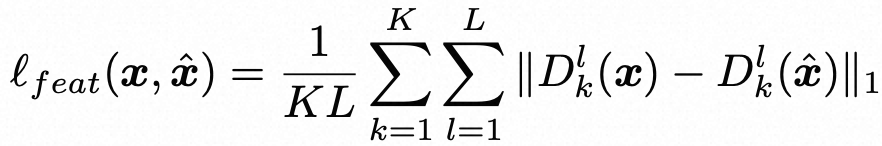
2023-8-11 11:59:0 Author: www.cnblogs.com(查看原文) 阅读量:15 收藏
神经生成模型挑战了我们创造数字内容的方式。从生成高质量图像和语音,到生成长文本,再到最近提出的文本引导的图像生成,这些模型展示了令人印象深刻的结果。这引出一个问题,对于文本引导的生成模型来说,音频的等效物是什么?可以是文本吗?我们用文本来抽象出世界上纷繁复杂地音频吗?
从生成声景、音乐或语音,一个高保真度、可控性和输出多样性的解决方案,将成为电影制作人、视频游戏制作人和任何虚拟环境创作者的有用补充。
虽然图像生成和音频生成有很多共同之处,但也有一些关键的区别。
- 从文本向音频概率空间的映射比较困难:音频本质上是一维信号,因此具有较少的自由度来区分重叠的"对象"。现实世界的音频本身就具有混响,这使得区分周围环境中的对象的任务更加困难。
- 从音频生成到人类感知之间还存在差异性Gap:心理听觉和心理视觉属性也有所不同,例如听觉"分辨率"(等响度)在频率上呈U形,4kHz处有一个低谷,8kHz处有一个峰值。
- 音频标注语料匮乏:具备文本描述的音频数据的可用性和数量远远低于文本-图像配对数据。这使得生成未见过的音频作品成为一项艰巨的任务(例如生成"一匹马骑着宇航员在太空中"的音频等效物)。
在这项工作中,我们致力于解决在输入描述性文本条件下生成音频样本的问题。我们还将所提出的方法扩展到有条件和无条件的音频生成。
例如,我们生成"一条狗在繁忙的街道上吠叫,有人在吹喇叭"。在上述提示中,模型必须生成三类声学内容,具有不同程度的背景/前景、持续时间和在时间轴上的相对位置,这种组合在训练集中极不可能出现。因此,生成这样的音频是一项具有挑战性的任务,需要考虑泛化能力、音频保真度、制作和混音等方面。
我们提出了AUDIOGEN,一个自回归的文本引导音频生成模型。AUDIOGEN由两个主要阶段组成。
- 第一阶段使用神经音频压缩模型,将原始音频编码为离散的令牌序列。该模型以端到端的方式训练,从压缩表示中重构输入音频,并添加了一组鉴别器的感知损失。这种音频表示旨在生成高保真度的音频样本,同时仍然紧凑。
- 第二阶段利用自回归的Transformer解码器语言模型,对从第一阶段获得的离散音频令牌进行操作,同时以文本输入为条件。我们使用在大型文本语料库上预训练的单独文本编码器模型表示文本,即T5。预训练的文本编码器能够泛化到当前文本-音频数据集中缺失的文本概念,这一段尤其对于文本-音频数据缺乏多样性和描述性存在限制等问题时,尤为重要。
与现有的文本到音频工作相比,AUDIOGEN生成的样本在客观和主观评估指标上表现更好。特别是,AUDIOGEN创建了更自然的未见过的音频作品。最后,我们通过利用残差矢量量化(用于声学单元)和多流Transformer,实证地展示了如何将所提出的方法扩展到有条件和无条件的音频生成。
论文的主要贡献:
- 我们提出了一种基于文本描述或音频提示的最先进的自回归音频生成模型,并通过客观和主观(人类听众)评分进行了评估。具体而言,我们提出了两种模型变体,一个具有2.85亿个参数,另一个具有10亿个参数。
- 我们在两个方面改进了文本到音频生成。我们通过在音频语言模型之上应用无分类器的引导来改进文本的一致性。我们通过即时文本和音频混合来改善组合性。
- 我们展示了所提出的方法可以扩展到在有条件和无条件的文本条件下进行音频生成。
- 我们通过利用残余向量量化(用于声学单元)和多流Transformer来探索音频保真度和采样时间之间的权衡。
参考链接:
https://huggingface.co/spaces/facebook/MusicGen?continueFlag=359cf5638b1ead03794a08a189551880 https://ai.meta.com/blog/audiocraft-musicgen-audiogen-encodec-generative-ai-audio/?continueFlag=359cf5638b1ead03794a08a189551880 https://felixkreuk.github.io/audiogen/
所提出的方法AUDIOGEN基于两个主要步骤:
- (i)使用自动编码方法学习原始音频的离散表示。
- (ii)以文本特征为条件,在从音频编码器获得的向量基础上训练Transformer语言模型。然后,在推断时,我们从语言模型中采样,根据文本特征生成一组新的音频令牌。这些令牌可以使用步骤(i)中的解码器组件解码为Audio波形。
该方法的可视化描述如下图所示。

AUDIOGEN系统的总体概述
左边:音频表示模型
右边:音频语言模型。文本和音频嵌入在时间维度上连接在一起,并将拼接后向量,前馈传入由文本的K个因果自注意力(causal self-attention)和交叉注意力(cross-attention)块组成的神经网络结构中
0x1:AUDIO REPRESENTATION
一个持续时间为 d 的音频信号可以用一个序列 x ∈ [−1, 1]Ca×T 来表示,其中
- Ca是音频通道的数量
- T = d · fsr 是在给定采样率 fsr 下的音频样本数,在这项工作中,我们设置 fsr = 16kHz
音频表示模型由三个组件组成:
- (i)编码器网络E,它以一个音频片段作为输入并输出一个潜在表示z
- (ii)一个量化层Q,使用向量量化层(Vector Quantization)产生一个压缩表示zq
- (iii)一个解码器网络G从压缩的潜在表示zq中重建时域信号xˆ
整个系统端到端地训练,以最小化在时域和频域上应用的重建损失,以及以几个不同时间分辨率操作的感知损失。
使用预训练模型,我们可以利用编码器和量化器组件作为离散特征提取器(例如:Q ◦ E),以及利用G来解码表示为时域信号。对于Q,我们使用一个包含2048个码字的单码本(single codebook),每个码字是一个128维的向量。
上述方法见上图右图。
1、Architecture
我们采用了与Zeghidour等人和Li等人类似的自编码器模型(auto-encoder model)架构。
编码器模型E由一个具有C个通道的 1D 卷积以及后接的B个卷积块组成。每个卷积块由一个残差单元和一个下采样层组成,下采样层由一个步幅卷积(strided convolution)以及卷积核大小K为步幅S的两倍的卷积组成。残差单元包含两个卷积和一个跳跃连接。每当进行下采样时,通道数加倍。
卷积块后面是一个包含两层LSTM的序列建模层,以及一个最后的1D卷积层,核大小为7,输出通道数为D。
我们使用C = 32,B = 4,步幅为(2, 2, 2, 4)。
我们使用ELU作为非线性激活函数,并使用LayerNorm。
解码器与编码器在结构上相对应,使用转置卷积(transposed convolutions)代替步幅卷积(strided convolutions),并按照与编码器相反的顺序使用步幅,输出最终的音频。
2、Training Objective
我们采用基于GAN的训练目标进行优化,共同最小化重建损失和对抗损失的组合。
具体而言,在时域上,我们最小化目标音频和重建音频之间的L1距离,即:
![]()
对于频域损失,我们使用在多个时间尺度上对梅尔频谱的L1和L2损失的线性组合:

其中:
- Si是一个使用归一化STFT计算的64-bins梅尔谱图,窗口大小为2i,跳跃长度为2i/4
- e = 5, . . . ,11是尺度集合
- α表示在L1和L2项之间平衡的标量系数集合
我们设置αi = 1,为了进一步提高生成样本的质量。
同时,我们额外优化了一个基于多尺度STFT(MS-STFT)的鉴别器。多尺度鉴别器在捕捉音频信号中的不同结构方面非常擅长。MS-STFT鉴别器基于多个具有相同结构的子网络网络,以此对多尺度复数值STFT进行操作,每个子网络由一个2D卷积层组成(使用3x8的卷积核和32个通道),之后跟着一个在时间维度上具有增大的膨胀率的2D卷积(1、2和4),以及在频率轴上的步幅2。最后,一个3x3的2D卷积和步幅(1, 1)给出最终的预测。
我们使用5个不同的尺度,STFT窗口长度分别为[2048, 1024, 512, 256, 128]。
生成器的对抗损失构造如下,
![]()
其中K是鉴别器网络的数量。与前人在神经声码器上的工作类似,我们还为生成器包括了特征匹配损失,

其中 Dk 是鉴别器,L是鉴别器中的层数。
总体上,鉴别器被训练以最小化以下损失函数:
![]()
![]()
其中K是鉴别器的数量,而生成器被训练以最小化以下内容:
![]()
0x2:AUDIO LANGUAGE MODELING
在这项工作中,我们的目标是根据文本生成音频。具体而言,给定文本输入c,音频语言模型(ALM)组件输出一系列音频token![]() ,可通过G将其解码为原始音频。
,可通过G将其解码为原始音频。
考虑一个文本编码器F,它将原始文本输入映射为语义层表示(semantic dense representation),F(c) = u。然后,查找表(Look-Up-Table,LUT)将音频token![]() 嵌入到连续空间中,
嵌入到连续空间中,![]()
![]() 。
。
然后,我们将u和v连接起来创建![]() ,其中Tu和Tv分别是文本表示和音频表示的长度。
,其中Tu和Tv分别是文本表示和音频表示的长度。
利用上述表示,我们使用交叉熵损失函数训练一个由θ参数化的Transformer解码器语言模型。

文本表示是使用预训练的T5文本编码器获得的。
我们还尝试使用查找表(LUT)学习文本嵌入。尽管它产生了与T5模型相当的结果,但在训练过程中限制了我们对未知单词的泛化能力,因此我们没有继续追求这个方向。
Transformer解码器语言模型采用了类似GPT2的架构实现。为了实现更好的文本一致性,我们在每个注意力块中的音频和文本之间添加了交叉注意力。
1、Classifier Free-Guidance
在Ho&Salimans和Nichol等人的研究中,使用无分类器引导(Classifier Free Guidance,CFG)方法是控制样本质量和多样性之间权衡的有效机制。虽然CFG方法最初是针对扩散模型的得分函数估计提出的,但在这项工作中,我们将其应用于自回归模型。
在训练过程中,我们有条件地和无条件地优化Transformer-LM。在实践中,我们在10%的训练样本中随机省略文本条件。在推理时,我们从通过条件概率和无条件概率的线性组合获得的分布中进行采样。
形式上,我们从以下分布中进行采样:
![]()
其中γ是引导比例。
2、Multi-stream audio inputs
为了生成高质量的音频样本,我们将原始音频进行32倍下采样,每个音频token对应2毫秒。这要求我们处理非常长的序列,因为每秒的音频由500个token表示。对这样长的序列进行建模是一个众所周知的难题。
为了缓解这个问题,我们提出了一个多流表示和建模范式。Kharitonov等人证明了transformer能够同时建模多个流。
考虑一个长度为Tv的序列,我们可以使用两个大致相同比特率的并行流来学习长度为Tv/2的表示。这种方法可以推广到k个流,其中每个流的长度为Tv/k,每个码本的大小为2048/k。这样的表示可以通过将Q从单个码书矢量量化(code book Vector-Quantization)推广为残差向量量化模块(Residual Vector Quantization module)来获得。在时间t,网络输入k个离散码,然后使用k个嵌入层进行嵌入。时间t的最终嵌入是这k个嵌入的平均值。我们调整网络以输出k个码,使用k个LM预测头。
由于我们使用相对较小的下采样因子对音频token进行操作,音频令牌序列可能非常长。这会带来两个主要限制:
- (i)需要建模长序列
- (ii)推理时间较长
在这项工作中,我们提出了对第一个限制的一种可能的缓解方法,但这种方法的代价是生成质量较低的音频样本。当考虑高分辨率音频样本时(例如,48kHz的采样率),这些问题会变得更加严重。
另一个限制与音频组合有关。尽管混合增强大大改善了模型分离源和创建复杂组合的能力,但它仍然缺乏对场景中时间顺序的理解,例如,狗在叫,然后鸟在哼唱,与狗在叫并且鸟在背景中哼唱。
最后,由于我们在训练集中省略了大部分语音样本,所提出的方法经常生成无法理解的语音。可以通过使用更多的语音数据、更好的语音数据增强方法或提供额外的语音特征来缓解这个问题。
在这项工作中,我们提出了一种基于Transformer的生成模型,名为AUDIOGEN,它在学习的离散音频表示上运行。
与先前的工作不同,我们经验证明自回归模型可以有条件或无条件地生成高质量的音频样本。我们展示了即时文本和音频混合增强可以改善模型性能,并提供了一项消融研究,分析了CFG和多流处理的效果。就更广泛的影响而言,这项工作为构建更好的文本到音频模型奠定了基础。此外,所提出的研究可以开辟涉及基准测试、语义音频编辑、从离散单元进行音频源分离等未来研究方向。
参考链接:
https://github.com/facebookresearch/audiocraft/blob/main/README.md https://github.com/facebookresearch/audiocraft/blob/main/docs/AUDIOGEN.md https://github.com/facebookresearch/audiocraft/tree/main
如有侵权请联系:admin#unsafe.sh