Loading...


A clear sign of maturing for any new programming language or environment is how easy and efficient debugging them is. Programming, like any other complex task, involves various challenges and potential pitfalls. Logic errors, off-by-ones, null pointer dereferences, and memory leaks are some examples of things that can make software developers desperate if they can't pinpoint and fix these issues quickly as part of their workflows and tools.
WebAssembly (Wasm) is a binary instruction format designed to be a portable and efficient target for the compilation of high-level languages like Rust, C, C++, and others. In recent years, it has gained significant traction for building high-performance applications in web and serverless environments.
Cloudflare Workers has had first-party support for Rust and Wasm for quite some time. We've been using this powerful combination to bootstrap and build some of our most recent services, like D1, Constellation, and Signed Exchanges, to name a few.
Using tools like Wrangler, our command-line tool for building with Cloudflare developer products, makes streaming real-time logs from our applications running remotely easy. Still, to be honest, debugging Rust and Wasm with Cloudflare Workers involves a lot of the good old time-consuming and nerve-wracking printf'ing strategy.
What if there’s a better way? This blog is about enabling and using Wasm core dumps and how you can easily debug Rust in Cloudflare Workers.
What are core dumps?
In computing, a core dump consists of the recorded state of the working memory of a computer program at a specific time, generally when the program has crashed or otherwise terminated abnormally. They also add things like the processor registers, stack pointer, program counter, and other information that may be relevant to fully understanding why the program crashed.
In most cases, depending on the system’s configuration, core dumps are usually initiated by the operating system in response to a program crash. You can then use a debugger like gdb to examine what happened and hopefully determine the cause of a crash. gdb allows you to run the executable to try to replicate the crash in a more controlled environment, inspecting the variables, and much more. The Windows' equivalent of a core dump is a minidump. Other mature languages that are interpreted, like Python, or languages that run inside a virtual machine, like Java, also have their ways of generating core dumps for post-mortem analysis.
Core dumps are particularly useful for post-mortem debugging, determining the conditions that lead to a failure after it has occurred.
WebAssembly core dumps
WebAssembly has had a proposal for implementing core dumps in discussion for a while. It's a work-in-progress experimental specification, but it provides basic support for the main ideas of post-mortem debugging, including using the DWARF (debugging with attributed record formats) debug format, the same that Linux and gdb use. Some of the most popular Wasm runtimes, like Wasmtime and Wasmer, have experimental flags that you can enable and start playing with Wasm core dumps today.
If you run Wasmtime or Wasmer with the flag:
--coredump-on-trap=/path/to/coredump/file
The core dump file will be emitted at that location path if a crash happens. You can then use tools like wasmgdb to inspect the file and debug the crash.
But let's dig into how the core dumps are generated in WebAssembly, and what’s inside them.
How are Wasm core dumps generated
(and what’s inside them)
When WebAssembly terminates execution due to abnormal behavior, we say that it entered a trap. With Rust, examples of operations that can trap are accessing out-of-bounds addresses or a division by zero arithmetic call. You can read about the security model of WebAssembly to learn more about traps.
The core dump specification plugs into the trap workflow. When WebAssembly crashes and enters a trap, core dumping support kicks in and starts unwinding the call stack gathering debugging information. For each frame in the stack, it collects the function parameters and the values stored in locals and in the stack, along with binary offsets that help us map to exact locations in the source code. Finally, it snapshots the memory and captures information like the tables and the global variables.
DWARF is used by many mature languages like C, C++, Rust, Java, or Go. By emitting DWARF information into the binary at compile time a debugger can provide information such as the source name and the line number where the exception occurred, function and argument names, and more. Without DWARF, the core dumps would be just pure assembly code without any contextual information or metadata related to the source code that generated it before compilation, and they would be much harder to debug.
WebAssembly uses a (lighter) version of DWARF that maps functions, or a module and local variables, to their names in the source code (you can read about the WebAssembly name section for more information), and naturally core dumps use this information.
All this information for debugging is then bundled together and saved to the file, the core dump file.
The core dump structure has multiple sections, but the most important are:
- General information about the process;
- The threads and their stack frames (note that WebAssembly is single threaded in Cloudflare Workers);
- A snapshot of the WebAssembly linear memory or only the relevant regions;
- Optionally, other sections like globals, data, or table.
Here’s the thread definition from the core dump specification:
corestack ::= customsec(thread-info vec(frame))
thread-info ::= 0x0 thread-name:name ...
frame ::= 0x0 ... funcidx:u32 codeoffset:u32 locals:vec(value)
stack:vec(value)
A thread is a custom section called corestack. A corestack section contains the thread name and a vector (or array) of frames. Each frame contains the function index in the WebAssembly module (funcidx), the code offset relative to the function's start (codeoffset), the list of locals, and the list of values in the stack.
Values are defined as follows:
value ::= 0x01 => ∅
| 0x7F n:i32 => n
| 0x7E n:i64 => n
| 0x7D n:f32 => n
| 0x7C n:f64 => n
At the time of this writing these are the possible numbers types in a value. Again, we wanted to describe the basics; you should track the full specification to get more detail or find information about future changes. WebAssembly core dump support is in its early stages of specification and implementation, things will get better, things might change.
This is all great news. Unfortunately, however, the Cloudflare Workers runtime doesn’t support WebAssembly core dumps yet. There is no technical impediment to adding this feature to workerd; after all, it's based on V8, but since it powers a critical part of our production infrastructure and products, we tend to be conservative when it comes to adding specifications or standards that are still considered experimental and still going through the definitions phase.
So, how do we get core Wasm dumps in Cloudflare Workers today?
Polyfilling
Polyfilling means using userland code to provide modern functionality in older environments that do not natively support it. Polyfills are widely popular in the JavaScript community and the browser environment; they've been used extensively to address issues where browser vendors still didn't catch up with the latest standards, or when they implement the same features in different ways, or address cases where old browsers can never support a new standard.
Meet wasm-coredump-rewriter, a tool that you can use to rewrite a Wasm module and inject the core dump runtime functionality in the binary. This runtime code will catch most traps (exceptions in host functions are not yet catched and memory violation not by default) and generate a standard core dump file. To some degree, this is similar to how Binaryen's Asyncify works.
Let’s look at code and see how this works. He’s some simple pseudo code:
export function entry(v1, v2) {
return addTwo(v1, v2)
}
function addTwo(v1, v2) {
res = v1 + v2;
throw "something went wrong";
return res
}
An imaginary compiler could take that source and generate the following Wasm binary code:
(func $entry (param i32 i32) (result i32)
(local.get 0)
(local.get 1)
(call $addTwo)
)
(func $addTwo (param i32 i32) (result i32)
(local.get 0)
(local.get 1)
(i32.add)
(unreachable) ;; something went wrong
)
(export "entry" (func $entry))
“;;” is used to denote a comment.
entry() is the Wasm function exported to the host. In an environment like the browser, JavaScript (being the host) can call entry().
Irrelevant parts of the code have been snipped for brevity, but this is what the Wasm code will look like after wasm-coredump-rewriter rewrites it:
(func $entry (type 0) (param i32 i32) (result i32)
...
local.get 0
local.get 1
call $addTwo ;; see the addTwo function bellow
global.get 2 ;; is unwinding?
if ;; label = @1
i32.const x ;; code offset
i32.const 0 ;; function index
i32.const 2 ;; local_count
call $coredump/start_frame
local.get 0
call $coredump/add_i32_local
local.get 1
call $coredump/add_i32_local
...
call $coredump/write_coredump
unreachable
end)
(func $addTwo (type 0) (param i32 i32) (result i32)
local.get 0
local.get 1
i32.add
;; the unreachable instruction was here before
call $coredump/unreachable_shim
i32.const 1 ;; funcidx
i32.const 2 ;; local_count
call $coredump/start_frame
local.get 0
call $coredump/add_i32_local
local.get 1
call $coredump/add_i32_local
...
return)
(export "entry" (func $entry))
As you can see, a few things changed:
- The (unreachable) instruction in
addTwo()was replaced by a call to$coredump/unreachable_shimwhich starts the unwinding process. Then, the location and debugging data is captured, and the function returns normally to theentry()caller. - Code has been added after the
addTwo()call instruction inentry()that detects if we have an unwinding process in progress or not. If we do, then it also captures the local debugging data, writes the core dump file and then, finally, moves to the unconditional trap unreachable.
In short, we unwind until the host function entry() gets destroyed by calling unreachable.
Let’s go over the runtime functions that we inject for more clarity, stay with us:
$coredump/start_frame(funcidx, local_count)starts a new frame in the coredump.$coredump/add_*_local(value)captures the values of function arguments and in locals (currently capturing values from the stack isn’t implemented.)$coredump/write_coredumpis used at the end and writes the core dump in memory. We take advantage of the first 1 KiB of the Wasm linear memory, which is unused, to store our core dump.
A diagram is worth a thousand words:
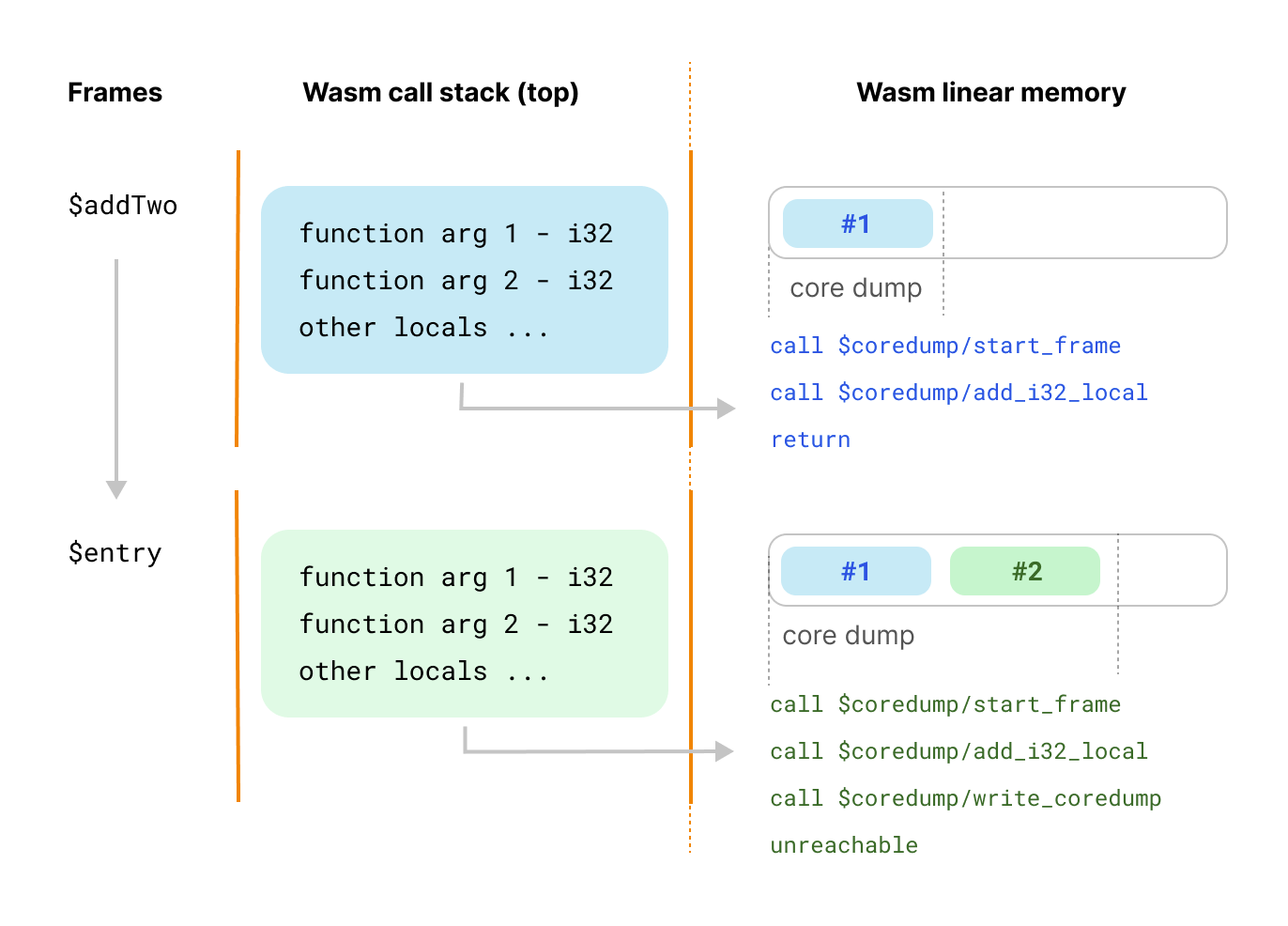
Wait, what’s this about the first 1 KiB of the memory being unused, you ask? Well, it turns out that most WebAssembly linters and tools, including Emscripten and WebAssembly’s LLVM don’t use the first 1 KiB of memory. Rust and Zig also use LLVM, but they changed the default. This isn’t pretty, but the hugely popular Asyncify polyfill relies on the same trick, so there’s reasonable support until we find a better way.
But we digress, let’s continue. After the crash, the host, typically JavaScript in the browser, can now catch the exception and extract the core dump from the Wasm instance’s memory:
try {
wasmInstance.exports.someExportedFunction();
} catch(err) {
const image = new Uint8Array(wasmInstance.exports.memory.buffer);
writeFile("coredump." + Date.now(), image);
}
If you're curious about the actual details of the core dump implementation, you can find the source code here. It was written in AssemblyScript, a TypeScript-like language for WebAssembly.
This is how we use the polyfilling technique to implement Wasm core dumps when the runtime doesn’t support them yet. Interestingly, some Wasm runtimes, being optimizing compilers, are likely to make debugging more difficult because function arguments, locals, or functions themselves can be optimized away. Polyfilling or rewriting the binary could actually preserve more source-level information for debugging.
You might be asking what about performance? We did some testing and found that the impact is negligible; the cost-benefit of being able to debug our crashes is positive. Also, you can easily turn wasm core dumps on or off for specific builds or environments; deciding when you need them is up to you.
Debugging from a core dump
We now know how to generate a core dump, but how do we use it to diagnose and debug a software crash?
Similarly to gdb (GNU Project Debugger) on Linux, wasmgdb is the tool you can use to parse and make sense of core dumps in WebAssembly; it understands the file structure, uses DWARF to provide naming and contextual information, and offers interactive commands to navigate the data. To exemplify how it works, wasmgdb has a demo of a Rust application that deliberately crashes; we will use it.
Let's imagine that our Wasm program crashed, wrote a core dump file, and we want to debug it.
$ wasmgdb source-program.wasm /path/to/coredump
wasmgdb>
When you fire wasmgdb, you enter a REPL (Read-Eval-Print Loop) interface, and you can start typing commands. The tool tries to mimic the gdb command syntax; you can find the list here.
Let's examine the backtrace using the bt command:
wasmgdb> bt
#18 000137 as __rust_start_panic () at library/panic_abort/src/lib.rs
#17 000129 as rust_panic () at library/std/src/panicking.rs
#16 000128 as rust_panic_with_hook () at library/std/src/panicking.rs
#15 000117 as {closure#0} () at library/std/src/panicking.rs
#14 000116 as __rust_end_short_backtrace<std::panicking::begin_panic_handler::{closure_env#0}, !> () at library/std/src/sys_common/backtrace.rs
#13 000123 as begin_panic_handler () at library/std/src/panicking.rs
#12 000194 as panic_fmt () at library/core/src/panicking.rs
#11 000198 as panic () at library/core/src/panicking.rs
#10 000012 as calculate (value=0x03000000) at src/main.rs
#9 000011 as process_thing (thing=0x2cff0f00) at src/main.rs
#8 000010 as main () at src/main.rs
#7 000008 as call_once<fn(), ()> (???=0x01000000, ???=0x00000000) at /rustc/b833ad56f46a0bbe0e8729512812a161e7dae28a/library/core/src/ops/function.rs
#6 000020 as __rust_begin_short_backtrace<fn(), ()> (f=0x01000000) at /rustc/b833ad56f46a0bbe0e8729512812a161e7dae28a/library/std/src/sys_common/backtrace.rs
#5 000016 as {closure#0}<()> () at /rustc/b833ad56f46a0bbe0e8729512812a161e7dae28a/library/std/src/rt.rs
#4 000077 as lang_start_internal () at library/std/src/rt.rs
#3 000015 as lang_start<()> (main=0x01000000, argc=0x00000000, argv=0x00000000, sigpipe=0x00620000) at /rustc/b833ad56f46a0bbe0e8729512812a161e7dae28a/library/std/src/rt.rs
#2 000013 as __original_main () at <directory not found>/<file not found>
#1 000005 as _start () at <directory not found>/<file not found>
#0 000264 as _start.command_export at <no location>
Each line represents a frame from the program's call stack; see frame #3:
#3 000015 as lang_start<()> (main=0x01000000, argc=0x00000000, argv=0x00000000, sigpipe=0x00620000) at /rustc/b833ad56f46a0bbe0e8729512812a161e7dae28a/library/std/src/rt.rs
You can read the funcidx, function name, arguments names and values and source location are all present. Let's select frame #9 now and inspect the locals, which include the function arguments:
wasmgdb> f 9
000011 as process_thing (thing=0x2cff0f00) at src/main.rs
wasmgdb> info locals
thing: *MyThing = 0xfff1c
Let’s use the p command to inspect the content of the thing argument:
wasmgdb> p (*thing)
thing (0xfff2c): MyThing = {
value (0xfff2c): usize = 0x00000003
}
You can also use the p command to inspect the value of the variable, which can be useful for nested structures:
wasmgdb> p (*thing)->value
value (0xfff2c): usize = 0x00000003
And you can use p to inspect memory addresses. Let’s point at 0xfff2c, the start of the MyThing structure, and inspect:
wasmgdb> p (MyThing) 0xfff2c
0xfff2c (0xfff2c): MyThing = {
value (0xfff2c): usize = 0x00000003
}
All this information in every step of the stack is very helpful to determine the cause of a crash. In our test case, if you look at frame #10, we triggered an integer overflow. Once you get comfortable walking through wasmgdb and using its commands to inspect the data, debugging core dumps will be another powerful skill under your belt.
Tidying up everything in Cloudflare Workers
We learned about core dumps and how they work, and we know how to make Cloudflare Workers generate them using the wasm-coredump-rewriter polyfill, but how does all this work in practice end to end?
We've been dogfooding the technique described in this blog at Cloudflare for a while now. Wasm core dumps have been invaluable in helping us debug Rust-based services running on top of Cloudflare Workers like D1, Privacy Edge, AMP, or Constellation.
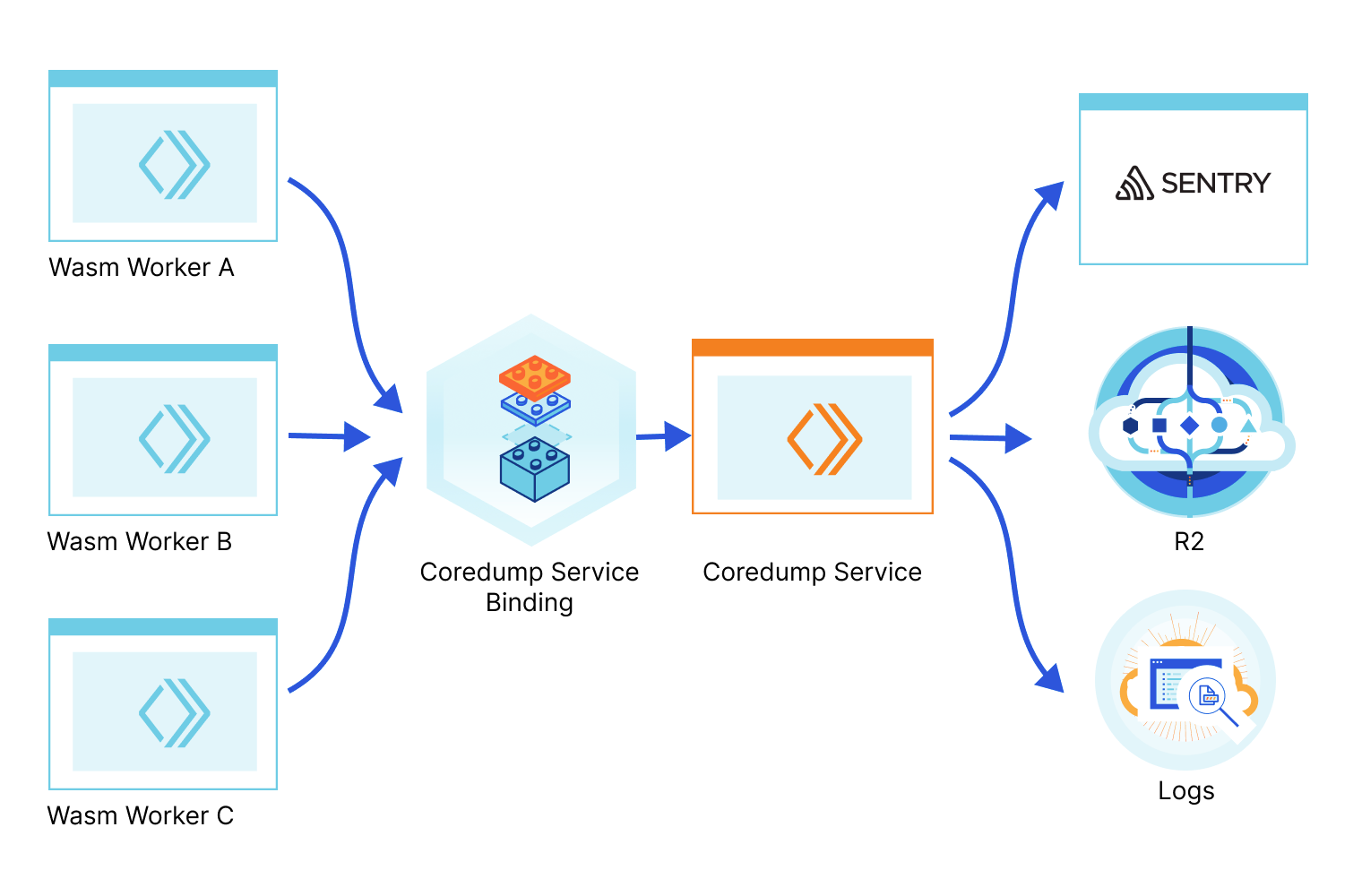
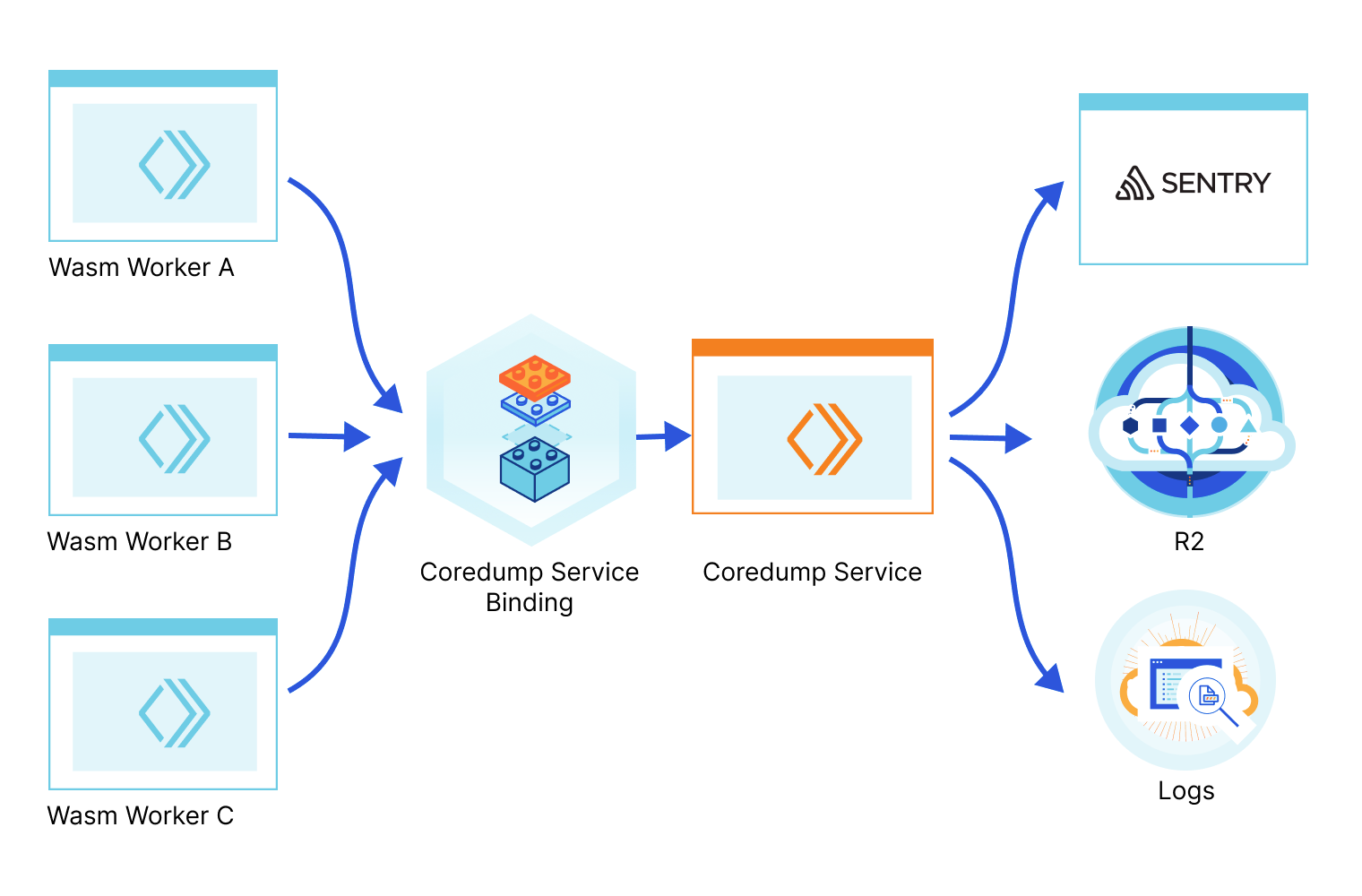
Today we're open-sourcing the Wasm Coredump Service and enabling anyone to deploy it. This service collects the Wasm core dumps originating from your projects and applications when they crash, parses them, prints an exception with the stack information in the logs, and can optionally store the full core dump in a file in an R2 bucket (which you can then use with wasmgdb) or send the exception to Sentry.
We use a service binding to facilitate the communication between your application Worker and the Coredump service Worker. A Service binding allows you to send HTTP requests to another Worker without those requests going over the Internet, thus avoiding network latency or having to deal with authentication. Here’s a diagram of how it works:
Using it is as simple as npm/yarn installing @cloudflare/wasm-coredump, configuring a few options, and then adding a few lines of code to your other applications running in Cloudflare Workers, in the exception handling logic:
import shim, { getMemory, wasmModule } from "../build/worker/shim.mjs"
const timeoutSecs = 20;
async function fetch(request, env, ctx) {
try {
// see https://github.com/rustwasm/wasm-bindgen/issues/2724.
return await Promise.race([
shim.fetch(request, env, ctx),
new Promise((r, e) => setTimeout(() => e("timeout"), timeoutSecs * 1000))
]);
} catch (err) {
const memory = getMemory();
const coredumpService = env.COREDUMP_SERVICE;
await recordCoredump({ memory, wasmModule, request, coredumpService });
throw err;
}
}
The ../build/worker/shim.mjs import comes from the worker-build tool, from the workers-rs packages and is automatically generated when wrangler builds your Rust-based Cloudflare Workers project. If the Wasm throws an exception, we catch it, extract the core dump from memory, and send it to our Core dump service.
You might have noticed that we race the workers-rs shim.fetch() entry point with another Promise to generate a timeout exception if the Rust code doesn't respond earlier. This is because currently, wasm-bindgen, which generates the glue between the JavaScript and Rust land, used by workers-rs, has an issue where a Promise might not be rejected if Rust panics asynchronously (leading to the Worker runtime killing the worker with “Error: The script will never generate a response”.). This can block the wasm-coredump code and make the core dump generation flaky.
We are working to improve this, but in the meantime, make sure to adjust timeoutSecs to something slightly bigger than the typical response time of your application.
Here’s an example of a Wasm core dump exception in Sentry:

You can find a working example, the Sentry and R2 configuration options, and more details in the @cloudflare/wasm-coredump GitHub repository.
Too big to fail
It's worth mentioning one corner case of this debugging technique and the solution: sometimes your codebase is so big that adding core dump and DWARF debugging information might result in a Wasm binary that is too big to fit in a Cloudflare Worker. Well, worry not; we have a solution for that too.
Fortunately the DWARF for WebAssembly specification also supports external DWARF files. To make this work, we have a tool called debuginfo-split that you can add to the build command in the wrangler.toml configuration:
command = "... && debuginfo-split ./build/worker/index.wasm"
What this does is it strips the debugging information from the Wasm binary, and writes it to a new separate file called debug-{UUID}.wasm. You then need to upload this file to the same R2 bucket used by the Wasm Coredump Service (you can automate this as part of your CI or build scripts). The same UUID is also injected into the main Wasm binary; this allows us to correlate the Wasm binary with its corresponding DWARF debugging information. Problem solved.
Binaries without DWARF information can be significantly smaller. Here’s our example:
| 4.5 MiB | debug-63372dbe-41e6-447d-9c2e-e37b98e4c656.wasm |
|---|---|
| 313 KiB | build/worker/index.wasm |
Final words
We hope you enjoyed reading this blog as much as we did writing it and that it can help you take your Wasm debugging journeys, using Cloudflare Workers or not, to another level.
Note that while the examples used here were around using Rust and WebAssembly because that's a common pattern, you can use the same techniques if you're compiling WebAssembly from other languages like C or C++.
Also, note that the WebAssembly core dump standard is a hot topic, and its implementations and adoption are evolving quickly. We will continue improving the wasm-coredump-rewriter, debuginfo-split, and wasmgdb tools and the wasm-coredump service. More and more runtimes, including V8, will eventually support core dumps natively, thus eliminating the need to use polyfills, and the tooling, in general, will get better; that's a certainty. For now, we present you with a solution that works today, and we have strong incentives to keep supporting it.
As usual, you can talk to us on our Developers Discord or the Community forum or open issues or PRs in our GitHub repositories; the team will be listening.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.