,如与文本模态结合的开集分割任务、文本引导的指向性分割任务等,其不仅能够将分割任务推广到更加开放的真实环境中,还能够通过文本这个桥梁提高人与分割模型之间的交互能力,使其能够更加快速、精准地实现定制化的分割需求。基于分割任务的更高层次的语义推理研究也有着重要的价值,在分割技术这样细粒度的基础场景理解、语义解析能力的加持下,辅以知识先验、逻辑推理能力强大的大语言模型,在未来也能够在街景理解场景中产生巨大的应用价值。
总之,通向更加统一、更加开放的街景视觉分割模型已经成为了现在以及未来的重要方向,街景理解团队将会继续实践、沉淀,探索视觉分割模型的未来。
4 CVPR 2023 技术成果
基于街景理解中的分割技术积累,街景理解团队在CVPR 2023发表了2篇Workshop论文,并在相关竞赛中取得了2项冠军1项季军的成绩,同时相应技术成果已经申请多项国家专利。
4.1 论文发表
面向分割任务的基于时空对齐的复杂目标精准分割方法、基于样本自动挖掘的困难目标发现方法完善为2篇学术论文:《Motion-state Alignment for Video Semantic Segmentation》[44]、《Perceive, Excavate and Purify: A Novel Object Mining Framework for Instance Segmentation》[45],被CVPR 2023接收为Workshop论文(8页长文)。
4.2 恶劣天气街景理解竞赛双赛道冠军
在自动驾驶场景中,恶劣天气(如雾、雨、雪、弱光、夜间、曝光、阴影等)会给感知系统带来很大的干扰。为了保证自动驾驶汽车在恶劣天气的情况下平稳运行,感知系统需要具备处理极端天气的能力。虽然计算机视觉技术在街景理解等场景中的表现正在快速发展,但是已有的评测基准主要集中在晴朗的天气条件下(好天气、有利的照明),即使是当前性能最好的算法,在恶劣天气条件下也会出现严重的性能下降。为此,ACDC Challenge提出了专门针对恶劣天气的评测基准,用于促进对不利天气和光照条件下鲁棒视觉算法设计的研究。
本次竞赛中,街景理解团队获得了语义分割、全景分割两个赛道的冠军。
4.3 视频理解竞赛视频全景分割赛道季军
像素级场景理解是计算机视觉中的基本问题之一,其目的是识别给定图像中每个目标的语义类别和准确位置。由于现实世界实际上是动态而非静态的,因此面向视频的全景分割对于现实应用具有合理性和实用性。因此,PVUW Challenge提出了自然场景下具有实用且具有挑战的大规模视频全景分割数据集并举办竞赛,用于促进视频全景分割的算法研究。
本次竞赛中,街景理解团队获得了视频全景分割赛道的季军。
5 业务应用
美团街景理解中的分割技术在多个业务场景得到了广泛应用,其中主要包括地图、自动配送、门店实景化等业务。
地图是美团本地生活服务必不可少的基础设施,地图数据自动化生产是地图业务的重要环节,该环节主要从图像等数据中进行各类交通要素的提取与处理,分割技术在其中发挥着重要作用。首先,分割技术作用于低质图像过滤,提取道路、车辆、镜头遮挡物等类别的准确区域,识别并防止了道路拥堵、镜头遮挡等低质图像影响地图数据生产流程。同时,分割技术作用于交通要素提取,有效提取各类车道线(例如单白实线、双黄虚线、四线等)、各类物体隔离物(例如栅栏、水马、混凝土石墩等)的位置信息、轮廓信息、语义信息、实例信息等,用于后续要素生产。
此外,分割技术作用于道路结构提取,解析主辅路及路口结构等,获取道路结构,同时用于交通要素的位置信息提取。另外,分割技术也作用于卫星影像识别,如自动化提取建筑楼栋用于地图前端的渲染等。如下图7所示:

自动配送业务围绕美团外卖、跑腿等核心业务,提升配送效率和用户体验。高精地图是自动驾驶的核心基建,为了保证低成本、高鲜度,高精地图的生产过程中视频图像数据的分割发挥着重要作用。其中,各类车道线、地面箭头、交通标牌等各类要素分割为交通要素的提取提供了重要信息,杆体、公交站台等交通设施的分割为交通设施提取提供了重要信息,提高了高精地图生产中要素提取的自动化率和精度。
此外,高效率的语义分割模型为高精地图的定位图层提供了70+类的语义分割,支持了定位图层的生产,高精度语义分割支持了感知模型的半监督学习。另外,视频图像分割技术为视觉高精地图建图提供了各类要素的提取及跟踪能力,提高了建图的成功率、自动化率和精度。
门店实景化业务涉及广泛的线下室内场景,目的是提供基于以视觉为主的室内建图与渲染解决方案,提供对线下场景的几何、语义、物体等内容的理解以及渲染能力,分割技术在其中发挥着重要作用。在门店实景化业务中,分割技术提高了重建精度和渲染成功率,有效支持了门店布局估计、营业面积计算、关键设施自动化计数等。
此外,分割技术在智能标注、数据生成等应用中也发挥着重要作用,同时也在为街景理解中其他技术进行赋能。
6 总结与展望
分割技术在街景理解中占有重要地位,同时也面临众多挑战。为了应对这些挑战,美团街景理解团队构建了一套兼顾精度与效率的分割技术体系,在业务应用中取得了显著效果。
随着人工智能技术的发展,街景理解中的分割技术也将更加精确、更加通用、更加智能。结合多源数据与先进模型的自动化迭代,分割效果将会越来越准确;结合语言及视觉大模型等先进技术,分割技术将逐渐实现开放世界的“万物分割”;结合大规模语言模型的成功与经验,分割技术也将通向更高层语义关系的建模与推理。
未来,美团街景理解团队将不断推动视觉技术在街景理解中的应用与演进,为场景重建、自动驾驶、机器人导航等应用场景提供更加高效便捷的技术支持。
7 作者简介
金明、旺旺、祎婷、兴岳、钧峰等,均来自美团基础研发平台/视觉智能部。
8 参考文献
- [1] Cordts, Marius and Omran, Mohamed and Ramos, Sebastian and Rehfeld, Timo and Enzweiler, Markus and Benenson, Rodrigo and Franke, Uwe and Roth, Stefan and Schiele, Bernt. The cityscapes dataset for semantic urban scene understanding. In CVPR, 2016.
- [2] Christos Sakaridis, Dengxin Dai, and Luc Van Gool. ACDC: The Adverse Conditions Dataset with Correspondences for Semantic Driving Scene Understanding. In ICCV, 2021.
- [3] Kirillov, Alexander and He, Kaiming and Girshick, Ross and Rother, Carsten and Doll{\‘a}r, Piotr. Panoptic segmentation. In CVPR, 2019.
- [4] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
- [5] Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, 2015.
- [6] Chen, Liang-Chieh and Papandreou, George and Kokkinos, Iasonas and Murphy, Kevin and Yuille, Alan L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. TPAMI, 2017.
- [7] Yuan, Yuhui, Xilin Chen, and Jingdong Wang. Object-contextual representations for semantic segmentation. In ECCV, 2020.
- [8] Xie, Enze and Wang, Wenhai and Yu, Zhiding and Anandkumar, Anima and Alvarez, Jose M and Luo, Ping. SegFormer: Simple and efficient design for semantic segmentation with transformers. In NeurIPS, 2021.
- [9] He, Kaiming and Gkioxari, Georgia and Doll{\‘a}r, Piotr and Girshick, Ross. Mask r-cnn. In ICCV, 2017.
- [10] Bolya, Daniel and Zhou, Chong and Xiao, Fanyi and Lee, Yong Jael. Yolact: Real-time instance segmentation. In ICCV, 2019.
- [11] Bolya, Daniel and Zhou, Chong and Xiao, Fanyi and Lee, Yong Jae. Solo: Segmenting objects by locations. In ECCV, 2020.
- [12] Mohan, Rohit and Valada, Abhinav. Efficientps: Efficient panoptic segmentation. IJCV, 2021.
- [13] Cheng, Bowen and Collins, Maxwell D and Zhu, Yukun and Liu, Ting and Huang, Thomas S and Adam, Hartwig and Chen, Liang-Chieh. Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. In CVPR, 2020.
- [14] Xiong, Yuwen and Liao, Renjie and Zhao, Hengshuang and Hu, Rui and Bai, Min and Yumer, Ersin and Urtasun, Raquel. Upsnet: A unified panoptic segmentation network. In CVPR, 2019.
- [15] Zhou, Tianfei and Porikli, Fatih and Crandall, David J and Van Gool, Luc and Wang, Wenguan. A survey on deep learning technique for video segmentation. TPAMI, 2022.
- [16] Caelles, Sergi and Maninis, Kevis-Kokitsi and Pont-Tuset, Jordi and Leal-Taix{\‘e}, Laura and Cremers, Daniel and Van Gool, Luc. One-shot video object segmentation. In CVPR, 2017.
- [17] Zhou, Tianfei and Li, Jianwu and Wang, Shunzhou and Tao, Ran and Shen, Jianbing. Matnet: Motion-attentive transition network for zero-shot video object segmentation. TIP, 2020.
- [18] Wang, Qiang and Zhang, Li and Bertinetto, Luca and Hu, Weiming and Torr, Philip HS. Fast online object tracking and segmentation: A unifying approach. In CVPR, 2019.
- [19] Oh, Seoung Wug and Lee, Joon-Young and Xu, Ning and Kim, Seon Joo. Video object segmentation using space-time memory networks. In ICCV, 2019.
- [20] Yang, Zongxin, Yunchao Wei, and Yi Yang. Associating objects with transformers for video object segmentation. In NeurIPS 2021.
- [21] Cheng, Ho Kei, Yu-Wing Tai, and Chi-Keung Tang. Modular interactive video object segmentation: Interaction-to-mask, propagation and difference-aware fusion. In CVPR, 2021.
- [22] Ye, Linwei and Rochan, Mrigank and Liu, Zhi and Zhang, Xiaoqin and Wang, Yang. Referring segmentation in images and videos with cross-modal self-attention network. TPAMI, 2021.
- [23] Yu, Changqian and Wang, Jingbo and Peng, Chao and Gao, Changxin and Yu, Gang and Sang, Nong. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In ECCV 2018.
- [24] Fan, Mingyuan and Lai, Shenqi and Huang, Junshi and Wei, Xiaoming and Chai, Zhenhua and Luo, Junfeng and Wei, Xiaolin. Rethinking bisenet for real-time semantic segmentation. In CVPR, 2021.
- [25] Zhao, Hengshuang and Shi, Jianping and Qi, Xiaojuan and Wang, Xiaogang and Jia, Jiaya. Pyramid scene parsing network. In CVPR, 2017.
- [26] Hao Wang, Weining Wang, and Jing Liu. Temporal memory attention for video semantic segmentation. In ICIP 2021.
- [27] Abhinav Shrivastava, Abhinav Gupta, and Ross Girshick. Training region-based object detectors with online hard example mining. In CVPR, 2016.
- [28] SouYoung Jin, Aruni RoyChowdhury, Huaizu Jiang, Ashish Singh, Aditya Prasad, Deep Chakraborty, and Erik Learned- Miller. Unsupervised hard example mining from videos for improved object detection. In ECCV, 2018.
- [29] Yumin Suh, Bohyung Han, Wonsik Kim, and Kyoung Mu Lee. Stochastic class-based hard example mining for deep metric learning. In CVPR, 2019.
- [30] Lin, Di and Dai, Jifeng and Jia, Jiaya and He, Kaiming and Sun, Jian. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In CVPR, 2016.
- [31] Chen, Xi and Zhao, Zhiyan and Zhang, Yilei and Duan, Manni and Qi, Donglian and Zhao, Hengshuang. Focalclick: Towards practical interactive image segmentation. In CVPR, 2022.
- [32] Zhang, Chi and Lin, Guosheng and Liu, Fayao and Yao, Rui and Shen, Chunhua. Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning. In CVPR, 2019.
- [33] He, Shuting, Henghui Ding, and Wei Jiang. Primitive generation and semantic-related alignment for universal zero-shot segmentation. In CVPR, 2023.
- [34] Zhang, Xiangyu and Zhou, Xinyu and Lin, Mengxiao and Sun, Jian. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In CVPR, 2018.
- [35] Howard, Andrew G and Zhu, Menglong and Chen, Bo and Kalenichenko, Dmitry and Wang, Weijun and Weyand, Tobias and Andreetto, Marco and Adam, Hartwig. Mobilenets: Efficient convolutional neural networks for mobile vision applications. Arxiv, 2017.
- [36] Cheng, Bowen, Alex Schwing, and Alexander Kirillov. Per-pixel classification is not all you need for semantic segmentation. In NeurIPS, 2021.
- [37] Jain, Jitesh and Li, Jiachen and Chiu, Mang Tik and Hassani, Ali and Orlov, Nikita and Shi, Humphrey. Oneformer: One transformer to rule universal image segmentation. In CVPR, 2023.
- [38] Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C and Lo, Wan-Yen and others. Segment anything. Arxiv, 2023.
- [39] Gabriel J Brostow, Jamie Shotton, Julien Fauqueur, and Roberto Cipolla. Segmentation and recognition using structure from motion point clouds. In ECCV, 2008.
- [40] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
- [41] OpenAI.https://openai.com/blog/chatgpt. 2022.
- [42] Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj{\“o}rn. High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- [43] Hu, Yihan and Yang, Jiazhi and Chen, Li and Li, Keyu and Sima, Chonghao and Zhu, Xizhou and Chai, Siqi and Du, Senyao and Lin, Tianwei and Wang, Wenhai and others. Planning-oriented autonomous driving. In CVPR, 2023.
- [44] Su, Jinming and Yin, Ruihong and Zhang, Shuaibin and Luo, Junfeng. Motion-state Alignment for Video Semantic Segmentation. In CVPRW, 2023.
- [45] Su, Jinming and Yin, Ruihong and Chen, Xingyue and Luo, Junfeng. Perceive, Excavate and Purify: A Novel Object Mining Framework for Instance Segmentation. In CVPRW, 2023.
如有侵权请联系:admin#unsafe.sh