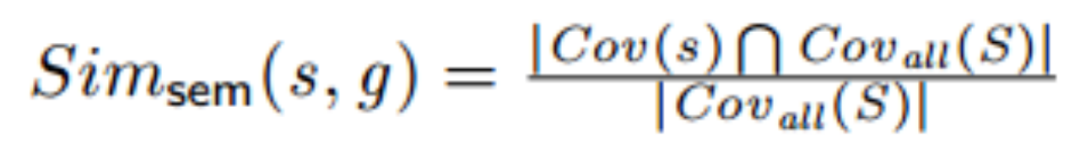
基本信息
原文名称 Learning Seed-Adaptive Mutation Strategies for Greybox Fuzzing
原文作者 Myungho Lee;Sooyoung Cha;Hakjoo Oh
原文链接 https://conf.researchr.org/details/
icse-2023/icse-2023-artifact-evaluation/55/Learning-Seed-Adaptive-Mutation-Strategies-for-Greybox-Fuzzing
发表期刊 ICSE,2023
开源代码 https://github.com/kupl/SeamFuzz-public
一、 引言
灰盒模糊测试器的性能很大程度取决于变异策略。通常,基于变异的模糊测试工具维护一组预定义的变异方法,这些方法指定变异的位置和变异的方式。传统模糊测试器(如AFL、HONGFUZZ和 VUZZER)遵循预定义的概率分布来选择突变策略,而不管目标是什么程序,这可能会降低模糊测试整体性能。程序自适应方法(如MOPT)旨在通过学习每个目标程序最优变异策略的概率分布解决这一问题。然而,程序自适应方法主要观察由大多数种子输入共有的特征触发的行为,经常会错过每个种子输入与大多数种子输入不同的个体特征。然而,这些个体特征往往在满足程序特定条件以到达深层次的程序位置方面发挥关键作用。
因此,作者提出了 SEAMFUZZ,一种具有新型种子自适应突变策略的灰盒模糊测试器。SEAMFUZZ 旨在捕获种子输入的个体特征,并对不同的种子输入应用不同的变异策略。
二、 概述
SEAMFUZZ 的工作流程如图1所示,在传统模糊测试的基础上新增两个步骤:(1)种子聚类,将种子输入聚类到具有相似特征的种子组中;(2)概率分布学习,通过不断进行模糊测试学习适合每个种子组的有效突变方法。
图1 SEAMFUZZ工作流程图
SEAMFUZZ的算法如图2所示。在第 2-3 行将崩溃触发集 Crash 和种子组信息集 G 初始化为空集。在第5行从种子输入语料库 I 中选择一个种子输入 s。在第 7-8行,函数CLUSTER将选择的种子输入s聚类到所对应的种子组,返回组信息g=(sid, S, Pid, Dg, Db),并从种子信息集G中移除种子组g。在第 11 -13行确定是遵循学习概率 Pid(利用)还是随机概率 Pr(探索)来为种子采样变异方法,根据选定的概率分布 P 采样有效的变异方法 M 来变异种子输入s。在第14行使用变异得到的测试用例 s' 执行程序 pgm,得到反馈信息(I , Crash, g)。在第15-16行 LEARN 函数利用反馈信息更新种子组g和种子组信息集G。通过 CLUSTER 和 LEARN 之间的迭代交互, SEAMFUZZ 能够学习到针对种子组的选择有效变异方法的概率分布。
图2 SEAMFUZZ算法图
三、种子聚类
给定一个种子输入 s 和一个种子组集合G,种子聚类的目标是将选定的种子输入 s 聚类到具有相似特征的适当种子组g中。为了实现这个目标,作者定义了相似度得分scoresim表示种子输入与种子组的相似程度,CLUSTER 函数根据分数将种子输入分组到种子组。相似度分数包括语法相似性得分、语义相似性得分、稀有度相似性得分。
(一)语义相似性
语义相似性 Simsem 描述种子输入与种子组的行为有多相似。更准确地说,它描述了种子输入和种子组所覆盖的执行路径的相似性;覆盖的执行路径越相同,它们就越相似。本文将覆盖的执行路径信息表示为两个基本块之间的一组覆盖转换,即A:a->b。由于种子组包含多个种子输入,本文通过计算单个种子组中所有种子输入覆盖的执行路径转换的集合 Covall 来定义种子组的一般语义行为。语义相似度是给定种子输入 s 和一组种子输入 S 共同覆盖的路径转换与集合 S 覆盖的路径转换的比率。
若Cov(s) = {A, B, D, Z}, Cov all(S) = {A, B, C,E, F, K, T, S},则该种子输入与种子组的语义相似性为0.25。
(二)语法相似性
语法相似性 Simsyn描述种子输入在语法上如何与种子组相似。将种子输入 s 视为大小为N位的位串,并定义种子组的代表性种子输入sid为种子组的语法特征。代表性种子是种子组中能够到达最多罕见覆盖路径转换Covrare的种子,其作用是描述引导探索罕见覆盖路径转换的语法特征。
µ(s, sid) 是种子s与sid之间相同比特位置上值相同的次数,s[i] 表示种子输入 s 的第i个比特的值,N为长度更长的种子输入的大小。若s = “0 1 0 1 0 0 0 0 1 1”, sid = “0 1 1 0 0 0 0 1 1 1”,则种子输入与种子组之间的语法相似性为0.7。
(三)稀有度相似性
稀有度相似性基于从很少探索的执行转换开始的突变可能会探索更深的程序位置的假设。
其中 hit(path) 表示执行路径的命中计数。如果 Simrare 覆盖了更多很少探索的路径转换,则需要为给定种子输入 s 分配更多的分数。与其他两个相似性不同,Simrare对聚类没有太大影响,但当种子组之间没有显著差异时,对识别最相似的种子组仍然有用。
(四)相似度得分
在获得三种不同的相似性(即语法、语义和稀有度)后,CLUSTER 计算种子输入与每个种子组之间的相似性分数(scoresim),并确定给定的种子输入所属的种子组。CLUSTER 函数定义为
其中dmax表示种子与所有种子组计算得到的最高相似性分数。当dmax超过γ值时,argmax 函数返回得分为dmax的种子组。否则,种子输入 s 不属于任何现有种子组, CLUSTER 函数通过使用代表性种子输入 s 初始化组来组织新的种子组,将 Pid 初始化为均匀分布 (Pr)。通过使用以下等式获得相似性分数scoresim。
超参数α反映了语法相似度与语义相似度的重要程度。经过反复试验,将α值设置为 0.9。
四、概率分布学习
概率学习器,它学习针对每个种子组选择有效变异方法的概率分布。
(一)采样空间
首先定义一个采样空间,用于选择变异方法 m,该空间指定在哪里变异 (loc) 以及如何变异 (op)。如何变异与预定义的变异算子直接相关,因此,可以很容易地确定选择变异算子的采样空间。然而,由于给定的种子输入大小不同,使得难以定义选择突变位置的采样空间。
为了具体确定选择 loc 的采样空间,本文将种子输入的长度除以 p 值,使 loc 的采样空间大小为 p,而不管种子输入如何。通过对空间进行分区,本文可以将采样空间从未定义大小 (loc) 转换为具体确定大小 (p) 的位置。一旦本文的变异策略选择了某个变异分区,它就会随机选择所选分区内的位置。
(二)汤普森采样
为了学习对种子组最有效的变异方法,本文问题可以自然地表示为多臂老虎机 (MAB) 问题。MAB 问题假设有 N 台老虎机,其目标是从它们那里获得最大的奖励。在每一轮中,本文选择一个老虎机进行游戏,并通过遵循为每个老虎机设定的概率分布来获得奖励。在本文的问题设置中,每个老虎机对应于每个变异算子 op 和变异分区 p;在模糊测试技术中,奖励可能对应于找到新的执行路径或新的崩溃输入。
本文方法的目标变成了找到最有利可图的老虎机(即有效的变异方法)以实现最大化的奖励,其中第 k 个老虎机获得奖励的成功概率为θk。为实现这一目标,本文采用了 Thompson 抽样算法,这是经典 MAB 问题的著名解决方案。汤普森抽样根据观察到的奖励建立概率模型,并从相应模型中采样每个老虎机的期望值,以选择下一轮的老虎机。直觉上,对特定老虎机观察到的奖励越多,就越有可能在下一轮选择该老虎机。如果某个老虎机的成功概率很低,则随着观察到的数据越多,选择这个老虎机的概率也会越低。
(三)学习算法
基于汤普森抽样,定义选择第 i 个变异算子的概率如下:
其中
定义模糊测试成功和失败的最简单方法是生成的测试用例是否是一个有趣的输入;否则,认为该测试用例失败。如果天真地定义成功和失败案例,将无法学习选择有效变异方法的概率分布。由于灰盒模糊测试技术的低效率,选择有效变异方法的概率分布将退化为均匀分布。为了解决这个问题,本文为成功和失败案例引入了额外的分类标准:
1) s ' 覆盖 Covrare 中的至少一个路径转换,
2) s ' 覆盖 Covcommon 中超过 80% 的路径转换。
要成为成功测试用例,s’需要满足有趣或上述第一个条件。仅仅是一个无趣的测试用例还不足以成为一个失败用例,必须满足第二个条件。有了这两个附加条件,可以提高成功次数并降低失败次数。本文为每个路径转换维护一个命中计数表。每当使用生成的测试用例执行程序 pgm 时,都会更新此命中计数表。使用此命中计数信息按升序排列,建立 Covrare(前30%) 和 Covcommon(后30%)两个集合。
在此示例中,s1 和 s2 都不是有趣的测试用例,因为它们未能涵盖新的执行路径。然而,s1 被认为是成功案例,因为它满足第一个条件,本文使用的变异方法更新良好的学习数据 Dg 以生成 s1。对于 s2 ,本文不更新 Dg 或 Db,因为它不成功并且不满足任何条件。
基于上述分类标准,将在运行过程中更新学习数据 Dg 和 Db。学习数据D是一对两个向量,变异算子数据(Vop)和变异分区数据(Vp);每个向量的第i个元素分别表示第i个变异算子和分区被选择的次数。在学习数据 D 的基础上,Dg 用于累积变异方法在生成成功测试用例时使用的数量,而 Db 用于生成失败测试用例。
比较早期和后期生成的成功测试用例的数量时,随着时间的推移,找到有效输入变得越来越困难。理论上,后期获得的成功奖励应该要比前期相对高一些,模糊测试才能有效进行。因此,随着模糊测试的进行,会逐渐增加基础奖励以便后续生成成功测试用例获得更多利润。
五、实验设计及结果
(一)实验设置
为了进行评估,本文使用了 FUZZBENCH,一种具有多种指标的模糊器基准测试框架。将FUZZBENCH中使用的所有参数值设置为默认值,并使用FUZZBENCH提供的运行脚本文件。本文在 AFL++上实现SEAMFUZZ,并将其与两种不同的基于突变的灰盒模糊器 AFL++ 和 AFL++MOPT 进行了比较。
评估的三个模糊器均基于 AFL++,版本为 3.15a。在 24 小时内通过 20 次试验评估了每个基准程序,以减轻模糊测试技术固有随机性的影响,并报告了平均结果。所有实验均在运行 Ubuntu 20.04 的机器上完成,该机器配备 64 个 CPU 和 256GB 内存,由 AMD Ryzen Threadripper 3990X 64 核处理器提供支持。实验基准如图3所示:
图3 基准程序
(二)具体实验
实验一:SEAMFUZZ的有效性
图4展示了SEAMFUZZ的性能表现。SEAMFUZZ 平均覆盖的分支比 AFL++ 和 AFL++MOPT 分别多 5.6% 和 7.7%。在碰撞输入生成能力方面,SEAMFUZZ 成功地生成了比 AFL++ 和 AFL++MOPT 多 56.4% 和 57.1% 的碰撞输入。SEAMFUZZ 通常实现最高数量的覆盖分支。例如,在 objdump 上,SEAMFUZZ 成功覆盖了 5,759 个分支,而 AFL++ 和 AFL++MOPT 分别只覆盖了 4,969 和 4,663 个分支。SEAMFUZZ 可以产生比其他模糊器多得多的崩溃输入,即使分支覆盖范围的增量很小。例如,在 php-parser 上,SEAMFUZZ 生成的崩溃输入比 AFL++ 多 233.3%,而覆盖分支数量的增加仅为 0.4%
图4 24 小时内对 14 个程序进行 20 次试验的平均结果。
实验二:BUG发现能力
图 5显示种子自适应方法在发现各种错误方面具有相当大的潜力。SEAMFUZZ 可以发现最多的独特错误(99个错误),包括 27 个其他基线模糊器未检测到的错误,而 AFL++ 和 AFL++MOPT 在 14 个基准程序中发现了 85 和 87 个独特错误。
图5 每个工具发现的独特错误的维恩图
图6展示了评估每个工具在 MAGMA上的错误发现能力。由于 MAGMA 提供了多个模糊测试目标程序,本文评估了每个程序的实验。为了在 FUZZBENCH 上评估注入错误的 MAGMA 基准程序,本文插入了断言语句来指定 MAGMA 中的错误条件。所有的模糊器都可以检测到相同的 14 个 MAGMA 错误,SEAMFUZZ 和 AFL++ 在 libxml2 中检测到另一个错误“XML002”,而 AFL++MOPT 只能在 openssl 中检测到SSL020”。
图6 每个模糊器都发现的MAGMA错误
实验三:种子聚类的有效性
为了研究种子聚类的功效,本文实施了 NOCLUSTER 和 EACHCLUSTER,它们维护不同数量的种子组。更准确地说,NOCLUSTER 只维护一个种子组,并将所有选定的种子输入聚集到这个组中,这模拟了程序自适应方法。EACHCLUSTER 为每个种子输入分配一个种子组,它分别应用为每个种子输入量身定制的不同变异策略。
图7展示采用聚类方法与否的实验性能。图8展示相似性分数中超参数α的选取实验结果。在所有 14 个程序中,与 SEAMFUZZ 相比,NOCLUSTER 和 EACHCLUSTER 覆盖的分支分别减少了 4.9% 和 4.4%。碰撞输入生成的性能下降更为严重;NOCLUSTER 和 EACHCLUSTER 分别减少了 36.3% 和 25.5% 的碰撞输入。
图7 不同粒度的种子聚类性能表现
图8 不同超参数α下性能表现
实验四:学习算法的有效性
图9展示评估 Thompson 抽样算法中成功和失败案例的分类标准如何影响 SEAMFUZZ 在前 9 个程序中的整体性能。更准确地说,本文将 SEAMFUZZ 与 NAIVESEAMFUZZ 进行了比较,为 Thompson 采样定制的标准提高了路径发现和崩溃生成能力;与朴素分类相比,它有助于多覆盖 6.1% 的分支并多生成 57.1% 的碰撞输入。
图9 不同数据分类标准下性能表现
本文调查了成功奖励的增加值如何影响本文方法的性能。为了观察奖励动态变化对绩效的影响,本文用五种不同的设置评估了 SEAMFUZZ;REWARDN 将奖励增加“N”。如图10所示,使用适当的值动态更新奖励可以显著提高本文方法的性能。
图10 不同奖励值增长下性能表现
六、 总结
最近,灰盒模糊器的程序自适应突变策略已经成功地改进了现有的与程序无关的模糊器。在本文中更进一步,呼吁关注从程序自适应方法到种子自适应方法的转变。关键思想是根据句法和语义相似性将种子输入聚类到种子组中,并使用 Thompson 抽样的变体在线学习针对每个种子组优化的变异策略。证明了本文的种子自适应方法在覆盖率和错误发现方面极大地增强了最先进的程序自适应技术。
如有侵权请联系:admin#unsafe.sh