2023-9-16 08:0:0 Author: arthurchiao.github.io(查看原文) 阅读量:78 收藏
Published at 2023-09-16 | Last Update 2023-09-16
记录一些平时接触到的 GPU 知识。由于是笔记而非教程,因此内容不会追求连贯,有基础的同学可作查漏补缺之用。
水平有限,文中不免有错误之处,请酌情参考。
大模型训练一般都是用单机 8 卡 GPU 主机组成集群,机型包括 8*{A100,A800,H100,H800}
可能还会用最近即将上市的 {4,8}*L40S 等。
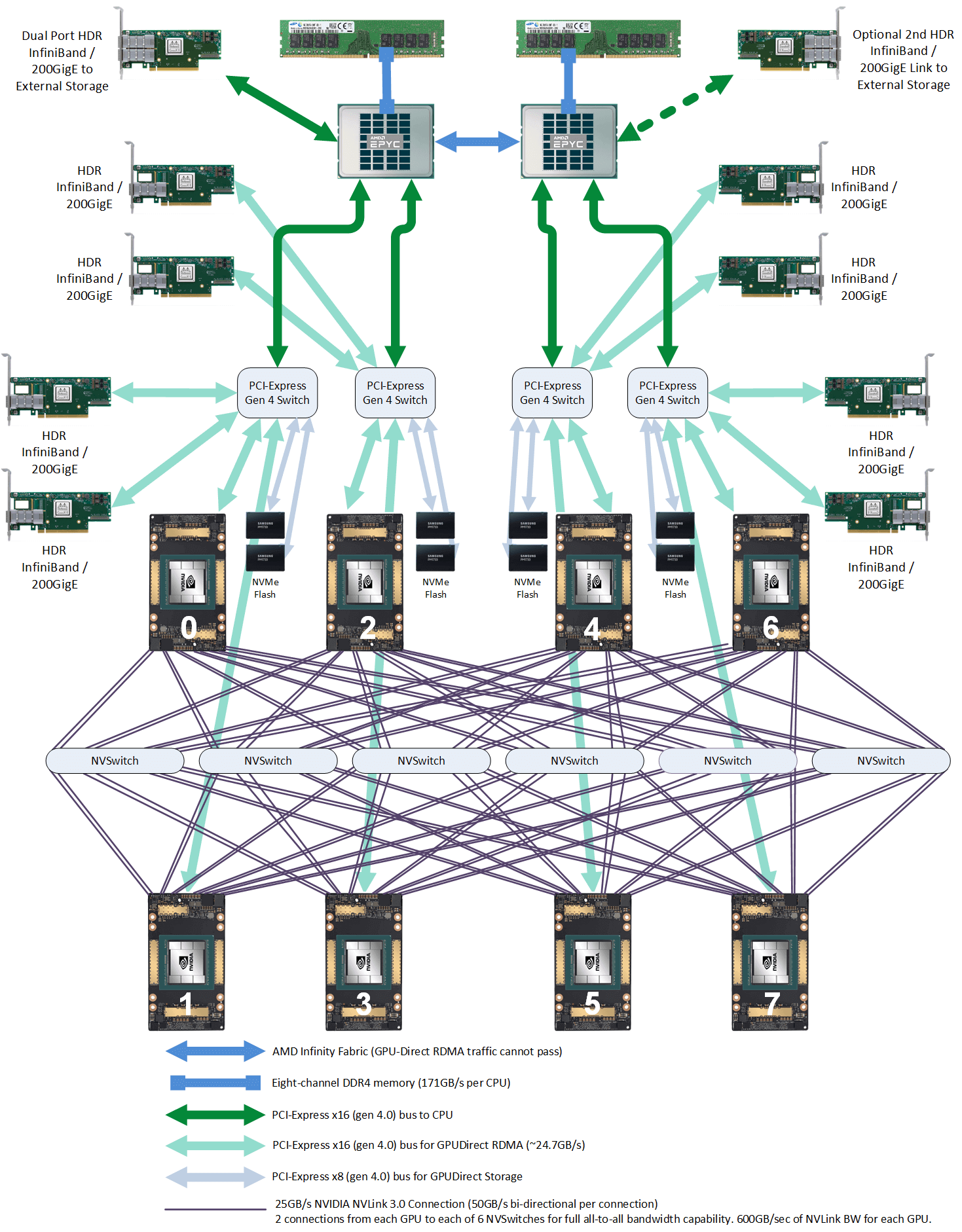
下面一台典型 8*A100 GPU 的主机内硬件拓扑:
典型 8 卡 A100 主机硬件拓扑
本节将基于这张图来介绍一些概念和术语,有基础的可直接跳过。
1.1 PCIe 交换芯片
CPU、内存、存储(NVME)、GPU、网卡等支持 PICe 的设备,都可以连接到 PCIe 总线或专门的 PCIe 交换芯片,实现互联互通。
PCIe 目前有 5 代产品,最新的是 Gen5。
1.2 NVLink
定义
Wikipedia 上 NVLink 上的定义:
NVLink is a wire-based serial multi-lane near-range communications link developed by Nvidia. Unlike PCI Express, a device can consist of multiple NVLinks, and devices use mesh networking to communicate instead of a central hub. The protocol was first announced in March 2014 and uses a proprietary high-speed signaling interconnect (NVHS).
简单总结:同主机内不同 GPU 之间的一种高速互联方式,
- 是一种短距离、串行通信链路,更高性能,替代 PCIe,
- 支持多 lane,link 带宽随 lane 数量线性增长,
- 同一台 node 内的 GPU 通过 NVLink 以 full-mesh 方式(类似 spine-leaf)互联,
- NVIDIA 专利技术。
演进:1/2/3/4 代
主要区别是单条 NVLink 链路的 lane 数量、每个 lane 的带宽(图中给的都是双向带宽)等:
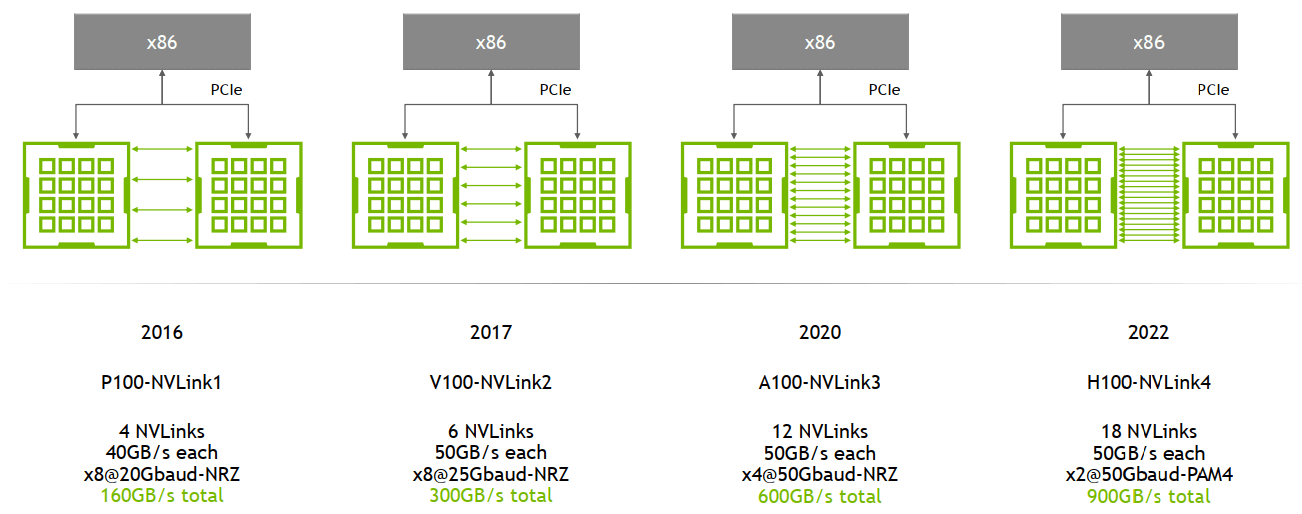
NVLink 演进。Image from: HotChips 2022 [1]
例如,
- A100 是
12 lane * 50GB/s/lane = 600GB/s双向带宽(单向 300GB/s) - A800 被阉割了 4 条 lane,所以是
8 lane * 50GB/s/lane = 400GB/s双向带宽(单向 200GB/s)
监控
基于 DCGM 可以采集到实时 NVLink 带宽:
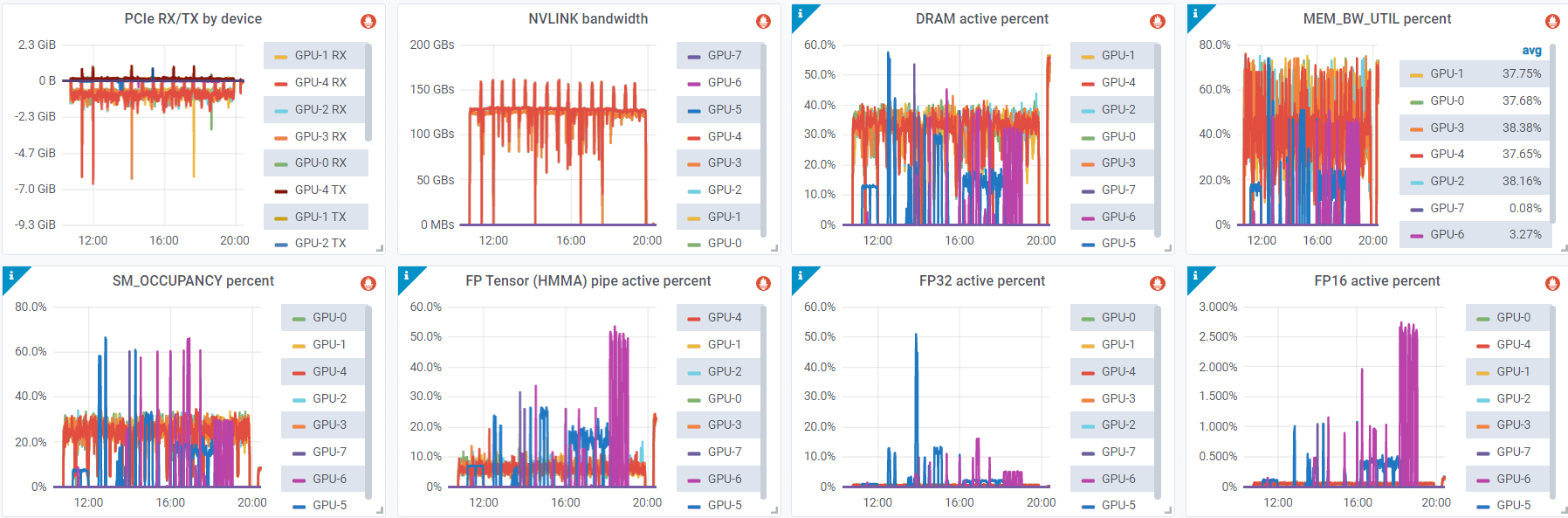
Metrics from dcgm-exporter [5]
1.3 NVSwitch
还是参考下图,
典型 8 卡 A100 主机硬件拓扑
NVSwitch 是 NVIDIA 的一款交换芯片,封装在 GPU module 上,并不是主机外的独立交换机。
下面是真机图,浪潮的机器,图中 8 个盒子就是 8 片 A100,右边的 6 块超厚散热片下面就是 NVSwitch 芯片:

Inspur NF5488A5 NVIDIA HGX A100 8 GPU Assembly Side View. Image source: [2]
1.4 NVLink Switch
NVSwitch 听名字像是交换机,但实际上是 GPU module 上的交换芯片,用来连接同一台主机内的 GPU。
2022 年,NVIDIA 把这块芯片拿出来真的做成了交换机,叫 NVLink Switch [3],
用来跨主机连接 GPU 设备。
这俩名字很容易让人混淆。
1.5 HBM (High Bandwidth Memory)
由来
传统的 GPU 显存和普通内存一样(DDR)通过 PCIe 连接,但是 PCIe Gen4 的带宽只有 64GB/s,Gen5 128GB/s,对 AI 训练来说是瓶颈。
因此,一些 GPU 厂商(不是只有 NVIDIA 一家这么做)将一种高带宽的存储芯片直接和 GPU 芯片封装到一起 (后文讲到 H100 时有图),这样每片 GPU 和它自己的显存交互时,就不用再去 PCIe 交换芯片绕一圈,速度最高可以提升一个量级。 这种“高带宽内存”(High Bandwidth Memory)缩写就是 HBM。
演进:HBM 1/2/2e/3/3e
From wikipedia HBM,
| Bandwidth | Year | GPU | |
|---|---|---|---|
| HBM | 128GB/s/package | ||
| HBM2 | 256GB/s/package | 2016 | V100 |
| HBM2e | ~450GB/s | 2018 | A100, ~2TB/s, |
| HBM3 | 600GB/s/site | 2020 | H100, 3.35TB/s |
| HBM3e | ~1TB/s | 2023 |
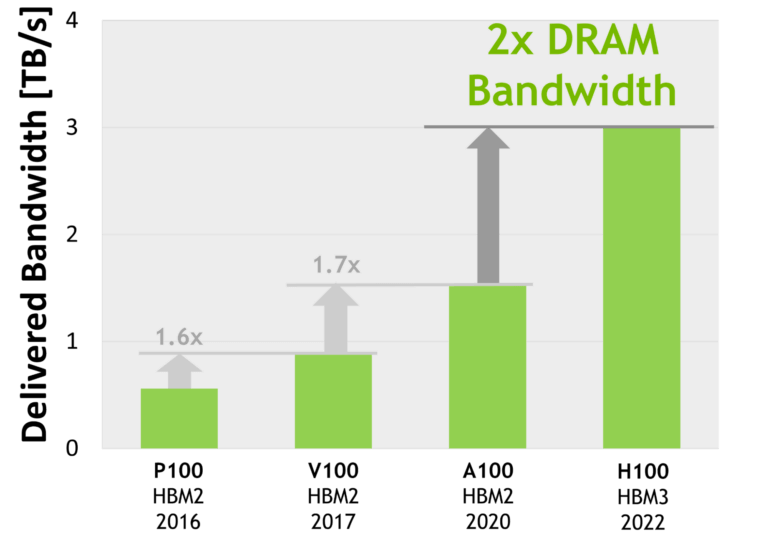
使用了 HBM 的近几代高端 NVIDIA GPU 显存带宽(双向),纵坐标是 TB/s。Image source: [3]
1.6 带宽单位
大规模 GPU 训练的性能与数据传输速度有直接关系。这里面涉及到很多链路,比如 PCIe 带宽、内存带宽、NVLink 带宽、HBM 带宽、网络带宽等等。
- 网络习惯用
bits/second (b/s)表示之外,并且一般说的都是单向(TX/RX); - 其他模块带宽基本用
byte/sedond (B/s)或transactions/second (T/s)表示,并且一般都是双向总带宽。
比较带宽时注意区分和转换。
2.1 主机内拓扑:2-2-4-6-8-8
- 2 片 CPU(及两边的内存,NUMA)
- 2 张存储网卡(访问分布式存储,带内管理等)
- 4 个 PCIe Gen4 Switch 芯片
- 6 个 NVSwitch 芯片
- 8 个 GPU
- 8 个 GPU 专属网卡
典型 8 卡 A100 主机硬件拓扑
下面这个图画的更专业,需要更多细节的可参考:
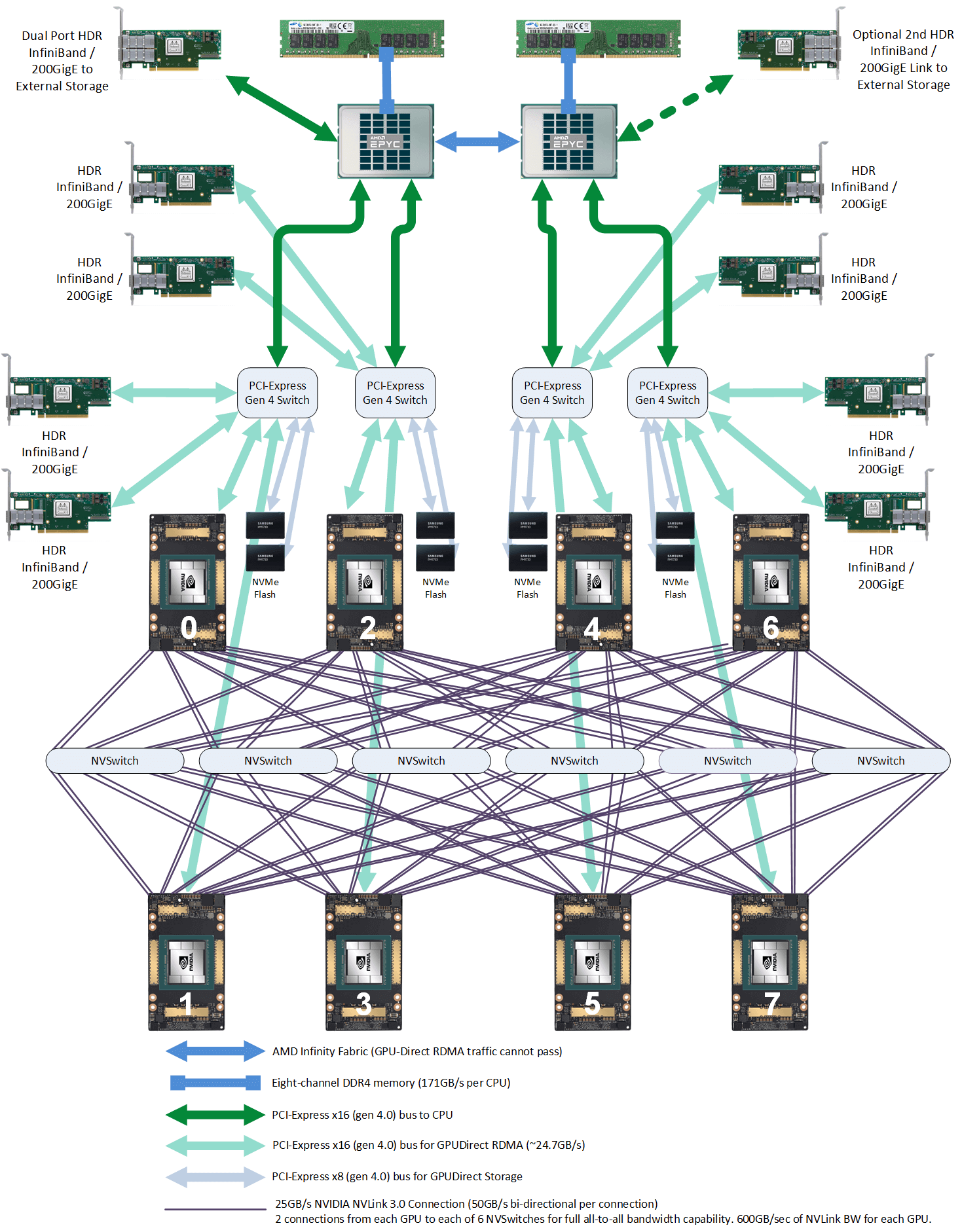
NVIDIA DGX A100 主机(官方 8 卡机器)硬件拓扑。Image source: [4]
存储网卡
通过 PCIe 直连 CPU。用途:
- 从分布式存储读写数据,例如读训练数据、写 checkpoint 等;
- 正常的 node 管理,ssh,监控采集等等。
官方推荐用 BF3 DPU。但其实只要带宽达标,用什么都行。组网经济点的话用 RoCE,追求最好的性能用 IB。
NVSwitch fabric:intra-node full-mesh
8 个 GPU 通过 6 个 NVSwitch 芯片 full-mesh 连接,这个 full-mesh
也叫 NVSwitch fabric;
full-mesh 里面的每根线的带宽是 n * bw-per-nvlink-lane,
- A100 用的 NVLink3,
50GB/s/lane,所以 full-mesh 里的每条线就是12*50GB/s=600GB/s,注意这个是双向带宽,单向只有 300GB/s。 - A800 是阉割版,12 lane 变成 8 lane,所以每条线 8*50GB/s=400GB/s,单向 200GB/s。
用 nvidia-smi topo 查看拓扑
下面是一台 8*A800 机器上 nvidia-smi 显示的实际拓扑(网卡两两做了 bond,NIC 0~3 都是 bond):
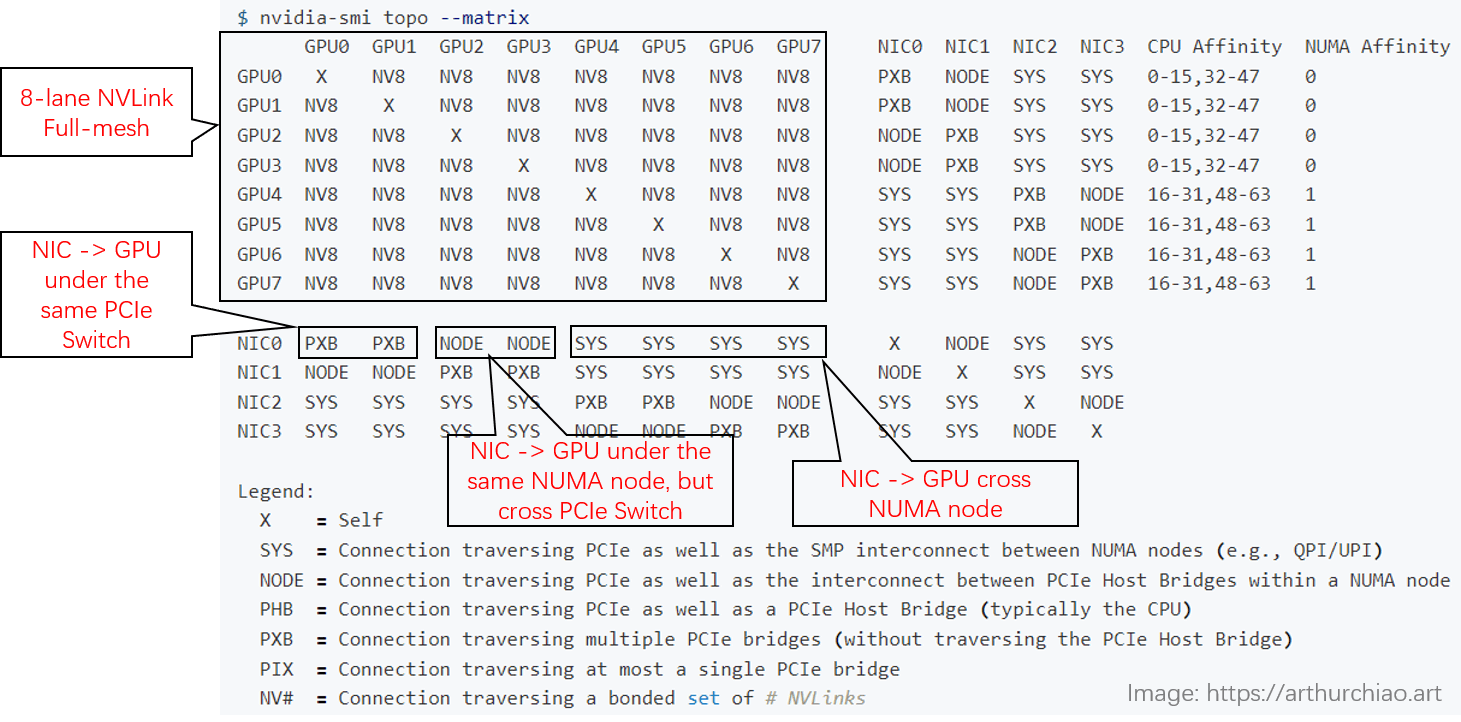
- GPU 之间(左上角区域):都是
NV8,表示 8 条 NVLink 连接; -
NIC 之间:
- 在同一片 CPU 上:
NODE,表示不需要跨 NUMA,但需要跨 PCIe 交换芯片; - 不在同一片 CPU 上:
SYS,表示需要跨 NUMA;
- 在同一片 CPU 上:
-
GPU 和 NIC 之间:
- 在同一片 CPU 上,且在同一个 PCIe Switch 芯片下面:
NODE,表示只需要跨 PCIe 交换芯片; - 在同一片 CPU 上,且不在同一个 PCIe Switch 芯片下面:
NODE,表示需要跨 PCIe 交换芯片和 PCIe Host Bridge; - 不在同一片 CPU 上:
SYS,表示需要跨 NUMA、PCIe 交换芯片,距离最远;
- 在同一片 CPU 上,且在同一个 PCIe Switch 芯片下面:
1.2 GPU 训练集群组网:IDC GPU fabirc
GPU node 互联架构:
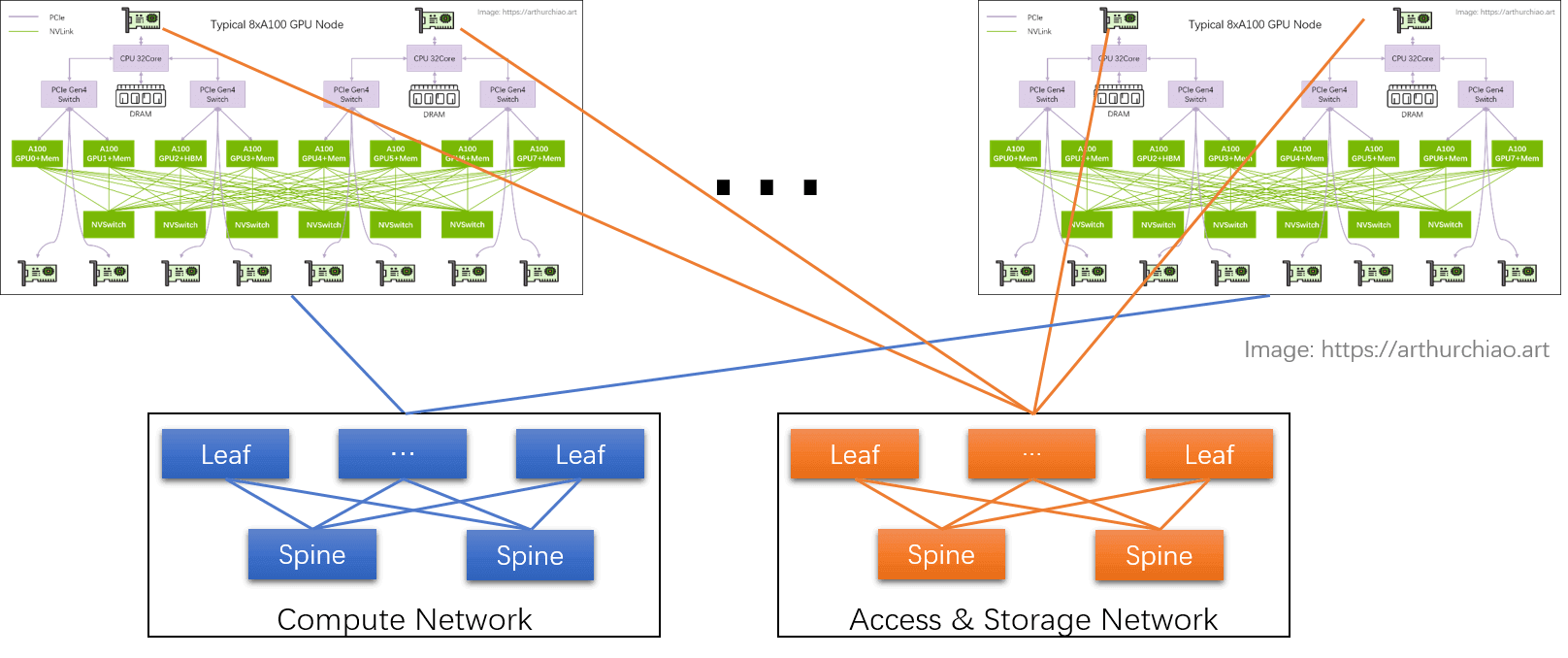
计算网络
GPU 网卡直连到置顶交换机(leaf),leaf 通过 full-mesh 连接到 spine,形成跨主机 GPU 计算网络。
- 这个网络的目的是 GPU 与其他 node 的 GPU 交换数据;
- 每个 GPU 和自己的网卡之间通过 PCIe 交换芯片连接:
GPU <--> PCIe Switch <--> NIC。
存储网络
直连 CPU 的两张网卡,连接到另一张网络里,主要作用是读写数据,以及 SSH 管理等等。
RoCE vs. InfiniBand
不管是计算网络还是存储网络,都需要 RDMA 才能实现 AI 所需的高性能。RDMA 目前有两种选择:
- RoCEv2:公有云卖的 8 卡 GPU 主机基本都是这种网络,比如 CX6
8*100Gbps配置;在性能达标的前提下,(相对)便宜; - InfiniBand (IB):同等网卡带宽下,性能比 RoCEv2 好 20% 以上,但是价格贵一倍。
1.3 数据链路带宽瓶颈分析
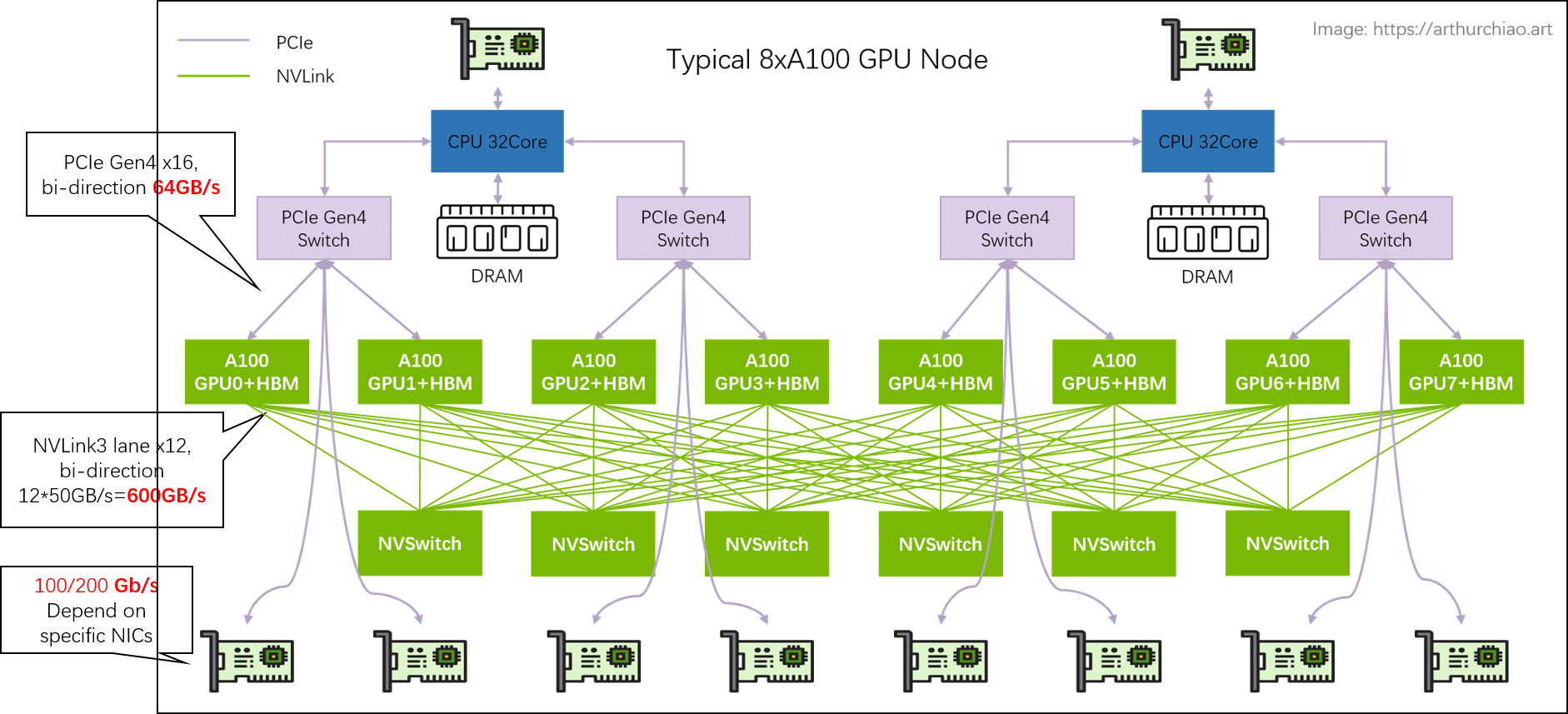
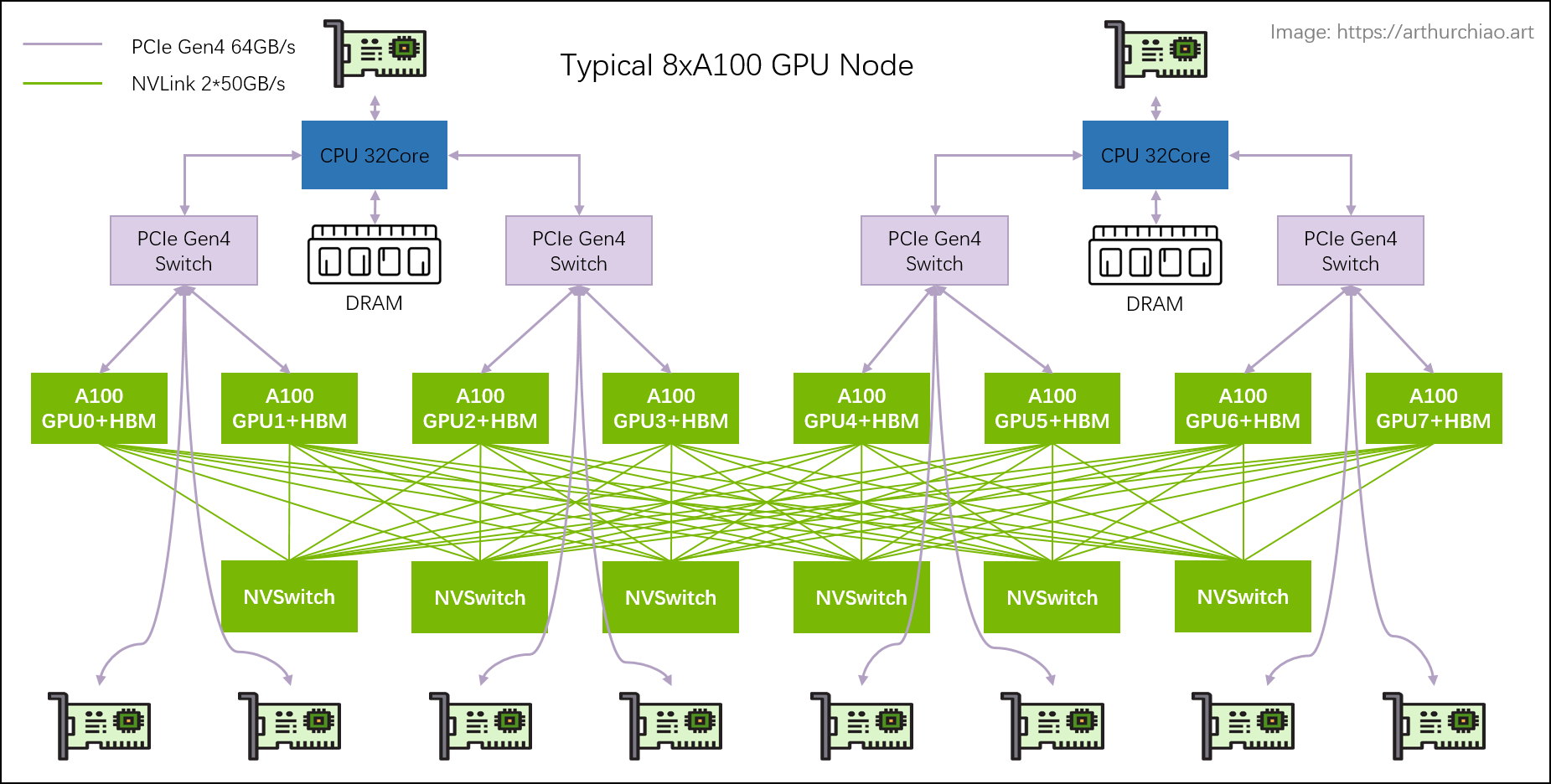
单机 8 卡 A100 GPU 主机带宽瓶颈分析
几个关键链路带宽都标在图上了,
- 同主机 GPU 之间:走 NVLink,双向 600GB/s,单向
300GB/s; - 同主机 GPU 和自己的网卡之间:走 PICe Gen4 Switch 芯片,双向 64GB/s,单向
32GB/s; - 跨主机 GPU 之间:需要通过网卡收发数据,这个就看网卡带宽了,目前国内 A100/A800
机型配套的主流带宽是(单向)
100Gbps=12.5GB/s。
所以跨机通信相比主机内通信性能要下降很多。
GPU Board Form Factor 分为两种类型:
- PCIe Gen5
- SXM5:性能更高一些
3.1 H100 芯片 layout
下面是一片 H100 GPU 芯片的内部结构:
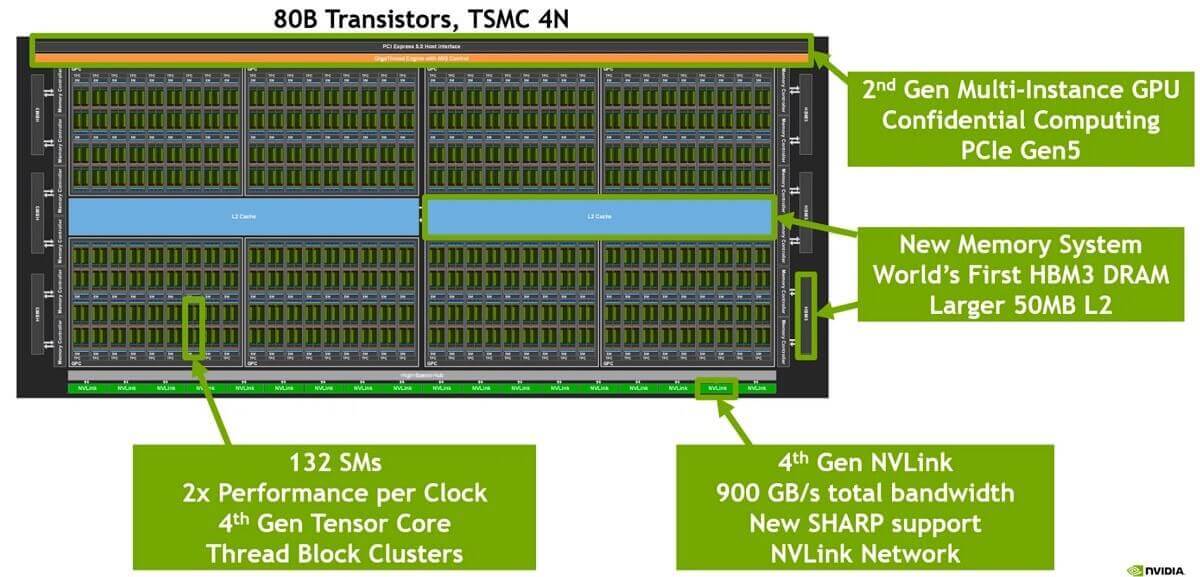
单片 H100 GPU 内部逻辑布局。Image source: [3]
4nm工艺;- 最下面一排是 18 根 Gen4 NVLink;双向总带宽
18 lanes * 25GB/s/lane = 900GB/s; - 中间蓝色的是 L2 cache;
- 左右两侧是
HBM芯片,即显存;
3.2 主机内硬件拓扑
跟 A100 8 卡机结构大致类似,区别:
-
NVSwitch 芯片从 6 个减少到了 4 个;真机图如下,

-
与 CPU 的互联从 PCIe Gen4 x16 升级到
PCIe Gen5 x16,双向带宽128GB/s;
3.3 组网
与 A100 也类似,只是标配改成了 400Gbps 的 CX7 网卡,
否则网络带宽与 PCIe Switch 和 NVLink/NVSwitch 之间的差距更大了。
L40S 是今年(2023)即将上市的新一代“性价比款”多功能 GPU,对标 A100。 除了不适合训练基座大模型之外(后面会看到为什么),官方的宣传里它几乎什么都能干。 价格的话,目前第三方服务器厂商给到的口头报价都是 A100 的 8 折左右。
4.1 L40S vs A100 配置及特点对比
L40S 最大的特点之一是 time-to-market 时间短,也就是从订货到拿到货周期比 A100/A800/H800 快很多。 这里面技术和非技术原因都有,比如:
- 不存在被美国制裁的功能,比如 FP64 和 NVLink 都干掉了;
- 使用
GDDR6显存,不依赖 HBM 产能(及先进封装);
价格便宜也有几方面原因,后面会详细介绍:
- 大头可能来自 GPU 本身价格降低:因为去掉了一些模块和功能,或者用便宜的产品替代;
- 整机成本也有节省:例如去掉了一层 PCIe Gen4 Swtich;不过相比于 4x/8x GPU,整机的其他部分都可以说送的了;
4.2 L40S 与 A100 性能对比
下面是一个官方标称性能对比:
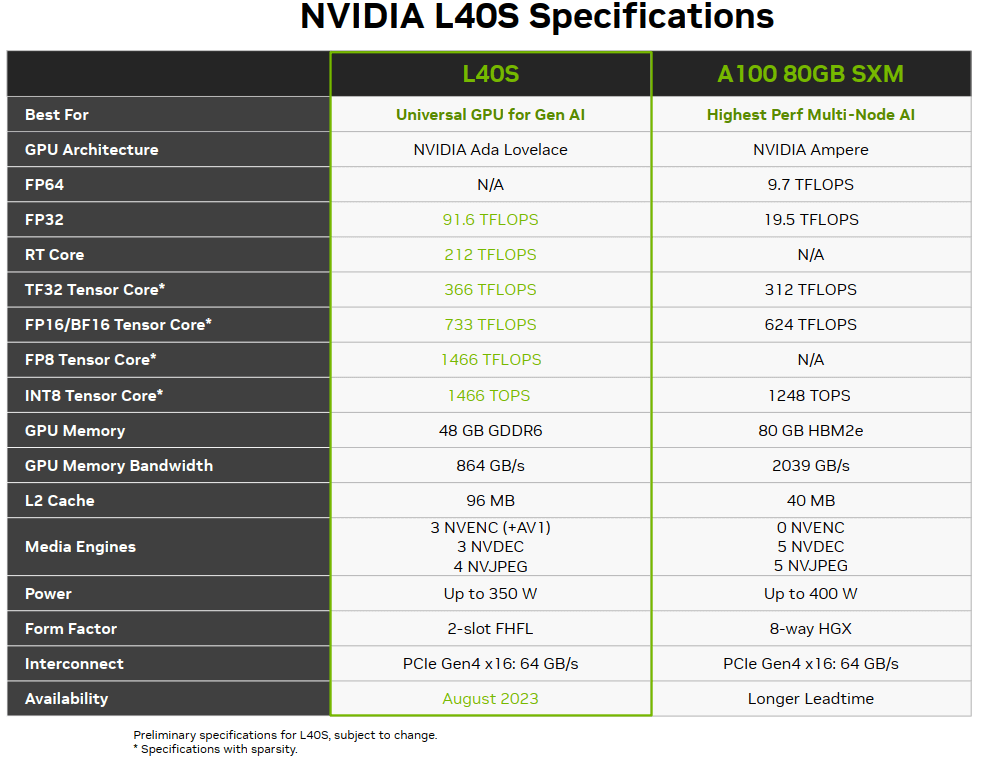
具体场景的性能对比网上也有很多官方资料,这里就不列举了。简单来,
- 性能 1.2x ~ 2x(看具体场景)。
- 功耗:两台 L40S 和单台 A100 差不多
需要注意,L40S 主机官方推荐的是单机 4 卡而不是 8 卡(后面会介绍为什么),
所以对比一般是用 两台 4*L40S vs 单台 8*A100。另外,很多场景的性能提升有个
大前提:网络需要是 200Gbps RoCE 或 IB 网络,接下来介绍为什么。
4.3 L40S 攒机
推荐架构:2-2-4
相比于 A100 的 2-2-4-6-8-8 架构,
官方推荐的 L40S GPU 主机是 2-2-4 架构,一台机器物理拓扑如下:
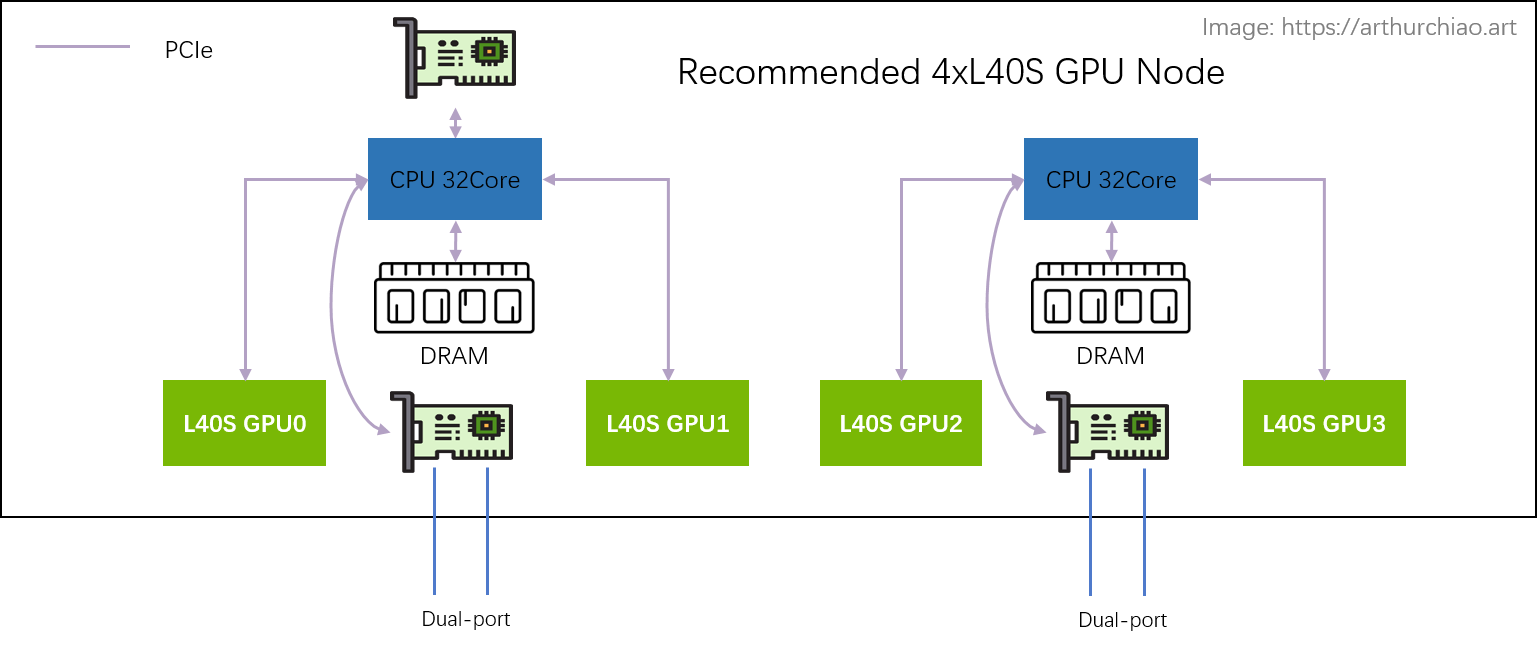
推荐单机 4 卡 L40S GPU 主机拓扑
最明显的变化是去掉了 CPU 和 GPU 之间的 PCIe Switch 芯片, 网卡和 GPU 都是直连 CPU 上自带的 PCIe Gen4 x16(64GB/s),
- 2 片 CPU(NUMA)
- 2 张双口 CX7 网卡(每张网卡
2*200Gbps) - 4 片 L40S GPU,每片 CPU 上 2 个 GPU
这样每片 GPU 平均 200Gbps 网络带宽。
不推荐架构:2-2-8
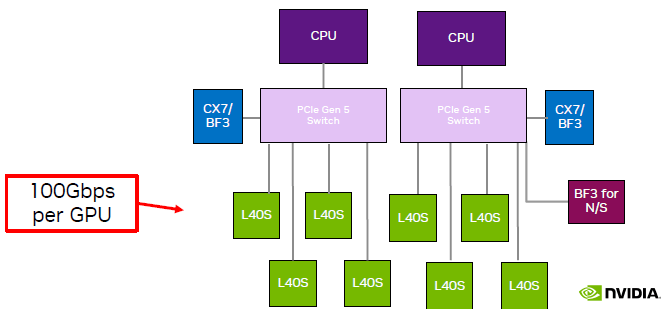
单机 8 卡 L40S GPU 主机拓扑,来自 NVIDIA L40S 官方推介材料
如图,跟单机 4 卡相比,单机 8 卡需要引入两片 PCIe Gen5 Switch 芯片:
- 说是现在PCIe Gen5 Switch 单片价格 1w 刀(不知真假),一台机器需要 2 片;价格不划算;
- PCIe switch 只有一家在生产,产能受限,周期很长;
- 平摊到每片 GPU 的网络带宽减半;
4.4 组网
官方建议 4 卡机型,搭配 200Gbps RoCE/IB 组网。
4.5 数据链路带宽瓶颈分析
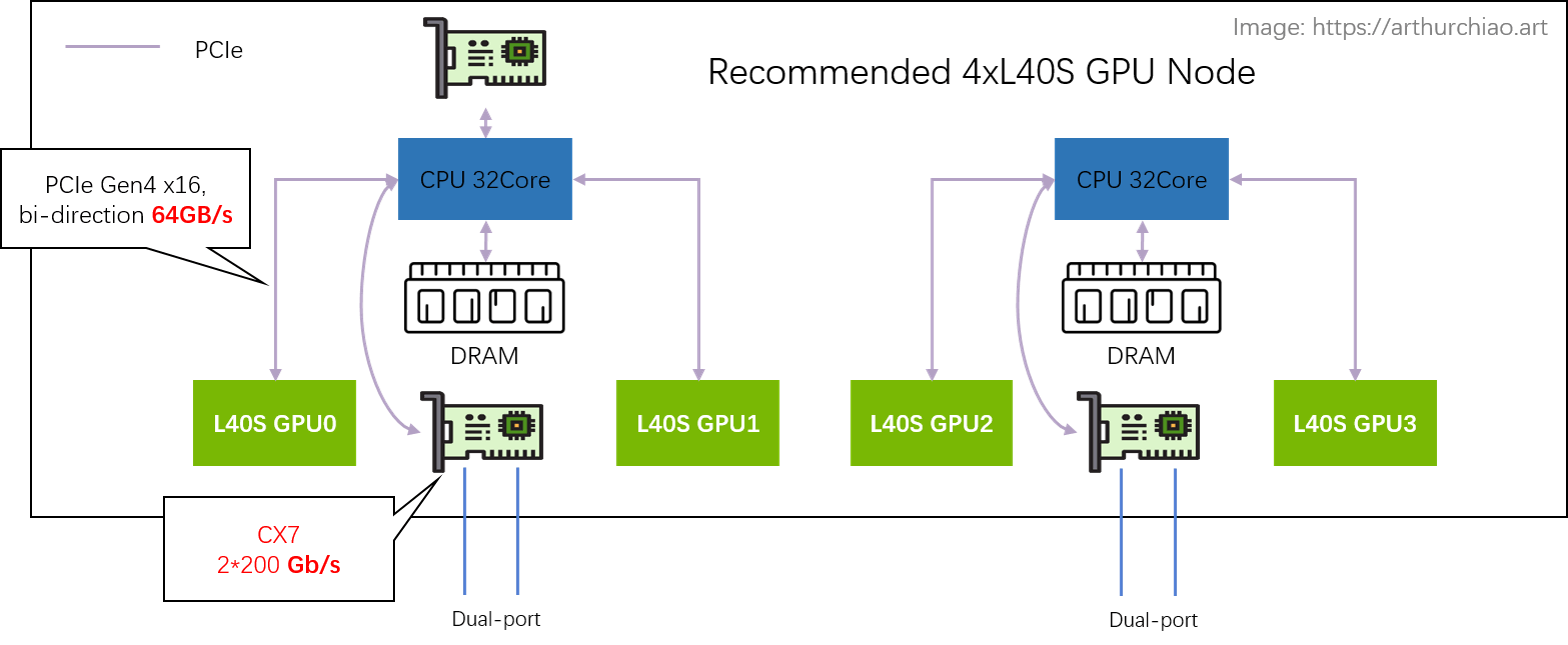
单机 4 卡 L40S GPU 主机带宽瓶颈分析
以同 CPU 下面的两种 L40S 为例,这里面有两条链路可选:
-
直接通过 CPU 处理:
GPU0 <--PCIe--> CPU <--PCIe--> GPU1- PCIe Gen4 x16 双向 64GB/s,单向
32GB/s; - CPU 处理瓶颈?TODO
- PCIe Gen4 x16 双向 64GB/s,单向
-
完全绕过 CPU 处理,通过网卡去外面绕一圈再回来:
GPU0 <--PCIe--> NIC <-- RoCe/IB Switch --> NIC <--PCIe--> GPU1- PCIe Gen4 x16 双向 64GB/s,单向
32GB/s; - 平均每个 GPU 一个单向 200Gbps 网口,单向折算
25GB/s; - 需要 NCCL 支持,官方说新版本 NCCL 正在针对 L40S 适配,默认行为就是去外面绕一圈回来;
- PCIe Gen4 x16 双向 64GB/s,单向
第二种方式看着长了很多,但官方说其实比方式一还要快很多(这里还每太搞懂,CPU 那里是怎么处理的?)—— 前提是网卡和交换机配到位:200Gbps RoCE/IB 网络。在这种网络架构下(网络带宽充足),
- 任何两片 GPU 的通信带宽和延迟都是一样的,是否在一台机器内或一片 CPU 下面并不重要,集群可以横向扩展(scaling up,compared with scaling in);
- GPU 机器成本降低;但其实对于那些对网络带宽要求没那么高的业务来说,是把 NVLINK 的成本转嫁给了网络,这时候必须要组建 200Gbps 网络,否则发挥不出 L40S 多卡训练的性能。
如果是方式二,同主机内 GPU 卡间的带宽瓶颈在网卡速度。即使网络是推荐的 2*CX7 配置,
- L40S: 200Gbps(网卡单向线速)
- A100: 300GB/s(NVLINK3 单向) ==
12x200Gbps - A800: 200GB/s(NVLINK3 单向) ==
8x200Gbps
可以看到,L40S 卡间带宽还是比 A100 NVLINK 慢了 12 倍, 比 A800 NVLink 慢了 8 倍,所以不适合数据密集交互的基础大模型训练。
4.6 测试注意事项
如上,即便只测试单机 4 卡 L40S 机器,也需要搭配 200Gbps 交换机,否则卡间性能发挥不出来。
- NVLink-Network Switch - NVIDIA’s Switch Chip for High Communication-Bandwidth SuperPODs, Hot Chips 2022
- ChatGPT Hardware a Look at 8x NVIDIA A100 Powering the Tool, 2023
- NVIDIA Hopper Architecture In-Depth, nvidia.com, 2022
- DGX A100 review: Throughput and Hardware Summary, 2020
- Understanding NVIDIA GPU Performance: Utilization vs. Saturation, 2023
如有侵权请联系:admin#unsafe.sh