2023-9-8 14:3:0 Author: www.cnblogs.com(查看原文) 阅读量:16 收藏
传统上,从零开始构建一个自然语言处理(NLP)模型是一项重大任务。一个寻求解决新问题的NLP从业者需要定义他们的任务范围,找到或创建目标任务领域的行为数据,选择合适的模型架构,训练模型,通过评估评估其性能,然后将其部署到实际应用中。

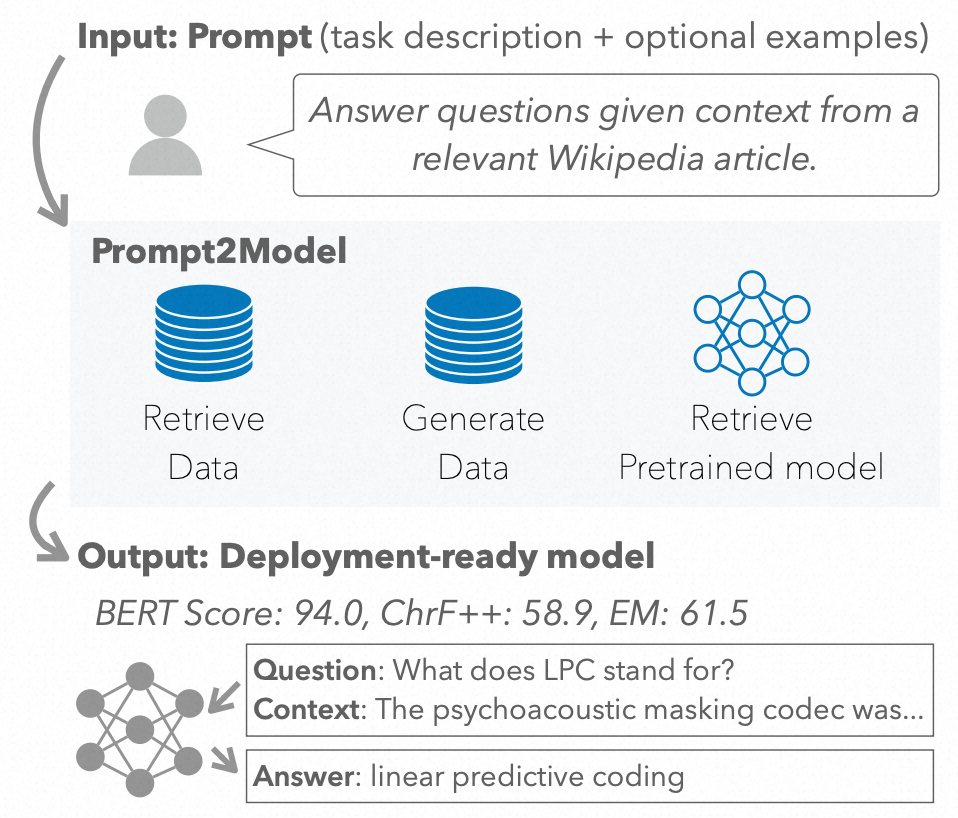
Prompt2Model is a framework for generating a small yet accurate model from a prompt.
类似于GPT-3的语言生成模型(LLM)提供了一种通过“prompt提示”实现的轻量级的自然语言处理系统构建范式。从业者现在可以编写一个prompt提示,指定预期的系统行为(可以选择性地提供一些演示),然后要求LLM通过text completion生成所需的输出。这使得开发者可以快速地为各种应用开发自然语言处理系统的原型,而无需编写任何代码。
然而,需要指出的是,目前仍存在着概念验证原型和实际部署之间的差距。
- 一方面,使用LLM进行提示可能很昂贵,因为它们要么需要大量的计算资源,要么需要访问商业API,并且它们对输入提示质量的依赖使其与经过训练的微调模型相比不稳定。因为从业者通常没有足够的验证数据来衡量系统的性能,所以在部署之前调试系统也更具挑战性。
- 此外,通过LLM进行提示的系统还存在使用上的挑战。从业者对使用LLM的高成本和较慢的预测时间表示关注,而在高风险领域工作的人员由于隐私问题不能依赖商业LLM API。例如,在美国,将用户数据与LLM服务提供商共享对于许多应用是非法的。
在这项工作中,我们提出了Prompt2Model,这是一个系统,它通过提示保留了以轻量级方式指定系统行为的能力,同时产生一个可部署的特定目标模型,保持了微调模型的所有优势。Prompt2Model被设计为一个自动化流水线,通过三个渠道提取用户提示中的关键任务信息,然后自动收集和综合任务特定的知识:
- 数据集检索:在可能的情况下,我们通过检索与任务相关的标注数据来收集训练数据。
- 数据集生成:我们利用一个LLM(“教师模型”)提取知识,通过使用它来生成一个伪标记数据集。之前的工作已经证明,这样的数据集可以用来训练一个较小的“学生”模型,以模拟教师模型的行为。
- 模型检索:根据提示,我们确定一个预训练的语言模型,其参数化知识适用于用户的意图。这个选择的模型作为学生模型,并利用生成和检索的数据进行进一步的微调和评估。
Prompt2Model被设计为支持每个组件的可插拔替换。
我们提供一个参考实现,其中展示了它与基于gpt-3.5-turbo的数据集生成器、基于DataFinder的数据集检索器以及使用BM25的模型检索器的实用性。我们对三个任务进行评估,涵盖传统的自然语言处理基准测试和新颖的应用,发现Prompt2Model在某些情况下生成的小模型在使用相同的提示作为输入时优于gpt-3.5-turbo。在这3个任务中的2个中,我们观察到与gpt-3.5-turbo基准相比的改进幅度超过20个点,尽管Prompt2Model生成的最终模型体积最多只有gpt-3.5-turbo的700倍小。我们还发现我们可以生成有效的评估数据集。
我们相信Prompt2Model可以为社区提供以下用途:
- 快速构建小型高效的自然语言处理系统的工具:Prompt2Model可以直接用于在几小时内生成优于LLMs的特定任务模型,而无需进行任何手动数据标注或架构设计。该方法填补了概念验证LLM原型和模型的实际部署之间的差距。
- 基于提示的端到端模型训练的测试平台:鉴于Prompt2Model的可扩展设计,它可以提供一个平台,用于探索模型蒸馏、数据集生成、合成评估、数据集检索和模型检索等新技术。我们的平台允许使用外在的下游度量标准研究这些组件,从而在这些研究领域取得经验上的进展。
参考链接:
https://arxiv.org/pdf/2308.12261.pdf
我们的系统Prompt2Model提供了一个自动化的机器学习流程平台:数据收集、模型训练、评估和部署。
我们在下图中展示了我们的自动化流程。

The Prompt2Model architecture seeks to automate the core machine learning development pipeline, allowing us to train a small yet accurate model from just a prompt.
核心是我们的自动化数据收集系统,它利用数据集检索和基于LLM的数据集生成来获取与用户需求相关的标记数据。
然后,我们检索预训练模型,并对收集到的数据集的训练集进行微调。
最后,我们在相同的数据集的测试集上评估我们训练过的模型,并可选择创建一个可以与模型交互的Web用户界面。
我们通用的方法设计成模块化和可扩展的,每个组件可以由从业者以不同方式实现或禁用。
0x1:Prompt Parser
作为我们系统的主要输入,用户提供LLMs的prompt提示。这些提示包括一条指令和可选的几个预期行为的演示。
虽然这种开放式的界面对用户来说很方便,但端到端的机器学习流水线强依赖于一个处理这种输入的提示解析器,例如将提示分割成指令和单个演示,或将指令翻译成英文。
我们将提示解析为指令和示范字段,其中,
- 指令代表主要任务或目标
- 示范展示所需行为
为了实现这一点,我们利用具有上下文学习的LLM来分割用户提示,在实验中使用OpenAI gpt-3.5-turbo-0613。如果提供的指令被确定为非英语语言,则使用DeepL API将其翻译成英语。
0x2:Dataset Retriever
给定一个prompt提示,我们首先尝试发现现有的人工标注数据,以支持用户的任务描述。
数据集检索器有几个设计决策:
- 搜索哪些数据集?
- 如何为搜索建立数据集索引?
- 用户任务需要哪些数据集列,哪些列应被忽略?
Färber和Leisinger以及Viswanathan等人的先前工作介绍了用于数据集搜索的系统。我们在我们的实现中使用了后者,称为DataFinder。
通过提取Hugging Face数据集中每个数据集的用户生成数据集描述,我们利用DataFinder训练的双编码检索器对数据集进行排序,以找出最相关的数据集。一旦确定了一个相关的数据集,下一步是确定数据集的哪些列对应于用户指定的输入和期望的输出。
由于自动识别任何数据集的正确模式可能具有挑战性,我们采用了人机协作的方法。我们向用户呈现默认情况下为k=25个的前k个数据集,并允许用户选择最相关的数据集,或者声明没有一个数据集适合其任务。然后,我们要求用户从数据集的模式中识别适当的输入和输出列。
0x3:Dataset Generator
并非所有任务都有现有的标注数据,许多任务仅与现有数据集存在弱相关。
为了支持各种任务,我们引入了一个数据集生成器,根据Prompt解析器解析的用户特定要求生成合成训练数据。这个组件面临成本效益、生成速度、示例多样性和质量控制方面的挑战。
我们精心设计了我们的数据集生成器,以实现速度优化的低成本生成,同时创建多样且高质量的示例。我们的策略包括以下组成部分。
1、高质量多样性的few-shot prompt(High-Diversity Few-Shot Prompting)
我们使用自动提示工程来生成多样化的数据集。我们将用户提供的演示示例与之前生成的示例的随机样本相结合,以促进多样性并避免生成重复的示例。如果没有这个策略,200个生成的问答示例中有120个是重复的;有了这个策略,只有25个是重复的。
2、温度退火策略(Temperature Annealing)
我们根据已生成示例的数量,按比例调整采样温度,从低(偏向确定性输出)调整到高(鼓励多样性探索)。
这种调节有助于保持输出质量,同时逐渐鼓励多样性。
3、自一致解码(Self-Consistency Decoding)
鉴于语言模型可能对相同的输入生成非唯一或不正确的输出,我们使用自一致性过滤来选择伪标签。
具体而言,我们通过选择最常见的答案为每个唯一输入创建一个共识输出,当出现常见答案之间的平局情况,我们启发式地选择最短的答案。这在确保唯一示例的同时提高了生成数据集的准确性。
4、异步批处理(Asynchronous Batching)
使用zeno-build,我们并行化API请求。我们使用额外的机制,如动态批处理大小和节流控制,来优化API的使用。
0x4:Model Retriever
除了训练数据之外,我们还必须确定一个适当的模型进行微调。
为了支持多个任务使用统一的模型接口,我们目前限制在Hugging Face的编码器-解码器架构上,这是根据最近的研究表明编码器-解码器模型在模型蒸馏中具有更高的数据效率。这个限制仍然有很多预训练模型可供选择,例如:
- 用于编码相关任务的Salesforce/codet5-base
- 用于阿拉伯语到英语翻译的MaryaAI/opus-mt-ar-en-finetuned-ar-to-en
我们把选择预训练模型的问题看作一个搜索问题。根据用户的指令作为查询,我们在Hugging Face的所有模型的文本描述中进行搜索。这个搜索任务具有挑战性,因为Hugging Face模型的描述往往很稀疏,包含很多模板化的文本,通常只有几个词表明模型的内容。
为了解决这个问题,我们采用HyDE框架,首先使用gpt-3.5-turbo根据用户的指令创建一个假设的模型描述。我们在下图中展示了一个针对问答指令生成的假设文档的示例。然后,我们将这个描述作为扩展查询,并应用BM25算法计算查询-模型的相似度得分。

For our model retriever, we first construct a hypothetical model description for a query, then compute similarity scores between that hypothetical model description and the descriptions of real models.
为了确保部署的便利性,我们过滤掉大小(以字节为单位)超过用户指定阈值的模型(默认设置为3GB)。根据高下载量的模型往往更具质量的直觉,我们通过以下排名选择顶级模型:
![]()
0x5:Training
基于已获取和生成的数据集以及预训练模型,我们使用一个模型训练器来在数据的子集上对模型进行微调。
目前,我们通过将所有任务视为文本到文本生成的方式来训练模型,但这个组件可以在未来扩展以支持新的方法。
1、Dataset Processing
我们通过利用两个数据集来训练模型,
- 一个是生成的数据集
- 一个是检索的数据集
为了避免领域特定建模的挑战(例如为分类或生成任务构建专门的架构),我们将所有数据集都视为“文本到文本”问题。我们将每个数据集的输入列文本化,并在输入之前添加用户的指令来指导模型。
2、Finetuning
我们将检索到的数据集和生成的数据集连接起来,并在训练学生模型之前对它们进行洗牌。我们为所有任务使用相同的默认超参数。我们使用AdamW优化器进行训练,lr = 5e-5,训练3个时期,大约需要一个小时完成所有任务。
0x6:Evaluation
在对检索到的和生成的数据集的部分进行模型训练后,我们将剩余的数据交给一个模型评估器模块。
我们的目标是支持各种任务,但是为任意任务选择正确的任务特定度量标准是一个困难的问题。
我们的模型评估器使用三个通用度量自动评估所有任务的模型:
- 精确匹配(Exact Match):精确匹配度量模型输出与参考答案完全匹配的频率。
- ChrF++:ChrF++平衡了精确度和召回率,用于评估文本生成质量。
- BERTScore:BERTScore通过比较模型输出和嵌入空间中的参考答案来捕捉语义相似性,尽管用词或短语不同。
我们使用XLM-R作为BERTScore的编码器,以支持多语言评估。
0x7:Web App Creation
为了使开发者能够向合作伙伴或用户展示模型,我们包含了一个可选的组件,称为Demo Creator,以创建一个可视化界面来与模型进行交互,这个基于Gradio构建的Web应用可以轻松地在服务器上公开部署。
我们提出了Prompt2Model框架,该框架仅使用自然语言提示自动生成任务特定模型。我们的概念验证实验证明,尽管使用了与LLMs相似的易于使用的界面,Prompt2Model仍然能够生成小型但准确的模型,并且其生成的数据集可以用于估计实际性能。除了我们提供的可直接使用的参考实现工具外,Prompt2Model的可扩展设计和模块化实现使其成为推进模型蒸馏、数据集生成、合成评估、数据集检索和模型检索的平台。
我们相信我们的Prompt2Model框架可以激发各种新颖的研究问题。我们希望我们的平台能够促使未来的工作更深入地研究生成数据和模型的质量保证。有趣的问题包括:
- 我们应该为下游模型训练生成多少数据以及它应该具有多大的多样性?
- 我们如何有效地混合检索和生成的数据集,以实现互补的优势(例如,使用数据集生成来专注于检索数据集未涵盖的模型预期输入)?
- 由于用户通常很难事先准确表达他们的需求,未来的扩展应该解决人在环路纠正的挑战 - 要么通过提供潜在策略来帮助人们迭代地完善提示,要么允许人们在任务元数据提取和生成数据与其意图不符合时进行事后修复。
我们希望提出明确的挑战,并邀请社区为我们的框架的各个组件提供新颖的实现。
我们系统的一个主要限制是,
- 我们目前的实验都是使用gpt-3.5-turbo API进行的(用于提示解析、数据集生成和模型检索)。这个LLM是付费闭源的,这使得它作为科学文物存在问题(Rogers等,2023年)
- 此外,这个LLM的服务提供商OpenAI禁止使用他们的API创建可能与OpenAI竞争的模型,这在商业应用中可能引起法律问题。我们正在探索集成开源LLM以避免对专有API的依赖。
我们工作的另一个局限性是
- Prompt2Model对处理英语以外的其他语言的任务的能力有限。虽然我们已经展示了我们的系统在从日语自然语言查询生成代码的支持方面的局限性,但我们的系统很可能在处理资源较少的语言时遇到更大的困难。在我们的参考实现中,我们使用了未公开的gpt-3.5-turbo模型作为我们的数据集生成器。该模型被认为与GPT-3相似,后者是在93%的英语文档、1%的德语文档、1%的法语文档和<5%的其他语言文档上进行训练的。
- 我们对这个模型的使用可能加剧高资源语言和低资源语言之间现有语言技术差距的存在。
还有一个潜在的局限性是
- 我们只在3个任务上测试了我们的方法,每个任务只有一个数据集和一个评估指标。我们之所以做出这个决定,是因为我们的重点是提供一个可扩展的软件系统,而不是在许多数据集上建立最先进的结果,但我们认为我们的结果表明具有更广泛的适用性。

"""An commend line demo to run the whole system.""" import json import logging import os import time from pathlib import Path import datasets import pyfiglet import torch import transformers import yaml from datasets import concatenate_datasets, load_from_disk from termcolor import colored from prompt2model.dataset_generator.base import DatasetSplit from prompt2model.dataset_generator.prompt_based import PromptBasedDatasetGenerator from prompt2model.dataset_processor.textualize import TextualizeProcessor from prompt2model.dataset_retriever import DescriptionDatasetRetriever from prompt2model.demo_creator import create_gradio from prompt2model.model_evaluator import Seq2SeqEvaluator from prompt2model.model_executor import GenerationModelExecutor from prompt2model.model_retriever import DescriptionModelRetriever from prompt2model.model_trainer.generate import GenerationModelTrainer from prompt2model.prompt_parser import ( MockPromptSpec, PromptBasedInstructionParser, TaskType, ) from prompt2model.utils.logging_utils import get_formatted_logger def line_print(input_str: str) -> None: """Print the given input string surrounded by horizontal lines. Args: input_str: The string to be printed. """ print(f"{input_str}") def print_logo(): """Print the logo of Prompt2Model.""" figlet = pyfiglet.Figlet(width=200) # Create ASCII art for each word and split into lines words = ["Prompt", "2", "Model"] colors = ["red", "green", "blue"] ascii_art_parts = [figlet.renderText(word).split("\n") for word in words] # Calculate the maximum height among the words max_height = max(len(part) for part in ascii_art_parts) # Equalize the height by adding empty lines at the bottom for part in ascii_art_parts: while len(part) < max_height: part.append("") # Zip the lines together, color them, and join them with a space ascii_art_lines = [] for lines in zip(*ascii_art_parts): colored_line = " ".join( colored(line, color) for line, color in zip(lines, colors) ) ascii_art_lines.append(colored_line) # Join the lines together to get the ASCII art ascii_art = "\n".join(ascii_art_lines) # Get the width of the terminal term_width = os.get_terminal_size().columns # Center the ASCII art centered_ascii_art = "\n".join( line.center(term_width) for line in ascii_art.split("\n") ) line_print(centered_ascii_art) def main(): """The main function running the whole system.""" print_logo() # Save the status of Prompt2Model for this session, # in case the user wishes to stop and continue later. if os.path.isfile("status.yaml"): with open("status.yaml", "r") as f: status = yaml.safe_load(f) else: status = {} while True: line_print("Do you want to start from scratch? (y/n)") answer = input() if answer.lower() == "n": if os.path.isfile("status.yaml"): with open("status.yaml", "r") as f: status = yaml.safe_load(f) print(f"Current status:\n{json.dumps(status, indent=4)}") break else: status = {} break elif answer.lower() == "y": status = {} break else: continue propmt_has_been_parsed = status.get("prompt_has_been_parsed", False) dataset_has_been_retrieved = status.get("dataset_has_been_retrieved", False) model_has_been_retrieved = status.get("model_has_been_retrieved", False) dataset_has_been_generated = status.get("dataset_has_been_generated", False) model_has_been_trained = status.get("model_has_been_trained", False) if not propmt_has_been_parsed: prompt = "" line_print( "Enter your task description and few-shot examples (or 'done' to finish):" ) time.sleep(2) while True: line = input() if line == "done": break prompt += line + "\n" line_print("Parsing prompt...") prompt_spec = PromptBasedInstructionParser(task_type=TaskType.TEXT_GENERATION) prompt_spec.parse_from_prompt(prompt) propmt_has_been_parsed = True status["instruction"] = prompt_spec.instruction status["examples"] = prompt_spec.examples status["prompt_has_been_parsed"] = True with open("status.yaml", "w") as f: yaml.safe_dump(status, f) line_print("Prompt parsed.") if propmt_has_been_parsed and not dataset_has_been_retrieved: prompt_spec = MockPromptSpec( TaskType.TEXT_GENERATION, status["instruction"], status["examples"] ) line_print("Retrieving dataset...") retriever = DescriptionDatasetRetriever() retrieved_dataset_dict = retriever.retrieve_dataset_dict(prompt_spec) dataset_has_been_retrieved = True if retrieved_dataset_dict is not None: retrieved_dataset_dict.save_to_disk("retrieved_dataset_dict") status["retrieved_dataset_dict_root"] = "retrieved_dataset_dict" else: status["retrieved_dataset_dict_root"] = None status["dataset_has_been_retrieved"] = True with open("status.yaml", "w") as f: yaml.safe_dump(status, f) if ( propmt_has_been_parsed and dataset_has_been_retrieved and not model_has_been_retrieved ): line_print("Retrieving model...") prompt_spec = MockPromptSpec( TaskType.TEXT_GENERATION, status["instruction"], status["examples"] ) retriever = DescriptionModelRetriever( model_descriptions_index_path="huggingface_data/huggingface_models/model_info/", # noqa E501 use_bm25=True, use_HyDE=True, ) top_model_name = retriever.retrieve(prompt_spec) line_print("Here are the models we retrieved.") for idx, each in enumerate(top_model_name): line_print(f"# {idx + 1}: {each}") while True: line_print( "Enter the number of the model you want to use. Range from 1 to 5." ) line = input() try: rank = int(line) assert 1 <= rank <= 5 break except Exception: line_print("Invalid input. Please enter a number.") model_has_been_retrieved = True status["model_has_been_retrieved"] = True status["model_name"] = top_model_name[rank - 1] with open("status.yaml", "w") as f: yaml.safe_dump(status, f) if ( propmt_has_been_parsed and dataset_has_been_retrieved and model_has_been_retrieved and not dataset_has_been_generated ): prompt_spec = MockPromptSpec( TaskType.TEXT_GENERATION, status["instruction"], status["examples"] ) generator_logger = get_formatted_logger("DatasetGenerator") generator_logger.setLevel(logging.INFO) line_print("The dataset generation has not finished.") time.sleep(2) line_print(f"Your input instruction:\n\n{prompt_spec.instruction}") time.sleep(2) line_print(f"Your input few-shot examples:\n\n{prompt_spec.examples}") time.sleep(2) while True: line_print("Enter the number of examples you wish to generate:") line = input() try: num_expected = int(line) break except ValueError: line_print("Invalid input. Please enter a number.") while True: line_print("Enter the initial temperature:") line = input() try: initial_temperature = float(line) assert 0 <= initial_temperature <= 2.0 break except Exception: line_print( "Invalid initial temperature. Please enter a number (float) between 0 and 2." # noqa E501 ) while True: line_print("Enter the max temperature (we suggest 1.4):") line = input() try: max_temperature = float(line) assert 0 <= max_temperature <= 2.0 break except Exception: line_print( "Invalid max temperature. Please enter a float between 0 and 2." ) line_print("Starting to generate dataset. This may take a while...") time.sleep(2) unlimited_dataset_generator = PromptBasedDatasetGenerator( initial_temperature=initial_temperature, max_temperature=max_temperature, responses_per_request=3, ) generated_dataset = unlimited_dataset_generator.generate_dataset_split( prompt_spec, num_expected, split=DatasetSplit.TRAIN ) generated_dataset.save_to_disk("generated_dataset") dataset_has_been_generated = True status["dataset_has_been_generated"] = True with open("status.yaml", "w") as f: yaml.safe_dump(status, f) line_print("The generated dataset is ready.") time.sleep(2) if ( propmt_has_been_parsed and dataset_has_been_retrieved and model_has_been_retrieved and dataset_has_been_generated and not model_has_been_trained ): line_print("The model has not been trained.") time.sleep(2) dataset_root = Path("generated_dataset") if not dataset_root.exists(): raise ValueError("Dataset has not been generated yet.") trained_model_root = Path("result/trained_model") trained_tokenizer_root = Path("result/trained_tokenizer") RESULT_PATH = Path("result/result") trained_model_root.mkdir(parents=True, exist_ok=True) trained_tokenizer_root.mkdir(parents=True, exist_ok=True) RESULT_PATH.mkdir(parents=True, exist_ok=True) dataset = load_from_disk(dataset_root) if status["retrieved_dataset_dict_root"] is not None: cached_retrieved_dataset_dict = datasets.load_from_disk( status["retrieved_dataset_dict_root"] ) dataset_list = [dataset, cached_retrieved_dataset_dict["train"]] else: dataset_list = [dataset] line_print("Processing datasets.") instruction = status["instruction"] t5_processor = TextualizeProcessor(has_encoder=True) t5_modified_dataset_dicts = t5_processor.process_dataset_lists( instruction, dataset_list, train_proportion=0.6, val_proportion=0.2, maximum_example_num=3000, ) processor_logger = get_formatted_logger("DatasetProcessor") processor_logger.setLevel(logging.INFO) training_datasets = [] validation_datasets = [] test_datasets = [] for idx, modified_dataset_dict in enumerate(t5_modified_dataset_dicts): training_datasets.append(modified_dataset_dict["train"]) validation_datasets.append(modified_dataset_dict["val"]) test_datasets.append(modified_dataset_dict["test"]) trainer_logger = get_formatted_logger("ModelTrainer") trainer_logger.setLevel(logging.INFO) evaluator_logger = get_formatted_logger("ModelEvaluator") evaluator_logger.setLevel(logging.INFO) while True: line = input("Enter the training batch size:") try: train_batch_size = int(line) assert 0 < train_batch_size break except Exception: line_print("The training batch size must be greater than 0.") time.sleep(1) while True: line = input("Enter the number of epochs to train for:") try: num_epochs = int(line) break except ValueError: line_print("Invalid input. Please enter a number.") time.sleep(1) trainer = GenerationModelTrainer( status["model_name"], has_encoder=True, executor_batch_size=train_batch_size, tokenizer_max_length=1024, sequence_max_length=1280, ) args_output_root = Path("result/training_output") args_output_root.mkdir(parents=True, exist_ok=True) line_print("Starting training.") trained_model, trained_tokenizer = trainer.train_model( hyperparameter_choices={ "output_dir": str(args_output_root), "save_strategy": "epoch", "num_train_epochs": num_epochs, "per_device_train_batch_size": train_batch_size, "evaluation_strategy": "epoch", }, training_datasets=training_datasets, validation_datasets=validation_datasets, ) trained_model.save_pretrained(trained_model_root) trained_tokenizer.save_pretrained(trained_tokenizer_root) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") trained_model = transformers.AutoModelForSeq2SeqLM.from_pretrained( trained_model_root ).to(device) trained_tokenizer = transformers.AutoTokenizer.from_pretrained( trained_tokenizer_root ) line_print("Finished training. Now evaluating on the test set.") test_dataset = concatenate_datasets(test_datasets) model_executor = GenerationModelExecutor( trained_model, trained_tokenizer, train_batch_size, tokenizer_max_length=1024, sequence_max_length=1280, ) t5_outputs = model_executor.make_prediction( test_set=test_dataset, input_column="model_input" ) evaluator = Seq2SeqEvaluator() metric_values = evaluator.evaluate_model( test_dataset, "model_output", t5_outputs, encoder_model_name="xlm-roberta-base", ) line_print(metric_values) with open(RESULT_PATH / "metric.txt", "w") as result_file: for metric_name, metric_value in metric_values.items(): result_file.write(f"{metric_name}: {metric_value}\n") status["model_has_been_trained"] = model_has_been_trained = True status["trained_model_root"] = str(trained_model_root) status["trained_tokenizer_root"] = str(trained_tokenizer_root) with open("status.yaml", "w") as f: yaml.safe_dump(status, f) line_print("Model has been trained and evaluated.") t5_model = transformers.AutoModelForSeq2SeqLM.from_pretrained( status["trained_model_root"] ).to(torch.device("cuda" if torch.cuda.is_available() else "cpu")) t5_tokenizer = transformers.AutoTokenizer.from_pretrained( status["trained_tokenizer_root"] ) model_executor = GenerationModelExecutor( t5_model, t5_tokenizer, 1, tokenizer_max_length=1024, sequence_max_length=1280 ) prompt_spec = MockPromptSpec( TaskType.TEXT_GENERATION, status["instruction"], status["examples"] ) interface_t5 = create_gradio(model_executor, prompt_spec) interface_t5.launch(share=True) if __name__ == "__main__": main()
View Code
参考链接:
https://colab.research.google.com/github/neulab/prompt2model/blob/main/prompt2model_demo.ipynb https://github.com/neulab/prompt2model
如有侵权请联系:admin#unsafe.sh