题外话:
因为人的因素,安全攻防对抗技术不断地变化,这看起来会给安全数据分析带来很大的挑战。
而安全数据的本质是不变的,基础的TCP/IP协议是不变的,恶意软件文件格式是不变的。掌握这些基础的,不变的特征,就能帮助我们分析绝大部分安全数据。
很多时候我们找不到一个恰当的应用场景,把先进的互联网技术应用到安全数据分析中去。我们不妨先去了解数据从何而来,尝试去模拟和解析网络协议,去捕获和运行恶意软件,去摸索和分析它们的行为规律。
大数据和机器学习技术蓬勃发展,我做的只是应用层的工作而已,可能这像是一个组装游戏,把各个技术,算法组装在一块就好了。
从去年7月份开始,我开始尝试使用ClickHouse大数据分析引擎去解决Anglerfish蜜罐日志和恶意软件(ELF)样本数据分析问题。现在总结一些经验和技巧,也给大家分享下几个数据分析场景。
1)二进制文件数据分析
传统的逆向分析工程师一般是通过IDA打开一个二进制样本进行深入分析。我并不是这样做的,一般我也不需要逆向分析单个样本。
我通过Radare2工具自动化分析二进制可执行文件(PE,ELF等格式),并把二进制文件结构化存储到ClickHouse数据中。这样,我不用每次分析一个样本都打开IDA。
你要知道等IDA打开并分析完1个样本一般需要10秒钟的时间,这对于分析百万/千万级的样本是不现实的。
以下是单机版ELF文件建表SQL示例:
CREATE TABLE `elf`(`timestamp` DateTime,`file_md5` String,`file_sha1` String,`file_sha256` String,`file_ssdeep` String,`file_magic` String,`file_type` String,`file_data` String,`format` String,`strings` Array(String),`strings_ssdeep` String,`strings_r2` Array(String),`strings_r2_ssdeep` String,`imagebase` UInt32,`interpreter` String,`libraries` Array(String),`arm_flags` Array(String),`entrypoint` UInt32,`header_size` UInt16,`identity_abi_version` UInt8,`identity_class` String,`identity_data` String,`identity_os_abi` String,`machine_type` String,`numberof_sections` UInt8,`numberof_segments` UInt8,`program_header_offset` UInt16,`program_header_size` UInt16,`section_header_offset` UInt16,`section_header_size` UInt16,`is_size_error` UInt8,`file_size` UInt32,`section` Nested(`name` String,`offset` UInt32,`size` UInt32,`md5` String,`sha1` String,`sha256` String,`ssdeep` String),`link_type` String,`is_stripped` UInt8,`symbols` Array(String),`function` Nested(`name` String,`offset` UInt32,`size` UInt32,`disasm` String,`md5` String,`sha1` String,`sha256` String,`ssdeep` String),`asm_sig` String,`asm_ssdeep` String,INDEX fmd5_index lower(file_md5) TYPE ngrambf_v1(3, 512, 2, 0) GRANULARITY 8192,INDEX asmsig_index lower(asm_sig) TYPE ngrambf_v1(3, 512, 2, 0) GRANULARITY 8192) ENGINE = MergeTree() PARTITION BY toYYYYMM(timestamp) ORDER BY (timestamp, file_sha256);
这样二进制可执行文件不仅实现了(极高的压缩比例)存储,还能根据文件结构化特征去计算。
场景1: 二进制文件相似性搜索
样本MD5: 80c0efb9e129f7f9b05a783df6959812样本SHA256: ba5b781ebacac07c4b14f9430a23ca0442e294236bd8dd14d1f69c6661551db8
对比下和VirusTotal的样本相似搜索结果
VirusTotal搜索语法1:
similar-to:ba5b781ebacac07c4b14f9430a23ca0442e294236bd8dd14d1f69c6661551db8结果:通过“Multi-similarity searches”相似性搜索返回结果较快,未找到相似样本
VirusTotal搜索语法2:
ssdeep:"49152:8xCbfW0KSrQqSQakNQ7GkIwGBl8BCaBrw5g+:UofBSQaZHGBl8BCaBr4F"结果:通过ssdeep相似性搜索时间较长,未找到相似样本
扩展阅读:
[1] Multi-similarity searches https://support.virustotal.com/hc/en-us/articles/360001398517
[2] https://ssdeep-project.github.io/ssdeep/index.html
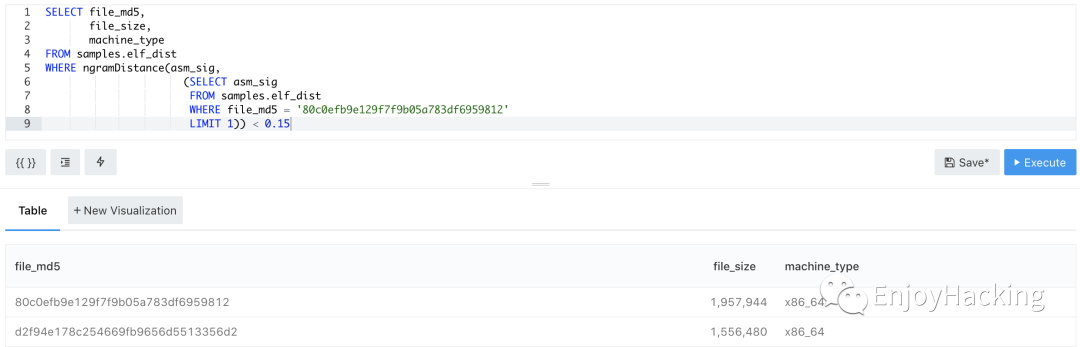
ClickHouse搜索语法1:
结果:找到相似样本d2f94e178c254669fb9656d5513356d2
原理:预先提取二进制样本反汇编代码字符串特征,通过ClickHouse + N-gram算法实现分布式计算字符串相似性。
扩展阅读:
[1] https://clickhouse.tech/docs/en/sql-reference/functions/string-search-functions/#ngramdistancehaystack-needle
[2] https://gallery.azure.ai/Experiment/Text-Classification-Step-3A-of-5-n-grams-TF-feature-extraction-2
ClickHouse搜索语法2:
结果:未找到相似样本(这里strings字符串过多,超过了N-gram特征大小限制:2^15)
原理:提取二进制样本字符串特征,利用N-gram算法去计算字符串相似性,然后通过ClickHouse ngramDistance函数实现分布式计算。
ClickHouse搜索语法3:
样本MD5: e535efb05104554df308aa0668c16150匹配到相似样本之后再去关联分析获得nod32病毒名。
场景1小结:
ClickHouse数据源ELF样本量上去之后匹配速度明显变慢,asm_sig预提取成本大,可以同时提取其它成本低而且高效的特征(比如strings_sig等),不同样本场景选取不同数据维度特征。
VirusTotal “Multi-similarity searches”不能组合搜索
场景2: 二进制文件特征搜索
样本MD5: 80c0efb9e129f7f9b05a783df6959812样本SHA256: ba5b781ebacac07c4b14f9430a23ca0442e294236bd8dd14d1f69c6661551db8
ViruslTotal搜索语法1:
content:"c_2910.cls" content:"k_3872.cls"ViruslTotal搜索语法2:
content:{635f323931302e636c73} content:{6b5f333837322e636c73}结果:通过字符串特征,在VirusTotal平台上找到了多种类型的文件,可以看出Lazarus Dacls RAT在Windows,Linux和Mac平台都存在相关样本。
VirusTotal搜索语法3:
content:{488b45e8ba01000000488d35[4]4889c7e8[4]85c07f0ab800000000e990000000488b45e8ba01000000488d35[4]4889c7e8[4]85c07f07b800000000eb6d}通过vt-ida插件(ida反汇编引擎),选取指定反汇编代码段,将内存偏移量或地址泛化并提取16进制字符串特征。
结果:通过Mnemonic(助记符)特征,在VirusTotal平台上找到了多个含有同样汇编代码特征的文件。
扩展阅读:
[1] https://github.com/VirusTotal/vt-ida-plugin
[2] https://support.virustotal.com/hc/en-us/articles/360001386897-Content-search-VTGrep-
ClickHouse搜索语法1:
结果:只匹配到1个样本(另一个样本提取字符串信息出错了)
ClickHouse搜索语法2:
结果:匹配到2个样本
ClickHouse搜索语法3:
通过mkYARA插件(capstone反汇编引擎),选取指定反汇编代码段,将内存偏移量或地址泛化并提取16进制字符串特征。
注:mkYARA插件只支持x86/x86-64 CPU架构,ARM和MIPS CPU架构还需自己完善capstone相关代码。
把YARA转换成SQL(vt-ida-plugin插件生成的16进制字符串特征也适用)
结果:匹配到2个样本
小结:
十六进制字符串搜索,在ClickHouse数据源ELF样本量上去之后匹配速度变得非常慢(样本量),但可以通过时间,文件大小,CPU架构等去限定搜索数据量级。
VirusTotal VTGrep不能组合搜索
YARA转SQL之后,通过ClickHouse在海量样本中去搜索样本优势明显
场景3: 函数相似性匹配
ClickHouse搜索语法1:
把一个被stripped的样本的函数对应的反汇编代码作为字符串特征,搜索未被stripped的样本中对应的函数名是什么。
ClickHouse搜索语法2:
把匹配到的函数名做group by统计,可以看到这个函数名绝大数时候被命名为:scanner_init,但也出现变种样本命名为:telnetscanner_scanner_init
2)结构化日志数据分析
场景4: 数据关联分析,统计,报表
基于ClickHouse数据库,把Anglerfish蜜罐中的sessions,downloads,payloads三个表进行关联分析,可以很快速地分析海量日志数据,再结合Redash系统通过SQL和Python去写数据模型和业务逻辑代码。
我这里把Anglerfish蜜罐捕获的Raw Payload数据进行Base64编码存储和计算,并把YARA规则识别的Exploit特征(rule和tag)存储到ClickHouse数据库中。YARA规则示例:
rule XiongMai_DVRIP_0day_RCE: IoT Camera Zero_day{meta:description = "XiongMai DVRIP Remote Code Execution"author = "[email protected]"date = "2019/08/08"reference = "https://twitter.com/zom3y3/status/1100667242159558656"port = "TCP/34567"strings:$header = { ff ?? 00 00 }$str1 = "Name"$str2 = "OPSystemUpgrade"$str3 = "InstallDesc"$str4 = "DVRIP"$str5 = "LoginType"condition:$header at 0 and (all of ($str*))}
3)相似性去重
海量(Payload和样本)数据分析避免不了重复数据,通过聚类实现相似性去重之后,会降低大量重复性工作。这时候再通过异常检测算法自动化告警新增数据,每天需要人工处理的事件也就不多了。
原理:通过SSDC算法对样本/Payload数据聚类,再抽取每个类中的1个成员。
恶意软件聚类分析 - 单机版Demo:https://github.com/zom3y3/ssdc
场景5: 未知Payload检测算法
第一步:筛选数据
第二步:聚类,相似性去重
第三步:通过slack和邮件告警
当看到告警时,我需要“肉眼”扫一遍,大多数时候是什么事都不用干,有时需要补充异常检测算法规则。只有当运气好的时候,才需要深入地分析在野0-day漏洞利用Payload。
=======
另外我创建了一个Botnet安全交流群,主要讨论Botnet,Honeypot等话题。(不过群里气氛现在还不活跃)
感兴趣的朋友可以加我的个人微信号:geenul
入群需要备注:真实姓名,所在公司/学校/单位,Botnet安全交流群。
例如:叶根深,360Netlab,Botnet安全交流群
一般我在微信公众号会发一些“软文”,不过我的推特是另一种风格哦,欢迎关注和交流: https://twitter.com/zom3y3
如有侵权请联系:admin#unsafe.sh