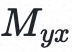
《Self-Alignment with Instruction Backtranslation》论文学习 - 郑瀚Andrew
2023-8-29 08:50:0 Author: www.cnblogs.com(查看原文) 阅读量:25 收藏
2023-8-29 08:50:0 Author: www.cnblogs.com(查看原文) 阅读量:25 收藏
$ bash data/seed/download.sh $ python data/seed/convert.py # #data: 3286, #dump: 3200 # Instruction len: 149±266, Response len: 1184±799
Since ClueWeb22 is not a free open-source dataset, we sample texts from falcon-refinedweb instead.
$ python data/unlabelled/falcon_refinedweb.py
# The first Myx training takes about 30min (on the seed data)
$ bash scripts/train_backward_Myx.sh
# Taking about 6:40:45 on the unlabelled data with 8*A100 $ bash scripts/self_aug.sh
Hyper parameters are the same as ![]() .
.
bash scripts/train_seed.sh
# 33:54:45 with 8*A100 on 482,963 samples $ bash scripts/self_curation.sh # scores: [('None', 217203), ('4', 119211), ('3', 102756), ('5', 21301), ('1', 13083), ('2', 9288), ('8', 19), ('0', 15), ('9', 14), ('7', 11), ('6', 9), ('10', 4), ('91', 3), ('83', 2), ('20', 2), ('14', 2), ('75', 2), ('92', 2), ('72', 1), ('93', 1), ('28', 1), ('19', 1), ('728', 1), ('17', 1), ('16', 1), ('100', 1), ('237', 1), ('13', 1), ('73', 1), ('38', 1), ('87', 1), ('94', 1), ('98', 1), ('64', 1), ('52', 1), ('27', 1), ('24', 1), ('762', 1), ('266', 1), ('225', 1), ('80', 1), ('267', 1), ('99', 1), ('90', 1), ('63', 1), ('97', 1), ('78', 1), ('40', 1), ('1986', 1), ('47', 1), ('66', 1), ('45', 1), ('10502', 1), ('21', 1)] # Number of qualified results (scores=5): 21301/482963 # instruction len: 198 ± 351 # response len: 1601 ± 345 # --------------------------------------- # v2: (Strict Curation Score Matching: add `$` to the matching regex): # Scores: [('None', 322324), ('3', 71851), ('4', 53120), ('5', 16460), ('1', 11921), ('2', 7260), ('0', 10), ('7', 4), ('6', 3), ('19', 1), ('8', 1), ('16', 1), ('13', 1), ('10', 1), ('23', 1), ('9', 1), ('90', 1), ('92', 1), ('45', 1)] # Number of qualified results (scores=5): 15521/482963 # instruction len: 124 ± 113 # response len: 1611 ± 345 # --------------------------------------- $ cat outputs/m1/unlabelled_curated_data.jsonl data/seed/seed.jsonl > data/curated/m1.jsonl
Most hyper parameters are the same as ![]() except for the number of steps (the original Humback trains 1600 steps on 512k samples).
except for the number of steps (the original Humback trains 1600 steps on 512k samples).
# change the `--data_path` in `scripts/train_seed.sh` $ bash scripts/train_seed.sh
文章来源: https://www.cnblogs.com/LittleHann/p/17661434.html
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh