Loading...


12 min read
Vectorize is our brand-new vector database offering, designed to let you build full-stack, AI-powered applications entirely on Cloudflare’s global network: and you can start building with it right away. Vectorize is in open beta, and is available to any developer using Cloudflare Workers.
You can use Vectorize with Workers AI to power semantic search, classification, recommendation and anomaly detection use-cases directly with Workers, improve the accuracy and context of answers from LLMs (Large Language Models), and/or bring-your-own embeddings from popular platforms, including OpenAI and Cohere.
Visit Vectorize’s developer documentation to get started, or read on if you want to better understand what vector databases do and how Vectorize is different.
Why do I need a vector database?
Machine learning models can’t remember anything: only what they were trained on.
Vector databases are designed to solve this, by capturing how an ML model represents data — including structured and unstructured text, images and audio — and storing it in a way that allows you to compare against future inputs. This allows us to leverage the power of existing machine-learning models and LLMs (Large Language Models) for content they haven’t been trained on: which, given the tremendous cost of training models, turns out to be extremely powerful.
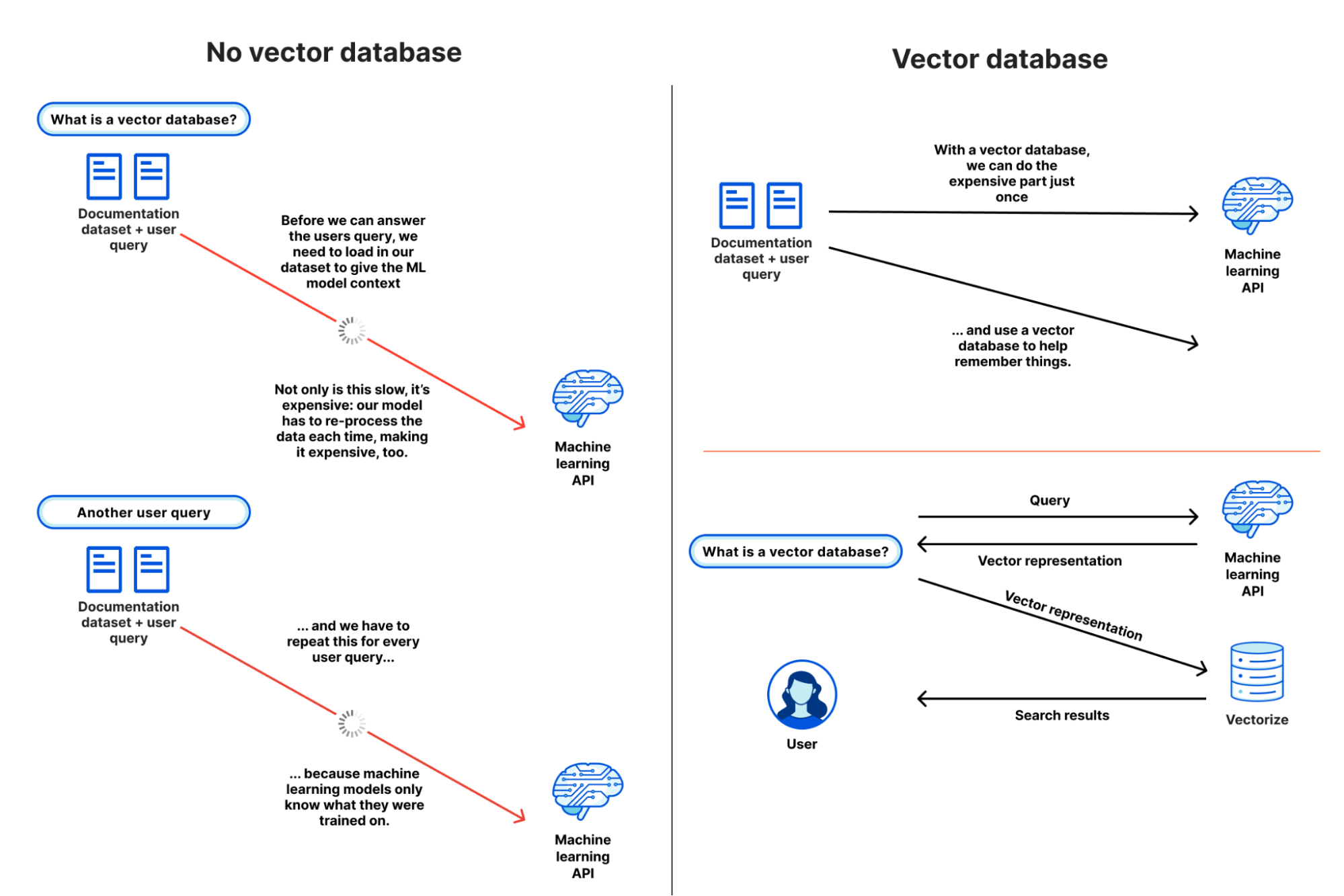
To better illustrate why a vector database like Vectorize is useful, let’s pretend they don’t exist, and see how painful it is to give context to an ML model or LLM for a semantic search or recommendation task. Our goal is to understand what content is similar to our query and return it: based on our own dataset.
- Our user query comes in: they’re searching for “how to write to R2 from Cloudflare Workers”
- We load up our entire documentation dataset — a thankfully “small” dataset at about 65,000 sentences, or 2.1 GB — and provide it alongside the query from our user. This allows the model to have the context it needs, based on our data.
- We wait.
- (A long time)
- We get our similarity scores back, with the sentences most similar to the user’s query, and then work to map those back to URLs before we return our search results.
… and then another query comes in, and we have to start this all over again.
In practice, this isn’t really possible: we can’t pass that much context in an API call (prompt) to most machine learning models, and even if we could, it’d take tremendous amounts of memory and time to process our dataset over-and-over again.
With a vector database, we don’t have to repeat step 2: we perform it once, or as our dataset updates, and use our vector database to provide a form of long-term memory for our machine learning model. Our workflow looks a little more like this:
- We load up our entire documentation dataset, run it through our model, and store the resulting vector embeddings in our vector database (just once).
- For each user query (and only the query) we ask the same model and retrieve a vector representation.
- We query our vector database with that query vector, which returns the vectors closest to our query vector.
If we looked at these two flows side by side, we can quickly see how inefficient and impractical it is to use our own dataset with an existing model without a vector database:
From this simple example, it’s probably starting to make some sense: but you might also be wondering why you need a vector database instead of just a regular database.
Vectors are the model’s representation of an input: how it maps that input to its internal structure, or “features”. Broadly, the more similar vectors are, the more similar the model believes those inputs to be based on how it extracts features from an input.
This is seemingly easy when we look at example vectors of only a handful of dimensions. But with real-world outputs, searching across 10,000 to 250,000 vectors, each potentially 1,536 dimensions wide, is non-trivial. This is where vector databases come in: to make search work at scale, vector databases use a specific class of algorithm, such as k-nearest neighbors (kNN) or other approximate nearest neighbor (ANN) algorithms to determine vector similarity.
And although vector databases are extremely useful when building AI and machine learning powered applications, they’re not only useful in those use-cases: they can be used for a multitude of classification and anomaly detection tasks. Knowing whether a query input is similar — or potentially dissimilar — from other inputs can power content moderation (does this match known-bad content?) and security alerting (have I seen this before?) tasks as well.
Building a recommendation engine with vector search
We built Vectorize to be a powerful partner to Workers AI: enabling you to run vector search tasks as close to users as possible, and without having to think about how to scale it for production.
We’re going to take a real world example — building a (product) recommendation engine for an e-commerce store — and simplify a few things.
Our goal is to show a list of “relevant products” on each product listing page: a perfect use-case for vector search. Our input vectors in the example are placeholders, but in a real world application we would generate them based on product descriptions and/or cart data by passing them through a sentence similarity model (such as Worker’s AI’s text embedding model)
Each vector represents a product across our store, and we associate the URL of the product with it. We could also set the ID of each vector to the product ID: both approaches are valid. Our query — vector search — represents the product description and content for the product user is currently viewing.
Let’s step through what this looks like in code: this example is pulled straight from our developer documentation:
export interface Env {
// This makes our vector index methods available on env.MY_VECTOR_INDEX.*
// e.g. env.MY_VECTOR_INDEX.insert() or .query()
TUTORIAL_INDEX: VectorizeIndex;
}
// Sample vectors: 3 dimensions wide.
//
// Vectors from a machine-learning model are typically ~100 to 1536 dimensions
// wide (or wider still).
const sampleVectors: Array<VectorizeVector> = [
{ id: '1', values: [32.4, 74.1, 3.2], metadata: { url: '/products/sku/13913913' } },
{ id: '2', values: [15.1, 19.2, 15.8], metadata: { url: '/products/sku/10148191' } },
{ id: '3', values: [0.16, 1.2, 3.8], metadata: { url: '/products/sku/97913813' } },
{ id: '4', values: [75.1, 67.1, 29.9], metadata: { url: '/products/sku/418313' } },
{ id: '5', values: [58.8, 6.7, 3.4], metadata: { url: '/products/sku/55519183' } },
];
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
if (new URL(request.url).pathname !== '/') {
return new Response('', { status: 404 });
}
// Insert some sample vectors into our index
// In a real application, these vectors would be the output of a machine learning (ML) model,
// such as Workers AI, OpenAI, or Cohere.
let inserted = await env.TUTORIAL_INDEX.insert(sampleVectors);
// Log the number of IDs we successfully inserted
console.info(`inserted ${inserted.count} vectors into the index`);
// In a real application, we would take a user query - e.g. "durable
// objects" - and transform it into a vector emebedding first.
//
// In our example, we're going to construct a simple vector that should
// match vector id #5
let queryVector: Array<number> = [54.8, 5.5, 3.1];
// Query our index and return the three (topK = 3) most similar vector
// IDs with their similarity score.
//
// By default, vector values are not returned, as in many cases the
// vectorId and scores are sufficient to map the vector back to the
// original content it represents.
let matches = await env.TUTORIAL_INDEX.query(queryVector, { topK: 3, returnVectors: true });
// We map over our results to find the most similar vector result.
//
// Since our index uses the 'cosine' distance metric, scores will range
// from 1 to -1. A value of '1' means the vector is the same; the
// closer to 1, the more similar. Values of -1 (least similar) and 0 (no
// match).
// let closestScore = 0;
// let mostSimilarId = '';
// matches.matches.map((match) => {
// if (match.score > closestScore) {
// closestScore = match.score;
// mostSimilarId = match.vectorId;
// }
// });
return Response.json({
// This will return the closest vectors: we'll see that the vector
// with id = 5 has the highest score (closest to 1.0) as the
// distance between it and our query vector is the smallest.
// Return the full set of matches so we can see the possible scores.
matches: matches,
});
},
};
The code above is intentionally simple, but illustrates vector search at its core: we insert vectors into our database, and query it for vectors with the smallest distance to our query vector.
Here are the results, with the values included, so we visually observe that our query vector [54.8, 5.5, 3.1] is similar to our highest scoring match: [58.799, 6.699, 3.400] returned from our search. This index uses cosine similarity to calculate the distance between vectors, which means that the closer the score to 1, the more similar a match is to our query vector.
{
"matches": {
"count": 3,
"matches": [
{
"score": 0.999909,
"vectorId": "5",
"vector": {
"id": "5",
"values": [
58.79999923706055,
6.699999809265137,
3.4000000953674316
],
"metadata": {
"url": "/products/sku/55519183"
}
}
},
{
"score": 0.789848,
"vectorId": "4",
"vector": {
"id": "4",
"values": [
75.0999984741211,
67.0999984741211,
29.899999618530273
],
"metadata": {
"url": "/products/sku/418313"
}
}
},
{
"score": 0.611976,
"vectorId": "2",
"vector": {
"id": "2",
"values": [
15.100000381469727,
19.200000762939453,
15.800000190734863
],
"metadata": {
"url": "/products/sku/10148191"
}
}
}
]
}
}
In a real application, we could now quickly return product recommendation URLs based on the most similar products, sorting them by their score (highest to lowest), and increasing the topK value if we want to show more. The metadata stored alongside each vector could also embed a path to an R2 object, a UUID for a row in a D1 database, or a key-value pair from Workers KV.
Workers AI + Vectorize: full stack vector search on Cloudflare
In a real application, we need a machine learning model that can both generate vector embeddings from our original dataset (to seed our database) and quickly turn user queries into vector embeddings too. These need to be from the same model, as each model represents features differently.
Here’s a compact example building an entire end-to-end vector search pipeline on Cloudflare:
import { Ai } from '@cloudflare/ai';
export interface Env {
TEXT_EMBEDDINGS: VectorizeIndex;
AI: any;
}
interface EmbeddingResponse {
shape: number[];
data: number[][];
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const ai = new Ai(env.AI);
let path = new URL(request.url).pathname;
if (path.startsWith('/favicon')) {
return new Response('', { status: 404 });
}
// We only need to generate vector embeddings just the once (or as our
// data changes), not on every request
if (path === '/insert') {
// In a real-world application, we could read in content from R2 or
// a SQL database (like D1) and pass it to Workers AI
const stories = ['This is a story about an orange cloud', 'This is a story about a llama', 'This is a story about a hugging emoji'];
const modelResp: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: stories,
});
// We need to convert the vector embeddings into a format Vectorize can accept.
// Each vector needs an id, a value (the vector) and optional metadata.
// In a real app, our ID would typicaly be bound to the ID of the source
// document.
let vectors: VectorizeVector[] = [];
let id = 1;
modelResp.data.forEach((vector) => {
vectors.push({ id: `${id}`, values: vector });
id++;
});
await env.TEXT_EMBEDDINGS.upsert(vectors);
}
// Our query: we expect this to match vector id: 1 in this simple example
let userQuery = 'orange cloud';
const queryVector: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: [userQuery],
});
let matches = await env.TEXT_EMBEDDINGS.query(queryVector.data[0], { topK: 1 });
return Response.json({
// We expect vector id: 1 to be our top match with a score of
// ~0.896888444
// We are using a cosine distance metric, where the closer to one,
// the more similar.
matches: matches,
});
},
};
The code above does four things:
- It passes the three sentences to Workers AI’s text embedding model (
@cf/baai/bge-base-en-v1.5) and retrieves their vector embeddings. - It inserts those vectors into our Vectorize index.
- Takes the user query and transforms it into a vector embedding via the same Workers AI model.
- Queries our Vectorize index for matches.
This example might look “too” simple, but in a production application, we’d only have to change two things: just insert our vectors once (or periodically via Cron Triggers), and replace our three example sentences with real data stored in R2, a D1 database, or another storage provider.
In fact, this is incredibly similar to how we run Cursor, the AI assistant that can answer questions about Cloudflare Worker: we migrated Cursor to run on Workers AI and Vectorize. We generate text embeddings from our developer documentation using its built-in text embedding model, insert them into a Vectorize index, and transform user queries on the fly via that same model.
BYO embeddings from your favorite AI API
Vectorize isn’t just limited to Workers AI, though: it’s a fully-fledged, standalone vector database.
If you’re already using OpenAI’s Embedding API, Cohere’s multilingual model, or any other embedding API, then you can easily bring-your-own (BYO) vectors to Vectorize.
It works just the same: generate your embeddings, insert them into Vectorize, and pass your queries through the model before you query your index. Vectorize includes a few shortcuts for some of the most popular embedding models.
# Vectorize has ready-to-go presets that set the dimensions and distance metric for popular embeddings models
$ wrangler vectorize create openai-index-example --preset=openai-text-embedding-ada-002
This can be particularly useful if you already have an existing workflow around an existing embeddings API, and/or have validated a specific multimodal or multilingual embeddings model for your use-case.
Making the cost of AI predictable
There’s a tremendous amount of excitement around AI and ML, but there’s also one big concern: that it’s too expensive to experiment with, and hard to predict at scale.
With Vectorize, we wanted to bring a simpler pricing model to vector databases. Have an idea for a proof-of-concept at work? That should fit into our free-tier limits. Scaling up and optimizing your embedding dimensions for performance vs. accuracy? It shouldn’t break the bank.
Importantly, Vectorize aims to be predictable: you don’t need to estimate CPU and memory consumption, which can be hard when you’re just starting out, and made even harder when trying to plan for your peak vs. off-peak hours in production for a brand new use-case. Instead, you’re charged based on the total number of vector dimensions you store, and the number of queries against them each month. It’s our job to take care of scaling up to meet your query patterns.
Here’s the pricing for Vectorize — and if you have a Workers paid plan now, Vectorize is entirely free to use until 2024:
| Workers Free (coming soon) | Workers Paid ($5/month) | |
|---|---|---|
| Queried vector dimensions included | 30M total queried dimensions / month | 50M total queried dimensions / month |
| Stored vector dimensions included | 5M stored dimensions / month | 10M stored dimensions / month |
| Additional cost | $0.04 / 1M vector dimensions queried or stored | $0.04 / 1M vector dimensions queried or stored |
Pricing is based entirely on what you store and query: (total vector dimensions queried + stored) * dimensions_per_vector * price. Query more? Easy to predict. Optimizing for smaller dimensions per vector to improve speed and reduce overall latency? Cost goes down. Have a few indexes for prototyping or experimenting with new use-cases? We don’t charge per-index.
As an example: if you load 10,000 Workers AI vectors (384 dimensions each) and make 5,000 queries against your index each day, it’d result in 49 million total vector dimensions queried and still fit into what we include in the Workers Paid plan ($5/month). Better still: we don’t delete your indexes due to inactivity.
Note that while this pricing isn’t final, we expect few changes going forward. We want to avoid the element of surprise: there’s nothing worse than starting to build on a platform and realizing the pricing is untenable after you’ve invested the time writing code, tests and learning the nuances of a technology.
Vectorize!
Every Workers developer on a paid plan can start using Vectorize immediately: the open beta is available right now, and you can visit our developer documentation to get started.
This is also just the beginning of the vector database story for us at Cloudflare. Over the next few weeks and months, we intend to land a new query engine that should further improve query performance, support even larger indexes, introduce sub-index filtering capabilities, increased metadata limits, and per-index analytics.
If you’re looking for inspiration on what to build, see the semantic search tutorial that combines Workers AI and Vectorize for document search, running entirely on Cloudflare. Or an example of how to combine OpenAI and Vectorize to give an LLM more context and dramatically improve the accuracy of its answers.
And if you have questions about how to use Vectorize for our product & engineering teams, or just want to bounce an idea off of other developers building on Workers AI, join the #vectorize and #workers-ai channels on our Developer Discord.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.