1 前言
数据压缩技术[1]因可有效降低数据存储及传输成本,在计算机领域有非常广泛的应用(包括网络传输、文件传输、数据库、操作系统等场景)。主流压缩技术按其原理可划分为无损压缩[2]、有损压缩[3]两类,工作中我们最常用的压缩工具 zip 和 gzip ,压缩函数库 zlib,都是无损压缩技术的应用。Java 应用中对压缩库的使用包括:处理 HTTP 请求时对 body 的压缩/解压缩操作、使用消息队列服务时对大消息体(如>1M)的压缩/解压缩、数据库写入前及读取后对大字段的压缩/解压缩操作等。常见于监控、广告等涉及大数据传输/存储的业务场景。
美团基础研发平台曾经开发过一种基于 Intel 的 isa-l 库优化的 gzip 压缩工具及 zlib[4] 压缩库(又称:mzlib[5] 库),优化后的压缩速度可提升 10 倍,解压缩速度能提升 2 倍,并已在镜像分发、图片处理等场景长期稳定使用。遗憾的是,受限于 JDK[6] 对压缩库调用的底层设计,公司 Java8 服务一直无法使用优化后的 mzlib 库,也无法享受压缩/解压缩速率提升带来的收益。为了充分发挥 mzlib 的性能优势为业务赋能,在 MJDK 的最新版本中,我们改造并集成了 mzlib 库,完成了JDK中 java.util.zip.* 原生类库的优化,可实现在保障 API 及压缩格式兼容性的前提下,将内存数据压缩速率提升 5-10 倍的效果。本文主要介绍该特性的技术原理,希望相关的经验给大家带来一些启发或者帮助。
2 数据压缩技术
计算机领域的数据压缩技术的发展大致可分为以下三个阶段:

详细时间节点如下:
- 20世纪50~80年代,香农创立信息论,为数据压缩技术奠定了理论基础。期间出现多种经典算法,如 Huffman 编码、LZ 系列编码等。
- 1989年,Phil Katz推出文件归档软件 PKZIP(zip 前身),并公开文件归档格式 zip 及其使用的数据压缩算法 deflate(Huffman 与 LZ77 的组合算法)的所有技术参数。
- 1990年,Info-ZIP 小组基于公开的 deflate 算法编写了可移植的、免费的、开源实现 zip 和 unzip,极大地扩展了 .zip 格式的使用。
- 1992年,Info-ZIP 小组基于 zip 的 deflate 算法代码,推出了文件压缩工具 gzip(GUN zip),用于替代 Unix 下的 compress(有专利纠纷)。通常 gzip 会与归档工具 tar 结合使用来生成压缩的归档格式,文件扩展名为 .tar.gz。
- 1995年,Info-ZIP 小组成员Jean-loup Gailly 和 Mark Adler 基于 gzip 源码中的 deflate 算法实现,推出了压缩库:zlib 。通过库函数调用的方式,为其他场景(如PNG压缩)提供通用的压缩/解压缩能力。同年,在 RFC 中发布了 DEFLATE、ZLIB、GZIP 三种数据压缩格式。其中 DEFLATE 是原始压缩数据流格式,ZLIB、GZIP 则是在前者的基础上包装数据头及校验逻辑等。此后随着 zip、gzip 工具及 zlib 库的广泛应用,DEFLATE 成为互联网时代数据压缩格式的事实标准。
- 2010年后,各大型互联网公司陆续开源了新的压缩算法及实现,如:LZFSE(Apple)、Brotli(Google)、Zstandard(Facebook)等,在压缩速度和压缩比方面均有不同程度的提升。常见的压缩库如下(需要注意的是:由于压缩算法协议的差异,这些函数库不能交叉使用,数据压缩/解压缩必须使用同一种算法操作):

3 压缩技术在 Java 中的应用及优化思路
前面我们介绍了压缩技术的基础知识,本章节主要介绍 MJDK8_mzlib 版本实现压缩速率 5 倍提升的技术原理。分两部分进行阐述:第一部分,介绍原生 JDK 中压缩/解压缩 API 的底层原理;第二部分,分享 MJDK 的优化思路。
3.1 Java 语言中压缩/解压缩 API 实现原理
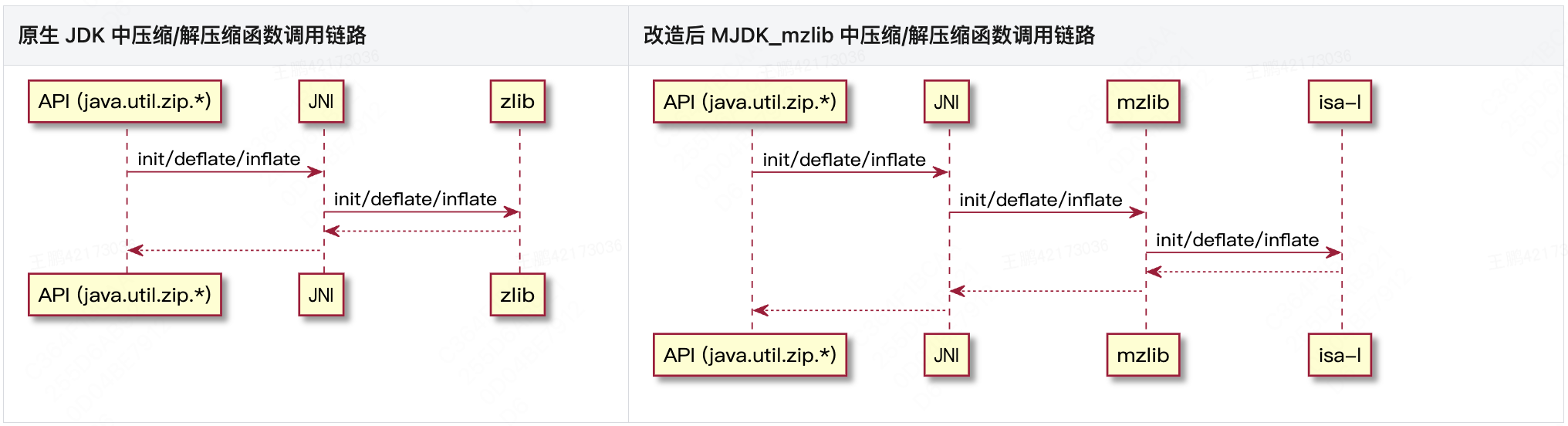
Java 语言中,我们可以使用 JDK 原生压缩类库(java.util.zip.*)或第三方 Jar 包提供的压缩类库两种方式来实现数据压缩/解压缩,其底层原理是通过 JNI (Java Native Interface) 机制,调用 JDK 源码或第三方 Jar 包中提供的共享库函数。详细对比如下:

其中在使用方式上,两者区别可参考如下代码。
(1)JDK 原生压缩类库(zlib 压缩库)
zip 文件压缩/解压缩代码 demo(Java)
public class ZipUtil {
//压缩
public void compress(File file, File zipFile) {
byte[] buffer = new byte[1024];
try {
InputStream input = new FileInputStream(file);
ZipOutputStream zipOut = new ZipOutputStream(new FileOutputStream(zipFile));
zipOut.putNextEntry(new ZipEntry(file.getName()));
int length = 0;
while ((length = input.read(buffer)) != -1) {
zipOut.write(buffer, 0, length);
}
input.close();
zipOut.close();
} catch (Exception e) {
e.printStackTrace();
}
}
//解压缩
public void uncompress(File file, File outFile) {
byte[] buffer = new byte[1024];
try {
ZipInputStream input = new ZipInputStream(new FileInputStream(file));
OutputStream output = new FileOutputStream(outFile);
if (!outFile.getParentFile().exists()) {
outFile.getParentFile().mkdir();
}
if (!outFile.exists()) {
outFile.createNewFile();
}
int length = 0;
while ((length = input.read(buffer)) != -1) {
output.write(buffer, 0, length);
}
input.close();
output.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
gzip 文件压缩/解压缩代码 demo(Java)
public class GZipUtil {
public void compress(File file, File outFile) {
byte[] buffer = new byte[1024];
try {
InputStream input = new FileInputStream(file);
GZIPOutputStream gzip = new GZIPOutputStream(new FileOutputStream(outFile));
int length = 0;
while ((length = input.read(buffer)) != -1) {
gzip.write(buffer, 0, length);
}
input.close();
gzip.finish();
gzip.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public void uncompress(File file, File outFile) {
try {
FileOutputStream out = new FileOutputStream(outFile);
GZIPInputStream ungzip = new GZIPInputStream(new FileInputStream(file));
byte[] buffer = new byte[1024];
int n;
while ((n = ungzip.read(buffer)) > 0) {
out.write(buffer, 0, n);
}
ungzip.close();
out.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
(2)第三方压缩类库(此处以Google推出的snappy压缩库举例,其他第三方类库原理基本类似)分成两步。
第一步:pom文件中添加依赖Jar包(C语言)
<dependency>
<groupId>org.xerial.snappy</groupId>
<artifactId>snappy-java</artifactId>
<version>1.1.8.4</version>
</dependency>
第二步:第二步,调用接口进行压缩/解压缩操作(C语言)
public class SnappyDemo {
public static void main(String[] args) {
String input = "Hello snappy-java! Snappy-java is a JNI-based wrapper of "
+ "Snappy, a fast compresser/decompresser.";
byte[] compressed = new byte[0];
try {
compressed = Snappy.compress(input.getBytes("UTF-8"));
byte[] uncompressed = Snappy.uncompress(compressed);
String result = new String(uncompressed, "UTF-8");
System.out.println(result);
} catch (IOException e) {
e.printStackTrace();
}
}
综上所述,JDK 中默认使用的压缩库是 zlib,虽然业务可以通过第三方 Jar 包的方式使用其他的压缩库算法,但是因为 Snappy 等算法的压缩数据格式与 zlib 支持的 DEFLATE、ZLIB、GZIP 不同,混合使用会有兼容性问题。
除此之外, zlib 库(1995年推出)本身的迭代速度非常缓慢(原因:应用范围广且稳定、无商业组织维护),这里使用测试集 Silesia corpus 测试了 OpenJDK 7u76(2014 年发行)、8u45(2015 年发行)、8u312(2022 年发行)中内置压缩类库的性能,从图表中可看出,三者在压缩耗时、压缩比两方面均未有明显的优化效果,难以满足业务日益增长的压缩性能需求场景。因此,我们选择在 MJDK 中集成 zlib 优化,实现既兼容原生接口实现,又能提升压缩性能的效果。
Silesia corpus是压缩方法性能基准测试集,提供一套涵盖现时使用的典型资料类别的档案资料。文件的大小在6 MB 到51 MB 之间,文件格式包括 text、exe、html、picture、database、bin data 等。测试数据类别如下:



3.2 MJDK 优化方案
通过 3.1 章节,我们知道 Java 原生的 java.util.zip.* 类库中的数据压缩/解压缩能力最终是调用 zlib 库实现的,因此 JDK 的压缩性能提升问题就可转换为对 JDK 使用的 zlib 库的优化。
3.2.1 优化思路
除原生 zlib 外,同样使用 deflate 算法的压缩库有Intel ISA-L、Intel IPP、Zopfli,直接基于 zlib 源码优化的项目有 zlib-cloudflare,它们与 zlib 间的对比如下:

综上,我们选择基于 Intel 开源的 ISA-L(原理是使用 intel sse/avx/avx2/avx256 的扩展指令,并行运算多个流来提升底层函数的执行性能) 来完成 zlib 的改造优化。
1. zlib 改造流程(重点在 API 的兼容性改造)

优化后的 mzlib 库在线上稳定运行 3 年以上,压缩速率提升在 5 倍以上,有效解决了上文提到基础研发平台曾在镜像构建、图片处理等场景面临过压缩/解压缩耗时较高的问题。
2. JDK 层面变更

3.2.2 优化效果
测试说明
- 测试集:Silesia corpus
- 测试内容:GZip 压缩/解压缩文件、Zip 压缩/解压缩文件
测试结论
- 兼容性测试(通过):改造后的 Java 类库的 Zip、Gzip 压缩/解压缩接口可正常使用,与原生 JDK 中的接口交叉进行压缩/解压缩操作验证通过。
- 性能测试(通过):在同一基准 update 版本下,MJDK8_mzlib 数据压缩耗时比 OpenJDK8 降低 5-10 倍,压缩比无较大波动(增加 3% 左右)。


目前,美团内部的文档协同服务已使用该 MJDK 版本,进行用户协同编辑记录数据(> 6M)的压缩存储,验证了该功能在线上的稳定运行,压缩性能提升在 5 倍以上。
4 本文作者
艳梅,来自美团基础研发平台。
5 参考文献
- [1] Comparison of Brotli, Deflate, Zopfli, LZMA, LZHAM and Bzip2 Compression Algorithms
- [2] zip、gzip、zlib的区别
注释
- [1] 数据压缩技术:在不丢失有用信息的前提下,通过相应的算法缩减信源数据冗余,从而提高数据存储、传输和处理效率的技术。
- [2] 无损压缩:利用数据的统计冗余进行压缩,常见的无损压缩编码方法有 Huffman编码,算术编码,LZ 编码(字典压缩)等。数据统计冗余度的理论限制为2:1到5:1,所以无损压缩的压缩比一般比较低。这类方法广泛应用于文本数据、程序等需要精确存储数据的压缩,
- [3] 有损压缩:利用了人类视觉、听觉对图像、声音中的某些频率成分不敏感的特性,允许压缩的过程中损失一定的信息,以此换来更大的压缩比。广泛应用于语音、图像和视频数据的压缩。 -[4] zlib:zlib 是基于 DEFLATE 算法实现的,一套完全开源、通用的无损数据压缩库。也是目前应用最广泛的压缩库。在网络传输、操作系统、图像处理等领域均有大量使用。比如:
- [5] mzlib:美团基于 Intel 的 isa-l 库优化的 zlib 压缩库。
- [6] JDK:Java Development Kit,是 Sun 公司针对Java开发人员发布的免费软件开发工具包,是 Java 开发的核心组件之一,包含了 Java 编译器、Java 虚拟机、Java 类库等开发工具和资源。
- [7] JNI (Java Native Interface) :JNI是一个本地编程接口。它允许在 Java 虚拟机中运行的 Java 代码与用其他编程语言(如 C、C++ 和汇编)编写的应用程序和库进行互操作。
如有侵权请联系:admin#unsafe.sh